关联分析(Affinity Analysis)
关联分析(Affinity Analysis)是购物篮分析(Market basket analysis,MBA)的核心所在。 通过关联分析,可以从特定用户或群组所做的活动中发现共现关系(co-occurrence relationships)。 零售业中,关联分析能够帮助我们理解顾客的购买行为。在这些分析结果的帮助下,通过运用“聪 明”的交叉销售(cross-selling)与追加销售策略(up
·
目录
关联分析(Affinity Analysis )是 购物篮分析 ( Market basket analysis , MBA )的核心所在。 通过关联分析,可以从特定用户或群组所做的活动中发现共现关系(co-occurrence relationships )。 零售业中,关联分析能够帮助我们理解顾客的购买行为。在这些分析结果的帮助下,通过运用“聪 明”的交叉销售(cross-selling )与追加销售策略( upselling strategies )可以大大提高商品销额, 而且能帮你制订忠诚度计划、商品促销与打折销售计划。
将学习如下主题:
购物篮分析
关联性规则学习
在各种领域的不同应用
首先了解与关联性规则学习有关的概念与算法,比如支持度( support )、提升度( lift )、 Apriori 算法、 FP- 增长算法 。然后使用 Weka 对超市数据集做关联分析,研究如何解释结果规则。最后分 析如何将关联规则学习应用于其他领域,比如IT 运营分析 、医药等。
创建工程
接着上一篇文章的项目
购物篮分析
随着大量电子销售点的设立,零售商们收集了数量惊人的数据。为了充分利用这些数据并使 其产生商业价值,他们必须首先开发一种方法合并这些数据,以便了解业务的基本状况—— 他们 在销售什么?多少销售点在运转?销售量是多少?
近来,人们将关注焦点转移到最低粒度级的购物篮交易上。在这个细节层次,零售商可以直 接查看在他们店铺购物的每位顾客的购物篮,不仅可以知道顾客购买的商品数量,还可以了解顾 客是如何搭配购买这些商品的。这些分析结果可以用于决定如何区分库存分类与指定商品,以及 将同类别或不同类别的多种商品有效组合,以促进销售,获取更高利润。这些决策可以在整条零 售链上实现,包括各种销售渠道、本地店铺,甚至针对某个特定顾客。这称为个性化营销,即针 对每个顾客提供不同的商品。
MBA 涵盖的分析多种多样,如下所示。
商品关联 :定义同时购买两个或多个商品的可能性。
驱动商品的识别 :启动那些驱使人们去商店购买的商品识别,这些商品总是需要有货。
购物出行分类 :分析购物篮中的商品并对购物出行分类,比如每周购物出行、特殊情 况等。
店到店对比 :了解购物篮数量,允许任何可被购物篮总数相除的度量指标,有效创建一 个方便易用的方法,用于比较具有不同特征的商店(每个顾客销售量、每个交易收益、 每个篮子的商品数等)。
收益优化 :帮助确定该店的神奇价格( magic price points ),增加购物篮的大小与价值。
营销 :帮助找出可以产生更大利润的广告与促销方式,更精准地锁定报价以提高 ROI (投 资回报率),利用纵向分析产生更好的会员卡促销效果,吸引更多顾客进店购物。
经营优化 :通过商店定制、贸易区分类、优化商店布局,更好地匹配顾客需求与库存。 预测模型有助于零售商将合适的商品推荐给相应的客户群体,并帮助其了解顾客喜欢什么样 的商品,预测顾客响应这个购物提议的可能性分数,了解顾客从这个提议的获益程度。
关联分析
关联分析用于确定顾客同时购买一组商品的可能性。零售业中,商品之间存在着一些天然的 关联,比如一个很常见的例子是:买汉堡肉饼的人通常还会一起买汉堡面包、番茄酱、芥末酱、 番茄,以及其他做汉堡包的原料。
有些商品的关联看起来可能微不足道,有些关联则不是很明显。一个典型的例子是牙膏和金 枪鱼。看起来吃金枪鱼的人吃完饭后更倾向于立刻刷牙。那么,对于零售商来说,为什么把握商 品之间的关联显得如此重要?这些信息对于策划促销活动至关重要,对一些商品做降价促销可能 引起相关商品销售额激增,而对于这些相关商品则无需专门再做促销活动。
接下来将学习关联规则学习算法: Apriori 算法与 FP- 增长算法。
关联规则学习
关联规则学习是一种很流行的方法,用于在大型数据库中发现两个项目之间的有趣联系。它 通常应用于零售业,揭示商品之间的关联规则。
关联规则学习方法使用不同的兴趣度度量方法,以发现数据库中那些有趣的强规则模式。比 如,下面规则表明,如果一个顾客同时购买了洋葱与土豆,那么他很可能会买汉堡包肉饼:{ 洋 葱, 土豆 } → { 汉堡包 } 。
另一个典型的案例是啤酒与尿布的故事,你可能已经在机器学习有关课程中听过。一项超市 顾客购物行为分析指出:购买尿布的顾客(大概是年轻男士)往往也会购买啤酒。这立刻成为一 个流行的例子,用来说明如何从每日数据中找到意想不到的关联规则。然而,对于这个故事的真 实性,人们持有不同看法。丹尼尔·鲍尔斯说(DSS 新闻, 2002 ):
“ 1992 年, Thomas Blischok (天睿公司零售业顾问团经理)和他的团队成员打算对 120万个购物篮数据进行分析,这些数据来自大约 25 家 Osco Drug 商店。他们对数据库查 询做了改动,使之可以对商品之间的关联进行识别。分析结果指出:下午5:00~7:00 的确 发现消费者同时购买了啤酒与尿布。但Osco 的经理们没有利用啤酒与尿布之间的关系, 并且也没有把它们摆放在一起。”
除了上面这个来自 MBA 的例子之外,现在关联规则也被应用于许多领域,包括网络使用挖 掘、入侵检测、连续生产、生物信息学。
基本概念
交易数据库
关联规则挖掘中,数据集的结构与第 1 章使用的那些数据集的结构略有不同。首先,数据集中没有类值(class value ),学习关联规则时不需要它。其次,数据集表现为一个交易表单,每个 超市商品对应于一个二元属性。因此,特征向量可能会非常大。
请思考下面这个例子。假设我们有 4 张收据,如图 所示。每个收据对应于一笔购物交易。

为了以交易数据库的形式写出这些收据,首先要识别出现在收据上的所有商品,这些商品有 洋葱、土豆、汉堡包、啤酒与勺子。每一次购物(交易)写在一行中,若交易中购买了某个商品, 就将其标为1 ,否则标为 0 ,如表:

这个示例包含的交易很少,只有 4 个。实际应用中,数据集通常包含几千或者几百万笔交易, 这使得学习算法可以从这些交易中发现显著的统计模式。
项目集与规则
项目集只是一组项目的集合,比如 { 洋葱 , 土豆 , 汉堡包 } 。规则由两个项目集 X 与 Y 组成,格式 为:X → Y 。
这表示一种模式,即观察项目集 X 时,也会观察项目集 Y 。为了选择有趣的规则,你可以使用 各种有意义的度量方法。
支持度
对某个项目集而言,支持度指包含该项目集的交易在总交易中所占的比例。比如前面表格中 的{ 土豆 , 汉堡包 } 项目集,它的支持度是 50% ,即它在 50% 的交易中出现。总交易数为 4 ,包含 { 土 豆, 汉堡包 } 项目集的交易有两笔,所以 supp({ 土豆 , 汉堡包 }) = 2/4 = 0.5 。
直观地说,支持度表示总交易中有多少笔交易支持这个模式。
置信度
一个规则的置信度指其准确度,其定义如下:
Conf(X → Y)=supp(X ∪ Y)/supp(X)
比如,前面表格中, { 洋葱 , 汉堡包 } → { 啤酒 } 规则的置信度为 0.5/0.5=1.0 , 100% 表示购买洋 葱与汉堡包的顾客也会同时购买啤酒。
Apriori 算法
Apriori 算法十分经典,用于频繁模式挖掘与基于事务的关联规则学习。通过在数据库中找 出单独的频繁项,并将之扩展到更大的项集,Apriori 算法能够产生关联规则,突出数据库的总 体趋势。
Apriori 算法先创建一组项目集,比如项目集 1={ 项目 A, 项目 B} ,并且计算支持度,即计算它 在数据库中出现的次数。然后Apriori 算法使用自下而上的方法对频繁项集做扩展,一次一项。它 工作时会消去最大集合,把更小一点的集合作为候选,并且认识到一个大集合不可能是频繁的, 除非它的所有子集都是频繁集。找不到更多扩展时,算法即停止。 虽然Apriori 算法是机器学习中的一个重要里程碑,但它仍然存在一些效率不佳与权衡取舍的 问题。接下来学习更新的FP- 增长算法。
FP-增长算法
FP- 增长( FP , 频繁模式 )算法中,将交易数据库表示为一个前缀树。首先,在算法数据集 中计算数据项出现的次数。第二步中,算法创建前缀树,它是一个有序树数据结构,通常用于存 储字符串。使用前缀树表示前面例子,如图 所示。
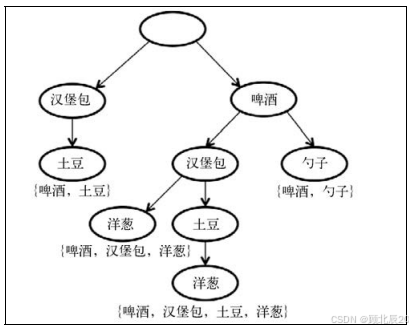
如果许多事务共享大部分频繁项,那么前缀树就会产生很高的压缩效果,几乎压到树根。大 项目集直接增长,不会产生候选项,也不会对整个数据库测试它们。增长从树底部开始,通过匹 配最小支持度与置信度查找所有项目集。一旦递归过程结束,所有带有最小覆盖率的大项目集就 会被找到,并开始创建关联规则。
FP- 增长算法有几个优点:首先,它创建一个 FP 树,使用非常紧凑的表示形式对原数据集进 行编码;其次,它能够有效创建频繁项目集,并且可以充分利用FP 树结构 与 分而治之 的策略。
超市数据集
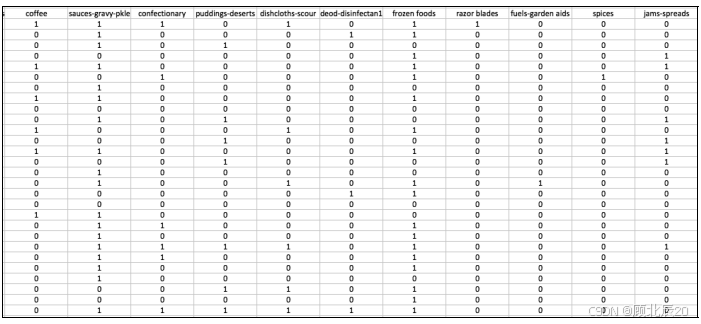
supermarket.arff,它描述了超市顾客的购物习惯。大部分属性表示一个特定的商品组,比如乳制品、牛肉、土豆;或者部门,比如部门79、部门81等。下图显示了数据库的一个片段,如果顾客购买了某件商品,就将其标为1,否则标为0。其中,每一个客户就是一个实例。数据集不包含类属性(class attribute),学习关联规则时并不需要它。
发现模式
下面,使用前面学过的两种算法( Apriori 算法与 FP- 增长算法)发现购物模式。
Apriori 算法案例
首先,使用已经在 Weka 中实现的 Apriori 算法。该算法不断减小最小支持度,直到找到所需 的规则数,它带有给定的最小置信度。
其次,加载超市数据集。
接着,初始化 Apriori 实例,调用 buildAssociations(Instances) 函数,开始频繁模式挖 掘。
最后,输出发现的项目集与规则。
//加载数据
Instances data=new Instances(new BufferedReader(new FileReader(PATH)));
//初始化Apriori实例,开始频繁挖掘数据
Apriori apriori=new Apriori();
apriori.buildAssociations(data);
System.out.println(apriori);
输出结果如下:
Apriori
=======
Minimum support: 0.15 (694 instances)
Minimum metric <confidence>: 0.9
Number of cycles performed: 17
Generated sets of large itemsets:
Size of set of large itemsets L(1): 44
Size of set of large itemsets L(2): 380
Size of set of large itemsets L(3): 910
Size of set of large itemsets L(4): 633
Size of set of large itemsets L(5): 105
Size of set of large itemsets L(6): 1
Best rules found:
1. biscuits=t frozen foods=t fruit=t total=high 788 ==> bread and cake=t 723 <conf:(0.92)> lift:(1.27) lev:(0.03) [155] conv:(3.35)
2. baking needs=t biscuits=t fruit=t total=high 760 ==> bread and cake=t 696 <conf:(0.92)> lift:(1.27) lev:(0.03) [149] conv:(3.28)
3. baking needs=t frozen foods=t fruit=t total=high 770 ==> bread and cake=t 705 <conf:(0.92)> lift:(1.27) lev:(0.03) [150] conv:(3.27)
4. biscuits=t fruit=t vegetables=t total=high 815 ==> bread and cake=t 746 <conf:(0.92)> lift:(1.27) lev:(0.03) [159] conv:(3.26)
5. party snack foods=t fruit=t total=high 854 ==> bread and cake=t 779 <conf:(0.91)> lift:(1.27) lev:(0.04) [164] conv:(3.15)
6. biscuits=t frozen foods=t vegetables=t total=high 797 ==> bread and cake=t 725 <conf:(0.91)> lift:(1.26) lev:(0.03) [151] conv:(3.06)
7. baking needs=t biscuits=t vegetables=t total=high 772 ==> bread and cake=t 701 <conf:(0.91)> lift:(1.26) lev:(0.03) [145] conv:(3.01)
8. biscuits=t fruit=t total=high 954 ==> bread and cake=t 866 <conf:(0.91)> lift:(1.26) lev:(0.04) [179] conv:(3)
9. frozen foods=t fruit=t vegetables=t total=high 834 ==> bread and cake=t 757 <conf:(0.91)> lift:(1.26) lev:(0.03) [156] conv:(3)
10. frozen foods=t fruit=t total=high 969 ==> bread and cake=t 877 <conf:(0.91)> lift:(1.26) lev:(0.04) [179] conv:(2.92)
这个算法根据置信度输出 10 个最佳规则。先看第一个规则,并对输出进行解释,如下所示:
1. biscuits=t frozen foods=t fruit=t total=high 788 ==> bread and cake=t 723 <conf:(0.92)> lift:(1.27) lev:(0.03) [155] conv:(3.35)
上述规则表明:顾客同时购买饼干、冷冻食品与水果且总价较高时,很有可能也会购买面包 与蛋糕。{ 饼干 , 冷冻食品 , 水果 , 总购买价格高 } 项目集出现在 788 笔交易中,而 { 面包 , 蛋糕 } 项目集出现在723 笔交易中。这个规则的置信度为 0.92 ,表示其在 92% 的交易中都适用,即出现 {饼干 , 冷冻食品 , 水果 , 总购买价格高 } 项目集。
输出结果也显示了其他指标,比如提升度( lift )、杠杆率( leverage )、确信度( conviction ), 用于评估相对于最初假设的准确程度。比如确信度为3.35 ,表示在关联完全随机的情形下,规 则不正确的可能性将是平常的3.35 倍。提升度表示 X 与 Y 相比于预期同时出现的次数,前提是它 们是统计独立的(lift=1 )。 X → Y 规则中,提升度为 2.16 表示 X 的几率比 Y 的几率大 2.16 倍。
FP-增长算法案例
下面尝试使用更有效率的 FP- 增长算法得到一样的结果。 FP- 增长算法也是在 weka. associations包中实现的。
就像我们前面所做的那样,首先对 FP- 增长算法进行初始化。
//加载数据
Instances data=new Instances(new BufferedReader(new FileReader(PATH)));
//初始化FPGrowth实例,开始频繁挖掘数据
FPGrowth fpgrowth=new FPGrowth();
fpgrowth.buildAssociations(data);
System.out.println(fpgrowth);
输出结果表明 FP- 增长算法发现了 16 个规则 :
FPGrowth found 16 rules (displaying top 10)
1. [fruit=t, frozen foods=t, biscuits=t, total=high]: 788 ==> [bread and cake=t]: 723 <conf:(0.92)> lift:(1.27) lev:(0.03) conv:(3.35)
2. [fruit=t, baking needs=t, biscuits=t, total=high]: 760 ==> [bread and cake=t]: 696 <conf:(0.92)> lift:(1.27) lev:(0.03) conv:(3.28)
3. [fruit=t, baking needs=t, frozen foods=t, total=high]: 770 ==> [bread and cake=t]: 705 <conf:(0.92)> lift:(1.27) lev:(0.03) conv:(3.27)
4. [fruit=t, vegetables=t, biscuits=t, total=high]: 815 ==> [bread and cake=t]: 746 <conf:(0.92)> lift:(1.27) lev:(0.03) conv:(3.26)
5. [fruit=t, party snack foods=t, total=high]: 854 ==> [bread and cake=t]: 779 <conf:(0.91)> lift:(1.27) lev:(0.04) conv:(3.15)
6. [vegetables=t, frozen foods=t, biscuits=t, total=high]: 797 ==> [bread and cake=t]: 725 <conf:(0.91)> lift:(1.26) lev:(0.03) conv:(3.06)
7. [vegetables=t, baking needs=t, biscuits=t, total=high]: 772 ==> [bread and cake=t]: 701 <conf:(0.91)> lift:(1.26) lev:(0.03) conv:(3.01)
8. [fruit=t, biscuits=t, total=high]: 954 ==> [bread and cake=t]: 866 <conf:(0.91)> lift:(1.26) lev:(0.04) conv:(3)
9. [fruit=t, vegetables=t, frozen foods=t, total=high]: 834 ==> [bread and cake=t]: 757 <conf:(0.91)> lift:(1.26) lev:(0.03) conv:(3)
10. [fruit=t, frozen foods=t, total=high]: 969 ==> [bread and cake=t]: 877 <conf:(0.91)> lift:(1.26) lev:(0.04) conv:(2.92)
可以看到,用 FP- 增长算法找到的规则与 Apriori 算法差不多是一样的。但处理大型数据集时, 使用FP- 增长算法需要的时间明显更短,执行效率更高。
完整代码
public static String PATH= ClassUtils.getDefaultClassLoader().getResource("supermarket.arff").getPath();
public static void main(String[] args) throws Exception{
//加载数据
Instances data=new Instances(new BufferedReader(new FileReader(PATH)));
//初始化Apriori实例,开始频繁挖掘数据
Apriori apriori=new Apriori();
apriori.buildAssociations(data);
System.out.println(apriori);
//初始化FPGrowth实例,开始频繁挖掘数据
FPGrowth fpgrowth=new FPGrowth();
fpgrowth.buildAssociations(data);
System.out.println(fpgrowth);
}在其他领域中的应用
上面介绍了关联分析在揭示超市顾客购物行为模式方面的应用。尽管关联规则学习根植于对 销售点的交易分析,但它也可以应用于零售业之外的其他领域,用来在其他类型的“购物篮”中 寻找关联。“购物篮”这个概念可以很容易地扩展到服务与产品,比如分析使用信用卡购买的服 务,像租车、租房;又比如分析与电信用户购买的增值服务相关的信息(呼叫等待、呼叫转移、 DSL、缩位拨号等),这可以帮助运营商决定如何改进他们提供的服务包。
接下来,了解如下这些跨行业应用的例子:
医疗诊断
蛋白质序列
人口普查
客户关系管理
IT 运营分析
医疗诊断
医疗诊断中,关联规则可以辅助医生对患者进行治疗。诊疗过程中一个常见的难题是,很难 归纳出可靠的诊断规则。从理论上说,归纳过程不能完全保证归纳假设本身的正确性。事实上, 诊断过程本身不是一个轻松的事,因为它会涉及不可靠的诊断测试,而且训练样本中可能还存在 噪声问题。
尽管如此,我们仍然可以使用关联规则识别可能同时出现的症状。这种应用情景中,一个事务 对应于一个医疗案例,而症状对应于项目。治疗病人时会记录一系列症状,它们一起组成一个事务。
蛋白质序列
有关蛋白质的大量研究已经深入到了解其组成与性质中来,然而还有许多方面有待人们认真 研究。现在普遍的共识是:蛋白质的氨基酸序列不是随机的。
借助关联规则,我们有可能识别同一个蛋白质中不同氨基酸之间的关联性。蛋白质序列由 20 种氨基酸组成。每种蛋白质拥有独一无二的三维结构,具体取决于氨基酸序列,序列中微小的改 变都会导致蛋白质功能发生变化。应用关联规则时,一种蛋白质对应于一个事务,氨基酸与其结 构对应于项目。
这些关联规则有助于加深我们对蛋白质组成的理解,有可能帮助我们在蛋白质的一些特殊的 氨基酸组中找到有关全球相互作用的线索。这些关联规则或约束的知识对于人工合成蛋白质非常 有用。
人口普查数据
人口普查产生大量与社会有关的统计信息,这些信息既可以提供给研究者使用,也可以提供 给普通大众。有关人口数量与经济普查的信息可以用在公共服务(教育、医疗、交通、基金)与 商业(设立新工厂、购物中心、银行甚至推销特定商品)规划中。
为了发现频繁模式,每个统计区域(比如自治区、城市、邻区)对应于一个事务,收集的指 标对应于项目。
客户关系管理
已经简单讨论过 客户关系管理 ( CRM ),它是一个富数据源,公司希望通过它找出不 同客户组对产品、服务的偏好,借此加强产品、服务、客户之间的黏合度。
关联规则能够强化知识管理流程,帮助营销人员更好地了解他们的客户,以便向客户提供更 优质的服务。比如,关联规则可以从客户资料与销售数据中检测客户在不同时间段行为的变化。 基本思想是从两个数据集找到变化,并从每个数据集产生规则进行规则匹配。
IT 运营分析
在大量事务记录基础之上,关联规则学习很适合用于分析每天 IT 运营定期收集的数据,启用 IT运营分析工具检测频繁模式并找到主要变化。 IT 专家需要查看总体运营情况,并了解某个问题 带来的影响,比如一个数据库的问题如何影响应用程序服务器。
在一个特殊的日子, IT 运营可能发现许多警报,并进一步发现它们来自一个事务数据库。此 情形下,使用关联规则学习算法后,IT 运营分析工具可以检测到同时出现这些警报的频繁模式。 这能帮助我们更好地了解组件之间是如何相互影响的。
借助发现的这些警告模式,可以进行预测分析。比如某个特定的数据库服务器中包含一个 Web应用程序,突然触发一个数据库警报。通过查看关联规则学习算法发现的频繁模式, IT 工作 人员可以采取相应措施,避免问题进一步影响Web 应用程序。
关联规则学习也能发现那些源自相同 IT 事件的警报事件。比如每次添加新用户时, Windows 操作系统中就会检测到6 个变化。接着,在 应用组合管理工具 ( Application Portfolio Management , APM)中, IT 可能面临多个警报,显示数据库中的事务时间为“高”。如果所有这些问题都来自 同一个源(比如几百个更改警报都是由Windows 更新引起的),那么这个频繁模式挖掘可以帮助 我们快速删减警报数量,让IT 运维人员专注于最关键的改变。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 29
29 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)