DDPM的基本原理(无公式版)
马尔可夫链定义本身比较简单,它假设某一时刻状态转移的概率只依赖于它的前一个状态。如果用精确的数学定义来描述,则假设我们的序列状态是。
DDPM 的基本原理
声明:这篇文章主要参考了扩散模型DDPM浅析和李宏毅(不是周宏毅 哈哈哈哈哈 太尴尬了)的课程李宏毅老师的Diffusion课程
写这篇博客的原因是在写其他博客的时候,就IP-Adapter的时候,发现要对Stable Diffusion要比较熟悉才能了解清楚IP-Adapter,
了解Stable Diffusion就要了解LDM. 要了解LDM就要先了解DDPM,我尝试下载原文去看看怎么回事。但是很遗憾,我概率论全忘了,
看不懂这篇论文(太多公式)
于是到处搜寻简单点的教程,于是结合知乎上的一篇文章和李宏毅老师的教学视频,终于弄懂了一些。
但是概率论还是必须得学,因为VAE的论文里面也全是概率论的公式。所以在AIGC这个领域,概率论的基础还是很重要了
(但是我已经4年没碰概率论了!!!)
但是没有数学公式的支撑,感觉还是很难去真正的了解Stable Diffusio,后续还是要继续补上
文章目录
一、李宏毅老师普适版本

Diffusion模型的核心机制始于一张从高斯分布中随机生成的噪声图像,这张噪声图像的维度与我们期望生成的图片完全一致。随后,一个关键组件——去噪网络(Denoise Network)介入这一过程。去噪网络的职责是逐步清除图像中的噪声成分,每一次迭代都旨在提升图像的清晰度。
通过连续应用去噪网络,我们逐步逆转了前向过程中添加的随机噪声,最终从混沌的噪声中恢复出一幅清晰的图像。这一过程模拟了物理世界中的扩散过程,其中噪声被视为需要被去除的“杂质”,而去噪网络则扮演了净化剂的角色。
在Diffusion模型中,去噪网络(Denoise Network)扮演着至关重要的角色。这个网络并不是一成不变的,它在生成过程的不同阶段承担着不同的任务。在模型的初始阶段,去噪网络面对的是一张几乎完全由噪声构成的图像,而在过程的最后阶段,它处理的则是一张已经能够辨认出具体内容(例如一只小猫)的图像。
去噪网络的关键特点在于它接收两个输入:一个是当前带有噪声的图像,另一个是代表噪声严重程度的参数,这个参数也可以被看作是去噪步骤的指标(step)。随着生成过程的进行,这个参数逐渐变化,指导网络如何逐步去除噪声,从而逐渐揭示出图像的真实内容。

去噪网络的内部结构,如上图所示,包含一个关键组件——噪声预测器(Noise Predictor)。这个噪声预测器接收两个输入:一张带有噪声的图像和一个表示噪声当前严重程度的参数,通常称为步骤参数(step parameter)。基于这些输入,噪声预测器的职责是预测并输出当前步骤中图像的噪声成分。
随后,通过将带噪声的图像减去预测出的噪声,我们可以得到一张噪声更少、更为清晰的图像。这个过程会在整个Diffusion模型的生成过程中不断重复,直到图像完全清晰。
至于为何不采用一个端到端(end-to-end)的模型直接从噪声生成一张清晰的图片,原因在于生成一张完整的图片与生成噪声的难度存在显著差异。直接生成一张清晰的图片在计算上更为复杂,且难度更高。相比之下,逐步预测并去除噪声的方法降低了模型在每一步中需要处理的信息量,使得整个生成过程更为可控和高效。

那么Noise Predicter是怎么训练过来的呢?这里的话其实就可以从数据库里面拿出一张图片,然后不断的加上从高斯分布中随机提取的noise,就可以得到不同step下的加过噪声的图片和step的大小,这样我们就有了训练Noise Predicter的原始数据。
二、知乎上的版本(难度大一些)
目前所采用的扩散模型大都是来自于2020年的工作DDPM: Denoising Diffusion Probabilistic Models,和GAN相比,DDPM拟合的是加噪图片,并通过反向过程(去噪)生成原始图片。而GAN通过判别器拟合原始图片,和DDPM有本质的区别。

图1中,GAN模型通过使得生成器(Generator)生成的图片 x ′ \mathbf{x}' x′ 尽可能逼近真实图片 x \mathbf{x} x,从而达到以假乱真的目的,本质上还是去生成和真实图片接近的新图片,因此GAN生成的图片可能没有太多亮点。而DDPM是拟合整个从真实图片 x 0 \mathbf{x}_0 x0 到随机高斯噪声 z \mathbf{z} z 的过程,再通过反向过程生成新的图片,和GAN有本质的区别。
2.1 DDPM模型原理
DPM包括两个过程:前向过程(forward process)和反向过程(reverse process),其中前向过程又称为扩散过程(diffusion process),如下图所示。无论是前向过程还是反向过程都是一个参数化的马尔可夫链(Markov chain),其中反向过程可以用来生成图片。

图2中,由高斯随机噪声 x T \mathbf{x}_T xT 生成原始图片 x 0 \mathbf{x}_0 x0 为反向过程,反之为前向过程。为了尽可能简化,我们主要介绍下前向过程、反向过程、DDPM如何训练、DDPM如何生成图片。
什么是马尔科夫链?
马尔可夫链定义本身比较简单,它假设某一时刻状态转移的概率只依赖于它的前一个状态。如果用精确的数学定义来描述,则假设我们的序列状态是 … X t − 2 , X t − 1 , X t , X t + 1 … \ldots X_{t-2},X_{t-1},X_t,X_{t+1}\ldots …Xt−2,Xt−1,Xt,Xt+1…,那么我们的在时刻 X t + 1 X_{t+1} Xt+1的状态的条件概率仅仅依赖于时刻 X t X_t Xt ,即:
P ( X t + 1 ∣ … X t − 2 , X t − 1 , X t ) = P ( X t + 1 ∣ X t ) P(X_{t+1}|\ldots X_{t-2},X_{t-1},X_t)=P(X_{t+1}|X_t) P(Xt+1∣…Xt−2,Xt−1,Xt)=P(Xt+1∣Xt)
马尔科夫链为状态空间中经过从一个状态到另一个状态的转换的随机过程,该过程要求具备“无记忆性 ”,即下一状态的概率分布只能由当前状态决定,在时间序列中它前面的事件均与之无关。这种特定类型的“无记忆性 ”称作马尔可夫性质,马尔科夫链认为过去所有的信息都被保存在了现在的状态下了
通过马尔科夫链的模型转换,我们可以将事件的状态转换成概率矩阵 (又称状态分布矩阵 )
状态转移矩阵有一个非常重要的特性,经过一定有限次数序列的转换,最终一定可以得到一个稳定的概率分布 ,且与初始状态概率分布无关
举个例子
一家店有汉堡 薯条 热狗三种食物 但是每天只有一种食物供应,并且食物的供应基于以下原则
如果今天供应的是薯条 就有0.5的概率明天继续供给薯条 0.5的概率供给汉堡 0.0的概率供给热狗
如果今天供应的是热狗 就有0.0的概率明天继续供给热狗 0.3的概率供给汉堡 0.7的概率供给薯条
如果今天供应的是汉堡 就有0.2的概率明天继续供给汉堡 0.2的概率供给薯条 0.6的概率供给热狗,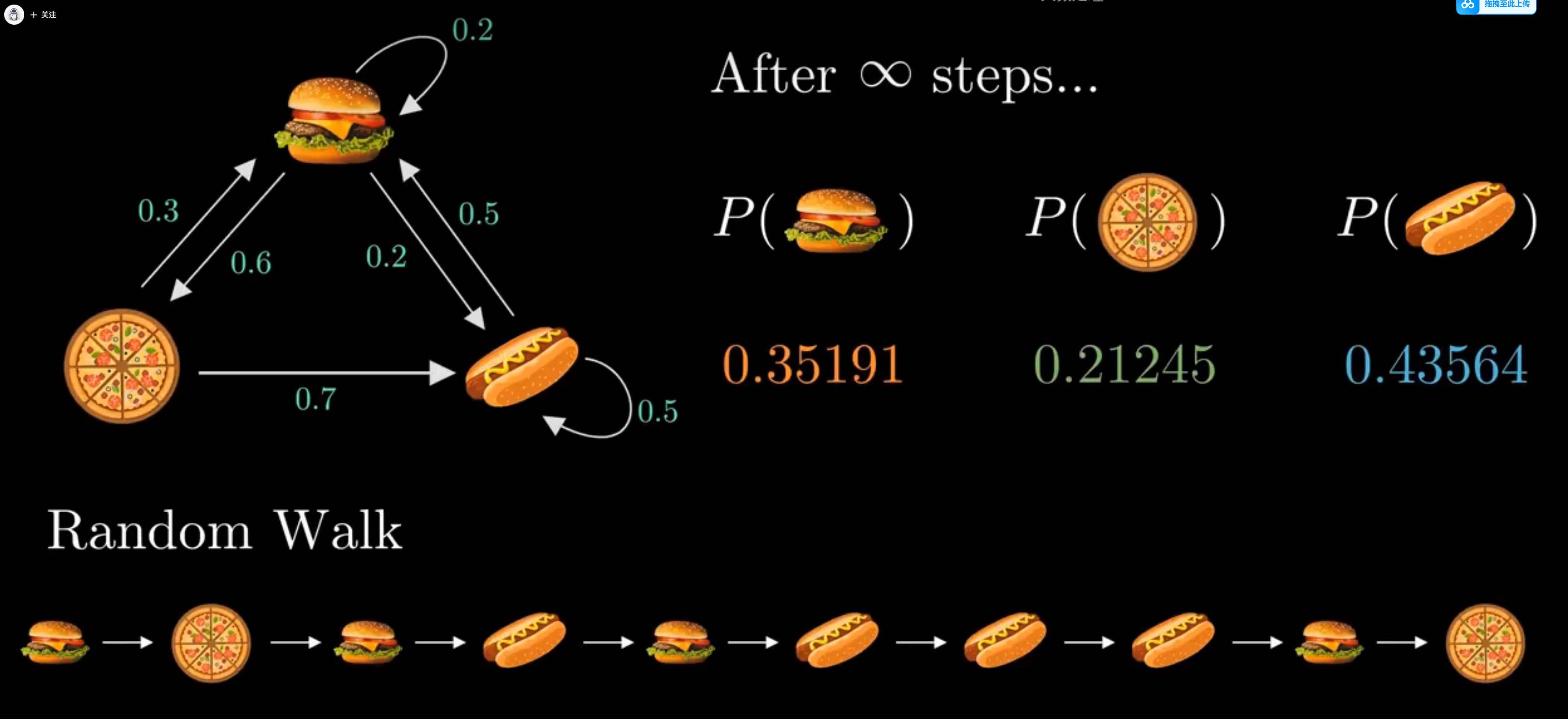
import numpy as np
# 定义转移概率矩阵
# 状态顺序: [汉堡, 薯条, 热狗]
transition_matrix = np.array([ ---->这个就是状态分布矩阵
[0.2, 0.2, 0.6], # 当前是汉堡
[0.5, 0.5, 0.0], # 当前是薯条
[0.3, 0.7, 0.0] # 当前是热狗
])
# 初始状态向量(今天供应的是汉堡)
initial_state = np.array([1, 0, 0]) # 汉堡的概率为 1,其他为 0
# 计算经过 10 天后的状态
days = 100000000000
final_state = initial_state @ np.linalg.matrix_power(transition_matrix, days)
# 输出结果
print("经过 10 天后,各种食物的供应概率:")
print(f"汉堡: {final_state[0]:.4f}")
print(f"薯条: {final_state[1]:.4f}")
print(f"热狗: {final_state[2]:.4f}")

可以发现,从第 10 轮开始,我们的状态概率分布就不变了,一直保持[ 0.3521 , 0.4366 , 0.2113 ]
2.2 DDPM前向过程(扩散过程)
一句话概括,前向过程就是对原始图片 x 0 \mathbf{x}_0 x0 不断加高斯噪声最后生成随机噪声 x T \mathbf{x}_T xT 的过程,如下图所示(图片来自于网络)。
由 x t − 1 \mathbf{x}_{t-1} xt−1到 x t \mathbf{x}_t xt可以表示为:
x t = α t x t − 1 + 1 − α t ϵ t − 1 \mathbf{x}_t=\sqrt{\alpha_t}\mathbf{x}_{t-1}+\sqrt{1-\alpha_t}\boldsymbol{\epsilon}_{t-1} xt=αtxt−1+1−αtϵt−1
其中 α t \alpha_t αt是一个很小值的超参数 + ^{+} +, ϵ t − 1 ∼ N ( 0 , 1 ) \boldsymbol{\epsilon}_{t-1}\sim N\left(0,1\right) ϵt−1∼N(0,1)是高斯噪声。由公式 (1)推导,最终可以得到 x 0 \mathbf{x}_0 x0到 x t \mathbf{x}_t xt的公式,表示如下:
x t = α ˉ t x 0 + 1 − α ˉ t ϵ \mathbf{x}_t=\sqrt{\bar\alpha_t}\mathbf{x}_0+\sqrt{1-\bar\alpha_t}\boldsymbol{\epsilon} xt=αˉtx0+1−αˉtϵ
其中 α ˉ t = ∏ i = 1 t α i \bar{\alpha}_t=\prod_{i=1}^t\alpha_i αˉt=∏i=1tαi , ϵ ∼ N ( 0 , 1 ) \boldsymbol{\epsilon}\sim N\left(0,1\right) ϵ∼N(0,1)也是一个高斯噪声。有了公式 (2),便可以由输入图片 x 0 \mathbf{x}_0 x0直接生成随机噪声。
2.3 DDPM反向过程(去燥过程)
前向过程是将原始图片变成随机噪声,而反向过程就是通过预测噪声 ϵ \boldsymbol{\epsilon} ϵ,将随机噪声 x t \mathbf{x}_t xt 逐步还原为原始图片 x 0 \mathbf{x}_0 x0 ,如下图所示。
反向过程公式表示如下:
x t − 1 = 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ θ ( x t , t ) ) + σ t z \mathbf{x}_{t-1}=\frac{1}{\sqrt{\alpha_t}}\bigg(\mathbf{x}_t-\frac{1-\alpha_t}{\sqrt{1-\bar{\alpha}_t}}\boldsymbol{\epsilon}_\theta\:(\mathbf{x}_t,t)\bigg)+\sigma_t\mathbf{z} xt−1=αt1(xt−1−αˉt1−αtϵθ(xt,t))+σtz
其中 ϵ θ \epsilon_\mathrm{\theta} ϵθ 是噪声估计函数(一般使用NN模型),用于估计真实噪声 ϵ \epsilon ϵ , θ \theta θ 是模型训练的参数 z ∼ N ( 0 , 1 ) \mathbf{z}\sim N\left(0,1\right) z∼N(0,1) , σ t z \sigma_t\mathbf{z} σtz 表示的是预测噪声和真实噪声的误差。DDPM的关键就是训练噪声估计模型 ϵ θ ( x t , t ) \epsilon_\theta\left(\mathbf{x}_t,t\right) ϵθ(xt,t) ,用于估计真实的噪声 ϵ \epsilon ϵ 。
2.4 DDPM如何训练
前面提到DDPM的关键是训练噪声估计模型 ϵ θ ( x t , t ) \epsilon_\theta\left(\mathbf{x}_t,t\right) ϵθ(xt,t) ,用于估计 ϵ \boldsymbol{\epsilon} ϵ ,那么损失函数可以使用MSE误差,表示如下:
L o s s = ∥ ϵ − ϵ θ ( x t , t ) ∥ 2 = ∥ ϵ − ϵ θ ( α ˉ t x t − 1 + 1 − α ˉ t ϵ , t ) ∥ 2 Loss=\left\|\boldsymbol{\epsilon}-\boldsymbol{\epsilon}_\theta\left(\mathbf{x}_t,t\right)\right\|^2=\left\|\boldsymbol{\epsilon}-\boldsymbol{\epsilon}_\theta\left(\sqrt{\bar{\alpha}_t}\mathbf{x}_{t-1}+\sqrt{1-\bar{\alpha}_t}\boldsymbol{\epsilon},t\right)\right\|^2 Loss=∥ϵ−ϵθ(xt,t)∥2= ϵ−ϵθ(αˉtxt−1+1−αˉtϵ,t) 2
整个训练过程可以表示如下:

论文中的DDPM训练过程如下所示:

跟着李宏毅老师的视频来了解这个过程:
-
不断重复这个过程:这个步骤描述了算法的迭代性质,意味着这个过程会多次执行以优化模型参数。
-
从图像数据库里面sample一张图片(clean image):这一步是从数据集中随机选择一张未加噪声的图像。
-
从1-T之间Sample一个整数t(一般比较大):这一步是从1到T(T是一个预定义的步数)之间随机选择一个时间步长t。较大的t值意味着我们正在查看向数据添加更多噪声的阶段。
-
从一个正态分布里Sample一个噪声(大小和上面的clean image的维度一致):这一步是生成一个与选定的干净图像具有相同维度的随机噪声向量。
-
计算梯度并进行优化:这一步涉及计算损失函数相对于模型参数θ的梯度,并使用这个梯度来更新模型参数。损失函数是噪声向量与模型预测的噪声向量之间的平方误差。
∇ θ ∥ ϵ − ϵ θ ( α ˉ t x 0 + 1 − α ˉ t ϵ , t ) ∥ 2 \nabla_\theta\left\|\boldsymbol{\epsilon}-\boldsymbol{\epsilon}_\theta(\sqrt{\bar{\alpha}_t}\mathbf{x}_0+\sqrt{1-\bar{\alpha}_t}\boldsymbol{\epsilon},t)\right\|^2 ∇θ ϵ−ϵθ(αˉtx0+1−αˉtϵ,t) 2-
α ˉ t \bar{\alpha}_t αˉt参数:这些参数是预先定义的,用于控制从数据中添加噪声的比例。随着t的增加, α ˉ t \bar{\alpha}_t αˉt减小,意味着添加的噪声量增加。
-
α ˉ t x 0 + 1 − α ˉ t ϵ \sqrt{\bar{\alpha}_t}\mathbf{x}_0+\sqrt{1-\bar{\alpha}_t}\boldsymbol{\epsilon} αˉtx0+1−αˉtϵ:这个表达式表示一个中间步骤,其中干净图像 x 0 \mathbf{x}_0 x0与噪声 ϵ \boldsymbol{\epsilon} ϵ结合,噪声的比例由 1 − α ˉ t \sqrt{1-\bar{\alpha}_t} 1−αˉt控制。
-
ϵ θ ( α ˉ t x 0 + 1 − α ˉ t ϵ , t ) \boldsymbol{\epsilon}_\theta(\sqrt{\bar{\alpha}_t}\mathbf{x}_0+\sqrt{1-\bar{\alpha}_t}\boldsymbol{\epsilon},t) ϵθ(αˉtx0+1−αˉtϵ,t):这表示噪声预测器,它接受一个加噪声的图像和一个时间步长t作为输入,并预测相应的噪声。
-
∇ θ ∣ ϵ − ϵ θ ( α ˉ t x 0 + 1 − α ˉ t ϵ , t ) ∣ 2 \nabla_\theta\left|\boldsymbol{\epsilon}-\boldsymbol{\epsilon}_\theta(\sqrt{\bar{\alpha}_t}\mathbf{x}_0+\sqrt{1-\bar{\alpha}_t}\boldsymbol{\epsilon},t)\right|^2 ∇θ ϵ−ϵθ(αˉtx0+1−αˉtϵ,t) 2:这是损失函数的梯度,它衡量实际噪声 ϵ \boldsymbol{\epsilon} ϵ与模型预测的噪声之间的差异。目标是最小化这个差异,从而训练模型更准确地预测噪声。
-


2.5 DDPM如何生成图片
在得到预估噪声 ϵ θ ( x t , t ) 后,就可以按公式(3)逐步得到最终的图片 x 0 ,整个过程表示如下 \begin{aligned}&\text{在得到预估噪声 }\boldsymbol{\epsilon}_\theta\left(\mathbf{x}_t,t\right)\text{后,就可以按公式(3)逐步得到最终的图片 }\mathbf{x}_0\text{,整个过程表示如下}\end{aligned} 在得到预估噪声 ϵθ(xt,t)后,就可以按公式(3)逐步得到最终的图片 x0,整个过程表示如下
根据李宏毅老师的视频来理解这个过程:(通过这张图可以Sample的过程一目了然)
这里补充一下这次组会中提出的两个问题: 为什么要在Sampling的添加过程中。减去了预测的一个噪声,又要重新再引入一个新的噪声
(大致的话,引入这个噪声是为了生成图片的多样性可能会丰富一些,提高模型的泛化性)
第二个问题的话就是 为什么选择在高斯分布去采集噪声?
三、LDM 的基本原理

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)