【论文阅读】Learning Deep Intensity Field for Extremely Sparse-View CBCT Reconstruction
稀疏视图锥束CT(CBCT)重建是减少辐射剂量并促进临床应用的重要方向。以往基于体素的生成方法将CT表示为离散的体素,这会导致高内存需求并由于使用3D解码器而限制了空间分辨率。本文将CT体积建模为连续的强度场,并提出了一种新型的DIF-Net(深度强度场网络),能够从极度稀疏的(≤10个)投影视图中,以超快的速度执行高质量的CBCT重建。CT的强度场可以看作是3D空间点的连续函数。因此,重建问题可

用于极度稀疏视图CBCT重建的深度强度场学习
引用:Lin Y, Luo Z, Zhao W, et al. Learning deep intensity field for extremely sparse-view CBCT reconstruction[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer Nature Switzerland, 2023: 13-23.
论文地址:下载地址
代码地址:https://github.com/xmed-lab/DIF-Net—(未公布数据集)
Abstract
稀疏视图锥束CT(CBCT)重建是减少辐射剂量并促进临床应用的重要方向。以往基于体素的生成方法将CT表示为离散的体素,这会导致高内存需求并由于使用3D解码器而限制了空间分辨率。本文将CT体积建模为连续的强度场,并提出了一种新型的DIF-Net(深度强度场网络),能够从极度稀疏的(≤10个)投影视图中,以超快的速度执行高质量的CBCT重建。CT的强度场可以看作是3D空间点的连续函数。因此,重建问题可以重新表述为从给定的稀疏投影中回归任意3D点的强度值。具体而言,对于每个点,DIF-Net从不同的2D投影视图中提取该点的视图特定特征。这些特征随后通过融合模块进行汇总,从而进行强度估计。值得注意的是,DIF-Net能够并行处理成千上万个点,从而提高训练和测试的效率。在实际应用中,我们收集了一个膝关节CBCT数据集来训练和评估DIF-Net。大量实验表明,我们的方法能够在1.6秒内从极度稀疏的视图中重建出高质量、高空间分辨率的CBCT图像,显著优于现有的最先进方法。我们的代码将发布在GitHub上。
1. Introduction
锥束计算机断层扫描(CBCT)是一种常用的三维成像技术,广泛用于以高空间分辨率和快速扫描速度检查物体的内部结构1。在CBCT扫描过程中,扫描仪围绕物体旋转并发射锥形射线,获取检测面板上的二维投影以重建三维体积。近年来,除了牙科应用外,CBCT还被广泛用于获取人体膝关节的图像,应用包括全膝关节置换术和术后疼痛管理2 3 4 5。为了保持图像质量,CBCT通常需要数百个投影,并涉及高剂量的X射线辐射,这在临床实践中可能引发关注。稀疏视图重建是减少辐射剂量的一种方式,通过减少扫描视图的数量(减少10倍)来降低辐射剂量。本文研究了一个更具挑战性的问题——极度稀疏视图的CBCT重建,旨在从少于10个投影视图中重建高质量的CT体积。 图1. (a-b): 常规CT与锥束CT扫描的比较。 (c-d): 从一堆稀疏的二维投影重建CBCT。
图1. (a-b): 常规CT与锥束CT扫描的比较。 (c-d): 从一堆稀疏的二维投影重建CBCT。
与传统CT(例如平行束、扇形束)相比,CBCT从二维投影重建三维体积,而不是从一维投影重建二维切片,如图1所示。这导致了空间维度和计算复杂度的显著增加。因此,尽管稀疏视图的传统CT重建6 7 8 9已经发展多年,但这些方法不能简单地扩展到CBCT。CBCT重建可以根据所需的投影视图数量分为密集视图(≥100)、稀疏视图(20∼50)、极度稀疏视图(≤10)和单视图/正交视图重建。密集视图重建的典型例子是FDK10,它是一种滤波反投影(FBP)算法,通过从二维视图反向投影来累积强度,但需要数百个视图以避免条纹伪影。为了减少所需的投影视图,ART11及其扩展(例如SART12,VW-ART13)将重建过程公式化为迭代最小化过程,在投影有限时非常有用。然而,这些方法通常需要较长的计算时间才能收敛,并且在应对极度稀疏的投影时表现较差;请参见表1中SART的结果。随着深度学习技术和计算设备的发展,基于学习的方法被提出用于CBCT稀疏视图重建。Lahiri等人14提出用FDK重建粗略的CT,并使用2D卷积神经网络(CNN)去噪每一张切片。然而,该算法尚未在医学数据集上验证,且由于FDK引入了大量条纹伪影,性能仍然有限。最近,神经渲染技术15 16 17 18 19被引入,通过将衰减系数字段参数化为隐式神经表示场(NeRF)来重建CBCT体积,但由于缺乏先验知识,这些方法在每个病人的优化过程中需要较长时间,并且在极度稀疏视图下表现较差;请参见表2中NAF的结果。对于单视图/正交视图重建,基于体素的方法20 21 22提出了构建由2D编码器和3D解码器组成的二维到三维生成网络,这些网络具有大量的训练参数,导致高内存需求和有限的空间分辨率。这些方法是具有特殊设计的网络20 22或病人特定训练数据21,因此难以扩展到一般的稀疏视图重建。
 表1. DIF-Net与先前方法在PSNR(分贝)和SSIM度量下的比较。我们评估了不同输出分辨率(Res.)和不同投影视图数量(K)的重建结果。
表1. DIF-Net与先前方法在PSNR(分贝)和SSIM度量下的比较。我们评估了不同输出分辨率(Res.)和不同投影视图数量(K)的重建结果。
在本工作中,我们的目标是从极度稀疏(≤10)个二维投影视图中重建具有高图像质量和高空间分辨率的CBCT,这是一个重要且具有挑战性的、尚未被充分研究的稀疏视图CBCT重建问题。与以往将CT表示为离散体素的体素方法不同,我们将CT体积建模为连续的强度场,这可以看作是3D空间点的连续函数 g ( ⋅ ) g(\cdot) g(⋅)。该场中点 p p p 的属性表示其强度值 v v v,即 v = g ( p ) v = g(p) v=g(p)。因此,重建问题可以重新表述为从一堆二维投影 I I I 中回归任意3D点的强度值,即 v = g ( I , p ) v = g(I, p) v=g(I,p)。
基于上述公式化方法,我们开发了一种新的重建框架,即 DIF-Net(深度强度场网络)。具体而言,DIF-Net首先从给定的 K K K 个二维投影中提取特征图。对于每个3D点,我们根据相应的成像参数(如距离、角度等)将该点投影到每个视图的二维成像面板上,并从视图 i i i 的特征图中查询其视图特定的特征。然后,来自不同视图的 K K K 个视图特定特征通过跨视图融合模块进行聚合,以进行强度回归。通过引入连续强度场,使得使用稀疏采样点集来训练DIF-Net成为可能,从而减少内存需求,并在测试时以任何所需的分辨率重建CT体积。
与基于NeRF的方法 15 16 17 18 19 相比,DIF-Net的设计共享了类似的数据表示(即隐式神经表示),但可以引入额外的训练数据来帮助DIF-Net学习先验知识。得益于此,DIF-Net不仅能够在极短的时间内重建高分辨率的CT图像,因为对新测试样本只需要推理(无需重新训练),而且在极度稀疏视图下的表现远超基于NeRF的方法。
总之,本工作的主要贡献包括:
- 我们首次引入连续强度场用于有监督的CBCT重建;
- 我们提出了一个新型的重建框架DIF-Net,该框架能够在1.6秒内从极度稀疏(≤10)视图中重建具有高图像质量(PSNR: 29.3 dB,SSIM: 0.92)和高空间分辨率(≥256³)的CBCT;
- 我们通过广泛的实验验证了所提出的稀疏视图CBCT重建方法在临床膝关节CBCT数据集上的有效性。
2 Method
2.1 Intensity Field
我们将CT体积建模为一个连续的强度场,其中3D点 p ∈ R 3 p \in \mathbb{R}^3 p∈R3 在该场中的属性表示其强度值 v ∈ R v \in \mathbb{R} v∈R。强度场可以定义为一个连续函数 g : R 3 → R g : \mathbb{R}^3 \to \mathbb{R} g:R3→R,使得 v = g ( p ) v = g(p) v=g(p)。因此,重建问题可以重新表述为从 K K K 个投影 I = { I 1 , I 2 , … , I K } I = \{I_1, I_2, \dots, I_K\} I={I1,I2,…,IK} 中回归3D空间中任意点 p p p 的强度值,即 v = g ( I , p ) v = g(I, p) v=g(I,p)。
基于上述公式化方法,我们提出了一个新型的重建框架,称为 DIF-Net,用于执行高效的稀疏视图CBCT重建,框架概述如图2所示。
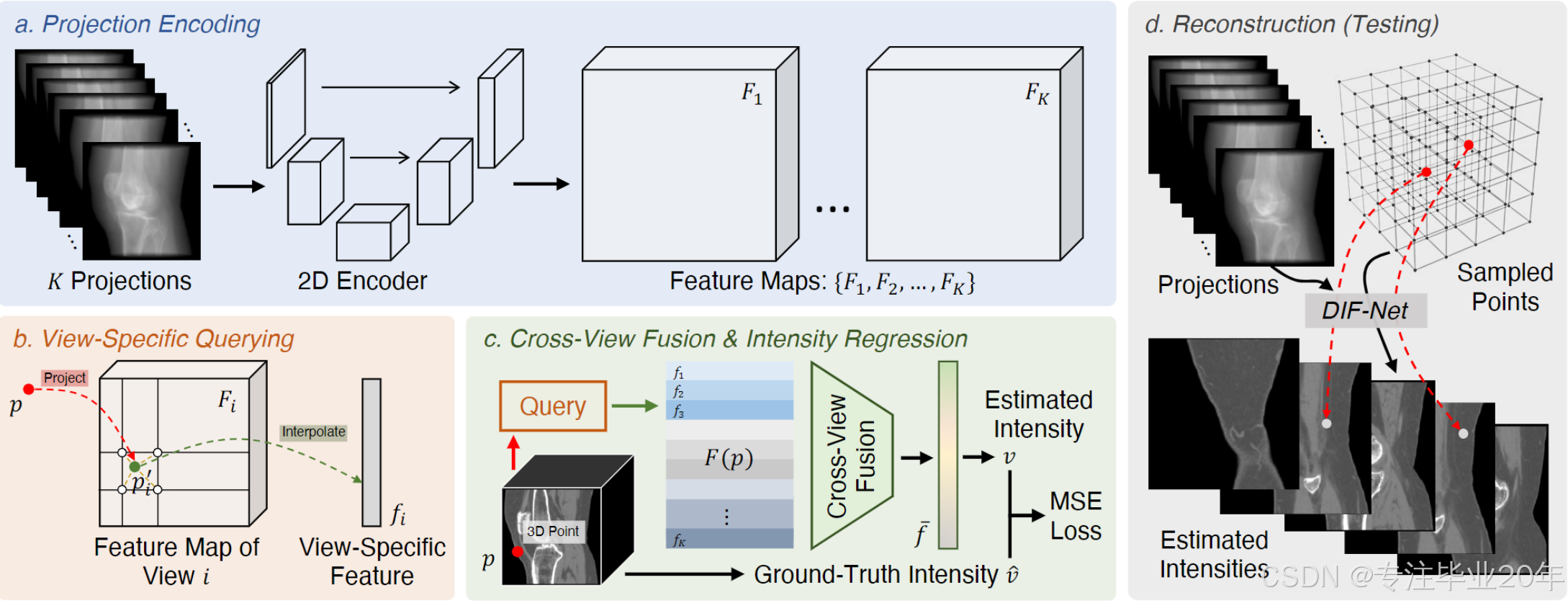 图2. DIF-Net概述。 (a) 给定 K K K 个投影,使用共享的2D编码器进行特征提取。 (b) 对于3D空间中的一个点 p p p,通过投影和插值从不同视图的特征图中查询其视图特定的特征。 © 查询到的特征被聚合以估计点 p p p 的强度值。 (d) 在测试过程中,给定输入投影,DIF-Net对在3D空间中均匀采样的点预测强度值,从而重建目标CT图像。
图2. DIF-Net概述。 (a) 给定 K K K 个投影,使用共享的2D编码器进行特征提取。 (b) 对于3D空间中的一个点 p p p,通过投影和插值从不同视图的特征图中查询其视图特定的特征。 © 查询到的特征被聚合以估计点 p p p 的强度值。 (d) 在测试过程中,给定输入投影,DIF-Net对在3D空间中均匀采样的点预测强度值,从而重建目标CT图像。
2.2 DIF-Net: Deep Intensity Field Network
DIF-Net首先使用共享的2D编码器从投影 I I I 中提取特征图 { F 1 , F 2 , … , F K } ⊂ R C × H × W \{F_1, F_2, \dots, F_K\} \subset \mathbb{R}^{C \times H \times W} {F1,F2,…,FK}⊂RC×H×W,其中 C C C 是特征通道数, H / W H/W H/W 是高度/宽度。在实际应用中,我们选择 U-Net 23 作为2D编码器,因为它具有良好的特征提取能力,并且在医学图像分析中有广泛应用 24。然后,给定一个3D点,DIF-Net从不同视图的特征图中查询其视图特定特征进行强度回归。
2.2.1 视图特定特征查询
考虑一个3D空间中的点 p ∈ R 3 p \in \mathbb{R}^3 p∈R3,对于具有扫描角度 α i \alpha_i αi 和其他成像参数 β \beta β(如距离、间距等)的投影视图 i i i,我们将点 p p p 投影到视图 i i i 的二维成像面板上,并获得其二维投影坐标 p i ′ = ϕ ( p , α i , β ) ∈ R 2 p'_i = \phi(p, \alpha_i, \beta) \in \mathbb{R}^2 pi′=ϕ(p,αi,β)∈R2,其中 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅) 是投影函数。投影坐标 p i ′ p'_i pi′ 用于从视图 i i i 的2D特征图 F i F_i Fi 中查询视图特定特征 f i ∈ R C f_i \in \mathbb{R}^C fi∈RC:
f i = π ( F i , p i ′ ) = π F i , ϕ ( p , α i , β ) , (1) f_i = \pi(F_i, p'_i) = \pi F_i, \phi(p, \alpha_i, \beta), \tag{1} fi=π(Fi,pi′)=πFi,ϕ(p,αi,β),(1)
其中 π ( ⋅ ) \pi(\cdot) π(⋅) 是双线性插值。类似于透视投影,CBCT投影函数 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅) 可以表述为:
ϕ ( p , α i , β ) = H A ( β ) R ( α i ) p 1 , (2) \phi(p, \alpha_i, \beta) = H A(\beta) R(\alpha_i) p_1, \tag{2} ϕ(p,αi,β)=HA(β)R(αi)p1,(2)
其中 R ( α i ) ∈ R 4 × 4 R(\alpha_i) \in \mathbb{R}^{4 \times 4} R(αi)∈R4×4 是旋转矩阵,将点 p p p 从世界坐标系转换到视图 i i i 的扫描仪坐标系, A ( β ) ∈ R 3 × 4 A(\beta) \in \mathbb{R}^{3 \times 4} A(β)∈R3×4 是投影矩阵,将点投影到视图 i i i 的2D成像面板上, H : R 3 → R 2 H : \mathbb{R}^3 \to \mathbb{R}^2 H:R3→R2 是齐次坐标到笛卡尔坐标的映射。由于页面限制, ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅) 的详细公式在补充材料中给出。
2.2.2 Cross-view Feature Fusion & Intensity Regression
给定 K K K 个投影视图,查询来自不同视图的点 p p p 的 K K K 个视图特定特征,形成特征列表 F ( p ) = { f 1 , f 2 , … , f K } ⊂ R C F(p) = \{f_1, f_2, \dots, f_K\} \subset \mathbb{R}^C F(p)={f1,f2,…,fK}⊂RC。然后,引入跨视图特征融合函数 δ ( ⋅ ) \delta(\cdot) δ(⋅) 来聚合来自 F ( p ) F(p) F(p) 的特征,并生成一个1D向量 f ˉ = δ ( F ( p ) ) ∈ R C \bar{f} = \delta(F(p)) \in \mathbb{R}^C fˉ=δ(F(p))∈RC 来表示点 p p p 的语义特征。通常, F ( p ) F(p) F(p) 是一个无序的特征集合,这意味着 δ ( ⋅ ) \delta(\cdot) δ(⋅) 应该是一个集合函数,可以通过池化层(例如最大池化/平均池化)来实现。在我们的实验中,训练和测试样本的投影角度是相同的,从 0 ∘ 0^\circ 0∘ 到 18 0 ∘ 180^\circ 180∘(半旋转)均匀采样。因此, F ( p ) F(p) F(p) 可以看作是一个有序列表( K × C K \times C K×C 张量),并且 δ ( ⋅ ) \delta(\cdot) δ(⋅) 可以通过一个两层的多层感知机(MLP)来实现特征聚合( K → ⌊ K / 2 ⌋ → 1 K \to \lfloor K/2 \rfloor \to 1 K→⌊K/2⌋→1)。我们将在消融实验中比较不同的 δ ( ⋅ ) \delta(\cdot) δ(⋅) 实现方法。最后,应用一个四层的多层感知机(MLP)( C → 2 C → ⌊ C / 2 ⌋ → ⌊ C / 8 ⌋ → 1 C \to 2C \to \lfloor C/2 \rfloor \to \lfloor C/8 \rfloor \to 1 C→2C→⌊C/2⌋→⌊C/8⌋→1)来对 f ˉ \bar{f} fˉ 进行强度值 v ∈ R v \in \mathbb{R} v∈R 的回归。
2.3 Network Training
假设原始CT体积的形状和间距分别为 H × W × D H \times W \times D H×W×D 和 ( s h , s w , s d ) (sh, sw, sd) (sh,sw,sd) 毫米。在训练过程中,与以往将整个3D CT图像作为监督目标的基于体素的方法不同,我们随机采样一组 N N N 个点 { p 1 , p 2 , … , p N } \{p_1, p_2, \dots, p_N\} {p1,p2,…,pN},其坐标范围从 ( 0 , 0 , 0 ) (0, 0, 0) (0,0,0) 到 ( s h H , s w W , s d D ) (shH, swW, sdD) (shH,swW,sdD),在世界坐标系中(单位:毫米),作为输入。然后,DIF-Net 将估计它们的强度值 V = { v 1 , v 2 , … , v N } V = \{v_1, v_2, \dots, v_N\} V={v1,v2,…,vN},通过给定的投影 I I I 进行估算。为了监督,基于点的坐标,通过三线性插值可以从真实的CT图像中获得地面真值强度值 V ^ = { v ^ 1 , v ^ 2 , … , v ^ N } \hat{V} = \{\hat{v}_1, \hat{v}_2, \dots, \hat{v}_N\} V^={v^1,v^2,…,v^N}。我们选择均方误差(MSE)作为目标函数,训练损失可以表示为:
L ( V , V ^ ) = 1 N ∑ i = 1 N ( v i − v ^ i ) 2 . (3) L(V, \hat{V}) = \frac{1}{N} \sum_{i=1}^N (v_i - \hat{v}_i)^2. \tag{3} L(V,V^)=N1i=1∑N(vi−v^i)2.(3)
由于背景点(62%,例如空气)占据的空间大于前景点(38%,例如骨骼、器官),均匀采样会导致强度预测的不平衡。我们设置一个强度阈值 1 0 − 5 10^{-5} 10−5 通过二分类方法识别前景和背景区域,并从每个区域中分别采样 N 2 N_2 N2 个点用于训练。
2.4 Volume Reconstruction
在推理过程中,首先采样一个规则且密集的点集,以覆盖所有CT体素,即从 ( 0 , 0 , 0 ) (0, 0, 0) (0,0,0) 到 ( s h H , s w W , s d D ) (shH, swW, sdD) (shH,swW,sdD) 均匀地采样 H × W × D H \times W \times D H×W×D 个点。然后,网络将使用二维投影和点集作为输入,生成采样点的强度值,从而形成目标CT体积。与以往的基于体素的方法不同,后者限制于生成固定分辨率的CT图像,我们的方法通过引入连续强度场的表示,能够实现可扩展的输出分辨率。例如,我们可以均匀地采样 ⌊ H s ⌋ × ⌊ W s ⌋ × ⌊ D s ⌋ \left\lfloor \frac{H}{s} \right\rfloor \times \left\lfloor \frac{W}{s} \right\rfloor \times \left\lfloor \frac{D}{s} \right\rfloor ⌊sH⌋×⌊sW⌋×⌊sD⌋ 个点来生成一个粗略的CT图像,但具有更快的重建速度,或者采样 ⌊ s H ⌋ × ⌊ s W ⌋ × ⌊ s D ⌋ \left\lfloor sH \right\rfloor \times \left\lfloor sW \right\rfloor \times \left\lfloor sD \right\rfloor ⌊sH⌋×⌊sW⌋×⌊sD⌋ 个点来生成更高分辨率的CT图像,其中 s > 1 s > 1 s>1 是缩放比。
3 Experiments
我们在收集的膝关节CBCT数据集上进行广泛实验,以展示我们提出的方法在稀疏视图CBCT重建中的有效性。与以往的工作相比,我们的DIF-Net能够以超快的速度从极度稀疏(≤ 10)个投影中重建出具有高图像质量和高空间分辨率的CT体积。
3.1 Experimental Settings
3.1.1 Dataset and Preprocessing
我们收集了一个膝关节CBCT数据集,包含614个CT扫描图像。其中,464个用于训练,50个用于验证,100个用于测试。我们对CT扫描进行重采样、插值和裁剪(或填充),使其具有各向同性体素间距 ( 0.8 , 0.8 , 0.8 ) (0.8, 0.8, 0.8) (0.8,0.8,0.8) 毫米,并且形状为 256 × 256 × 256 256 \times 256 \times 256 256×256×256。通过数字重建射线(DRRs)以 256 × 256 256 \times 256 256×256 的分辨率生成二维投影。投影角度均匀地选择在 18 0 ∘ 180^\circ 180∘ 范围内。
3.1.2 Implementation
我们使用PyTorch实现了DIF-Net,并在一台单NVIDIA RTX 3090 GPU上进行训练。网络参数使用带动量为0.98的随机梯度下降(SGD)进行优化,初始学习率为0.01。学习率在每个epoch后按因子 0.0011 / 400 ≈ 0.9829 0.0011/400 \approx 0.9829 0.0011/400≈0.9829 递减,我们训练模型400个epoch,批大小为4。对于每个CT扫描, N = 10 , 000 N = 10,000 N=10,000 个点在每次训练迭代中被采样作为输入。对于完整的模型,我们采用具有 C = 128 C = 128 C=128 输出特征通道的U-Net 23 作为2D编码器,并使用MLP实现跨视图特征融合。
3.1.3 Baseline Methods
我们将四种公开可用的方法作为基准进行比较,包括传统方法FDK 10 和SART 12,基于NeRF的方法NAF 19,以及基于数据驱动的去噪方法FBPConvNet 25。由于维度的增加(从2D到3D),去噪方法应配备3D卷积/反卷积,以实现CBCT重建时的密集预测,这会导致极高的计算成本和较低的分辨率(≤ 643 643 643)。为了公平比较,我们使用FDK获取初始结果,并应用2D网络进行切片级别的去噪。
3.1.4 Evaluation Metrics
我们遵循以往的工作 22 26 19,使用两个定量指标评估重建的CT体积,分别为峰值信噪比(PSNR)和结构相似性(SSIM) 27。较高的PSNR/SSIM值表示更优的重建质量。
3.2 Results
3.2.1 Performance
如表1所示,我们将DIF-Net与四种先前的方法 12 10 21 19 进行了比较,比较设置包括使用不同输出分辨率(即 12 8 3 , 25 6 3 128^3, 256^3 1283,2563)和不同数量的投影视图(即6、8和10)。实验表明,我们提出的DIF-Net即使只使用6个投影视图,也能重建出高质量的CBCT图像,在PSNR和SSIM值方面显著优于以往的工作。更重要的是,DIF-Net可以直接用于重建不同输出分辨率的CT图像,而无需重新训练或修改模型。如图3所示的视觉结果所示,FDK 10 由于缺乏足够的投影视图,产生了许多条纹伪影;SART 12 和NAF 19 产生了具有良好形状轮廓的结果,但缺乏详细的内部信息;FBPConvNet 25 重建了良好的形状和适中的细节,但仍然存在一些条纹伪影;而我们提出的DIF-Net能够重建高质量的CT图像,具有更好的形状轮廓、更清晰的内部信息和更少的伪影。更多关于输入视图数量的视觉比较请参见补充材料。
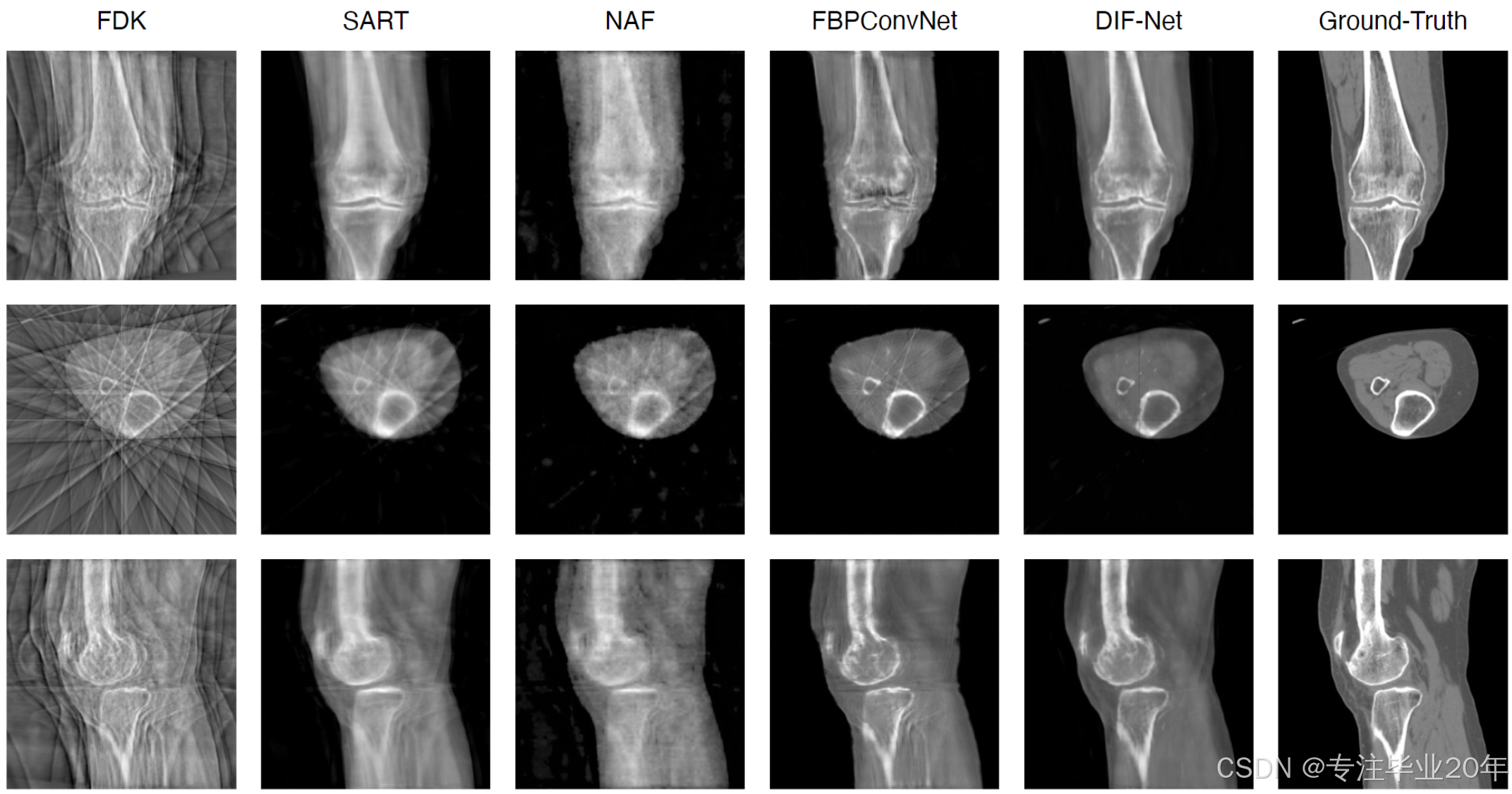
图3. 10视图重建的定性比较。
3.2.2 Reconstruction Efficiency
如表2所示,FDK 10 需要最少的重建时间,但图像质量最差;SART 12 和NAF 19 需要大量的时间进行优化或训练;FBPConvNet 25 可以更快地重建3D体积,但质量仍然有限。我们的DIF-Net可以在1.6秒内重建高质量的CT,远快于大多数比较方法。此外,得益于强度场表示,DIF-Net具有更少的训练参数,并且需要较少的计算内存,从而使高分辨率重建成为可能。
表2. 不同方法在重建质量(PSNR/SSIM)、重建时间、参数和训练内存成本方面的比较。默认设置:10视图重建,输出分辨率为 25 6 3 256^3 2563;训练批量大小为1。†:由于内存限制,评估时输出分辨率为 12 8 3 128^3 1283。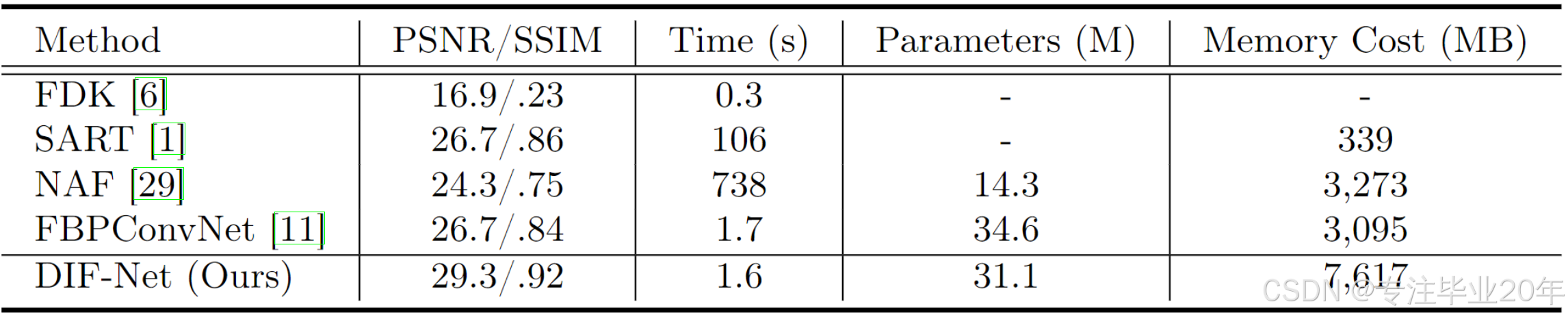
3.2.3 Ablation Study
表3和表4展示了跨视图融合策略和训练点数量 N N N 的消融分析。实验表明:
- MLP表现最佳,但最大池化也有效,并且当训练/测试数据中的视角不一致时,最大池化会成为一种通用解决方案,如第2.2节所讨论的;
- 较少的点(例如 5 , 000 5,000 5,000)可能会在训练过程中不稳定,导致损失和梯度的波动,从而导致性能下降; 10 , 000 10,000 10,000 个点足以实现最佳性能,而训练 10 , 000 10,000 10,000 个点比基于体素的方法(即 25 6 3 256^3 2563 或 12 8 3 128^3 1283)训练整个CT体积要稀疏得多。
我们曾尝试使用不同的编码器,如预训练的ResNet18 28,该模型的参数比U-Net 23 多,但ResNet18并未带来任何改进(PSNR/SSIM:29.2/0.92),这意味着U-Net在此任务中足够强大,可以进行特征提取。
表3. 关于不同跨视图融合策略的消融研究(10-view)。
表4. 关于不同训练点数量 N N N 的消融研究(10-view)。
4. Conclusion
在本工作中,我们将CT体积建模为一个连续的强度场,并提出了一种新型的DIF-Net,用于从极度稀疏(≤10)个投影视图中进行超快的CBCT重建。DIF-Net旨在从输入的投影中估计3D空间中任意点的强度值,这意味着不需要3D CNN进行特征解码,从而减少了内存需求和计算成本。实验表明,DIF-Net能够执行高效且高质量的CT重建,显著优于以往的最先进方法。更重要的是,DIF-Net是一个通用的稀疏视图重建框架,可以在包含不同身体部位、不同投影视图和成像参数的大规模数据集上进行训练,从而实现更好的泛化能力。这将作为我们未来的工作方向。
《用于极度稀疏视图CBCT重建的深度强度场学习 — 补充材料》
A. 投影函数 φ \varphi φ 的公式化
如第2.2节所述,3D点被投影到2D成像面板上,以便从某一视图的特征图中查询其视图特定的特征。在本节中,我们正式介绍投影函数 φ \varphi φ。如图4所示,给定一个世界坐标系(WCS,下标为 w w w)中的点,我们首先将其从WCS转换到扫描仪坐标系(SCS,下标为 s s s);然后将其从SCS投影到面板坐标系(PCS);最后,获取其在PCS中的二维投影坐标,用于查询视图特定的特征。为了简化公式,我们假设成像面板与SCS的 z z z方向正交,并且面板中心到PCS原点的偏移量为零。
旋转
如图4a所示,给定一个在世界坐标系(WCS)中的点 p w = [ x w , y w , z w ] T p_w = [x_w, y_w, z_w]^T pw=[xw,yw,zw]T,我们首先通过旋转矩阵 R ( α ) R(\alpha) R(α) 将 p w p_w pw 从WCS转换到扫描仪坐标系(SCS),并获得其SCS坐标 p s = [ x s , y s , z s ] T p_s = [x_s, y_s, z_s]^T ps=[xs,ys,zs]T:
R ( α ) = [ 1 0 0 0 0 cos ( α ) − sin ( α ) 0 0 sin ( α ) cos ( α ) 0 0 0 0 1 ] , a n d [ x s y s z s 1 ] = R ( α ) [ x w y w z w 1 ] , (4) R(\alpha) = \begin{bmatrix} 1 & 0 & 0 & 0 \\ 0 & \cos(\alpha) & -\sin(\alpha) & 0 \\ 0 & \sin(\alpha) & \cos(\alpha) & 0 \\ 0 & 0 & 0 & 1 \end{bmatrix}, and \begin{bmatrix} x_s \\ y_s \\ z_s \\ 1 \end{bmatrix} = R(\alpha) \begin{bmatrix} x_w \\ y_w \\ z_w \\ 1 \end{bmatrix}, \tag{4} R(α)=
10000cos(α)sin(α)00−sin(α)cos(α)00001
,and
xsyszs1
=R(α)
xwywzw1
,(4)
其中 α \alpha α 是CT扫描仪的旋转角度。
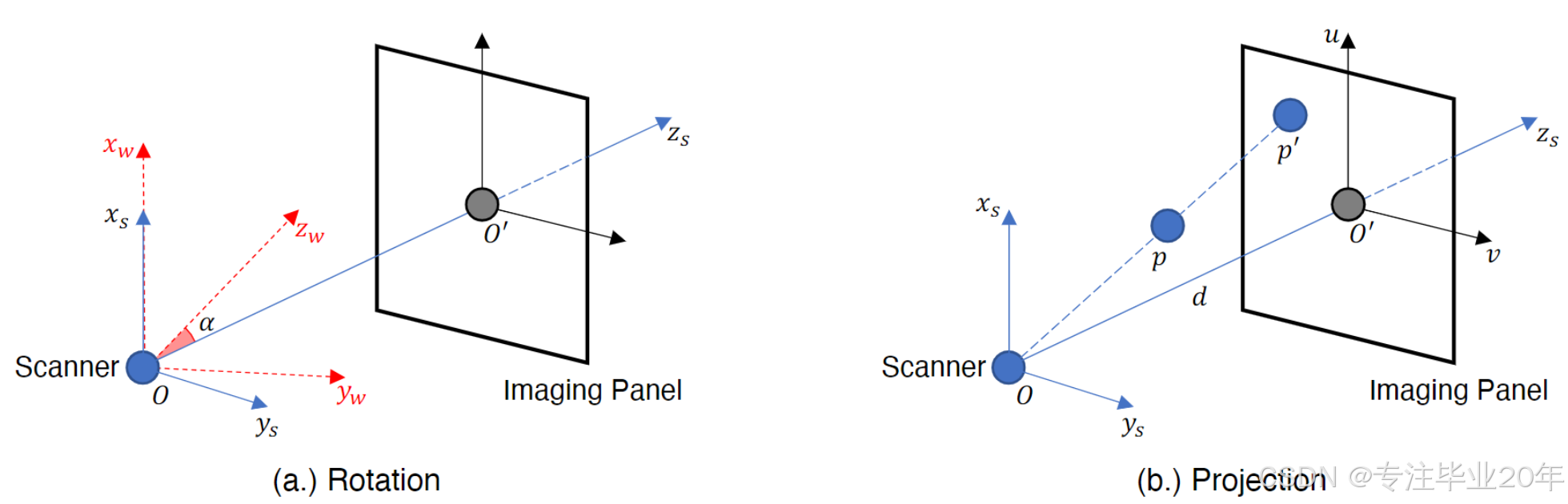
图4.(a.) 从世界坐标系(3D)到扫描仪坐标系(3D)的旋转。 (b.) 从扫描仪坐标系(3D)到面板坐标系(2D)的投影。
投影
如图4b所示,假设扫描仪源点 O O O 到成像面板中心 O ′ O' O′ 的距离为 ∥ O O ′ ∥ = d \|OO'\| = d ∥OO′∥=d。投影矩阵 A A A 定义为:
A = [ d 0 0 0 0 d 0 0 0 0 1 0 ] . (5) A = \begin{bmatrix} d & 0 & 0 & 0 \\ 0 & d & 0 & 0 \\ 0 & 0 & 1 & 0 \end{bmatrix}. \tag{5} A=
d000d0001000
.(5)
然后,我们通过投影矩阵 A A A 将 p s p_s ps 投影到成像面板上,并获得投影后的齐次坐标:
A ⋅ [ x s y s z s 1 ] = [ d x s d y s z s ] . (6) A \cdot \begin{bmatrix} x_s \\ y_s \\ z_s \\ 1 \end{bmatrix} = \begin{bmatrix} d x_s \\ d y_s \\ z_s \end{bmatrix}. \tag{6} A⋅
xsyszs1
=
dxsdyszs
.(6)
最终,我们得到在PCS中的投影点 p ′ = [ u , v ] p' = [u, v] p′=[u,v],其中 u = d x s z s , v = d y s z s u = \frac{d x_s}{z_s}, \quad v = \frac{d y_s}{z_s} u=zsdxs,v=zsdys。总之,对于世界坐标系中的点 p = [ x , y , z ] T p = [x, y, z]^T p=[x,y,z]T,其投影点 p ′ = [ u , v ] T p' = [u, v]^T p′=[u,v]T 可表示为:
[ u , v ] T = φ ( p , α , β ) = H A ⋅ R ( α ) ⋅ [ x y z 1 ] , (7) [u, v]^T = \varphi(p, \alpha, \beta) = H A \cdot R(\alpha) \cdot \begin{bmatrix} x \\ y \\ z \\ 1 \end{bmatrix}, \tag{7} [u,v]T=φ(p,α,β)=HA⋅R(α)⋅
xyz1
,(7)
其中 β \beta β 代表成像参数(如距离、偏移量等), H : R 3 → R 2 H : \mathbb{R}^3 \to \mathbb{R}^2 H:R3→R2 是齐次划分,将 p ′ p' p′ 的齐次坐标映射到其笛卡尔坐标。
B. 附加实验
重建效率分析
如表5所示,使用较低的输出分辨率( 12 8 3 128^3 1283),DIF-Net能够实现实时CT重建。此外,减少投影视图的数量可以加速重建。如第2.2节所述,输出分辨率在测试期间是可扩展的。因此,我们可以根据不同的应用调整输出分辨率,以在重建时间和图像质量之间做出权衡。
表5. 在不同输出分辨率(Res.)和不同投影视图数量(K)下的重建效率比较。
使用不同投影参数的重建
DIF-Net可以配备最大池化进行跨视图融合,并通过训练不同的投影参数来提高在实际场景中的鲁棒性。为了验证上述说法,我们进行实验,使用随机的6∼10个视图、随机的起始角度和固定的角度间隔(6/7/8/9/10视图的角度间隔分别为30/26/23/20/18度)训练DIF-Net。以下表6显示了使用不同投影参数的单一训练模型的测试结果。训练后的模型足够鲁棒,可以适应不同数量的输入视图和变化的投影角度,这表明所提出的框架DIF-Net在实际场景中具有潜在的应用价值。
表6. 在不同视图数量和变化的投影角度下的评估。
C. Others
实现细节
在训练时间方面,使用单个3090 GPU分别对6视图、8视图和10视图重建进行了训练,训练时间为10小时、15小时和18小时。投影配置已在我们的代码仓库中提供。
视觉比较
下图5展示了不同数量输入视图的视觉比较。
图5. 基准模型与我们的DIF-Net在不同输入视图数量下的定性比较。
-
Scarfe, W.C., Farman, A.G., Sukovic, P., et al.: Clinical applications of cone-beam computed tomography in dental practice. Journal-Canadian Dental Association 72(1), 75 (2006). ↩︎
-
Bier, B., Ravikumar, N., Unberath, M., Levenston, M., Gold, G., Fahrig, R., Maier, A.: Range imaging for motion compensation in c-arm cone-beam ct of knees under weight-bearing conditions. Journal of Imaging 4(1), 13 (2018). ↩︎
-
Dartus, J., Jacques, T., Martinot, P., Pasquier, G., Cotten, A., Migaud, H., Morel, V., Putman, S.: The advantages of cone-beam computerised tomography (ct) in pain management following total knee arthroplasty, in comparison with conventional multi-detector ct. Orthopaedics & Traumatology: Surgery & Research 107(3), 102874 (2021). ↩︎
-
Jaroma, A., Suomalainen, J.S., Niemitukia, L., Soininvaara, T., Salo, J., Kröger, H.: Imaging of symptomatic total knee arthroplasty with cone beam computed tomography. Acta Radiologica 59(12), 1500–1507 (2018). ↩︎
-
Nardi, C., Buzzi, R., Molteni, R., Cossi, C., Lorini, C., Calistri, L., Colagrande, S.: The role of cone beam ct in the study of symptomatic total knee arthroplasty (tka): a 20 cases report. The British Journal of Radiology 90(1074), 20160925 (2017). ↩︎
-
Anirudh, R., Kim, H., Thiagarajan, J.J., Mohan, K.A., Champley, K., Bremer, T.: Lose the views: Limited angle ct reconstruction via implicit sinogram completion. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 6343–6352 (2018). ↩︎
-
Tang, C., Zhang, W., Li, Z., Cai, A., Wang, L., Li, L., Liang, N., Yan, B.: Projection super-resolution based on convolutional neural network for computed tomography. In: 15th International Meeting on Fully Three-Dimensional Image Reconstruction in Radiology and Nuclear Medicine. vol. 11072, pp. 537–541. SPIE (2019). ↩︎
-
Wu, W., Guo, X., Chen, Y., Wang, S., Chen, J.: Deep embedding-attention refinement for sparse-view ct reconstruction. IEEE Transactions on Instrumentation and Measurement (2022). ↩︎
-
Wu, W., Hu, D., Niu, C., Yu, H., Vardhanabhuti, V., Wang, G.: Drone: dual-domain residual-based optimization network for sparse-view ct reconstruction. IEEE Transactions on Medical Imaging 40(11), 3002–3014 (2021). ↩︎
-
Feldkamp, L.A., Davis, L.C., Kress, J.W.: Practical cone-beam algorithm. Josa a1(6), 612–619 (1984). ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
-
Gordon, R., Bender, R., Herman, G.T.: Algebraic reconstruction techniques (art) for three-dimensional electron microscopy and x-ray photography. Journal of theoretical Biology 29(3), 471–481 (1970). ↩︎
-
Andersen, A.H., Kak, A.C.: Simultaneous algebraic reconstruction technique (sart): a superior implementation of the art algorithm. Ultrasonic imaging 6(1), 81–94 (1984). ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
-
Pan, J., Zhou, T., Han, Y., Jiang, M.: Variable weighted ordered subset image reconstruction algorithm. International Journal of Biomedical Imaging 2006 (2006). ↩︎
-
Lahiri, A., Klasky, M., Fessler, J.A., Ravishankar, S.: Sparse-view cone beam ct reconstruction using data-consistent supervised and adversarial learning from scarce training data. arXiv preprint arXiv:2201.09318 (2022). ↩︎
-
Fang, Y., Mei, L., Li, C., Liu, Y., Wang, W., Cui, Z., Shen, D.: Snaf: Sparse-view cbct reconstruction with neural attenuation fields. arXiv preprint arXiv:2211.17048 (2022). ↩︎ ↩︎
-
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM 65(1), 99–106 (2021). ↩︎ ↩︎
-
Rückert, D., Wang, Y., Li, R., Idoughi, R., Heidrich, W.: Neat: Neural adaptive tomography. ACM Transactions on Graphics (TOG) 41(4), 1–13 (2022). ↩︎ ↩︎
-
Shen, L., Pauly, J., Xing, L.: Nerp: implicit neural representation learning with prior embedding for sparsely sampled image reconstruction. IEEE Transactions on Neural Networks and Learning Systems (2022). ↩︎ ↩︎
-
Zha, R., Zhang, Y., Li, H.: Naf: Neural attenuation fields for sparse-view cbct reconstruction. In: Medical Image Computing and Computer Assisted Intervention–MICCAI 2022: 25th International Conference, Singapore, September 18–22, 2022, Proceedings, Part VI. pp. 442–452. Springer (2022). ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
-
Jiang, Y.: Mfct-gan: multi-information network to reconstruct ct volumes for security screening. Journal of Intelligent Manufacturing and Special Equipment (2022). ↩︎ ↩︎
-
Shen, L., Zhao, W., Xing, L.: Patient-specific reconstruction of volumetric computed tomography images from a single projection view via deep learning. Nature biomedical engineering 3(11), 880–888 (2019). ↩︎ ↩︎ ↩︎
-
Ying, X., Guo, H., Ma, K., Wu, J., Weng, Z., Zheng, Y.: X2ct-gan: reconstructing ct from biplanar x-rays with generative adversarial networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10619–10628 (2019). ↩︎ ↩︎ ↩︎
-
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18. pp. 234–241. Springer (2015). ↩︎ ↩︎ ↩︎
-
Punn, N.S., Agarwal, S.: Modality specific u-net variants for biomedical image segmentation: a survey. Artificial Intelligence Review 55(7), 5845–5889 (2022). ↩︎
-
Jin, K.H., McCann, M.T., Froustey, E., Unser, M.: Deep convolutional neural network for inverse problems in imaging. IEEE Transactions on Image Processing 26(9), 4509–4522 (2017). ↩︎ ↩︎ ↩︎
-
Zang, G., Idoughi, R., Li, R., Wonka, P., Heidrich, W.: Intratomo: self-supervised learning-based tomography via sinogram synthesis and prediction. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 1960–1970 (2021). ↩︎
-
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing 13(4), 600–612 (2004). ↩︎
-
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016). ↩︎

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 23
23 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)