PyTorch 模型训练教程(一)-数据
第一章 数 据1.1 Cifar10 转 png下载 cifar-10-python.tar.gz下载方式:官网:http://www.cs.toronto.edu/~kriz/cifar.htmllinux命令:cd Datawget http://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz下载 cifar-10-python.tar.gz,存
第一章 数 据
1.1 Cifar10 转 png
下载 cifar-10-python.tar.gz
下载方式:
官网:http://www.cs.toronto.edu/~kriz/cifar.html
linux命令:
cd Data
wget http://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
下载 cifar-10-python.tar.gz,存放到 /Data 文件夹下,并且解压,获得文件夹/Data/cifar-10-batches-py/
运行代码:
# coding:utf-8
"""
将cifar10的data_batch_12345 转换成 png格式的图片
每个类别单独存放在一个文件夹,文件夹名称为0-9
"""
from imageio import imwrite
import numpy as np
import os
import pickle
data_dir = os.path.join("..", "..", "Data", "cifar-10-batches-py")
train_o_dir = os.path.join("..", "..", "Data", "cifar-10-png", "raw_train")
test_o_dir = os.path.join("..", "..", "Data", "cifar-10-png", "raw_test")
Train = False # 不解压训练集,仅解压测试集
# 解压缩,返回解压后的字典
def unpickle(file):
with open(file, 'rb') as fo:
dict_ = pickle.load(fo, encoding='bytes')
return dict_
def my_mkdir(my_dir):
if not os.path.isdir(my_dir):
os.makedirs(my_dir)
# 生成训练集图片,
if __name__ == '__main__':
if Train:
for j in range(1, 6):
data_path = os.path.join(data_dir, "data_batch_" + str(j)) # data_batch_12345
train_data = unpickle(data_path)
print(data_path + " is loading...")
for i in range(0, 10000):
img = np.reshape(train_data[b'data'][i], (3, 32, 32))
img = img.transpose(1, 2, 0)
label_num = str(train_data[b'labels'][i])
o_dir = os.path.join(train_o_dir, label_num)
my_mkdir(o_dir)
img_name = label_num + '_' + str(i + (j - 1)*10000) + '.png'
img_path = os.path.join(o_dir, img_name)
imwrite(img_path, img)
print(data_path + " loaded.")
print("test_batch is loading...")
# 生成测试集图片
test_data_path = os.path.join(data_dir, "test_batch")
test_data = unpickle(test_data_path)
for i in range(0, 10000):
img = np.reshape(test_data[b'data'][i], (3, 32, 32))
img = img.transpose(1, 2, 0)
label_num = str(test_data[b'labels'][i])
o_dir = os.path.join(test_o_dir, label_num)
my_mkdir(o_dir)
img_name = label_num + '_' + str(i) + '.png'
img_path = os.path.join(o_dir, img_name)
imwrite(img_path, img)
print("test_batch loaded.")
可在文件夹 Data/cifar-10-png/raw_test/下看到 0-9 个文件夹,对应10 个类别。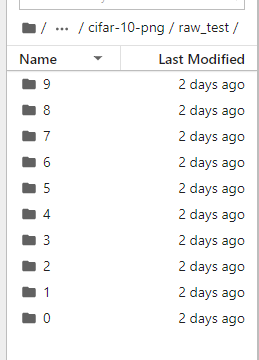
脚本中未将训练集解压出来,这里只是为了实验,因此未使用过多的数据。这里仅将测试集中的 10000 张图片解压出来,作为原始图片,将从这 10000 张图片中划分出训练集(train),验证集(valid),测试集(test)。
运行完成,在 Data/cifar-10-png/raw_test 下将有 10 个文件夹,对应 10 个类别,接着进入下一步:划分训练集、验证集和测试集。
1.2 训练集、验证集和测试集的划分
1.1把 cifar-10 的测试集转换成了 png 图片,充当实验的原始数据。1.2将把原始数据按 8:1:1 的比例划分为训练集(train set)、验证集(valid/dev set)和测试集(test set)。
运行 1_2_split_dataset.py,将会获得以下三个文件夹
/Data/train/
/Data/valid/
/Data/test/
# coding: utf-8
"""
将原始数据集进行划分成训练集、验证集和测试集
"""
import os
import glob
import random
import shutil
dataset_dir = os.path.join("..", "..", "Data", "cifar-10-png", "raw_test")
train_dir = os.path.join("..", "..", "Data", "train")
valid_dir = os.path.join("..", "..", "Data", "valid")
test_dir = os.path.join("..", "..", "Data", "test")
train_per = 0.8
valid_per = 0.1
test_per = 0.1
def makedir(new_dir):
if not os.path.exists(new_dir):
os.makedirs(new_dir)
if __name__ == '__main__':
for root, dirs, files in os.walk(dataset_dir):
for sDir in dirs:
imgs_list = glob.glob(os.path.join(root, sDir, '*.png'))
random.seed(666)
random.shuffle(imgs_list)
imgs_num = len(imgs_list)
train_point = int(imgs_num * train_per)
valid_point = int(imgs_num * (train_per + valid_per))
for i in range(imgs_num):
if i < train_point:
out_dir = os.path.join(train_dir, sDir)
elif i < valid_point:
out_dir = os.path.join(valid_dir, sDir)
else:
out_dir = os.path.join(test_dir, sDir)
makedir(out_dir)
out_path = os.path.join(out_dir, os.path.split(imgs_list[i])[-1])
shutil.copy(imgs_list[i], out_path)
print('Class:{}, train:{}, valid:{}, test:{}'.format(sDir, train_point, valid_point-train_point, imgs_num-valid_point))
数据划分完毕,下一步是制作存放有图片路径及其标签的 txt,PyTorch 依据该 txt 上的信息进行寻找图片,并读取图片数据和标签数据。
1.3 让 PyTorch 能读你的数据集
1.2中,将源数据(10000 张图片)划分为训练集、验证集和测试集,接下来就要让PyTorch 能读取这批数据。想让 PyTorch 能读取我们自己的数据,首先要了解 pytroch 读取图片的机制和流程,然后按流程编写代码。
Dataset 类
PyTorch 读取图片,主要是通过 Dataset 类,所以先简单了解一下 Dataset 类。Dataset类作为所有的 datasets 的基类存在,所有的 datasets 都需要继承它,类似于 C++中的虚基类。
class Dataset(object):
"""
表示数据集的抽象类.
所有其他数据集应该子类化它。所有的子类都应该重写'__len__', 它提供了数据集的大小, '__getitem__',
提供从0到len(self)范围内的整数索引排除了数据集的大小.
"""
def __getitem__(self, index):
raise NotImplementedError
def __len__(self):
raise NotImplementedError
def __add__(self, other):
return ConcatDataset([self, other])
这里重点看 getitem 函数,getitem 接收一个 index,然后返回图片数据和标签,这个index 通常指的是一个 list 的 index,这个 list 的每个元素就包含了图片数据的路径和标签信息。然而,如何制作这个 list 呢,通常的方法是将图片的路径和标签信息存储在一个 txt中,然后从该 txt 中读取。
那么读取自己数据的基本流程就是:
- 制作存储了图片的路径和标签信息的 txt
- 将这些信息转化为 list,该 list 每一个元素对应一个样本
- 通过 getitem 函数,读取数据和标签,并返回数据和标签
在训练代码里是感觉不到这些操作的,只会看到通过 DataLoader 就可以获取一个batch 的数据,其实触发去读取图片这些操作的是 DataLoader 里的__iter__(self),后面会详细讲解读取过程。1.3,主要讲 Dataset 子类。
因此,要让 PyTorch 能读取自己的数据集,只需要两步:
- 制作图片数据的索引
- 构建 Dataset 子类
制作图片数据的索引
这个比较简单,就是读取图片路径,标签,保存到 txt 文件中,这里注意格式就好,特别注意的是,txt 中的路径,是以训练时的那个 py 文件所在的目录为工作目录,所以这里需要提前算好相对路径!
# coding:utf-8
import os
'''
为数据集生成对应的txt文件
'''
train_txt_path = os.path.join("..", "..", "Data", "train.txt")
train_dir = os.path.join("..", "..", "Data", "train")
valid_txt_path = os.path.join("..", "..", "Data", "valid.txt")
valid_dir = os.path.join("..", "..", "Data", "valid")
def gen_txt(txt_path, img_dir):
f = open(txt_path, 'w')
for root, s_dirs, _ in os.walk(img_dir, topdown=True): # 获取 train文件下各文件夹名称
for sub_dir in s_dirs:
i_dir = os.path.join(root, sub_dir) # 获取各类的文件夹 绝对路径
img_list = os.listdir(i_dir) # 获取类别文件夹下所有png图片的路径
for i in range(len(img_list)):
if not img_list[i].endswith('png'): # 若不是png文件,跳过
continue
label = img_list[i].split('_')[0]
img_path = os.path.join(i_dir, img_list[i])
line = img_path + ' ' + label + '\n'
f.write(line)
f.close()
if __name__ == '__main__':
gen_txt(train_txt_path, train_dir)
gen_txt(valid_txt_path, valid_dir)
运行代码 1_3_generate_txt.py,即会在/Data/文件夹下面看到train.txt valid.txt
txt 中是这样的: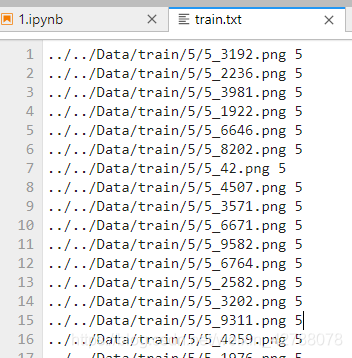
构建 Dataset 子类
下面是本实验构建的 Dataset 子类——MyDataset 类:
# coding: utf-8
from PIL import Image
from torch.utils.data import Dataset
# Dataset类作为所有的 datasets 的基类存在,所有的 datasets 都需要继承它
class MyDataset(Dataset):
def __init__(self, txt_path, transform=None, target_transform=None):
fh = open(txt_path, 'r')
imgs = []
for line in fh:
line = line.rstrip()
words = line.split()
imgs.append((words[0], int(words[1])))
self.imgs = imgs # 最主要就是要生成这个list, 然后DataLoader中给index,通过getitem读取图片数据
self.transform = transform
self.target_transform = target_transform
def __getitem__(self, index):
fn, label = self.imgs[index]
img = Image.open(fn).convert('RGB') # 像素值 0~255,在transfrom.totensor会除以255,使像素值变成 0~1
if self.transform is not None:
img = self.transform(img) # 在这里做transform,转为tensor等等
return img, label
def __len__(self):
return len(self.imgs)
首先看看初始化,初始化中从我们准备好的 txt 里获取图片的路径和标签,并且存储在 self.imgs,self.imgs 就是上面提到的 list,其一个元素对应一个样本的路径和标签,其实就是 txt 中的一行。
初始化中还会初始化 transform,transform 是一个 Compose 类型,里边有一个 list,list中就会定义了各种对图像进行处理的操作,可以设置减均值,除标准差,随机裁剪,旋转,翻转,仿射变换等操作。在这里我们可以知道,一张图片读取进来之后,会经过数据处理(数据增强),最终变成输入模型的数据。这里就有一点需要注意,PyTorch 的数据增强是将原始图片进行了处理,并不会生成新的一份图片,而是“覆盖”原图,当采用 randomcrop 之类的随机操作时,每个 epoch 输入进来的图片几乎不会是一模一样的,这达到了样本多样性的功能。
然后看看核心的 getitem 函数:
第一行:self.imgs 是一个 list,也就是一开始ᨀ到的 list,self.imgs 的一个元素是一个 str,包含图片路径,图片标签,这些信息是从 txt 文件中读取
第二行:利用 Image.open 对图片进行读取,img 类型为 Image ,mode=‘RGB’
第三行与第四行: 对图片进行处理,这个 transform 里边可以实现 减均值,除标准差,随机裁剪,旋转,翻转,放射变换,等等操作,这个放在后面会详细讲解。
当 Mydataset 构建好,剩下的操作就交给 DataLoder,在 DataLoder 中,会触发Mydataset 中的 getiterm 函数读取一张图片的数据和标签,并拼接成一个 batch 返回,作为模型真正的输入。1.4将会通过一个小例子,介绍 DataLoder 是如何获取一个 batch,以及一张图片是如何被 PyTorch 读取,最终变为模型的输入的。
1.4 图⽚从硬盘到模型
1.3中介绍了如何构建自己的 Dataset 子类——MyDataset,在 MyDataset 中,主要获取图片的索引以及定义如何通过索引读取图片及其标签。但是要触发 MyDataset 去读取图片及其标签却是在数据加载器 DataLoder 中。本小节,将进行单步调试,学习图片是如何从硬盘上流到模型的输入口的,并观察图片经历了哪些处理。
对应代码:
# coding: utf-8
import torch
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import numpy as np
import os
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import sys
sys.path.append("..")
from utils.utils import MyDataset, validate, show_confMat
from tensorboardX import SummaryWriter
from datetime import datetime
train_txt_path = os.path.join("..", "..", "Data", "train.txt")
valid_txt_path = os.path.join("..", "..", "Data", "valid.txt")
classes_name = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
train_bs = 16
valid_bs = 16
lr_init = 0.001
max_epoch = 1
# log
result_dir = os.path.join("..", "..", "Result")
now_time = datetime.now()
time_str = datetime.strftime(now_time, '%m-%d_%H-%M-%S')
log_dir = os.path.join(result_dir, time_str)
if not os.path.exists(log_dir):
os.makedirs(log_dir)
writer = SummaryWriter(log_dir=log_dir)
# ------------------------------------ step 1/5 : 加载数据------------------------------------
# 数据预处理设置
normMean = [0.4948052, 0.48568845, 0.44682974]
normStd = [0.24580306, 0.24236229, 0.2603115]
normTransform = transforms.Normalize(normMean, normStd)
trainTransform = transforms.Compose([
transforms.Resize(32),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor(),
normTransform
])
validTransform = transforms.Compose([
transforms.ToTensor(),
normTransform
])
# 构建MyDataset实例
train_data = MyDataset(txt_path=train_txt_path, transform=trainTransform)
valid_data = MyDataset(txt_path=valid_txt_path, transform=validTransform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=train_bs, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=valid_bs)
# ------------------------------------ step 2/5 : 定义网络------------------------------------
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool1(F.relu(self.conv1(x)))
x = self.pool2(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 定义权值初始化
def initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
torch.nn.init.xavier_normal_(m.weight.data)
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
torch.nn.init.normal_(m.weight.data, 0, 0.01)
m.bias.data.zero_()
net = Net() # 创建一个网络
net.initialize_weights() # 初始化权值
# ------------------------------------ step 3/5 : 定义损失函数和优化器 ------------------------------------
criterion = nn.CrossEntropyLoss() # 选择损失函数
optimizer = optim.SGD(net.parameters(), lr=lr_init, momentum=0.9, dampening=0.1) # 选择优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.1) # 设置学习率下降策略
# ------------------------------------ step 4/5 : 训练 --------------------------------------------------
for epoch in range(max_epoch):
loss_sigma = 0.0 # 记录一个epoch的loss之和
correct = 0.0
total = 0.0
scheduler.step() # 更新学习率
for i, data in enumerate(train_loader):
# if i == 30 : break
# 获取图片和标签
inputs, labels = data
inputs, labels = Variable(inputs), Variable(labels)
# forward, backward, update weights
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 统计预测信息
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).squeeze().sum().numpy()
loss_sigma += loss.item()
# 每10个iteration 打印一次训练信息,loss为10个iteration的平均
if i % 10 == 9:
loss_avg = loss_sigma / 10
loss_sigma = 0.0
print("Training: Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch + 1, max_epoch, i + 1, len(train_loader), loss_avg, correct / total))
# 记录训练loss
writer.add_scalars('Loss_group', {'train_loss': loss_avg}, epoch)
# 记录learning rate
writer.add_scalar('learning rate', scheduler.get_lr()[0], epoch)
# 记录Accuracy
writer.add_scalars('Accuracy_group', {'train_acc': correct / total}, epoch)
# 每个epoch,记录梯度,权值
for name, layer in net.named_parameters():
writer.add_histogram(name + '_grad', layer.grad.cpu().data.numpy(), epoch)
writer.add_histogram(name + '_data', layer.cpu().data.numpy(), epoch)
# ------------------------------------ 观察模型在验证集上的表现 ------------------------------------
if epoch % 2 == 0:
loss_sigma = 0.0
cls_num = len(classes_name)
conf_mat = np.zeros([cls_num, cls_num]) # 混淆矩阵
net.eval()
for i, data in enumerate(valid_loader):
# 获取图片和标签
images, labels = data
images, labels = Variable(images), Variable(labels)
# forward
outputs = net(images)
outputs.detach_()
# 计算loss
loss = criterion(outputs, labels)
loss_sigma += loss.item()
# 统计
_, predicted = torch.max(outputs.data, 1)
# labels = labels.data # Variable --> tensor
# 统计混淆矩阵
for j in range(len(labels)):
cate_i = labels[j].numpy()
pre_i = predicted[j].numpy()
conf_mat[cate_i, pre_i] += 1.0
print('{} set Accuracy:{:.2%}'.format('Valid', conf_mat.trace() / conf_mat.sum()))
# 记录Loss, accuracy
writer.add_scalars('Loss_group', {'valid_loss': loss_sigma / len(valid_loader)}, epoch)
writer.add_scalars('Accuracy_group', {'valid_acc': conf_mat.trace() / conf_mat.sum()}, epoch)
print('Finished Training')
# ------------------------------------ step5: 保存模型 并且绘制混淆矩阵图 ------------------------------------
net_save_path = os.path.join(log_dir, 'net_params.pkl')
torch.save(net.state_dict(), net_save_path)
conf_mat_train, train_acc = validate(net, train_loader, 'train', classes_name)
conf_mat_valid, valid_acc = validate(net, valid_loader, 'valid', classes_name)
show_confMat(conf_mat_train, classes_name, 'train', log_dir)
show_confMat(conf_mat_valid, classes_name, 'valid', log_dir)
大体流程:
- main.py: train_data = MyDataset(txt_path=train_txt_path, …) —>
- main.py: train_loader = DataLoader(dataset=train_data, …) —>
- main.py: for i, data in enumerate(train_loader, 0) —>
- dataloder.py: class DataLoader(): def iter(self): return _DataLoaderIter(self) —>
- dataloder.py: class _DataLoderIter(): def next(self): batch = self.collate_fn([self.dataset[i]
for i in indices]) —> - tool.py: class MyDataset(): def getitem(): img = Image.open(fn).convert(‘RGB’) —>
- tool.py: class MyDataset(): img = self.transform(img) —>
- main.py: inputs, labels = data inputs, labels = Variable(inputs), Variable(labels) outputs =
net(inputs)
一句话概括就是,从 MyDataset 来,到 MyDataset 去。
一开始通过 MyDataset 创建一个实例,在该实例中有路径,有读取图片的方法(函 数)。然后需要 pytroch 的一系列规范化流程,在第 6 步中,才会调用 MyDataset 中的__getitem__()函数,最终通过 Image.open()读取图片数据。然后对原始图片数据进行一系列预处理(transform 中设置),最后回到 main.py,对数据进行转换成 Variable 类型,最终成为模型的输入。流程详细描述:
-
从 MyDataset 类中初始化 txt,txt 中有图片路径和标签
-
初始化 DataLoder 时,将 train_data 传入,从而使 DataLoder 拥有图片的路径
-
在一个 iteration 进行时,才读取一个 batch 的图片数据 enumerate()函数会返回可迭代数
据的一个“元素”,在这里 data 是一个 batch 的图片数据和标签,data 是一个 list -
class DataLoader()中再调用class _DataLoderIter() -
在 _DataLoderiter()类中会跳到
__next__(self)函数,在该函数中会通过indices = next(self.sample_iter)获取一个 batch 的 indices再通过batch = self.collate_fn([self.dataset[i] for i in indices])获取一个 batch 的数据
在batch = self.collate_fn([self.dataset[i] for i in indices])中会调用self.collate_fn函数 -
self.collate_fn中会调用 MyDataset 类中的__getitem__()函数,在__getitem__()中通过Image.open(fn).convert('RGB')读取图片 -
通过 Image.open(fn).convert(‘RGB’)读取图片之后,会对图片进行预处理,例如减均值,除以标准差,随机裁剪等等一系列ᨀ前设置好的操作。具体 transform 的用法将用单独一小节介绍,最后返回 img,label,再通过 self.collate_fn 来拼接成一个 batch。一个 batch 是一个 list,有两个元素,第一个元素是图片数据,是一个4D 的 Tensor,shape 为(64,3,32,32),第二个元素是标签 shape 为(64)。
-
将图片数据转换成 Variable 类型,然后称为模型真正的输入
inputs, labels = Variable(inputs), Variable(labels)outputs = net(inputs)通过了解图片从硬盘到模型的过程,我们可以更好的对数据做处理(减均值,除以标准差,裁剪,翻转,放射变换等等),也可以灵活的为模型准备数据,最后总结两个需要注意的地方。 -
图片是通过 Image.open()函数读取进来的,当涉及如下问题:
图片的通道顺序(RGB or BGR ?)
图片是 whc or cwh ?
像素值范围[0-1] or [0-255] ?
就要查看 MyDataset()类中__getitem__()下读取图片用的是什么方法 -
从 MyDataset()类中
__getitem__()函数中发现,PyTorch 做数据增强的方法是在原
始图片上进行的,并覆盖原始图片,这一点需要注意。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 1
1 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)