机器学习决策树
设 𝑋 是取值在有限范围内的一个离散随机变量,其概率密度为:随机变量 𝑋 的熵定义为:当某个集合含有多个类别时,此时 𝑘 较大, 𝑝𝑖 的数量过多;且整体的 𝑝𝑖 都会因 𝑘 的过大而普遍较小,从而使得 𝐻(X) 的值过大。这正好符合“熵值越大,事物越混乱”的定义。
一、何为决策树
决策树(Decision Tree)是一种分类和回归方法,是基于各种情况发生的所需条件构成决策树,以实现期望最大化的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。它的运行机制非常通俗易懂,因此被誉为机器学习中,最“友好”的算法。下面通过一个简单的例子来阐述它的执行流程。假设根据大量数据(含 3 个指标:天气、温度、风速)构建了一棵“可预测学校会不会举办运动会”的决策树(如下图所示)。
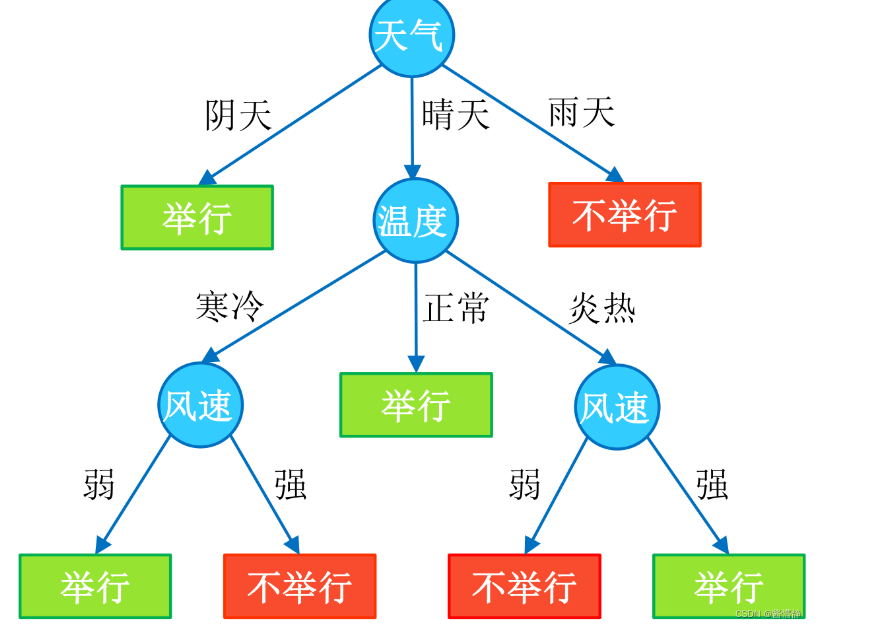
1、决策树的组成
决策树由结点和有向边组成。结点有两种类型:内部结点(圆)和叶结点(矩形)。其中,内部结点表示一个特征(属性);叶结点表示一个类别。而有向边则对应其所属内部结点的可选项(属性的取值范围),有非常好的可解释性。
2、决策树的构建
构建要求:
- 具有较好的泛化能力;
- 在 1 的基础上尽量不出现过拟合现象。
思路:
如果按照某个特征对数据进行划分时,它能最大程度地将原本混乱的结果尽可能划分为几个有序的大类,则就应该先以这个特征为决策树中的根结点。接着,不断重复这一过程,直到整棵决策树被构建完成为止。
二、熵
1、熵的作用
熵(Entropy)是表示随机变量不确定性的度量。说简单点就是物体内部的混乱程度。我们希望分类后的结果能使得整个样本集在各自的类别中尽可能有序,即希望某个特征在被用于分类后,能最大程度地降低样本数据的熵。
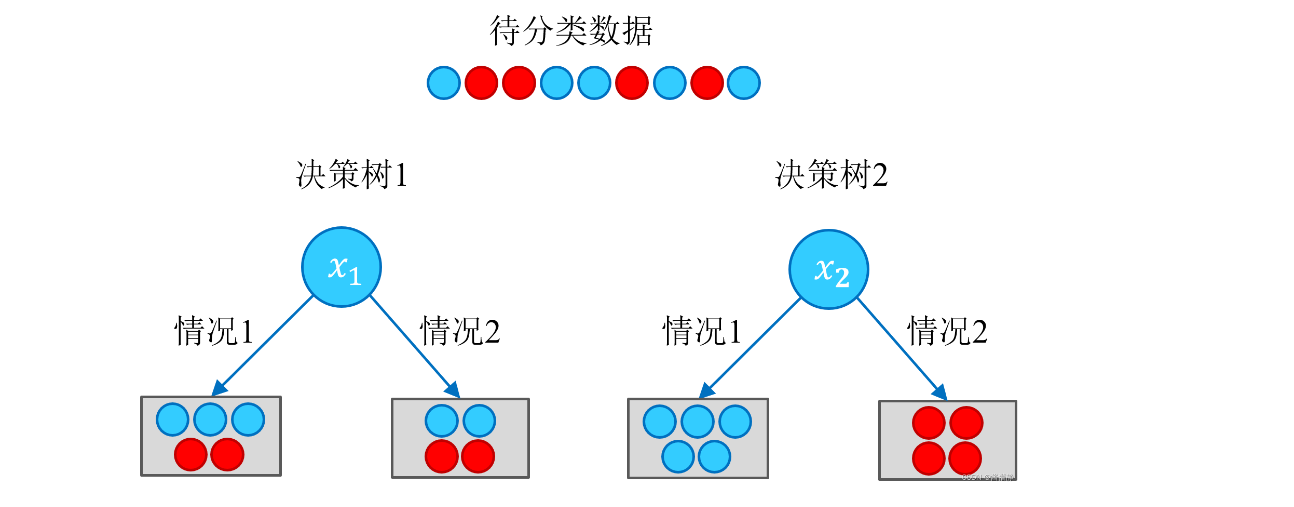
根据以上结果,可以很直观地认为,决策树 2 的分类效果优于决策树 1 。决策树 1 在通过特征 𝑥1 进行分类后,得到的分类结果依然混乱(甚至有熵增的情况),因此这个特征在现阶段被认为是无效特征。
2、熵的定义
设 𝑋 是取值在有限范围内的一个离散随机变量,其概率密度为:
随机变量 𝑋 的熵定义为:
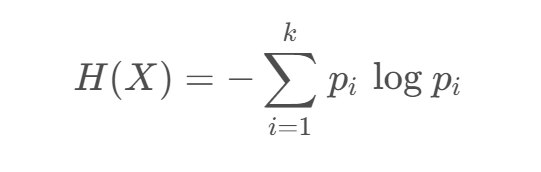
当某个集合含有多个类别时,此时 𝑘 较大, 𝑝𝑖 的数量过多;且整体的 𝑝𝑖 都会因 𝑘 的过大而普遍较小,从而使得 𝐻(X) 的值过大。这正好符合“熵值越大,事物越混乱”的定义。
3、条件熵
对于每个特征,都可以算出“该特征各项取值对运动会举办与否”的影响(而衡量各特征谁最合适的准则,即是熵)。
定义条件熵 𝐻(𝑌 | 𝑋) :在给定 𝑋 的条件下 𝑌 的条件概率分布对 𝑋 的数学期望,即
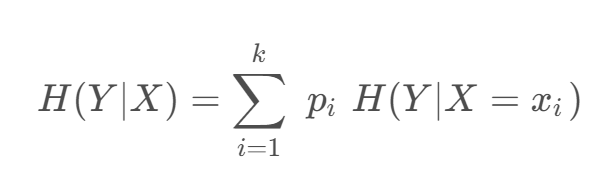
pi=P(X=xi) , i=1,2,…,k (表示指定集合中的元素类别) 。
三、划分选择
决策树学习的关键在于:如何选择最优划分属性。一般而言,随着划分过程的不断进行,我们自然希望决策树各分支结点所包含的样本尽可能属于同一类别,即结点的 “纯度” (purity) 越来越高。下面介绍几类较为主流的评选算法。
1、信息增益( ID3 算法选用的评估标准)
信息增益 𝑔(𝐷, 𝑋) :表示某特征 𝑋 使得数据集 𝐷 的不确定性减少程度,定义为集合 𝐷 的熵与在给定特征 𝑋 的条件下 𝐷 的条件熵 𝐻(𝐷 | 𝑋) 之差,即
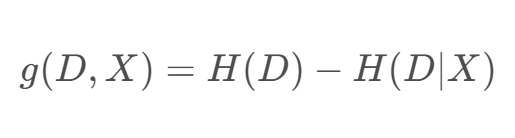
信息增益表达了样本数据在被分类后的专一性。因此,它可以作为选择当前最优特征的一个指标,依据该指标从大到小依次作为选择的特征。
2、信息增益率( C4.5 算法选用的评估标准)
以信息增益作为划分数据集的特征时,其偏向于选择取值较多的特征(特征下的类别很多)。比如,当在学校举办运动会的历史数据中加入一个新特征 “编号” 时,该特征将成为最优特征。因为给定 “编号” 就一定知道那天是否举行过运动会,因此 “编号” 的信息增益很高。
但实际我们知道,“编号” 对于类别的划分并没有实际意义。故此,引入信息增益率。
信息增益率 𝑔𝑅(𝐷, 𝑋) 定义为其信息增益 𝑔(𝐷, 𝑋) 与数据集 𝐷 在特征 𝑋 上值的熵 𝐻𝑋(𝐷) 之比,即:
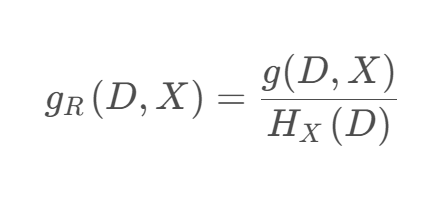
![]() 𝑘 是特征 𝑋 的取值类别个数。
𝑘 是特征 𝑋 的取值类别个数。
信息增益率能明显降低取值较多的特征偏好现象,从而更合理地评估各特征在划分数据集时取得的效果。
3、基尼系数( CART 算法选用的评估标准)
它通过使用基尼系数来代替信息增益率,从而避免复杂的对数运算。基尼系数代表了模型的不纯度,基尼系数越小,则不纯度越低,特征越好。注:这一点和信息增益(率)恰好相反。
对于给定数据集 𝐷 ,假设有 𝑘 个类别,且第 𝑘 个类别的数量为 𝐶𝑘 ,则该数据集的基尼系数为
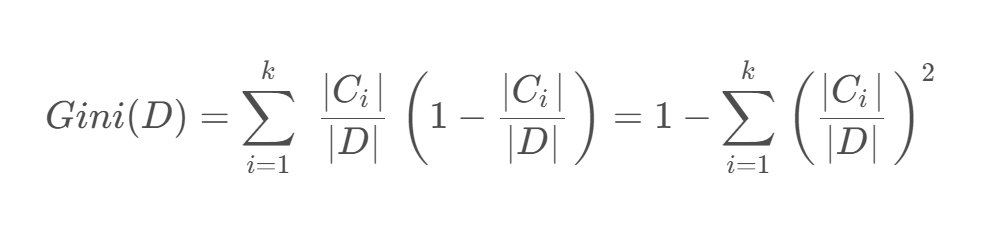
如果数据集 D 根据特征 X 的取值将其划分为 { D 1 , D 2 , … , D m },则在特征D的条件下划分过后的基尼系数为:
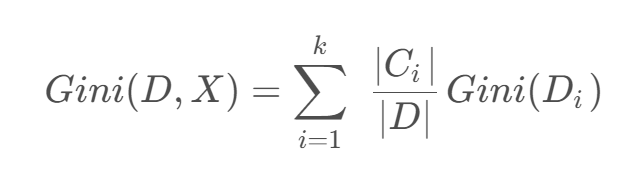
四、实战
data_loader.py
import numpy as np
# 导入 pandas 库,用于数据处理和分析
import pandas as pd
# 从 sklearn 库的 model_selection 模块中导入 train_test_split 函数,用于划分训练集和测试集
from sklearn.model_selection import train_test_split
# 用于加载和预处理数据
def load_data():
"""加载并预处理数据"""
# 定义一个字典 data,模拟贷款审批相关的数据集
# 字典的键是列名,对应的值是每列的数据
data = {
'ID': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
'年龄段': ['青年', '青年', '青年', '青年', '青年', '中年', '中年', '中年', '中年', '中年', '老年', '老年',
'老年', '老年', '老年', '老年'],
'有工作': ['否', '否', '是', '是', '否', '否', '否', '是', '否', '否', '否', '否', '是', '是', '否', '否'],
'有自己的房子': ['否', '否', '否', '是', '否', '否', '否', '是', '是', '是', '是', '是', '否', '否', '否',
'否'],
'信贷情况': ['一般', '好', '好', '一般', '一般', '一般', '好', '好', '非常好', '非常好', '非常好', '好', '好',
'非常好', '一般', '非常好'],
'类别(是否给贷款)': ['否', '否', '是', '是', '否', '否', '否', '是', '是', '是', '是', '是', '是', '是', '否',
'否']
}
# 将字典 data 转换为 pandas 的 DataFrame 对象 df,方便后续的数据处理
df = pd.DataFrame(data)
# 从 DataFrame 中删除 'ID' 和 '类别(是否给贷款)' 这两列,剩余的列作为特征矩阵 X
# axis=1 表示按列删除
X = df.drop(['ID', '类别(是否给贷款)'], axis=1)
# 提取 '类别(是否给贷款)' 这一列作为目标变量 y,即我们要预测的结果
y = df['类别(是否给贷款)']
# 使用 train_test_split 函数将特征矩阵 X 和目标变量 y 划分为训练集和测试集
# test_size=0.3 表示将 30% 的数据作为测试集,剩余 70% 作为训练集
# random_state=42 设置随机种子,确保每次运行代码时划分的结果一致,方便结果的复现
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 返回训练集的特征矩阵 X_train、测试集的特征矩阵 X_test
# 训练集的目标变量 y_train、测试集的目标变量 y_test
# 以及特征矩阵 X 的列名列表
return X_train, X_test, y_train, y_test, X.columns.tolist()将原始贷款审批数据转换为结构化格式,划分训练集和测试集,为后续决策树建模提供可直接使用的输入。
具体分三步:
1) 用字典定义原始数据并转为Pandas DataFrame;
2) 分离特征(年龄段、工作、房产、信贷)和标签(是否贷款);
3) 按7:3比例随机拆分训练集和测试集(固定随机种子确保可复现),最终返回处理好的特征矩阵、标签向量及特征名称列表。
c45_tree.py
import numpy as np
from collections import Counter
# 定义 C4.5 决策树类
class C45DecisionTree:
# 初始化函数,设置最大深度和最小样本分裂数
def __init__(self, max_depth=None, min_samples_split=2):
self.max_depth = max_depth
self.min_samples_split = min_samples_split
self.tree = None # 初始化决策树为空
self.label_encoders = None # 初始化标签编码器为空
# 计算熵的函数
def _entropy(self, y):
"""计算熵"""
# 使用 np.bincount 统计 y 中每个类别的数量
counts = np.bincount(y)
# 计算每个类别的概率
probabilities = counts / len(y)
# 计算熵,对概率大于 0 的类别进行计算
return -np.sum([p * np.log2(p) for p in probabilities if p > 0])
# 计算信息增益的函数
def _information_gain(self, X, y, feature):
"""计算信息增益"""
# 计算总熵
total_entropy = self._entropy(y)
# 统计特征 feature 的唯一值和对应的数量
values, counts = np.unique(X[feature], return_counts=True)
weighted_entropy = 0
# 遍历特征的每个唯一值
for v, c in zip(values, counts):
# 提取特征值为 v 时对应的目标值子集
subset_y = y[X[feature] == v]
# 计算加权熵
weighted_entropy += (c / len(y)) * self._entropy(subset_y)
# 返回信息增益,即总熵减去加权熵
return total_entropy - weighted_entropy
# 计算特征信息熵函数
def _split_info(self, X, feature):
"""计算特征信息熵"""
# 统计特征 feature 的唯一值和对应的数量
_, counts = np.unique(X[feature], return_counts=True)
# 计算每个特征值的概率
probabilities = counts / len(X)
# 计算特征信息熵,对概率大于 0 的特征值进行计算
return -np.sum([p * np.log2(p) for p in probabilities if p > 0])
# 计算信息增益率的函数
def _gain_ratio(self, X, y, feature):
"""计算信息增益率"""
# 计算信息增益
gain = self._information_gain(X, y, feature)
# 计算特征信息熵
split = self._split_info(X, feature)
# 返回信息增益率,若特征信息熵不为 0,则信息增益除以特征信息熵,否则返回 0
return gain / split if split != 0 else 0
# 选择最佳分裂特征的函数
def _choose_best_feature(self, X, y, features):
"""选择最佳分裂特征"""
# 计算每个特征的信息增益率
gain_ratios = [self._gain_ratio(X, y, f) for f in features]
# 获取信息增益率最大的特征索引
best_idx = np.argmax(gain_ratios)
# 返回最佳特征
return features[best_idx]
# 递归构建决策树的函数
def _build_tree(self, X, y, features, depth=0):
"""递归构建决策树"""
# 终止条件:所有样本属于同一类别,或达到最大深度,或样本数小于最小样本分裂数
if (len(np.unique(y)) == 1 or
(self.max_depth is not None and depth >= self.max_depth) or
len(y) < self.min_samples_split):
# 返回该节点的类别,使用 Counter 统计出现次数最多的类别
return {'class': Counter(y).most_common(1)[0][0]}
# 选择最佳特征
best_feature = self._choose_best_feature(X, y, features)
# 初始化树节点,包含最佳特征和子节点字典
tree = {'feature': best_feature, 'children': {}}
# 剩余特征列表,去除已选的最佳特征
remaining_features = [f for f in features if f != best_feature]
# 遍历最佳特征的每个唯一值
for value in np.unique(X[best_feature]):
# 提取特征值为 value 时对应的特征子集,去除最佳特征列
subset_X = X[X[best_feature] == value].drop(columns=[best_feature])
# 提取特征值为 value 时对应的目标值子集
subset_y = y[X[best_feature] == value]
# 递归构建子树,深度加 1
tree['children'][value] = self._build_tree(subset_X, subset_y, remaining_features, depth + 1)
# 返回构建好的树节点
return tree
# 训练模型的函数
def fit(self, X, y):
"""训练模型"""
# 将分类特征转换为数值
self.label_encoders = {}
X_encoded = X.copy()
# 遍历每个特征列
for col in X.columns:
# 创建标签编码器,将特征值映射为索引
le = {val: idx for idx, val in enumerate(X[col].unique())}
# 使用标签编码器转换特征列
X_encoded[col] = X[col].map(le)
# 保存标签编码器
self.label_encoders[col] = le
# 将目标值 '否' 和 '是' 转换为 0 和 1
y_encoded = y.map({'否': 0, '是': 1})
# 调用 _build_tree 函数构建决策树
self.tree = self._build_tree(X_encoded, y_encoded, X.columns.tolist())
# 预测函数
def predict(self, X):
"""预测"""
X_encoded = X.copy()
# 遍历每个特征列,使用训练时保存的标签编码器转换特征
for col in X.columns:
X_encoded[col] = X[col].map(self.label_encoders[col])
predictions = []
# 遍历每个样本
for _, row in X_encoded.iterrows():
node = self.tree
# 遍历决策树节点,直到到达叶子节点
while 'children' in node:
feature = node['feature']
value = row[feature]
if value in node['children']:
node = node['children'][value]
else:
break
# 将叶子节点的类别添加到预测结果中
predictions.append(node.get('class', 0))
# 将预测结果 0 和 1 转换回 '否' 和 '是'
return ['是' if p == 1 else '否' for p in predictions]通过递归地选择信息增益率最大的特征进行节点分裂,构建树形决策结构。
主要流程分为四步:
1) 预处理阶段将分类特征编码为数值;
2) 基于信息熵计算各特征的信息增益率,选择最佳分裂特征;
3) 递归构建决策树,直到满足终止条件(纯度100%、达到最大深度或样本不足);
4) 预测时根据特征值沿树结构向下遍历至叶节点获取分类结果。该实现完整包含了C4.5算法的关键特性:使用增益率避免特征取值数目带来的偏差,支持预剪枝控制过拟合,并通过字典嵌套结构清晰表示树的分支关系。
cart_tree.py
import numpy as np
from collections import Counter
# 定义 CART 决策树类
class CARTDecisionTree:
# 初始化函数,设置最大深度和最小样本分裂数
def __init__(self, max_depth=None, min_samples_split=2):
self.max_depth = max_depth # 决策树的最大深度
self.min_samples_split = min_samples_split # 节点分裂所需的最小样本数
self.tree = None # 初始化决策树模型为空
self.label_encoders = None # 初始化标签编码器为空
# 计算基尼系数的函数
def _gini(self, y):
"""计算基尼系数"""
# 使用 np.bincount 统计 y 中每个类别的数量
counts = np.bincount(y)
# 计算每个类别的概率
probabilities = counts / len(y)
# 计算基尼系数,1 减去各类别概率的平方和(仅对概率大于 0 的类别计算)
return 1 - np.sum([p ** 2 for p in probabilities if p > 0])
# 计算基尼指数的函数,基于指定特征 X 进行划分后,集合 𝐷 的不确定性
def _gini_index(self, X, y, feature):
"""计算基尼指数,基于指定特征 X XX 进行划分后,集合 𝐷 的不确定性"""
# 统计特征 feature 的唯一值和对应的数量
values, counts = np.unique(X[feature], return_counts=True)
weighted_gini = 0
# 遍历特征的每个唯一值
for v, c in zip(values, counts):
# 提取特征值为 v 时对应的目标值子集
subset_y = y[X[feature] == v]
# 计算加权基尼指数,即每个子集的基尼系数乘以该子集样本数占总样本数的比例
weighted_gini += (c / len(y)) * self._gini(subset_y)
# 返回加权基尼指数
return weighted_gini
# 选择最佳分裂特征的函数
def _choose_best_feature(self, X, y, features):
"""选择最佳分裂特征"""
# 计算每个特征的基尼指数
gini_indices = [self._gini_index(X, y, f) for f in features]
# 获取基尼指数最小的特征索引(基尼指数越小,划分越纯净)
best_idx = np.argmin(gini_indices)
# 返回最佳分裂特征
return features[best_idx]
# 递归构建决策树的函数
def _build_tree(self, X, y, features, depth=0):
"""递归构建决策树"""
# 终止条件:所有样本属于同一类别,或达到最大深度,或样本数小于最小样本分裂数
if (len(np.unique(y)) == 1 or
(self.max_depth is not None and depth >= self.max_depth) or
len(y) < self.min_samples_split):
# 返回该节点的类别,使用 Counter 统计出现次数最多的类别
return {'class': Counter(y).most_common(1)[0][0]}
# 选择最佳特征
best_feature = self._choose_best_feature(X, y, features)
# 初始化树节点,包含最佳特征和子节点字典
tree = {'feature': best_feature, 'children': {}}
# 剩余特征列表,去除已选的最佳特征
remaining_features = [f for f in features if f != best_feature]
# 遍历最佳特征的每个唯一值
for value in np.unique(X[best_feature]):
# 提取特征值为 value 时对应的特征子集,去除最佳特征列
subset_X = X[X[best_feature] == value].drop(columns=[best_feature])
# 提取特征值为 value 时对应的目标值子集
subset_y = y[X[best_feature] == value]
# 递归构建子树,深度加 1
tree['children'][value] = self._build_tree(subset_X, subset_y, remaining_features, depth + 1)
# 返回构建好的树节点
return tree
# 训练模型的函数
def fit(self, X, y):
"""训练模型"""
# 将分类特征转换为数值(简化实现)
self.label_encoders = {}
X_encoded = X.copy()
# 遍历每个特征列
for col in X.columns:
# 创建标签编码器,将特征值映射为索引
le = {val: idx for idx, val in enumerate(X[col].unique())}
# 使用标签编码器转换特征列
X_encoded[col] = X[col].map(le)
# 保存标签编码器
self.label_encoders[col] = le
# 将目标值 '否' 和 '是' 转换为 0 和 1
y_encoded = y.map({'否': 0, '是': 1})
# 调用 _build_tree 函数构建决策树
self.tree = self._build_tree(X_encoded, y_encoded, X.columns.tolist())
# 预测函数
def predict(self, X):
"""预测"""
X_encoded = X.copy()
# 遍历每个特征列,使用训练时保存的标签编码器转换特征
for col in X.columns:
X_encoded[col] = X[col].map(self.label_encoders[col])
predictions = []
# 遍历每个样本
for _, row in X_encoded.iterrows():
node = self.tree
# 遍历决策树节点,直到到达叶子节点
while 'children' in node:
feature = node['feature']
value = row[feature]
if value in node['children']:
node = node['children'][value]
else:
break
# 将叶子节点的类别添加到预测结果中
predictions.append(node.get('class', 0))
# 将预测结果 0 和 1 转换回 '否' 和 '是'
return ['是' if p == 1 else '否' for p in predictions]通过递归地选择基尼指数最小的特征进行节点分裂,构建二叉树结构的决策模型。
主要流程分为四个关键步骤:
1) 数据预处理阶段将分类特征编码为数值形式;
2) 计算各特征的基尼指数,选择使数据不纯度降低最多的特征作为分裂节点;
3) 递归构建决策树,直到满足终止条件(节点样本纯净、达到最大深度或样本数不足);
4) 预测时根据特征值匹配树的分支结构,最终到达叶节点获得分类结果。该实现完整体现了CART算法的核心特点:使用基尼指数作为分裂标准、支持预剪枝参数控制过拟合、采用字典嵌套结构存储树形关系,并能处理分类特征,最终输出"是"/"否"的贷款审批决策。
main.py
import numpy as np
from data_loader import load_data
from c45_tree import C45DecisionTree
from cart_tree import CARTDecisionTree
def accuracy(y_true, y_pred):
return np.sum(y_true == y_pred) / len(y_true)
def print_tree(node, feature_names, class_names, indent=""):
"""打印决策树结构"""
if 'class' in node:
print(indent + "预测:", class_names[node['class']])
else:
print(indent + "特征:", feature_names[node['feature']] if isinstance(node['feature'], int) else node['feature'])
for value, child in node['children'].items():
print(indent + f"--> 值: {value}")
print_tree(child, feature_names, class_names, indent + " ")
if __name__ == "__main__":
# 加载数据
X_train, X_test, y_train, y_test, feature_names = load_data()
class_names = ['否', '是']
# 训练和评估C4.5
print("\n=== C4.5决策树 ===")
c45 = C45DecisionTree(max_depth=3)
c45.fit(X_train, y_train)
print("测试集准确率:", accuracy(y_test, c45.predict(X_test)))
print("\n决策树结构:")
print_tree(c45.tree, feature_names, class_names)
# 训练和评估CART
print("\n=== CART决策树 ===")
cart = CARTDecisionTree(max_depth=3)
cart.fit(X_train, y_train)
print("测试集准确率:", accuracy(y_test, cart.predict(X_test)))
print("\n决策树结构:")
print_tree(cart.tree, feature_names, class_names)-
数据准备阶段:调用load_data()加载并划分训练集/测试集,同时获取特征名称和类别标签。
-
模型训练与评估:
-
分别实例化C4.5和CART决策树(限制最大深度为3)
-
在训练集上拟合模型
-
在测试集上计算预测准确率
-
-
结果展示:递归打印决策树结构,直观显示每个节点的分裂特征和分支条件,以及叶节点的预测结果。



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 29
29 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)