Naive Bayes Classifier
理论介绍
Naive Bayes Classifier 是一种基于 贝叶斯定理(Bayes’ Theorem) 的概率分类算法,它适用于解决各种机器学习中的分类问题。该算法之所以称为 “Naive” 是因为它假设所有特征是独立的,这在实际情况中可能并不完全成立,但这种简单的假设使得算法非常高效。
Naive Bayes 的核心思想:
- 贝叶斯定理:Naive Bayes 算法基于贝叶斯定理,其公式如下:

- 朴素假设:Naive Bayes 假设特征之间是相互独立的。也就是说,给定某个类别,每个特征独立影响最终结果。虽然这个假设通常不完全成立,但它使得计算大为简化,算法仍然能在实际问题中表现出色。
Naive Bayes 的三种常见变种:
-
高斯(Gaussian) Naive Bayes:用于特征是连续值的数据,假设数据服从正态分布(即高斯分布)。它特别适用于处理连续特征的问题。
-
多项式(Multinomial) Naive Bayes:适用于离散计数数据,例如词频、文件分类等。常用于文本分类任务。
-
伯努利(Bernoulli) Naive Bayes:适用于二元数据,每个特征只有两种可能值(0 和 1)。它也多用于文本分类,尤其是二元特征(如词的出现与否)的情况。
Naive Bayes 分类器的步骤:

Naive Bayes 的优点:
- 简单快速:由于“朴素”的独立假设,Naive Bayes 的计算复杂度较低,能够高效处理大规模数据。
- 适合多类问题:Naive Bayes 能够自然地处理多类分类问题,而不需要对类别进行特殊处理。
- 小样本下表现良好:在样本数量较小的情况下,Naive Bayes 也能提供可靠的分类结果。
- 适合文本分类:由于文本数据的高维稀疏性,Naive Bayes 在文本分类任务中,尤其是垃圾邮件分类、情感分析等任务中表现出色。
Naive Bayes 的局限:
- 特征独立假设不现实:Naive Bayes 假设特征是相互独立的,但在实际问题中,特征往往有相关性,这种假设的违背可能导致分类性能下降。
- 对零概率问题敏感:如果某个特征在训练集中从未在某类中出现,似然概率为零,可能会导致最终的后验概率为零。这可以通过 拉普拉斯平滑(Laplace Smoothing) 进行修正。
使用场景:
- 文本分类:如垃圾邮件检测、新闻分类、情感分析等,通常使用多项式 Naive Bayes 或伯努利 Naive Bayes。
- 推荐系统:可以用来根据用户的特征预测其喜欢的物品类别。
- 医疗诊断:可以通过特征的组合,预测患者可能患有的疾病。
Naive Bayes 分类器的 Python 实现:
使用 scikit-learn 库实现 Naive Bayes 分类器非常简单。以下是基本的代码流程:
from sklearn.naive_bayes import GaussianNB, MultinomialNB, BernoulliNB
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 假设 X 是特征矩阵,y 是标签
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# 使用高斯 Naive Bayes
model = GaussianNB()
model.fit(X_train, y_train) # 训练模型
y_pred = model.predict(X_test) # 进行预测
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
根据不同的特征类型,可以选择不同的 Naive Bayes 变种(GaussianNB, MultinomialNB, BernoulliNB)。
Naive Bayes 算法简单而高效,特别适合初学者和对计算效率要求高的任务。
问题预测示例(是否会购买电脑)
1. Using Machine Learning Naive Bayes Classifier to Solve Problems
1.1. Given the training data in the table below (Buy Computer data), we need to predict the classes of a new example using Naïve Bayes classification. EEE = age<=30, income=medium, student=yes, credit-rating=fair. E1E_1E1 is age<=30, E2E_2E2 is income=medium, E3E_3E3 is student=yes, E4E_4E4 is credit = fair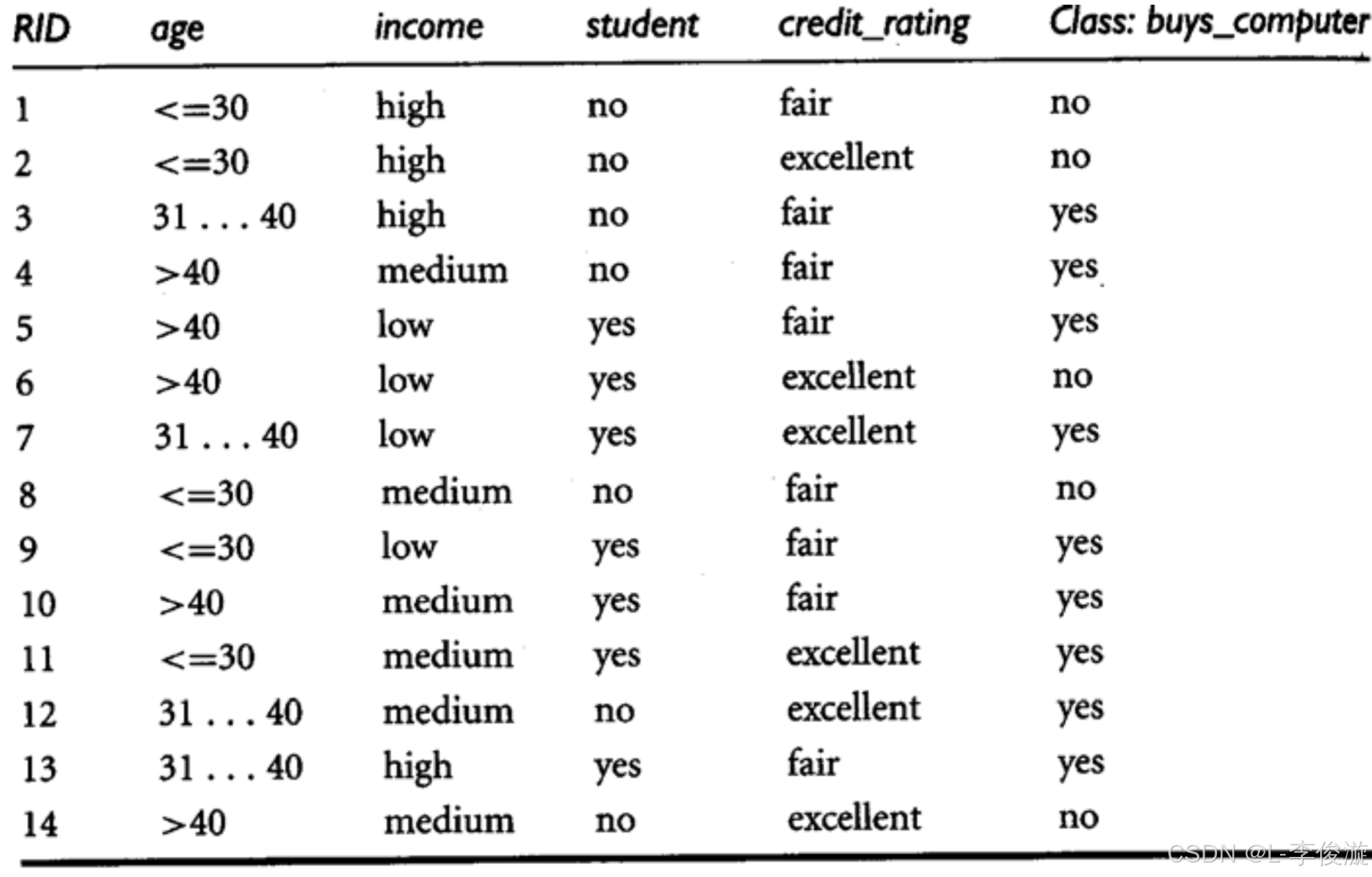
According to given data, please work on the following questions:
-
Please compute P(yes) and P(no).
Solution:
P(yes)=9/14=0.643P(no)=5/14=0.357
-
After obtaining P(yes) and P(no) from (1), please compute P(EiE_iEi |yes) and P(EiE_iEi |no), where i=1,2,3,4.
Solution:
P(E1E_1E1 |yes)= 2/9=0.222 ,class:Buy_Computer(Yes)=9 , [age<=30]=2
P(E2E_2E2 |yes)= 4/9=0.444 ,class:Buy_Computer(Yes)=9 , [income=medium]=4
P(E3E_3E3 |yes)= 6/9=0.667 ,class:Buy_Computer(Yes)=9 , [student=yes]=6
P(E4E_4E4 |yes)= 6/9=0.667 ,class:Buy_Computer(Yes)=9 , [is_credit=fair]=6
P(E1E_1E1 |no)= 3/5=0.6 ,class:Buy_Computer(No)=5 , [age<=30]=3
P(E2E_2E2 |no)= 2/5=0.4 ,class:Buy_Computer(No)=5 , [income=medium]=2
P(E3E_3E3 |no)= 1/5=0.2 ,class:Buy_Computer(No)=5 , [student=yes]=1
P(E4E_4E4 |no)= 2/5=0.4 ,class:Buy_Computer(No)=5 , [is_credit=fair]=2 -
Please compute P(yes|E) and P(no|E).
P(yes│E)=(0.222×0.444×0.667×0.668×0.643)P(E)=0.028P(E)P(yes│E)=\frac{(0.222×0.444×0.667×0.668×0.643)}{P(E)}=\frac{0.028}{P(E)}P(yes│E)=P(E)(0.222×0.444×0.667×0.668×0.643)=P(E)0.028
P(no│E)=(0.6×0.4×0.2×0.4×0.357)P(E)=0.007P(E)P(no│E)=\frac{(0.6×0.4×0.2×0.4×0.357)}{P(E)}=\frac{0.007}{P(E)}P(no│E)=P(E)(0.6×0.4×0.2×0.4×0.357)=P(E)0.007
Hence, the Naïve Bayes classifier predicts buys_computer=yes for the new example.
解题步骤
这段内容展示了如何通过 Naive Bayes 分类器 进行计算,并且基于给定的概率数据预测某个样本的类别(是否会购买电脑)。
第一步:计算 P(yes) 和 P(no)
这是先验概率,表示在总样本中“yes”和“no”类的比例:
- P(yes) = 9/14 = 0.643
- P(no) = 5/14 = 0.357
第二步:计算条件概率 P(EiE_iEi | yes) 和 P(EiE_iEi | no)
这里的 ( E1E_1E1, E2E_2E2,E3E_3E3,E4E_4E4) 是各个特征事件。我们计算每个事件在“yes”和“no”类别下发生的条件概率:
- P(E1E_1E1 | yes) = 2/9 = 0.222 , P(E1E_1E1 | no) = 3/5 = 0.6
- P(E2E_2E2 | yes) = 4/9 = 0.444 , P(E2E_2E2 | no) = 2/5 = 0.4
- P(E3E_3E3 | yes) = 6/9 = 0.667 , P(E3E_3E3 | no) = 1/5 = 0.2
- P(E4E_4E4 | yes) = 6/9 = 0.667 , P(E4E_4E4 | no) = 2/5 = 0.4
第三步:计算 P(yes | E) 和 P(no | E)
通过贝叶斯定理,可以计算后验概率 P(yes | E) 和 P(no | E) 。公式如下:
P(yes∣E)=P(E1∣yes)∗P(E2∣yes)∗P(E3∣yes)∗P(E4∣yes)∗P(yes)P(E)P(yes | E) = \frac{P(E_1 | yes) * P(E_2 | yes) * P(E_3 | yes) * P(E_4 | yes) * P(yes)}{P(E)}P(yes∣E)=P(E)P(E1∣yes)∗P(E2∣yes)∗P(E3∣yes)∗P(E4∣yes)∗P(yes)
P(no∣E)=P(E1∣no)∗P(E2∣no)∗P(E3∣no)∗P(E4∣no)∗P(no)P(E)P(no | E) = \frac{P(E_1 | no) * P(E_2 | no) * P(E_3 | no) * P(E_4 | no) * P(no)}{P(E)}P(no∣E)=P(E)P(E1∣no)∗P(E2∣no)∗P(E3∣no)∗P(E4∣no)∗P(no)
其中, P(E) 是用于标准化的总概率,但因为我们只需要比较 P(yes | E) 和 P(no | E),可以忽略P(E) 来直接比较分子。
计算:
- P(yes∣E)=0.222∗0.444∗0.667∗0.667∗0.643P(E)=0.028P(E)P(yes | E )= \frac{0.222 * 0.444 * 0.667 * 0.667 * 0.643}{P(E)} = \frac{0.028}{P(E)}P(yes∣E)=P(E)0.222∗0.444∗0.667∗0.667∗0.643=P(E)0.028
- P(no∣E)=0.6∗0.4∗0.2∗0.4∗0.357P(E)=0.007P(E)P(no | E )= \frac{0.6 * 0.4 * 0.2 * 0.4 * 0.357}{P(E)} = \frac{0.007}{P(E)}P(no∣E)=P(E)0.6∗0.4∗0.2∗0.4∗0.357=P(E)0.007
结论:
由于 P(yes | E) > P(no | E) ,Naive Bayes 分类器最终预测为 “buys_computer=yes”(即买电脑)。
1.2. Classifying Text by Multinomial Naive Bayes
One place where multinomial naive Bayes is often used is in text classification, where the features are related to word counts or frequencies within the documents to be classified. Here, we will use the sparse word count features from the 20 Newsgroups corpus to show how we might classify these short documents into categories.
Let’s download the data and take a look at the target names:
from sklearn.datasets import fetch_20newsgroups
#fetch_20newsgroups() 是 sklearn.datasets 提供的一个函数,用于加载 20 Newsgroups 数据集,这是一个常用于文本分类任务的基准数据集。数据集中包含来自 20 个不同新闻组(newsgroups)的帖子,主要用于文本分类和自然语言处理任务。
data = fetch_20newsgroups() #从 sklearn 的数据集中加载 20 Newsgroups 数据。这个函数可以加载训练和测试数据集,提供了各种新闻组的文本数据
data.target_names #这个属性返回一个列表,包含所有 20 个新闻组的名称,也就是20 个类别标签。每个类别对应一个特定的新闻组,目标是对这些新闻组的文本进行分类。
For the simplicity, we will select the categories of ‘talk.religion.misc’, ‘soc.religion.christian’, ‘sci.space’, ‘comp.graphics’, and download the training and testing set:
# put above mention in to a list and name it as categories. categories below is empty now.
categories = ['talk.religion.misc', 'soc.religion.christian', 'sci.space', 'comp.graphics']
# Generate training and testing data
train = fetch_20newsgroups(subset='train', categories=categories) #subset='train': 这表示你正在加载训练数据集。训练数据集是用来训练机器学习模型的。
test = fetch_20newsgroups(subset='test', categories=categories) #subset='test': 这表示你正在加载测试数据集。测试数据集是用来评估模型性能的。
# 通过这个参数,你告诉函数只加载与上面 categories 列表中指定的 4 个新闻组相关的数据,而不是整个 20 个类别。
Please print 6th training data. Hint: using data method.
# put your codes here
print(train.data[5])
In order to use this data for machine learning, we need to be able to convert the content of each string into a vector of numbers. For this we will use the TF-IDF vectorizer, and create a pipeline that attaches it to a multinomial naive Bayes classifier:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import make_pipeline
Please create a pipeline that attaches it to a multinomial naive Bayes classifier
# put your codes here
model = make_pipeline(TfidfVectorizer(), MultinomialNB())
With this pipeline, we can apply the model to the training data, and predict labels for the test data.
Hint: using fit method for training and predict method to predict labels on test data.
# put your codes here
model.fit(train.data, train.target)
predictions = model.predict(test.data)
Now that we have predicted the labels for the test data, we can evaluate them to learn about the performance of the classifier. Please use confusion_matrix method to plot confusion matrix.
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
from sklearn.metrics import confusion_matrix
# put your codes here
mat = confusion_matrix(test.target, predictions)
mat
这段代码的目的是从 20 Newsgroups 数据集中筛选指定类别的新闻组,生成训练集和测试集的数据。
详细解释:
categories = ['talk.religion.misc', 'soc.religion.christian', 'sci.space', 'comp.graphics']
- 这里创建了一个名为
categories的列表,包含了 4 个特定的新闻组类别。这个列表指定了要从 20 Newsgroups 数据集中选择的新闻组。你只对这些类别感兴趣:talk.religion.misc: 关于宗教的讨论soc.religion.christian: 关于基督教的讨论sci.space: 关于太空科学的讨论comp.graphics: 关于计算机图形学的讨论
train = fetch_20newsgroups(subset='train', categories=categories)
test = fetch_20newsgroups(subset='test', categories=categories)
fetch_20newsgroups()是加载 20 Newsgroups 数据集的函数。- 参数解释:
subset='train': 这表示你正在加载训练数据集。训练数据集是用来训练机器学习模型的。subset='test': 这表示你正在加载测试数据集。测试数据集是用来评估模型性能的。categories=categories: 通过这个参数,你告诉函数只加载与上面categories列表中指定的 4 个新闻组相关的数据,而不是整个 20 个类别。
因此,这两行代码的作用是:
- 使用
categories中的新闻组类别,从 20 Newsgroups 数据集中提取训练集,并将其存储在train变量中。 - 从相同的新闻组类别中提取测试集,并将其存储在
test变量中。
总结:
这段代码将 20 Newsgroups 数据集的某些子集(四个指定的新闻组类别)加载为训练和测试数据,供后续的文本分类模型使用。
这段代码导入了三个常用的机器学习工具,分别用于文本特征提取、朴素贝叶斯分类器和创建机器学习流水线。下面是详细解释:
1. TfidfVectorizer (来自 sklearn.feature_extraction.text)
from sklearn.feature_extraction.text import TfidfVectorizer
TfidfVectorizer是一种文本特征提取方法。它将原始文本数据转换为基于 TF-IDF(词频-逆文档频率) 的特征向量。- 作用:它根据文本中的词语频率和它们在整个数据集中的重要性来提取特征。词频(Term Frequency, TF)衡量某个词在文档中出现的频率,逆文档频率(Inverse Document Frequency, IDF)则衡量词在整个语料库中是否常见。
- 使用
TfidfVectorizer可以将文本数据转换为数值表示,便于分类器处理。
2. MultinomialNB (来自 sklearn.naive_bayes)
from sklearn.naive_bayes import MultinomialNB
MultinomialNB是一种朴素贝叶斯分类器,特别适用于离散特征数据,常用于文本分类任务。- 作用:它基于贝叶斯定理(Bayes’ Theorem),并假设特征之间相互独立。
MultinomialNB在多项式分布假设下工作,适用于离散计数值,比如文档中的词频。 - 在文本分类任务中,
MultinomialNB经常与TfidfVectorizer一起使用,因为它能够很好地处理基于文本词频(如TF-IDF)的特征。
3. make_pipeline (来自 sklearn.pipeline)
from sklearn.pipeline import make_pipeline
make_pipeline用于创建一个机器学习的流水线(pipeline)。- 作用:流水线可以将多个处理步骤串联起来,形成一个连续的流程。每个步骤都由前一个步骤的输出作为输入,最后一步通常是分类器。
- 在这种情况下,流水线可能会将
TfidfVectorizer(文本转换为特征向量的步骤)和MultinomialNB(分类器)串联在一起,构成一个完整的文本分类流程。通过流水线,你可以一次性执行文本转换和分类,而无需手动地调用每一步。
示例:
你可以通过以下代码将这些工具结合起来构建一个文本分类流水线:
# 创建一个由 TfidfVectorizer 和 MultinomialNB 组成的流水线
model = make_pipeline(TfidfVectorizer(), MultinomialNB())
总结:
TfidfVectorizer:将文本数据转换为 TF-IDF 特征向量。MultinomialNB:基于贝叶斯定理的分类器,适用于处理离散特征(如词频)。make_pipeline:将多个处理步骤串联起来,方便组合特征提取和模型训练流程。
最终,这三者结合在一起,用于文本分类任务中的特征提取和模型构建。
这行代码的作用是创建一个机器学习流水线,将文本数据处理和模型训练的步骤组合在一起,以便简化后续的训练和预测流程。
model = make_pipeline(TfidfVectorizer(), MultinomialNB())
详细解释:
1. TfidfVectorizer()
- 作用:这个步骤会将原始的文本数据转换为TF-IDF(词频-逆文档频率)特征向量。
- 输入:原始文本数据(比如一篇新闻文章或一个文档)。
- 输出:一个稀疏矩阵,每一行代表一个文档,每一列代表一个词语。矩阵的元素是该词在文档中的权重,基于该词的词频(TF)和在整个语料库中的出现情况(IDF)。
- 好处:通过使用 TF-IDF,可以有效地减少像 “the”、“is” 这样常见但信息量较小的词的影响,增强那些具有更高区分度的词的权重。
2. MultinomialNB()
- 作用:这是一个多项式朴素贝叶斯分类器,通常用于文本分类问题。
- 输入:TF-IDF 矩阵(特征向量表示的文档)。
- 输出:类别标签的预测(文本分类结果,比如新闻的类别是“科技”还是“体育”)。
- 工作原理:基于贝叶斯定理,
MultinomialNB假设各个特征(词频)是独立的,并通过学习每个类别中的特征分布,来预测新文本的类别。
3. make_pipeline()
- 作用:将多个步骤组成一个流水线(pipeline)。
- 在这个例子中,它把
TfidfVectorizer()和MultinomialNB()串联在一起。 - 好处:流水线可以将特征提取(从原始文本到特征向量)和模型训练(从特征向量到类别预测)组合在一起。这样做的好处是你只需要调用一个模型,不需要手动进行每一步的转换。
- 当你调用
model.fit()或model.predict()时,流水线会自动执行每个步骤,保持整个过程简洁高效。
- 在这个例子中,它把
举例:
假设你有文本数据 X_train 和相应的类别标签 y_train,你可以用以下方式训练模型:
# 训练模型
model.fit(X_train, y_train)
# 用训练好的模型进行预测
predicted_categories = model.predict(X_test)
总结:
- 这段代码创建了一个由
TfidfVectorizer和MultinomialNB组成的流水线。 - 目的:自动化文本分类任务,处理从文本数据到分类预测的所有步骤。
- 这段代码的作用是训练模型并进行预测,具体操作如下:
详细解释:
model.fit(train.data, train.target)
- 作用:用训练集数据来训练机器学习模型。
- 输入:
train.data:包含训练数据中的文本(新闻组文章)。train.target:包含训练数据中每个文本对应的标签(新闻组类别)。
fit()方法:这是 scikit-learn 中用于训练模型的方法。它会让模型通过学习train.data和train.target之间的关系,学到如何根据文本的特征来预测类别。- 在这个例子中,流水线首先会使用
TfidfVectorizer()将train.data中的文本转换成 TF-IDF 特征向量,然后使用MultinomialNB()根据这些特征向量和train.target中的标签来进行模型训练。
- 输入:
predictions = model.predict(test.data)
- 作用:对测试集的数据进行预测。
- 输入:
test.data:包含测试数据中的文本(这些文本的类别是未知的,你的任务是预测它们的类别)。
predict()方法:用于使用已经训练好的模型对新数据进行预测。在这个例子中,流水线会先将test.data中的文本通过TfidfVectorizer()转换为特征向量,然后利用训练好的MultinomialNB()模型来预测每个文本属于哪个类别。- 输出:
predictions是一个包含预测类别的数组,表示模型对每一条测试数据的预测结果。
- 输入:
整体流程:
-
训练模型:
model.fit(train.data, train.target)会对训练数据进行特征提取(将文本转换为 TF-IDF 特征向量),并根据特征向量和对应的类别标签进行训练。
-
进行预测:
predictions = model.predict(test.data)使用训练好的模型,对测试数据进行特征提取和预测,得到每条测试数据的预测类别。
举例:
如果训练数据 train.data 包含的是不同类别的新闻文章,train.target 包含的是每篇文章对应的类别(例如科技类、体育类等),模型会学会通过文章中的词汇和词频来判断类别。接着,模型会对新文章(即测试集中的文章)进行分类预测,将它们分类为相应的类别。
你还可以进一步评估模型的预测效果,比如计算准确率:
from sklearn.metrics import accuracy_score
# 计算模型的预测准确率
accuracy = accuracy_score(test.target, predictions)
print("Accuracy:", accuracy)
这段代码会计算模型对测试集的预测与实际类别(test.target)的一致性,从而得到分类模型的准确率。
这段代码的目的是通过计算混淆矩阵来评估模型的性能,展示模型在分类任务中的预测结果与实际结果之间的关系。以下是每行代码的解释:
代码解释:
-
import matplotlib.pyplot as plt- 作用:导入
matplotlib.pyplot,这是 Python 中常用的绘图库,支持绘制各种图表。 - 目的:稍后我们可以使用它来可视化混淆矩阵。
- 作用:导入
-
import seaborn as sns; sns.set()- 作用:导入
seaborn,这是基于matplotlib的高级可视化库,能更方便地绘制漂亮的统计图形。 sns.set():这个函数会设置 Seaborn 的默认主题样式,使得绘制的图表美观。
- 作用:导入
-
from sklearn.metrics import confusion_matrix- 作用:从
scikit-learn的metrics模块中导入confusion_matrix函数。 - 目的:用于生成混淆矩阵,它能显示模型的分类结果与实际结果之间的差异。
- 作用:从
-
mat = confusion_matrix(test.target, predictions)- 作用:生成混淆矩阵,保存为变量
mat。 - 输入:
test.target:测试数据的真实类别标签。predictions:模型对测试数据的预测结果。
- 输出:
mat是一个二维数组(矩阵),表示模型分类的结果。矩阵的每一行代表真实类别,每一列代表预测类别。矩阵的元素mat[i][j]表示真实类别为i,但被预测为j的样本数量。 - 混淆矩阵的作用:
- 行代表实际类别。
- 列代表预测类别。
- 对角线元素表示预测正确的样本数量,非对角线元素表示预测错误的样本数量。
- 作用:生成混淆矩阵,保存为变量
举例:
如果你有 3 个类别(如 0, 1, 2),假设模型的实际预测与真实标签的匹配结果如下:
[[5 1 0]
[2 7 1]
[0 1 6]]
- 第 1 行:真实类别是
0,预测为0的有 5 个样本,预测为1的有 1 个样本。 - 第 2 行:真实类别是
1,预测为1的有 7 个样本,但误判为0的有 2 个样本,误判为2的有 1 个样本。 - 第 3 行:真实类别是
2,预测为2的有 6 个样本,误判为1的有 1 个样本。
可视化混淆矩阵:
你可以使用以下代码将混淆矩阵可视化:
# 绘制混淆矩阵
plt.figure(figsize=(10,7))
sns.heatmap(mat, annot=True, fmt='d', cmap='Blues')
plt.xlabel('Predicted')
plt.ylabel('True')
plt.show()
sns.heatmap(mat, annot=True, fmt='d', cmap='Blues'):使用 Seaborn 绘制热力图,annot=True会在每个方格中显示数值,fmt='d'表示以整数格式显示数值,cmap='Blues'指定颜色样式为蓝色渐变。plt.xlabel('Predicted')和plt.ylabel('True'):分别设置横轴和纵轴的标签。
混淆矩阵( confusion matrix)
重新解释一下混淆矩阵的每一行和每一列的含义。混淆矩阵用于显示模型的分类结果,行代表真实类别,列代表预测类别。
假设我们有一个 3 类分类问题(类别为 0, 1, 2),并且混淆矩阵如下:
[[5 1 0]
[2 7 1]
[0 1 6]]
这个矩阵的解释如下:
- 行:代表真实的类别标签。
- 列:代表模型预测的类别。
第 1 行(真实类别是 0 的样本):
[5 1 0]
- 这一行表示所有真实类别是
0的样本的预测结果:- 5 个样本被正确预测为
0(对角线上的数值)。 - 1 个样本被错误预测为
1(预测错误)。 - 0 个样本被错误预测为
2。
- 5 个样本被正确预测为
第 2 行(真实类别是 1 的样本):
[2 7 1]
- 这一行表示所有真实类别是
1的样本的预测结果:- 7 个样本被正确预测为
1(对角线上的数值)。 - 2 个样本被错误预测为
0。 - 1 个样本被错误预测为
2。
- 7 个样本被正确预测为
第 3 行(真实类别是 2 的样本):
[0 1 6]
- 这一行表示所有真实类别是
2的样本的预测结果:- 6 个样本被正确预测为
2(对角线上的数值)。 - 1 个样本被错误预测为
1。 - 0 个样本被错误预测为
0。
- 6 个样本被正确预测为
总结:
- 行表示真实类别,列表示模型的预测类别。
- 对角线上的值表示模型预测正确的数量(即真实类别与预测类别相同)。
- 非对角线的值表示预测错误的数量。
所以,假设有 9 个真实类别为 0 的样本,模型预测时,5 个样本预测正确为 0,1 个被错误预测为 1,0 个被错误预测为 2。
这个解释能帮助你更好地理解混淆矩阵的行和列所代表的含义。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 14
14 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)