11. yolov8的训练和测试
其实,我们就是要制作这种数据集作为训练的数据集。表示没有测到目标,这里需要作具体的修改。这就是训练用的图片。在第一个文件夹进入test文件夹如下,至此,训练和测试的大概步骤就完成了。再进入train文件夹有。进入train文件夹有。
·
1.数据集的准备
首先打开yolov8的文件夹如下:
进入该文件夹的datasets文件夹如下:
再进入该文件夹有
可以看到,有images和labels两个文件夹,下面分别进入两个文件夹:
1. images/

再进入train文件夹有

这就是训练用的图片。进入val文件夹有
2. labels/

进入train文件夹有

以上是对应的4张图片的label 文件,我们打开一个txt文件如下:

这是标签文件.
其实,我们就是要制作这种数据集作为训练的数据集。
2.训练模型
在第一个文件夹进入test文件夹如下,
建立一个1_train.py文件,里面的代码如下:
from ultralytics import YOLO
model = YOLO("yolov8n.yaml").load("yolov8n.pt")
if __name__=="__main__":
results = model.train(data = "coco8-seg.yaml", epochs = 100, imgsz=640)
# metrics = model.val()运行这个代码就可以训练了,训练结果如下:
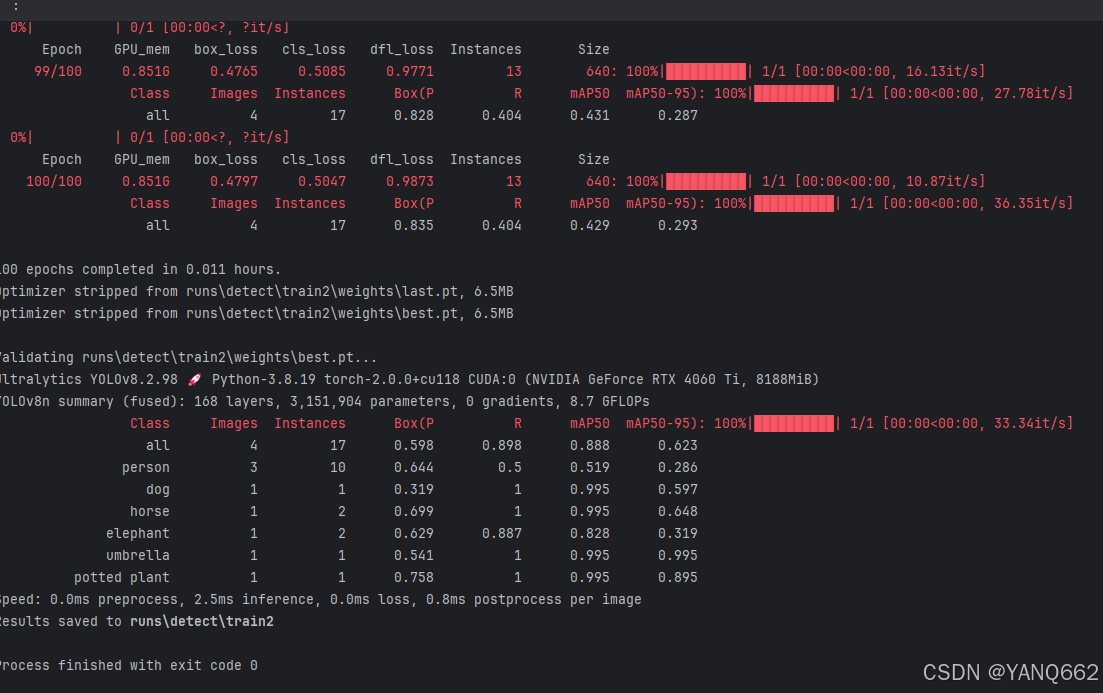
训练的模型如下:
至此,训练结束!!!
3.预测模型
和训练一样,进入test文件夹,建立2_predict.py文件,代码如下:
from ultralytics import YOLO
#from PIL import Image
import cv2
model = YOLO("yolov8n.pt")
# # 接受所有格式-image/dir/Path/URL/video/PIL/ndarray。0用于网络摄像头
# results = model.predict(source="0")
# results = model.predict(source="folder", show=True) # 展示预测结果
# # from PIL
# im1 = Image.open("img1.jpg")
# results = model.predict(source=im1, save=True) # 保存绘制的图像
# from ndarray
im2 = cv2.imread("img2.jpg")
results = model.predict(source=im2, save=True, save_txt=True) # 将预测保存为标签
print()
for item in results:
if item == "name":
print(item)
if item == "save_dir":
print(item)
if item == "path":
print(item)
# # from list of PIL/ndarray
# results = model.predict(source=[im1, im2])
测试效果如下:
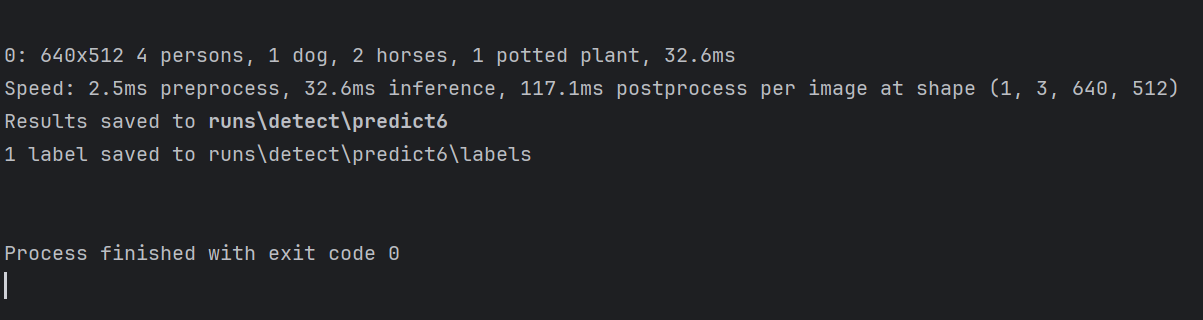
我们根据提示,进入文件夹 runs\detect\predict6 找到图片image0.jpg,打开图片的测试结果如下:

至此,训练和测试的大概步骤就完成了。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)