手把手教你在RT-DETR中添加注意力机制
手把手教你在RT-DETR中添加注意力机制
·
RT-DETR中添加注意力机制
1.将相关代码复制到nn.modules.conv.py
class SimAM(torch.nn.Module):
def __init__(self, e_lambda=1e-4):
super(SimAM, self).__init__()
self.activaton = nn.Sigmoid()
self.e_lambda = e_lambda
def __repr__(self):
s = self.__class__.__name__ + '('
s += ('lambda=%f)' % self.e_lambda)
return s
@staticmethod
def get_module_name():
return "simam"
def forward(self, x):
b, c, h, w = x.size()
n = w * h - 1
x_minus_mu_square = (x - x.mean(dim=[2, 3], keepdim=True)).pow(2)
y = x_minus_mu_square / (4 * (x_minus_mu_square.sum(dim=[2, 3], keepdim=True) / n + self.e_lambda)) + 0.5
return x * self.activaton(y)
2.在conv.py中添加名字
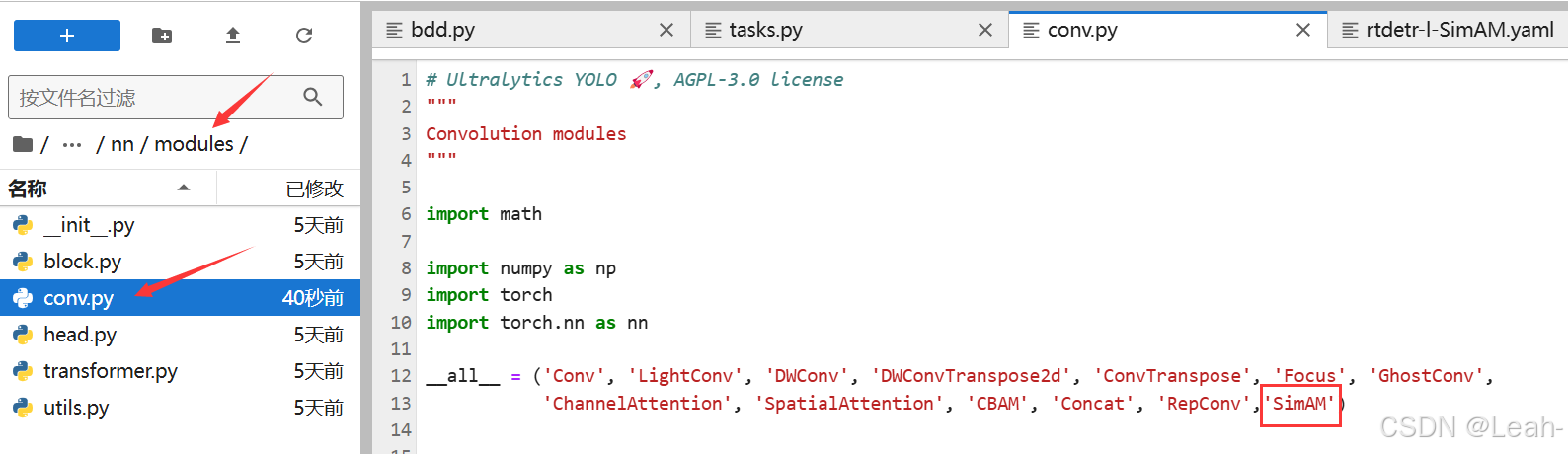
3.在nn/modules/init.py添加名字

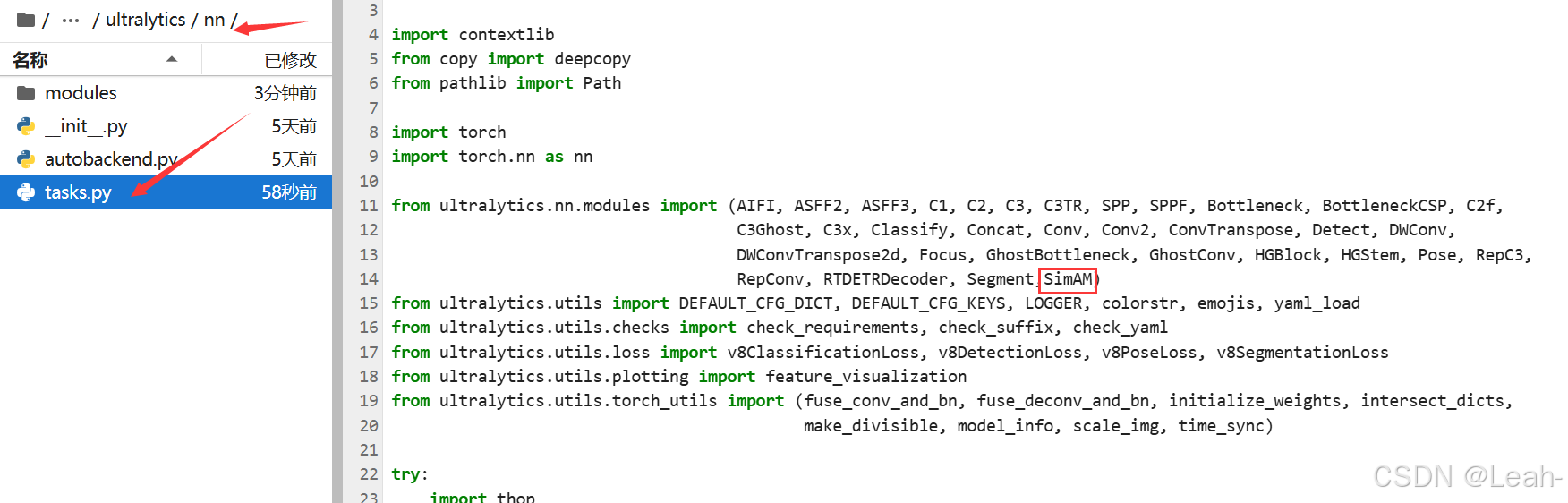
4.在nn/tasks.py添加名字以及相关配置
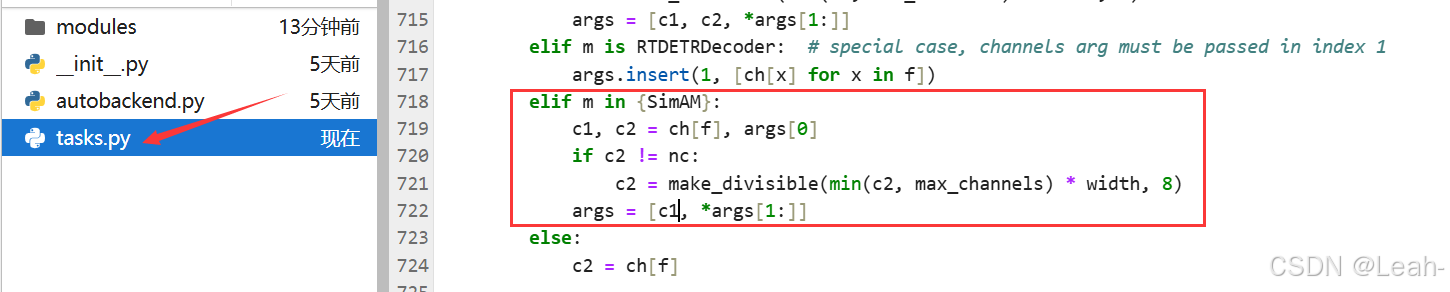
elif m in {SimAM}:
c1, c2 = [ch[f], args[0]]
if c2 != nc:
c2 = make_divisible(min(c2, max_channels) * width, 8)
args = [c1, *args[1:]]
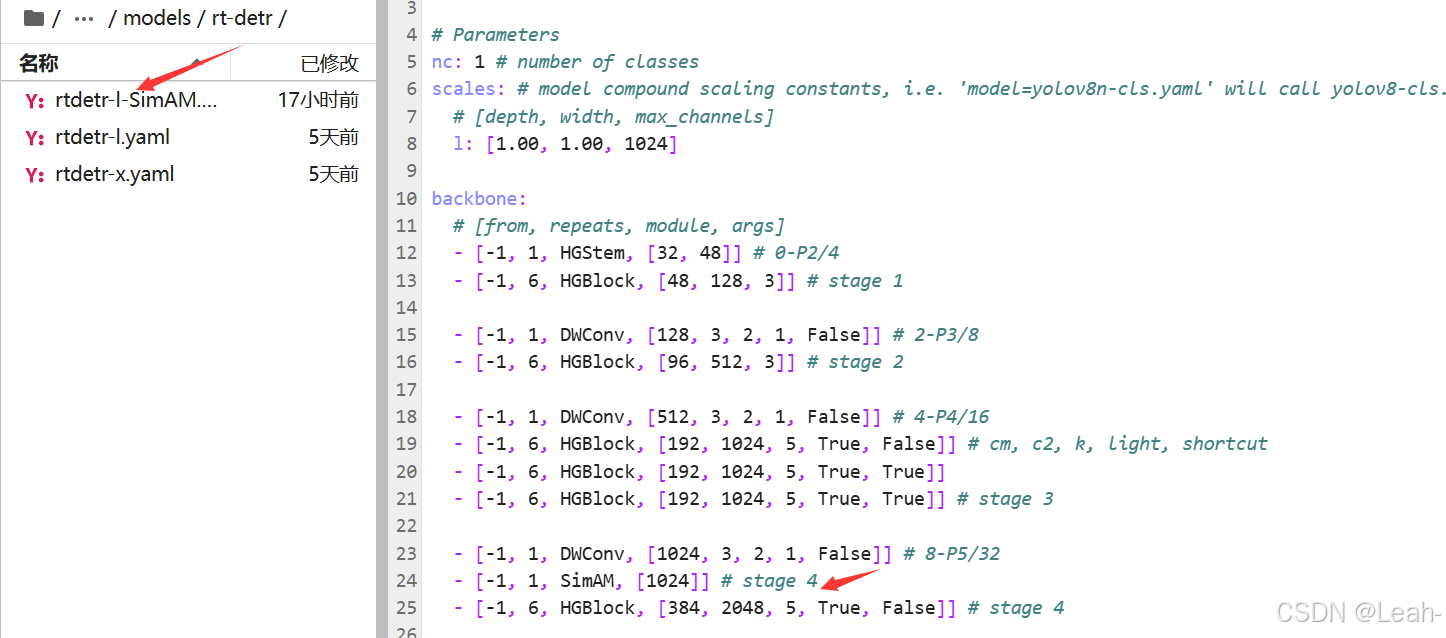
5.定义相关的yaml文件,修改参数(在定义函数中查找)
# Ultralytics YOLO 🚀, AGPL-3.0 license
# RT-DETR-l object detection model with P3-P5 outputs. For details see https://docs.ultralytics.com/models/rtdetr
# Parameters
nc: 2 # number of classes根据你的数据集进行调整
scales: # model compound scaling constants, i.e. 'model=yolov8n-cls.yaml' will call yolov8-cls.yaml with scale 'n'
# [depth, width, max_channels]
l: [1.00, 1.00, 1024]
backbone:
# [from, repeats, module, args]
- [-1, 1, HGStem, [32, 48]] # 0-P2/4
- [-1, 6, HGBlock, [48, 128, 3]] # stage 1
- [-1, 1, DWConv, [128, 3, 2, 1, False]] # 2-P3/8
- [-1, 6, HGBlock, [96, 512, 3]] # stage 2
- [-1, 1, DWConv, [512, 3, 2, 1, False]] # 4-P4/16
- [-1, 6, HGBlock, [192, 1024, 5, True, False]] # cm, c2, k, light, shortcut
- [-1, 6, HGBlock, [192, 1024, 5, True, True]]
- [-1, 6, HGBlock, [192, 1024, 5, True, True]] # stage 3
- [-1, 1, DWConv, [1024, 3, 2, 1, False]] # 8-P5/32
- [-1, 1, SimAM, [1024]] # stage 4
- [-1, 6, HGBlock, [384, 2048, 5, True, False]] # stage 4
head:
- [-1, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 10 input_proj.2
- [-1, 1, AIFI, [1024, 8]]
- [-1, 1, Conv, [256, 1, 1]] # 12, Y5, lateral_convs.0
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [7, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 14 input_proj.1
- [[-2, -1], 1, Concat, [1]]
- [-1, 3, RepC3, [256]] # 16, fpn_blocks.0
- [-1, 1, Conv, [256, 1, 1]] # 17, Y4, lateral_convs.1
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [3, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 19 input_proj.0
- [[-2, -1], 1, Concat, [1]] # cat backbone P4
- [-1, 3, RepC3, [256]] # X3 (21), fpn_blocks.1
- [-1, 1, Conv, [256, 3, 2]] # 22, downsample_convs.0
- [[-1, 18], 1, Concat, [1]] # cat Y4
- [-1, 3, RepC3, [256]] # F4 (24), pan_blocks.0
- [-1, 1, Conv, [256, 3, 2]] # 25, downsample_convs.1
- [[-1, 13], 1, Concat, [1]] # cat Y5
- [-1, 3, RepC3, [256]] # F5 (27), pan_blocks.1
- [[22, 25, 28], 1, RTDETRDecoder, [nc]] # Detect(P3, P4, P5)
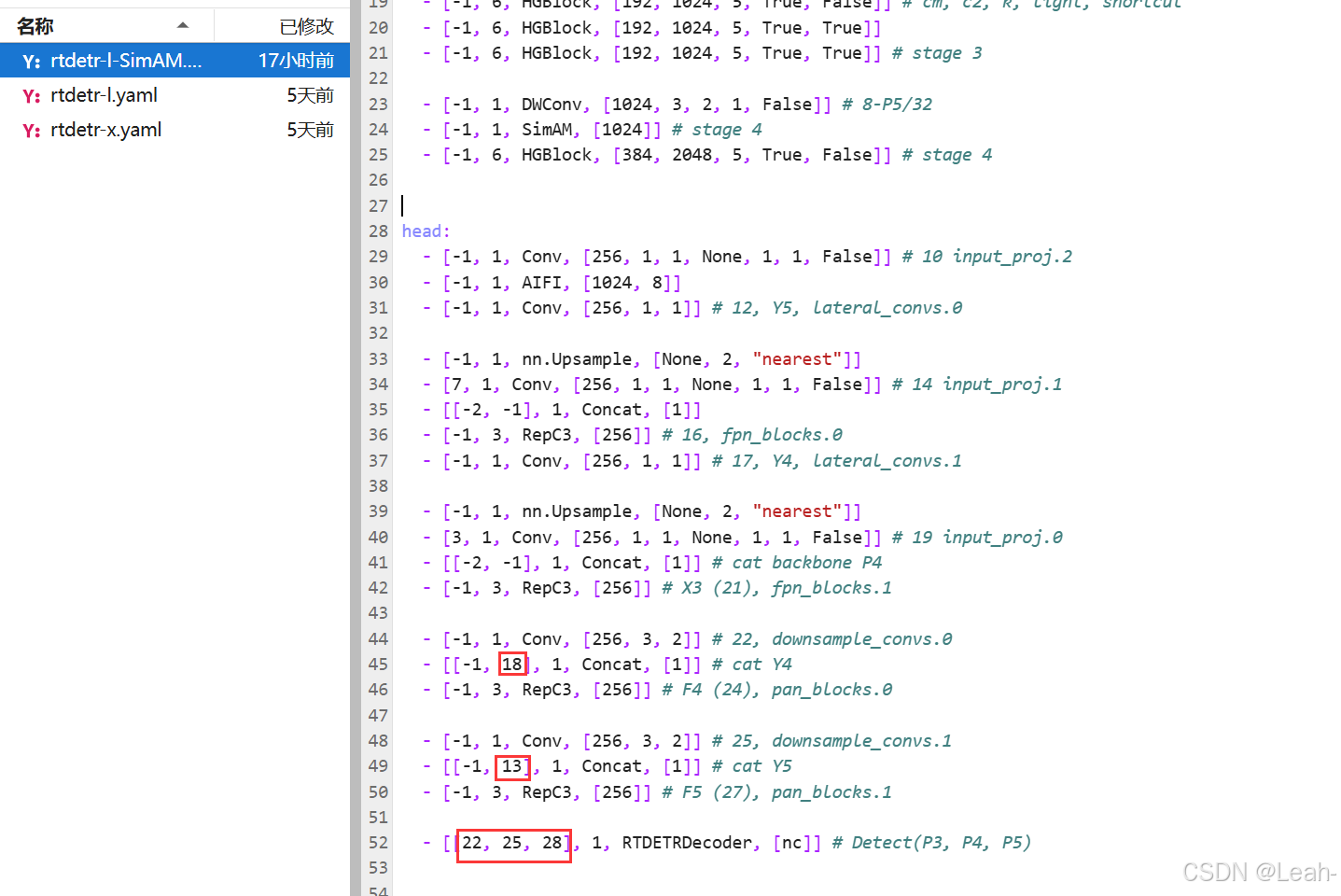
6.创建test_SimAM.py测试是否添加成功
在ultralytics文件下创建test_SimAM.py
from ultralytics import RTDETR
from ultralytics.utils import LINUX, ONLINE, ROOT, SETTINGS
CFG = '/root/ultralytics/ultralytics/cfg/models/rt-detr/rtdetr-l-SimAM.yaml' # 确保路径正确
def test_model_forward():
model = RTDETR(CFG)
model.info(verbose=True) # 输出模型结构
#results = model(SOURCE)
#print(results)
if __name__ == '__main__':
test_model_forward()
未加入SimAM的模型结构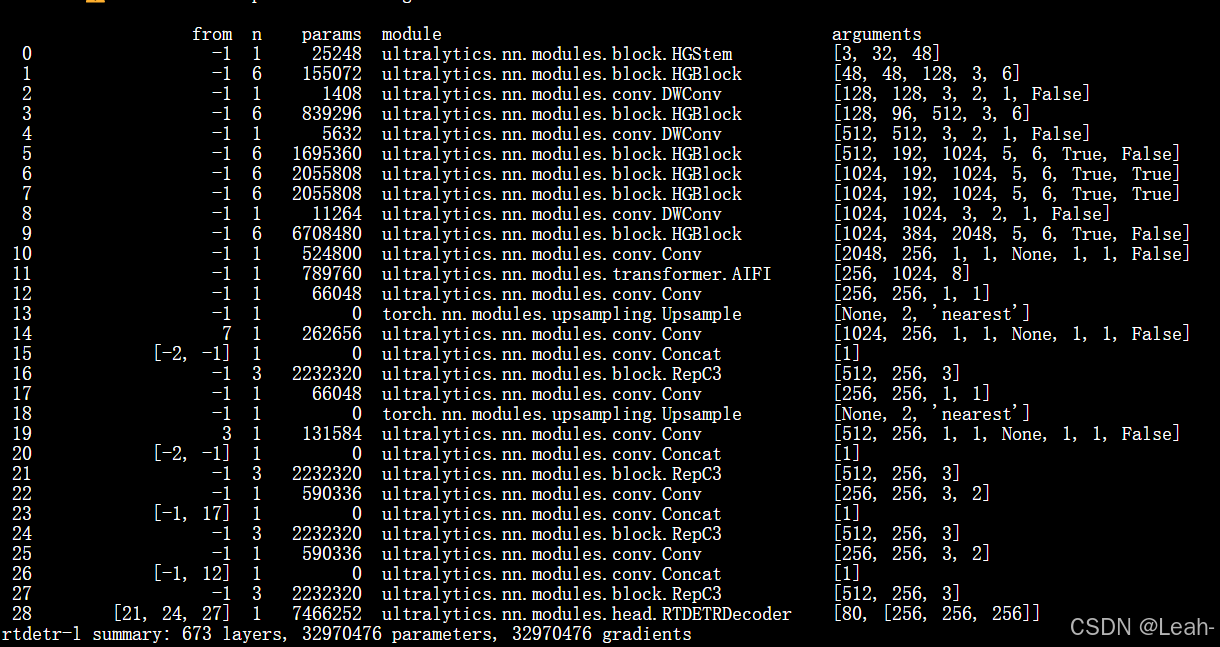
加入SimAM注意力机制的模型结构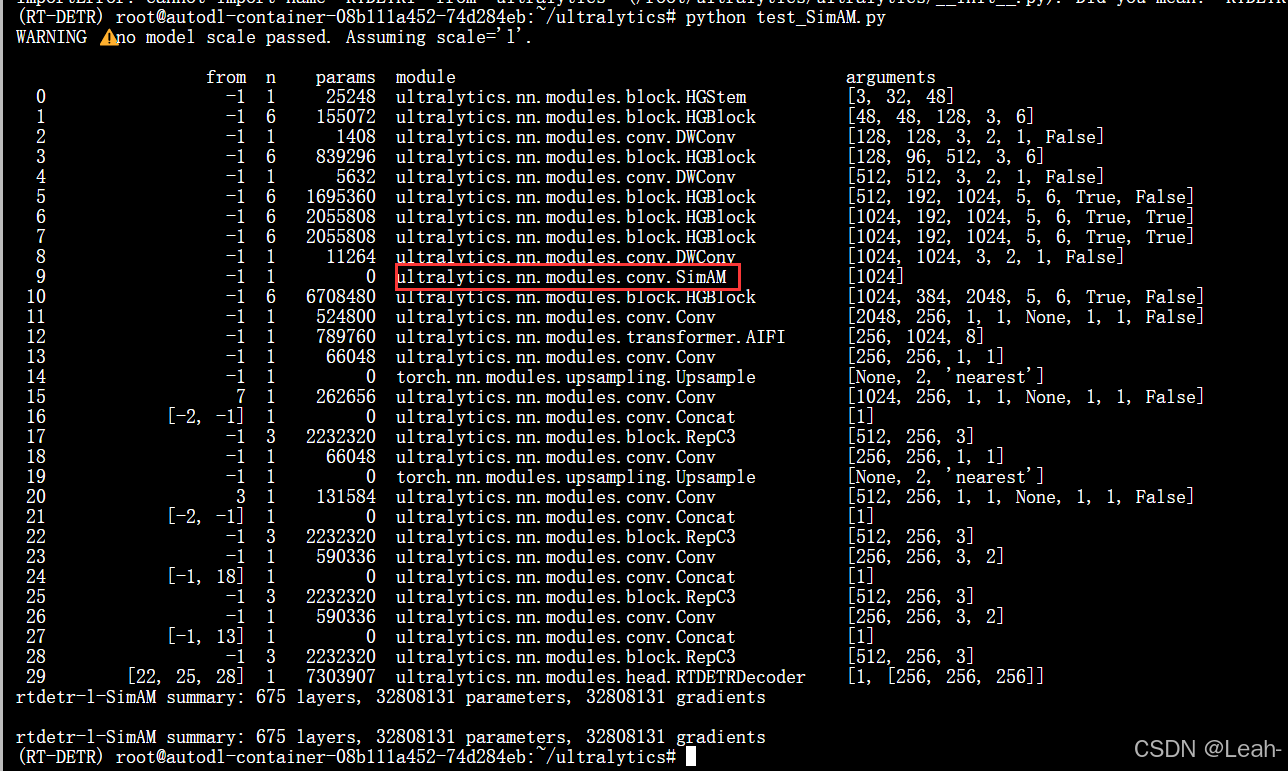
7.训练模型时出现keyerror:SimAM
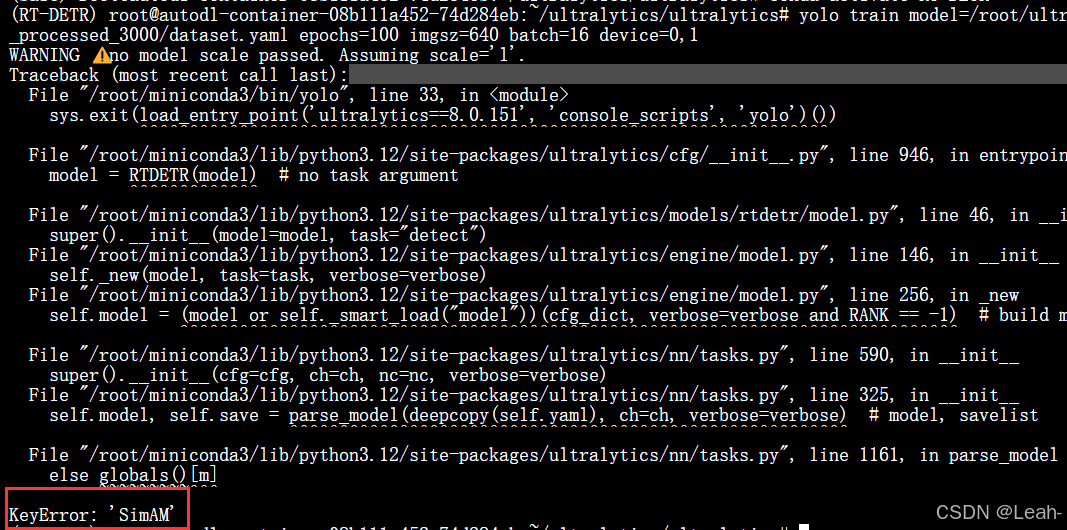
在根目录新建一个main.py,然后使用命令行进行运行
from ultralytics import RTDETR
if __name__ == '__main__':
model = RTDETR('/root/ultralytics/ultralytics/cfg/models/rt-detr/rtdetr-l-SimAM.yaml')
model.train(
data='/root/ultralytics/Datasets/BDD_processed_3000/dataset.yaml',
epochs=100,
imgsz=640,
batch=16,
device='0,1'
)
参考资料
RT-DETR改进入门篇 | 手把手讲解改进模块如何实现高效涨点,以SimAM注意力模块为例
最新!YOLOv8添加注意力机制——轻松上手

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)