【推荐系统】协同过滤
介绍了推荐系统的经典召回算法
协同过滤
1.1 核心思想:
协同过滤是推荐系统中的经典算法,它通过用户与物品之间的交互行为来衡量物品或用户之间的相似性,而不考虑用户或物品的自身属性。这是符合生活经验的,例如对于两个年龄、性别、学历等硬性指标都完全一致的两人,他们的喜好可能千差万别;而对于这些硬性属性完全不同的两人,他们也可能会拥有相同的兴趣爱好。因此,希望推荐系统将前一种情况视为不同类用户,而将后一种情况视为相似用户,这就是协同过滤的基本思想。
1.2 相似性度量方法:
-
余弦相似度 :
【 应用方法】:
- 建立用户-物品的交互矩阵
,其中m为用户数量,n为物品数量,矩阵填充为用户与物品的交互情况。(例如,用0和1表示用户是否点赞该物品;用分数表示用户对物品的喜爱程度)
- 若要计算用户i与用户j之间的相似度,则提取出行向量
,计算二者的余弦相似度。注意!若采用字典的方式来进行存储,只需要遍历二者共同交互过的物品即可。这是因为,若用户没有交互过一个物品,则交互矩阵对应位置的元素为0,做内积计算之后的结果也为0。
- 若要计算物品k与物品p之间的相似度,则提取出列向量
,计算二者的余弦相似度。
【 细节】:交互矩阵在实际场景下是很稀疏的,因此根据userCF/itemCF选择合适的字典进行存储。
【使用场景】:余弦相似度广泛应用于文本相似度、用户相似度、文本相似度的度量。
UserCF:
{"user1":["item1","item2",..],
"user2":["item1","item2",..],
"user3":["item1","item2",..]}
ItemCF:
{"Item1":["user1","user2",...],
"Item2":["user1","user2",...],
"Item3":["user1","user2",...],
-
皮尔逊相关系数:

【评价】:皮尔逊相关系数本质上仍为余弦相似度,但是增加了中心化处理。
【使用场景】:
- 可以用于度量两个变量的变化趋势是否一致。可以用于消除用户评分尺度差异的影响。例如用户1习惯打高分[3,4,5],用户2习惯打低分[1,2,3],虽然评分的绝对值相差较大,但是他们对于这三个物品的喜好程度趋势是相似的,采用皮尔逊系数可以更好地捕捉到这种特性。
- 不适合用于评估布尔值(0,1)之间的相关性。
UserCF
1.1 UserCF进行物品推荐流程:
- 计算用户相似性矩阵
- 给定用户ID,从用户相似性矩阵中找到与目标用户最相似的n个用户
- 根据n个用户对候选物品的评分以及与目标用户的相似度,计算目标用户对候选物品的评分:

- 将兴趣分数高的候选物品推荐给目标用户
- 【目标用户→相似用户→物品评分】
1.2 代码实现:
# 创建用户与物品的交互矩阵
def loadData():
users = {'Alice': {'A': 5, 'B': 3, 'C': 4, 'D': 4},
'user1': {'A': 3, 'B': 1, 'C': 2, 'D': 3, 'E': 3},
'user2': {'A': 4, 'B': 3, 'C': 4, 'D': 3, 'E': 5},
'user3': {'A': 3, 'B': 3, 'C': 1, 'D': 5, 'E': 4},
'user4': {'A': 1, 'B': 5, 'C': 5, 'D': 2, 'E': 1}
}
return users
# 计算用户相似性矩阵
user_matrix = loadData() // 创建一个单位矩阵,对角线上的元素为1,其余元素均为0
u2u_sim = pd.DataFrame(
np.identity(len(user_matrix)),
index=user_matrix.keys(),
columns=user_matrix.keys(),
)
for user1,item1 in user_matrix.items():
for user2,item2 in user_matrix.items():
if user1 == user2:
continue
common_keys = set(item1.keys())& set(item2.keys()) // 提取用户共同交互过的物品
vec1=[]
vec2=[]
for key in common_keys:
vec1.append(item1[key])
vec2.append(item2[key])
u2u_sim[user1][user2] = np.corrcoef(vec1,vec2)[0][1] //皮尔逊相关系数的返回结果是一个n×n的矩阵,n为向量长度,对角线元素为1,其余位置为相关性系数
----------------------------------------------------------------
Alice user1 user2 user3 user4
Alice 1.000000 0.852803 0.707107 0.000000 -0.792118
user1 0.852803 1.000000 0.467707 0.489956 -0.900149
user2 0.707107 0.467707 1.000000 -0.161165 -0.466569
user3 0.000000 0.489956 -0.161165 1.000000 -0.641503
user4 -0.792118 -0.900149 -0.466569 -0.641503 1.000000
3.90659966456864
------------------------------------------------------------------
# 提取与Alice最相似的n个用户
target_user = 'Alice'
num = 2
sim_user = u2u_sim[target_user].sort_values(ascending=False)[1:num+1].index.tolist()
------------------
['user1', 'user2']
------------------
# 计算Alice对物品E的兴趣分数
weighted_scores = 0.
corr_values_sum = 0.
target_item = 'E'
for user in sim_user:
weighted_scores += user_matrix[user][target_item]*u2u_sim[target_user][user]
corr_values_sum += u2u_sim[target_user][user]
final_score = weighted_scores/corr_values_sum
----------------
3.90659966456864
----------------1.3 UserCF进行召回流程:
- 给定用户ID,从用户相似性矩阵中找到与该用户最相似的n个用户
- 返回这n个用户最近交互过的k个物品
- 召回nk个物品
ItemCF
1.1 ItemCF进行物品推荐流程:
- 计算物品相似性矩阵
- 给定候选物品,从物品相似性矩阵中找到最相似的n个物品
- 根据目标用户对这n个物品的评分以及与物品间的相似度,计算目标用户对候选物品的评分
- 【候选物品→物品相似度→物品评分】
1.2 ItemCF进行召回流程:
- 获取用户ID,获取用户最近交互过的k个物品
- 从物品相似度矩阵中获取与这k个物品最相似的n个物品
- 召回nk个物品
1.3 ItemCF的物品相似度公式理解:
 假设与物品i交互过的用户列表为[0,1,0,1],与物品j交互过的用户列表为[1,1,0,1],那么这两个向量的内积为:(0×1+1×1+0×0+1×1)=2,即同时交互过物品i和物品j的用户数量,等价于标准itemCF计算公式的分子。
假设与物品i交互过的用户列表为[0,1,0,1],与物品j交互过的用户列表为[1,1,0,1],那么这两个向量的内积为:(0×1+1×1+0×0+1×1)=2,即同时交互过物品i和物品j的用户数量,等价于标准itemCF计算公式的分子。
1.4 标准itemCF的代码实现:
# 标准itemCF的物品相似性矩阵计算
from collections import defaultdict
import math
user_item_dict = {
"user1": ["item1", "item2", "item3"],
"user2": ["item1", "item3"]
}
# 统计每个物品被哪些用户喜欢
item_users = defaultdict(set)
for user, items in user_item_dict.items():
for item in items:
item_users[item].add(user)
# 计算物品之间的相似度
i2i_sim = defaultdict(dict)
for item, users in item_users.items():
for other_item, other_users in item_users.items():
if item == other_item:
continue
common_users = len(users.intersection(other_users))
i2i_sim[item][other_item] = common_users / math.sqrt(len(users) * len(other_users))
print(i2i_sim)1.5 ItemCF优化思路:
- 用户存在不同的给分偏好,有的用户倾向于给高分,有的用户倾向于给低分:事先对用户的评分进行归一化 / 皮尔逊相关系数
- 对活跃用户的惩罚:引入归一化因子,降低点击数量多的用户对物品相似度的增量。(天池新闻推荐大赛baseline所采用的方法)
norm_factor = 1 / math.log(1 + user_click_count[user]) - 对热门物品的惩罚:
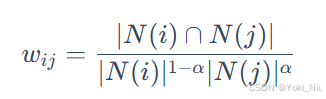
- 对活跃用户的惩罚:
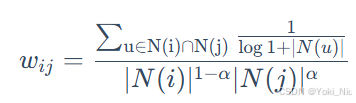
- 有的物品虽然有大量的共现用户,但他们来自于同一个小圈子,因此对物品相似度的增量应当降低。 → Swing模型
- 关联规则+协同过滤:若还有其他因素会对物品相似度产生正向或负向的影响,则将其转换为>1或<1的权重,乘在物品的相似度增量上。(UserCF同理)
Swing模型:
1.1 核心思想:
在itemCF中,若用户i和用户j同时喜欢物品a和物品b,即可认为这两件物品相似。但是如果用户i和用户j来自于同一个小圈子,他们所接触到的信息类似,因此喜欢的物品也大多相同,那么这些物品虽然有共同的受众,但是依然不能说明它们相似。反之,若用户i和用户j喜欢的物品基本不同,但是他们都喜欢物品c和物品d,那么很大程度上能说明物品c和物品d是相似的。
1.2 计算公式:
若两个用户喜欢的物品重叠越大,则他们对物品相似度的增量越小。
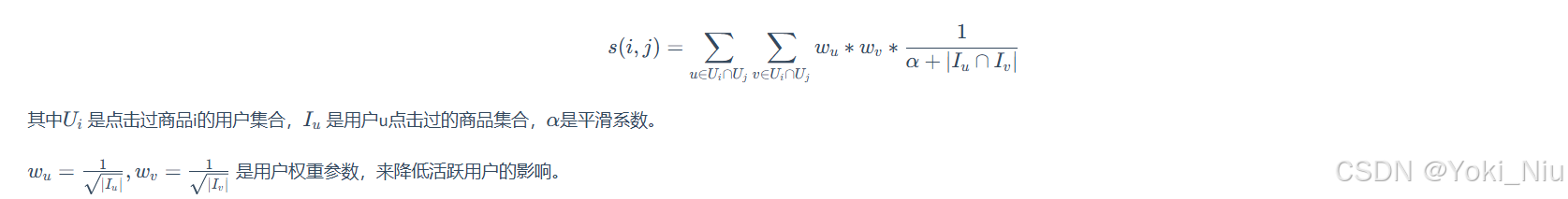
1.3 代码实现:
from itertools import combinations
# 用户 - 物品交互字典,键为用户 ID,值为用户交互过的物品集合
u_items = {
'user1': {'item1', 'item2', 'item3'},
'user2': {'item1', 'item3', 'item4'},
'user3': {'item2', 'item3', 'item5'},
'user4': {'item1', 'item2', 'item5'}
}
# 物品 - 用户交互字典,键为物品 ID,值为与该物品有交互的用户集合
i_users = {
'item1': {'user1', 'user2', 'user4'},
'item2': {'user1', 'user3', 'user4'},
'item3': {'user1', 'user2', 'user3'},
'item4': {'user2'},
'item5': {'user3', 'user4'}
}
# 定义 alpha 参数
alpha = 1
def swing_model(u_items, i_users):
# print([i for i in i_users.values()][:5])
# print([i for i in u_items.values()][:5])
# 获取全排列组合对: [('item1', 'item2'), ('item1', 'item3'), ('item1', 'item4'), ('item1', 'item5'), ('item2', 'item3'), ('item2', 'item4'), ('item2', 'item5'), ('item3', 'item4'), ('item3', 'item5'), ('item4', 'item5')]
item_pairs = list(combinations(i_users.keys(), 2))
print("item pairs length:{}".format(len(item_pairs)))
item_sim_dict = dict()
for (i, j) in item_pairs:
# combinations(i_users[i] & i_users[j], 2):此操作会从 i_users[i] 和 i_users[j] 的交集集合里选取元素,生成所有可能的包含 2 个元素的组合。例如,若交集集合为 {1, 2, 3},那么 combinations({1, 2, 3}, 2) 会生成 (1, 2)、(1, 3)、(2, 3) 这些组合。
user_pairs = list(combinations(i_users[i] & i_users[j], 2)) #item_i和item_j对应的user取交集后全排列 得到user对
result = 0
for (u, v) in user_pairs:
# list(u_items[u] & u_items[v]).__len__() 为用户1与用户2共同交互过的物品列表的长度
result += 1 / (alpha + list(u_items[u] & u_items[v]).__len__()) #分数公式
if result != 0 :
item_sim_dict.setdefault(i, dict())
item_sim_dict[i][j] = format(result, '.6f')
return item_sim_dict 协同过滤算法小结:
1.1 算法缺陷:
- 数据稀疏:当一个系统中用户和物品数量都很大时,用户交互过的物品只占很少的部分,导致用户-物品矩阵非常稀疏。→ 矩阵分解
- 冷启动问题:新用户和新物品没有足够的行为数据,难以被系统准确推荐。→采用基于内容embedding的协同过滤。
- 同质化推荐:热门物品能够获得与更多用户的交互,在相似度计算中更容易被推荐。 →对热门物品进行惩罚。
- 实时性差、占用内存大:UserCF和ItemCF需要维护一个用户/物品相似性矩阵,若用户或物品的数量很大,则矩阵的维度成O(n^2)增长。且每一次用户-物品的交互行为更新后,都需要重新计算相似性矩阵,难以实时捕捉用户和物品的特征。→ 聚类方法,减少计算量 / 采用时间序列模型来捕获用户的兴趣变化。
- 仅考虑了用户与物品的交互性,未考虑用户和物品的其他属性特征。→ 深度学习模型/ 特征交叉融合
1.2 思考:
- 什么时候使用UserCF和ItemCF? 答:UserCF适用于用户少、物品多、时效性强的场合。例如新闻推荐、新信息推荐;ItemCF适用于物品少、用户多、用户兴趣固定持久,物品更新速度慢的场合,例如艺术品、电影、音乐推荐。
- 协同过滤算法的缺点,如何改进?答:如上
- 相似度计算方法的对比?答:余弦相似度容易受到用户打分偏好的影响,而皮尔逊相似度对用户打分进行了中心化处理,可以消除打分偏好的影响,反映出用户间真实的喜好相似性。
矩阵分解:
1.1 基本思想:
将用户-物品的共现矩阵m×n,分解成用户矩阵m×k和物品矩阵k×n,其中k为隐向量的维度,是需要调节的参数,要根据数据量的大小,权衡计算量和精确度。
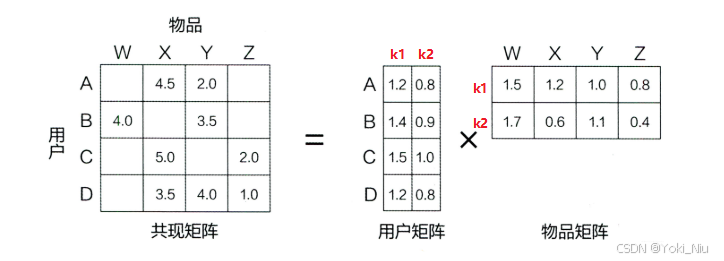
1.2 评分预测:
 1.3 矩阵分解的优缺点:
1.3 矩阵分解的优缺点:
- 优点:
- 泛化能力强: 一定程度上解决了稀疏问题
- 空间复杂度低: 由于用户和物品都用隐向量的形式存放, 少了用户和物品相似度矩阵, 空间复杂度由n^2降到了(n+m)∗f
- 更好的扩展性和灵活性:矩阵分解的最终产物是用户和物品隐向量, 这个深度学习的embedding思想不谋而合, 因此矩阵分解的结果非常便于与其他特征进行组合和拼接, 并可以与深度学习无缝结合
- 缺点:
- 矩阵分解算法依然是只用到了评分矩阵, 没有考虑到用户特征,物品特征和上下文特征, 这使得矩阵分解丧失了利用很多有效信息的机会。
- 同时在缺乏用户历史行为的时候, 无法进行有效的推荐。
- 为了解决这个问题, 逻辑回归模型及后续的因子分解机模型, 凭借其天然的融合不同特征的能力, 逐渐在推荐系统领域得到了更广泛的应用。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)