【深度学习】textCNN论文与原理
前言文本分类是自然语言处理中一个比较基础与常见的任务。咱也不谈传统的文本分类方法,就看看这个使用CNN是如何进行文本分类了,听说效果还不错。如果CNN不是很了解的话,可以看看我之前的文章:【深度学习】卷积神经网络-CNN简单理论介绍 、【深度学习】卷积神经网络-图片分类案例(pytorch实现),当然既然是一种深度学习方法进行文本分类,跑不了使用词向量相关内容,所以读者也是需要有一定词向量(也就是
前言
文本分类是自然语言处理中一个比较基础与常见的任务。咱也不谈传统的文本分类方法,就看看这个使用CNN是如何进行文本分类了,听说效果还不错。如果CNN不是很了解的话,可以看看我之前的文章:【深度学习】卷积神经网络-CNN简单理论介绍 、【深度学习】卷积神经网络-图片分类案例(pytorch实现),当然既然是一种深度学习方法进行文本分类,跑不了使用词向量相关内容,所以读者也是需要有一定词向量(也就是词语的一种分布式表示而已)的概念。对于使用CNN进行文本的原论文地址如下:https://arxiv.org/abs/1408.5882 感兴趣的话,可自行下载原文。
那么废话不多说,我们来一起看看论文主要内容与模型设计。
1 textcnn网络结构
文中给出的网络模型如下:
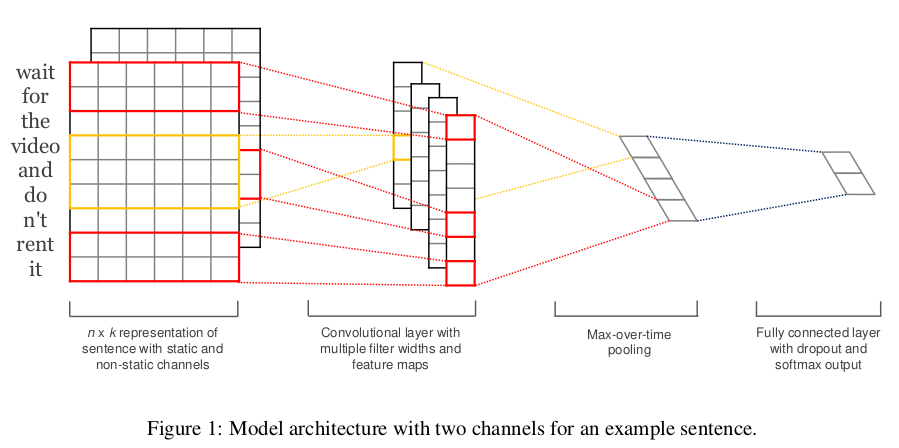
从图中可以看出,模型还是很简单的。如果上图看不懂(涉及多个通道),我们也可以看看网上流行的另一张图(来自于论文:A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional
Neural Networks for Sentence Classification
):
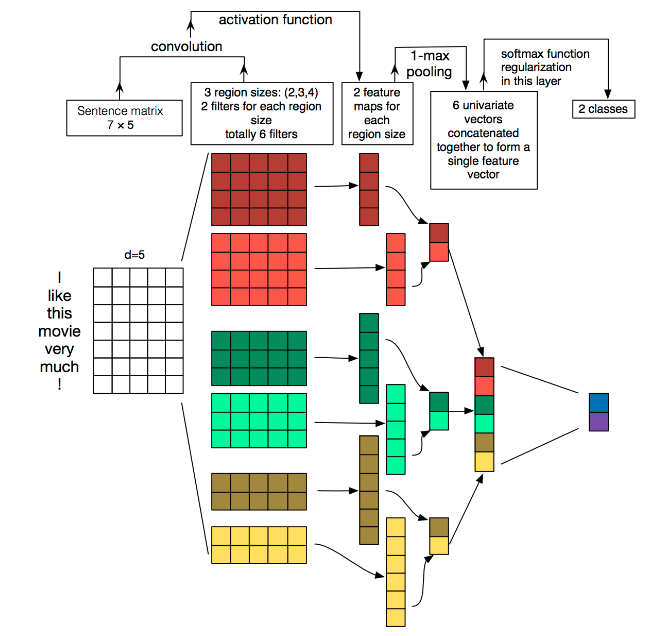
这里我们就按照上图去讲解这个模型。模型包含的模块如下:
- Embedding层:一个7x5的矩阵,其中每行是一个单词的向量,即词向量,词向量的维度为5
- Convolution层:这里是一维卷积,卷积核宽度固定:即为词向量维度,卷积核的高度即一个窗口中包含的单词的个数,这里的kernel_size=(2,3,4)即为一个窗口中分别可以包含2,3,4个单词。然后每个kernel_size输出2个通道,实际上是每类(包含单词个数)卷积核的个数为2而已,再将卷积输出的结果经过激活函数输出
- MaxPooling层:每类卷积核输出两个通道,然后再取各个通道结果的最大值(MaxPooling),于是就得到了6个值
- FullConnection层:将MaxPooling层的输出结果进行拼接构成一个全连接层的输入,然后再根据分类类别数接上一个softmax层就可以得到分类结果了。
当然原文还使用了dropout,dropout的作用也可想而知,这里就不做介绍了。
补充:
通道(Channels):图像中可以利用 (R, G, B) 作为不同channel;文本的输入的channel通常是不同方式的embedding方式(比如 word2vec或Glove),实践中也有利用静态词向量和fine-tunning词向量作为不同channel的做法。
一维卷积(conv-1d):图像是二维数据;文本是一维数据,因此在TextCNN卷积用的是一维卷积(在word-level上是一维卷积;虽然文本经过词向量表达后是二维数据,但是在embedding-level上的二维卷积没有意义)。一维卷积带来的问题是需要通过设计不同 kernel_size 的 filter 获取不同宽度的视野,也可以理解为n-gram。
2 再看textcnn网络结构
如果上面的图你不懂,可再看看这个计算过程吧,再不懂的话,我也没法了。
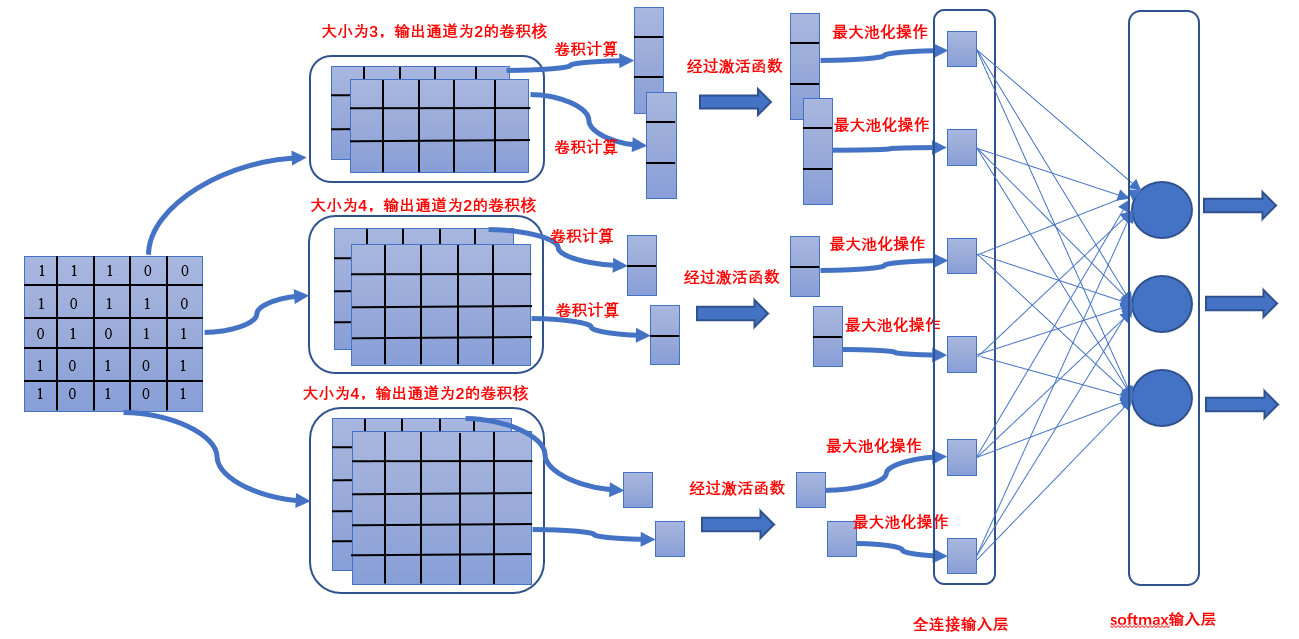
其中模型还对比了输入的词向量的embedding层,
CNN-rand:作为一个基础模型,Embedding layer所有words被随机初始化,然后模型整体进行训练。
CNN-static:模型使用预训练的word2vec初始化Embedding layer,对于那些在预训练的word2vec没有的单词,随机初始化。然后固定Embedding layer,fine-tune整个网络。
CNN-non-static:同(2),只是训练的时候,Embedding layer跟随整个网络一起训练。
CNN-multichannel: Embedding layer有两个channel,一个channel为static,一个为non-static。然后整个网络fine-tune时只有一个channel更新参数。两个channel都是使用预训练的word2vec初始化的。
其实模型的主要内容到这里就完了,下面就是需要动手去实现他了,至于论文给出的实验结果,可以了解一下。
3 总结
总得来说TextCNN模型是比较简单的,原论文用6也就介绍完了。接下来我找一些开源语料使用Pytorch来实现该模型了,敬请关注。欢迎关注个人订阅号“AIAS编程有道”在第一时间里查看最新个人原创文章。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)