【LLM论文日更】 | 你的专家组合LLM是秘密的免费嵌入模型
具体来说,RW和HS嵌入的聚类结果显示出中等的重叠(AMI和NMI在0.29左右),但它们的Jaccard相似度和精确匹配率较低(分别为0.06和45.54%)。通过分析发现,MoE的路由权重(RW)补充了广泛使用的隐藏状态(HS)嵌入,提供了对输入语义的更深入理解。最近的研究表明,LLMs可以生成高质量的句子嵌入,但这些方法通常依赖于复杂的预训练和大规模的对比目标。总体而言,PromptEOL的
- 论文:https://arxiv.org/pdf/2410.10814
- 代码:GitHub - tianyi-lab/MoE-Embedding: Code for "Your Mixture-of-Experts LLM Is Secretly an Embedding Model For Free"
- 机构 :马里兰大学
- 领域:嵌入模型
- 发表:arxiv

研究背景
-
研究问题:这篇文章探讨了大型语言模型(LLMs)在作为嵌入模型时的潜力,特别是混合专家(MoE)LLMs。尽管LLMs在生成任务上表现出色,但其解码器架构限制了其在没有进一步表示微调的情况下作为嵌入模型的潜力。
-
研究难点:LLMs的最终或中间隐藏状态(HS)可能无法捕捉输入令牌的关键特征和所有信息,尤其是当涉及到细微语义差异时。此外,现有的嵌入方法通常依赖于静态架构,可能忽略了输入的可变性。
-
相关工作:早期的句子嵌入方法如SkipThought利用分布假设,而最近的方法则转向对比学习。最近的研究表明,LLMs可以生成高质量的句子嵌入,但这些方法通常依赖于复杂的预训练和大规模的对比目标。
研究方法
这篇论文提出了MoE嵌入(MOEE),用于解决LLMs作为嵌入模型的问题。具体来说,研究方法包括以下几个步骤:
-
MoE路由权重(RW)作为嵌入:MoE模型通过动态路由机制将输入分配给不同的专家。每个专家专注于输入的特定特征,路由权重(RW)表示每个专家对最终输出的贡献。通过连接所有层的路由权重,形成基于路由的嵌入eRW:
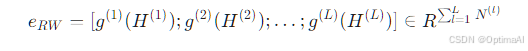
![]()
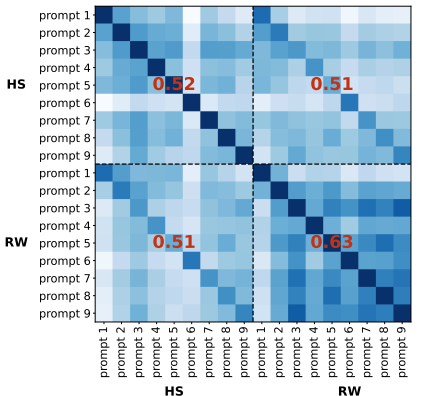
路由权重和隐藏状态的互补性分析:通过聚类分析和相关性分析,研究了RW和HS嵌入的不同之处。发现RW和HS嵌入在聚类行为和主题上有所不同,且它们之间的相关性较低,表明它们具有互补性。
-
提出的MOEE方法:基于RW和HS嵌入的互补性,提出了两种结合方法:
- 串联组合:将HS和RW嵌入直接串联起来,形成最终的嵌入
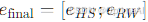
- 加权求和集成:分别计算HS和RW嵌入的相似度得分,然后进行加权求和,公式如下:
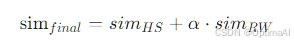
- 串联组合:将HS和RW嵌入直接串联起来,形成最终的嵌入
其中,α是超参数,用于控制RW的贡献 。
实验设计
实验在MTEB(Massive Text Embedding Benchmark)上进行,涵盖了一系列自然语言处理任务,包括分类、聚类、成对分类、重排序、检索、语义文本相似度和摘要。实验使用了三种MoE模型:DeepSeekMoE-16B、Qwen1.5-MoE-A2.7B和OLMoE-1B-7B。所有模型都使用逐令牌路由,但MOEE使用最后一个令牌的路由权重。
结果与分析
-
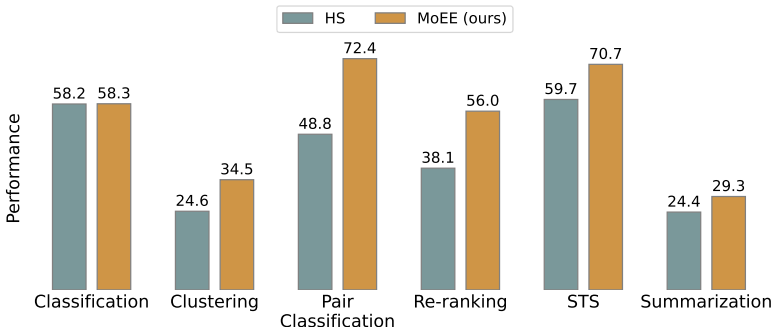
无提示情况下的性能:在不使用提示的情况下,MOEE(sum)在所有模型和任务上均表现出显著的性能提升,特别是在分类、重排序和语义文本相似度任务上。例如,DeepSeekMoE的分类准确率从35.36提高到43.30,提升了22.45%。
-
使用PromptEOL的情况:引入PromptEOL后,MOEE的性能进一步提升。例如,DeepSeekMoE的分类准确率从58.24提高到67.39,提升了9.15%。
-
消融研究:通过消融研究,验证了不同提取RW和HS的方法对嵌入质量的影响。结果表明,仅使用最后一个令牌的HS或RW效果最佳,而使用所有令牌的平均池化会引入噪声。
-
稳定性比较:在不同提示下的性能方差分析显示,HS对提示选择的敏感性较高,而RW则表现出更高的稳定性。
总体结论
这篇论文展示了MoE作为有效嵌入生成器的潜力,无需额外训练。通过分析发现,MoE的路由权重(RW)补充了广泛使用的隐藏状态(HS)嵌入,提供了对输入语义的更深入理解。提出的MOEE方法结合了RW和HS,显著提高了MTEB基准中各种任务的嵌入性能。未来工作将进一步探索如何自适应地利用MOEE以适应特定任务场景。
论文评价
优点与创新
- 发现MoE LLMs的专家路由器可以作为现成的嵌入模型:研究表明,MoE LLMs中的专家路由器可以在不需要额外微调的情况下,在多种嵌入任务上表现出色。
- 路由权重(RW)与隐藏状态(HS)的互补性:分析表明,RW与HS相比,对提示的选择更为鲁棒,并且专注于高层次语义。
- 提出MOEE方法:通过结合RW和HS,提出了MOEE方法,该方法在不进一步微调的情况下,显著提高了基于LLM的嵌入性能。
- 多种组合策略的探索:实验中探索了多种组合策略,发现RW和HS相似度的加权和优于它们的简单拼接。
- 广泛的实验验证:在MTEB基准上的6个嵌入任务和20个数据集上进行了实验,证明了MOEE在不同任务上的显著改进。
不足与反思
- 未来工作方向:论文提到未来的研究方向包括如何自适应地利用MOEE来适应特定任务场景。
关键问题及回答
问题1:MoE模型中的路由权重(RW)嵌入和隐藏状态(HS)嵌入在聚类行为和主题上有何不同?
根据论文的分析,路由权重(RW)嵌入和隐藏状态(HS)嵌入在聚类行为和主题上存在显著差异。具体来说,RW和HS嵌入的聚类结果显示出中等的重叠(AMI和NMI在0.29左右),但它们的Jaccard相似度和精确匹配率较低(分别为0.06和45.54%)。这表明RW和HS嵌入在结构化和主题上捕获了不同的信息。进一步的分析显示,RW嵌入强调输入的不同主题,而HS嵌入则更好地捕捉到句子的整体结构和意义。
问题2:MOEE方法中提出的两种组合方法——串联组合和加权求和集成——各自的优缺点是什么?
- 串联组合:
- 优点:简单直观,保留了HS和RW嵌入的独立信息,允许下游任务灵活地利用这两种表示。
- 缺点:可能会引入冗余信息,因为两种嵌入的类型和结构不同,简单的串联可能导致某些信息的重复或抵消。
- 加权求和集成:
- 优点:通过加权求和可以平衡RW和HS嵌入的贡献,避免直接融合带来的复杂性。这种方法允许根据不同任务的需求调整RW和HS的权重,优化性能。
- 缺点:需要设置超参数α来控制RW的贡献,这可能需要额外的实验和调整。此外,加权求和可能会掩盖某些嵌入的特定优势。
问题3:MOEE方法在不同提示策略下的表现如何?特别是与不使用提示的情况相比,使用PromptEOL后有哪些改进?
- 无提示情况:
- MOEE(sum)在大多数任务中显著优于单独的RW和HS嵌入。例如,在DeepSeekMoE模型的分类任务中,性能从35.36提高到43.30,提高了22.45%。
- 使用PromptEOL后:
- MOEE的性能进一步提升。例如,在DeepSeekMoE模型的分类任务中,性能从58.24提高到59.34,提高了1.10%。这表明PromptEOL能够有效地提升MOEE方法的嵌入质量,使其在更多任务中超越自监督和监督方法。
总体而言,PromptEOL的使用显著增强了MOEE方法的稳定性和性能,使其在不确定性较高的提示条件下也能保持较高的嵌入质量。
模型输出获取:
outputs, sent_emb = self.model(**prompts, output_hidden_states=True, return_dict=True)
- 这里,
self.model是一个预训练的MoE模型。prompts是输入到模型的提示信息。output_hidden_states=True表示模型返回所有层的隐藏状态。return_dict=True表示模型输出以字典形式返回,方便后续处理。提取最后一层的最后一个token的隐藏状态:
lst_token_emb = outputs.hidden_states[-1][:, -1, :].cpu()
outputs.hidden_states[-1]获取最后一层的隐藏状态。[:, -1, :]选择每一序列的最后一个token的隐藏状态。.cpu()将张量移动到CPU上进行处理。提取路由权重:
lst_token_rw = sent_emb[:, :, -1, :]
sent_emb包含了所有层的隐藏状态。[:, :, -1, :]选择每一层最后一个token的隐藏状态。lst_token_rw = torch.cat([lst_token_rw[:, i, :] for i in range(lst_token_rw.shape[1])], dim=1)
[lst_token_rw[:, i, :] for i in range(lst_token_rw.shape[1])]对于每个专家(expert),提取其最后一层的隐藏状态。torch.cat(..., dim=1)沿着第二个维度(即专家的数量)将这些隐藏状态拼接起来,形成最终的路由权重。总结来说,MOE权重的提取过程包括以下步骤:
- 调用MoE模型并获取所有层的隐藏状态。
- 从这些隐藏状态中提取最后一层的最后一个token的隐藏状态。
- 提取每个专家在该token上的隐藏状态,并将这些状态拼接起来,形成最终的路由权重。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)