UCTransNet: Rethinking the Skip Connections in U-Net from a Channel-wisePerspective with Transforme
UCTransNet
对文章简单的理解,不对之处还请指正。
引言
本文主要对U-Net这一经典的网络进行研究改进,作者指出U-Net对全局上下文多尺度建模有待改进,是因为1:encoder和decoder一些不相容的特征图造成不是每一个跳连接都有效:2:原始的U-Net在一些数据集上表现不如不加跳连接的U-net。
因此作者提出了UCTransNet,模型包含多尺度通道交叉融合Transformer(CCT),和逐通道交叉注意力(CCA),来引导多尺度逐通道信息和decoder特征进行融合。
在医学领域,U-Net网络用的十分广泛,传统的U-Net通过encoder进行捕获低层和高层特征,跳连接将空间信息恢复到原来的分辨率,decoder结合语义信息进行最终结果的输出。
作者提出了两个问题:
哪一层的encoder和decoder进行连接?
如何有效的融合特征?
首先不同的通道关注于不同的语义模态,因此自适应的融合充足的逐通道特征对于复杂的分割有帮助。因此这里首先用CCT从逐通道视角融合多尺度特征,使用CCA融合融合了的多尺度特征和decoder特征。
相关工作:
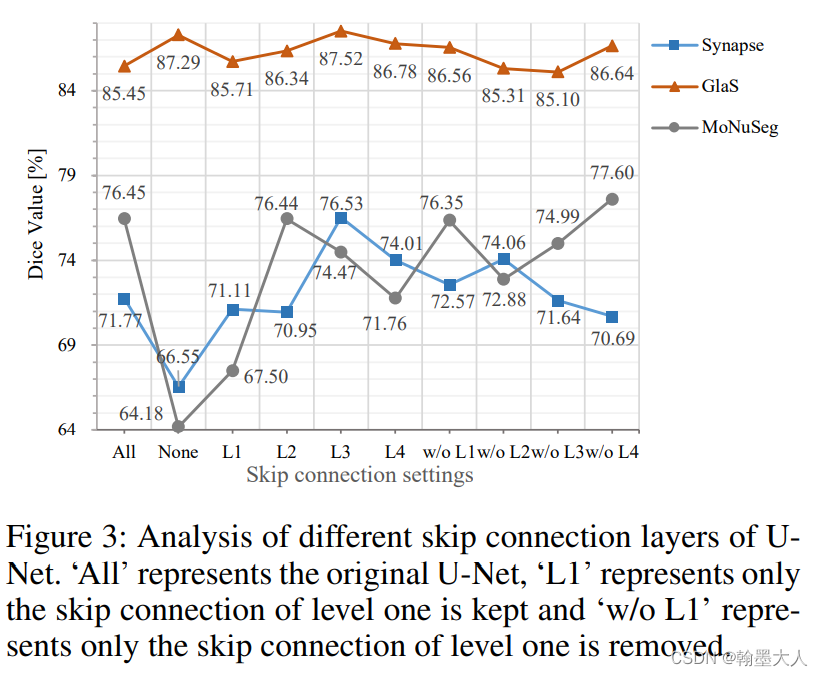
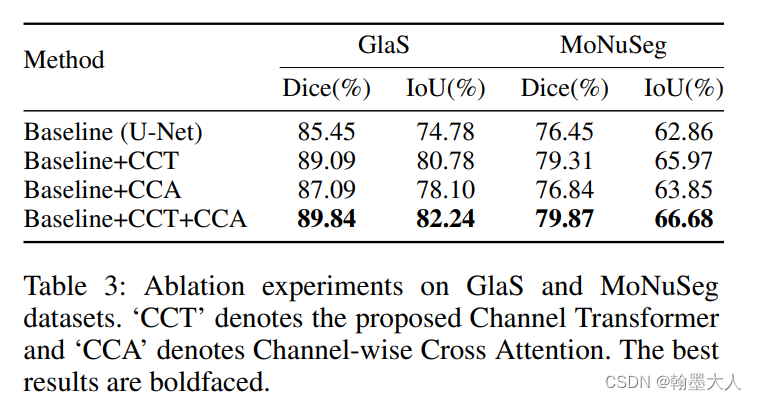
作者对U-Net的跳连接进行了大量的实验,发现每一个跳连接都有不同的贡献,比如在Glas数据集上,没有跳连接的U-Net比原始的效果更好,在其余两个数据集上,不同的跳连接数目,以及连接哪一层的跳连接都有不同的作用。
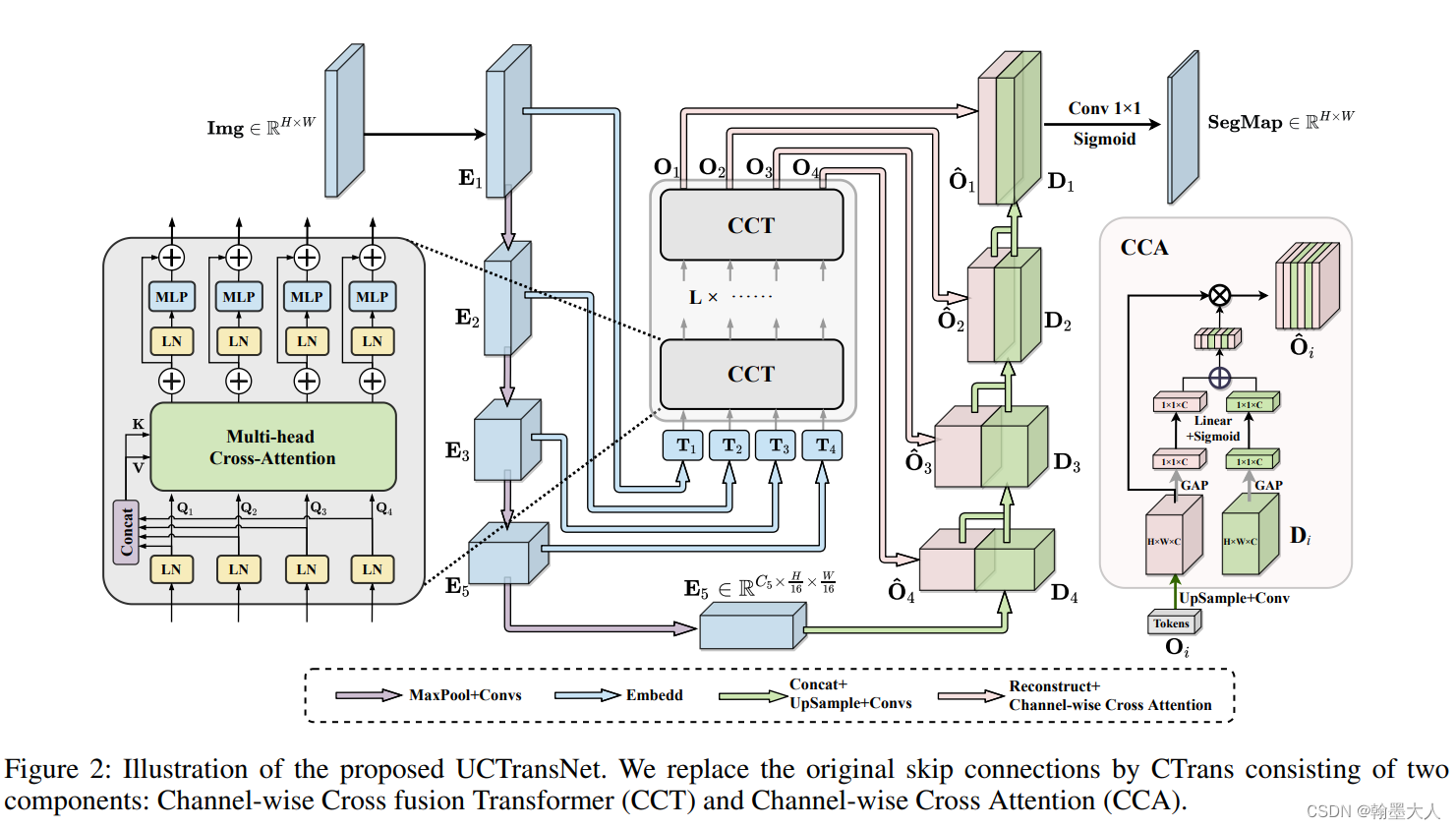
首先我们看一下整体的架构:
我们大致的看一下作者将跳连接替换成了L个CCT组合而成的Transformer,其中Transformer的输入是四个不同尺度的特征图,输出的特征图也是四个不同大小的特征图,最后与Decoder进行CCA运算,其中CCA运算也是注意力,生成的通道1x1特征与CCT输出特征图进行相乘。得到的结果进行1x1卷积,得到了最终的Segmap。
CCT: Channel-wise Cross Fusion Transformer for Encoder Feature Transformation:
首先将四个不同尺寸的特征图进行reshape,进行2D展平,patch大小为(P,P/2,P/4,P/8),
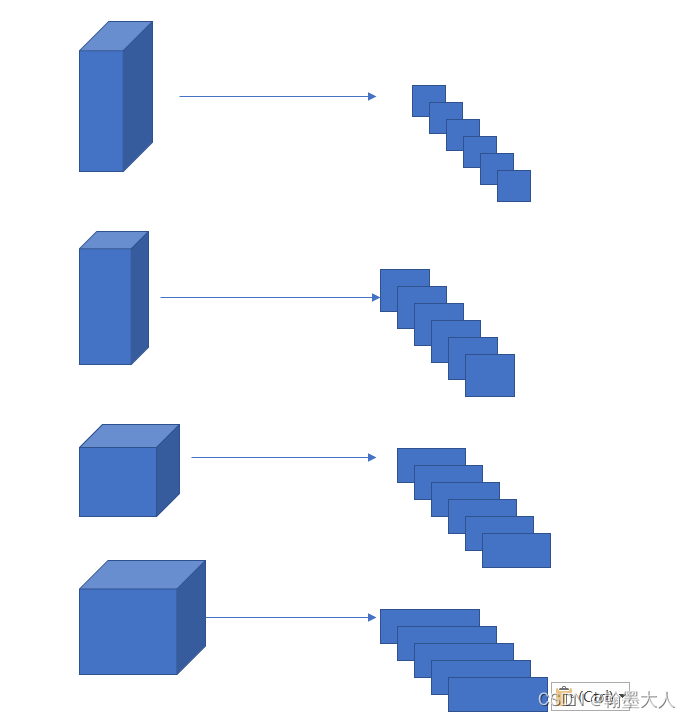
将tokens输入进多头通道交叉注意力模块,接着使用一个带有残差结构的MLP模块,CCT模块具有五个输入,四个tokenTi作为查询,连加T作为K和V。
然后计算相似度矩阵Mi,这里多加了一个instance normalization(IN和BN最大的区别是,IN作用于单张图片,BN作用于一个batch,IN对HW做归一化,同时保证了每个图像实例之间的独立。),是为了让梯度进行更好的传播。最后再与V相乘。 所以:逐通道交叉融合就体现在这里。每一个通道与其他所有的通道进行注意力,生成的结果也融合了其他的通道。

对于每一个q都会计算一个M,计算一个CA,则四个输入Q,就会产生四个CA。在N个多头注意力情况,输出可以这样计算:
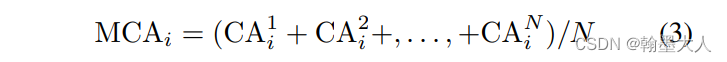
例如当i=1,则MAC1 等于第一个多头生成的第一个CA1,加上第二个多头生成的第一个CA2,有N个就加N次,最后除以N。
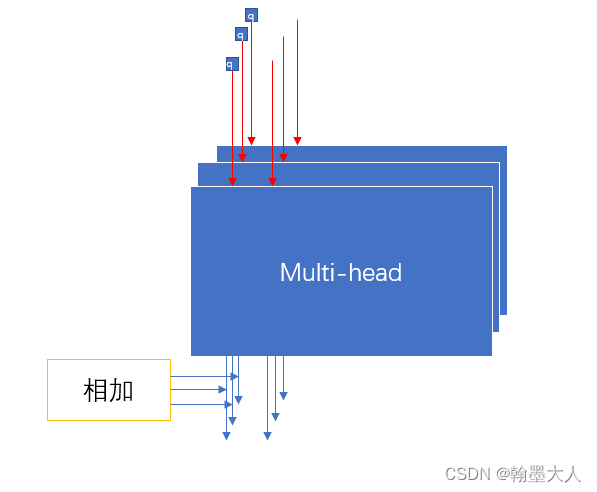
最后经过LN和MLP,在这里的公式和原图所画的可能对不上,因为这里是Q和MCA共同经过MLP,再加上MCA,而原图画的是(MCA+Q)+MLP(Q+MCA),到时候看代码再确认一下。
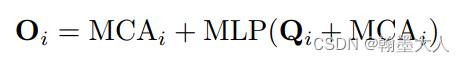
![]()
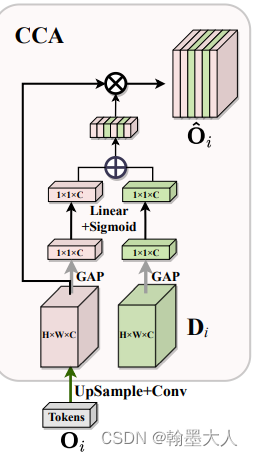
CCA: Channel-wise Cross Attention for Feature Fusion in Decoder
我们将得到的四个输出Oi中的每一个O与decoder特征图的每一个D作为CCA的输入,首先通过全局平均池化压缩空间,然后分别经过两个权重相乘,再相加,最后与Qi相乘,便生成了最后的分割图。
实验:

消融实验:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 1
1 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)