scikit-learn分类模型 KNN算法
算法原理
简介
KNN k(邻居个数) nearest neighbor K近邻算法 Classification分类
简单地说,K-近邻算法采用测量不同特征值之间的距离方法进行分类(k-Nearest Neighbor,KNN)物以类聚,人以群分
优点:精度高、对异常值不敏感、无数据输入假定。
缺点:时间复杂度高、空间复杂度高。
1、当样本不平衡时,比如一个类的样本容量很大,其他类的样本容量很小,输入一个样本的时候,K个临近值中大多数都是大样本容量的那个类,这时可能就会导致分类错误。改进方法是对K临近点进行加权,也就是距离近的点的权值大,距离远的点权值小。
2、计算量较大,每个待分类的样本都要计算它到全部点的距离,根据距离排序才能求得K个临近点,改进方法是:先对已知样本点进行剪辑,事先去除对分类作用不大的样本。
原理
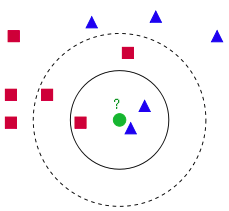
kNN近邻分类算法的原理
从上图中我们可以看到,图中的数据集都有了自己的标签,一类是蓝色的正方形,一类是红色的三角形,那个绿色的圆形是我们待分类的数据
如果K=3,那么离绿色点最近的有2个红色三角形和1个蓝色的正方形,这3个点投票,于是绿色的这个待分类点属于红色的三角形.
如果K=5,那么离绿色点最近的有2个红色三角形和3个蓝色的正方形,这5个点投票,于是绿色的这个待分类点属于蓝色的正方形
我们可以看到,KNN本质是基于一种数据统计的方法!其实很多机器学习算法也是基于数据统计的
KNN是一种基于记忆的学习(memory-based learning),也是基于实例的学习(instance-based learning),属于惰性学习(lazy learning)。即它没有明显的前期训练过程,而是程序开始运行时,把数据集加载到内存后,不需要进行训练,就可以开始分类了。
我们需要教会计算机根据’邻居’分类,邻居:距离比较近
距离公式:欧式距离
d=(x1−y1)2+(x2−y2)2+(x3−y3)2+......d=\sqrt{(x1-y1)^2+(x2-y2)^2+(x3-y3)^2+......}d=(x1−y1)2+(x2−y2)2+(x3−y3)2+......
距离d越小,越近,就是邻居,就是一类,小于d<10规定为邻居
计算机擅长计算—>通过给数学公式—>返回计算结果
通过计算距离获取邻居(最近的5个邻居)—>统计,类别(富有,贫穷)
4个富有 1个贫穷 4>1 计算机会返回概率结果80%
结论:判断处理:富有
入门案例
from sklearn.neighbors import KNeighborsClassifier
neigh = KNeighborsClassifier(n_neighbors=3)
#身高、体重、鞋的尺寸
X = np.array([[181,80,44],[177,70,43],[160,60,38],[154,54,37],
[166,65,40],[190,90,47],[175,64,39],[177,70,40],
[159,55,37],[171,75,42],[181,85,43]])
display(X)
y = ['male','male','female','female','male','male','female','female','female','male','male']
### 第1步:训练数据
neigh.fit(X,y)
### 第2步:预测数据
Z = neigh.predict(np.array([[190,70,43],[168,55,37]]))
display(Z)``
入门使用
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
import pandas as pd
# 分类,电影类别
# 动作 武打镜头:碟中谍6、杀死bill、谍影重重
# 爱情 接吻镜头:泰坦尼克号
# 属性:武打镜头、接吻镜头
# 量化,数量化、数字化
# 金融量化
movie = pd.read_excel('./movies.xlsx',sheet_name=1) #加载第二个sheet的
movie
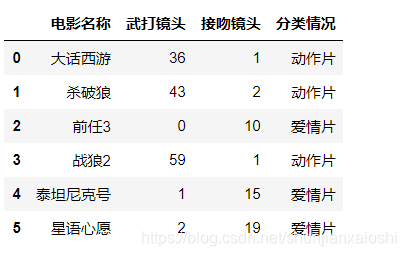
data = movie.iloc[:,1:3] #数据
target = movie['分类情况'] #目标
display(data,target)
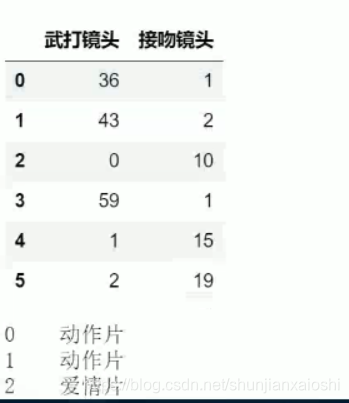
type(data)
#pandas.core.frame.DataFrame
# 算法,训练
knn = KNeighborsClassifier(n_neighbors=5)
# 训练,学习,算法,知道,数据和目标值target什么样关系
knn.fit(data,target)
#KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',metric_params=None, n_jobs=None, n_neighbors=5, p=2,weights='uniform')
# 预测,使用,应用,高考
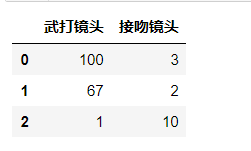
# 碟中谍6:100,3
# 谍影重重5:67,2
# 前任2 1,10
X_test = pd.DataFrame({'武打镜头':[100,67,1],'接吻镜头':[3,2,10]})
X_test
# 计算机,根据规则,返回的结果
# 算法‘意见’:结果
knn.predict(X_test)
#array(['动作片', '动作片', '爱情片'], dtype=object)
分类案例 鸢尾花案例
#导包
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
from sklearn import datasets #datasets自带很多数据
# 鸢尾花,因为自然环境不同,所以类别可以细分
iris = datasets.load_iris()
X = iris['data']
y = iris['target']
# 150代表着150个样本,4代表着4个属性:花萼长、宽;花瓣长、宽
##机器学习是二维的 第一维:样本数量 第二维:特征
X.shape
#(150,4)
# 将数据划分,一分为二:一部分用于训练,另一部分用测试
# 将顺序打乱
index = np.arange(150)
index
#array([0,1,2,3,4,5,....146,147,148,149])
np.random.shuffle(index) #打乱数据
index
#array([3,109,118,65,46,...120,53,79,21])
# 150个数据将打乱顺序100个取出来,算法学习,留下50个使用算法预测(验证算法是否可靠)
# 应用到实际中,要获取现实中的数据,算法对数据进行分类-------->上线:实时进行分类
X_train,X_test = X[index[:100]],X[index[100:]]
y_train,y_test = y[index[:100]],y[index[-50:]]
# 数据简单,只有4个属性
# p = 1 距离度量采用的是:曼哈顿距离
# p = 2 距离度量采用的是:欧氏距离
# 100**0.5 = 10
knn = KNeighborsClassifier(n_neighbors= 5,weights='distance',p = 1,n_jobs = 4)
#邻居数量可以调整 p=1 距离度量 采用的是:曼哈顿距离 闵可夫斯基提出的 默认2是欧式距离
#5个邻居都说是这种类型,那他就是那种 weights权重:uniform统一,一人一票 distance 离得近权重大 n_jobs=-1满进程执行 4 4个进程
#邻居数量最好不要超过样本数量的开方
knn.fit(X_train,y_train)
y_ = knn.predict(X_test)
knn.score(X_test,y_test)
#0.96
# 对比,看算法,预测的和真实的结果,是否对应
# 对应,大部分正确:算法没问题
# 不然,说明算法效果不好
print(y_)
print('--------------')
print(y_test)
# 算法返回的结果,使用 bianliang_接收:约定俗成变量命名规则
proba_ = knn.predict_proba(X_test)
proba_

proba_.argmax(axis=1)
#array([0, 0, 0, 2, 2, 1, 0, 0, 1, 2,......1, 2, 2, 1, 1, 0])
# 准确率
(y_ == y_test).sum()/50
#0.96
KNN算法可以接受numpy和DataFrame
KNN手写数字识别
import numpy as np
import cv2 #加载图片比matplotlib快一些
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.neighbors import KNeighborsClassifier
# bitmap 位图
digit = cv2.imread('./data/0/0_101.bmp')
# 将彩色(三维的)图片转化成黑白的(图片灰度化处理):大大降低数据量
digit = cv2.cvtColor(digit,code = cv2.COLOR_BGR2GRAY)
# (28,28,3) ----------> (28,28)
# 数据量大大减少了2/3,只有原来的1/3
digit.shape
#(28, 28)
加载数据,处理(灰度化)
X = []
for i in range(10):
for j in range(1,501):
digit = cv2.imread('./data/%d/%d_%d.bmp'%(i,i,j))
X.append(digit[:,:,0]) ##彩色图片 三条通道值相同 即为灰度图片
# 数据X和目标值y是一一对应
X = np.asarray(X) # numpy对象 X.shape(5000,28,28)
y = np.array([i for i in range(10)]*500)
y.sort()
# digit二维的,高度,宽度,像素(只有一个值)--------用什么颜色表示呢?
# 选择黑白,图片show就是黑白,rainbow显示出来,彩虹效果
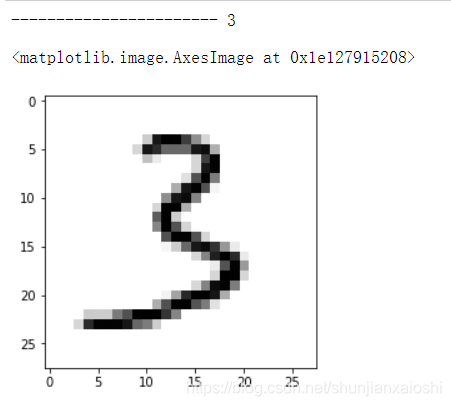
index = np.random.randint(0,5000,size = 1)[0]
digit = X[index]
print('-----------------------',y[index])
plt.imshow(digit,cmap = plt.cm.gray) #颜色可以变rainbow彩虹色 还有其他
X,y划分成训练和验证数据
# 模型选择,可以打乱顺序,按照比例进行划分
from sklearn.model_selection import train_test_split
# test_size = 0.2,train_size = 0.8
# 训练:测试= 4:1
# 一一对应的
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.2,random_state = 100) #默认0.25 random_state是随机的状态 固定 利于之后的比较
#4000 1000 4000 1000
算法训练和预测(验证)
4000**0.5
#63.245553203367585 邻居数量
# 数据不合要求,reshape形状改变
# 数据不变
# 三维的数据--------->变成2维
X_train = X_train.reshape(4000,-1)
X_train.shape
#(4000, 784)
%%time
knn = KNeighborsClassifier(n_neighbors= 63)
knn.fit(X_train,y_train)
# 使用算法进行预测
# 保留了1000个数据,算法‘没见过‘这1000个数据
X_test = X_test.reshape(1000,784)
y_ = knn.predict(X_test)
# 准确率
# (y_ == y_test).sum()/1000
print((y_ == y_test).mean())
#0.881
#Wall time: 8.6 s
调整参数,比较预测的时间
#调整邻居数量为5个 比较两者的时间
%%time
# 参数n_neighbors = 5告诉计算机找到最近的5个邻居
# 计算所有,找到最小的5个距离,最近的5个邻居
knn = KNeighborsClassifier(n_neighbors= 5)
knn.fit(X_train,y_train)
# 使用算法进行预测
# 保留了1000个数据,算法‘没见过‘这1000个数据
X_test = X_test.reshape(1000,784)
# 取出一个,找这一个5个邻居(4000个数据中)-----> 遍历------->d[:5]
# 取出一个,找这一个63个邻居(4000个数据中)-----> 遍历------>d[:63]
y_ = knn.predict(X_test)
# 准确率
# (y_ == y_test).sum()/1000
print((y_ == y_test).mean())
#0.929
#Wall time: 8.47 s
#KNN时间复杂度 空间复杂度比较长
得出结论:准确率有提升,时间没什么变化。KNN时间复杂度,空间复杂度比较高
原因上面代码中有解释
学习训练数据 预测还预测训练数据,是否是100%准确
%%time
# 参数n_neighbors = 5告诉计算机找到最近的5个邻居
# 计算所有,找到最小的5个距离,最近的5个邻居
knn = KNeighborsClassifier(n_neighbors= 5)
knn.fit(X_train,y_train) #算法训练(学习)4000个数据
# 使用算法进行预测
# 保留了1000个数据,算法‘没见过‘这1000个数据
X_test = X_test.reshape(1000,784)
# 取出一个,找这一个5个邻居(4000个数据中)-----> 遍历------->d[:5]
# 取出一个,找这一个63个邻居(4000个数据中)-----> 遍历------>d[:63]
y_ = knn.predict(X_train) #算法预测4000个数据
# 准确率是否可以100% ???
# (y_ == y_test).sum()/1000
print((y_ == y_train).mean())
#0.95425
#Wall time: 32.3 s
将上一段代码knn = KNeighborsClassifier(n_neighbors= 5)加上n_jobs=-1,通过多线程提高运行速度
运行结果 :0.95425 运行时间Wall time: 6.97 s
算法是‘学习‘,不是死记硬背,存到数据库一样,进行一一对比 即使学训练数据,预测训练数据也达不到100%
多次预测取平均值
%%time
accuracy = 0
for i in range(30):
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.2)
# 参数n_neighbors = 5告诉计算机找到最近的5个邻居
# 计算所有,找到最小的5个距离,最近的5个邻居
knn = KNeighborsClassifier(n_neighbors= 5,n_jobs=-1)
# 算法是‘学习‘,不是死记硬背,存到数据库一样,进行一一对比
knn.fit(X_train.reshape(4000,-1),y_train) #算法训练(学习)4000个数据
# 使用算法进行预测
# 保留了1000个数据,算法‘没见过‘这1000个数据
X_test = X_test.reshape(1000,784)
# 取出一个,找这一个5个邻居(4000个数据中)-----> 遍历------->d[:5]
# 取出一个,找这一个63个邻居(4000个数据中)-----> 遍历------>d[:63]
y_ = knn.predict(X_test.reshape(1000,-1)) #算法预测4000个数据
# 准确率是否可以100% ???
# (y_ == y_test).sum()/1000
accuracy += (y_ == y_test).mean()/30
print('-----------------数据没有进行二值化处理多次划分训练预测的平均准确率:%0.3f'%(accuracy))
#-----------------数据没有进行二值化处理多次划分训练预测的平均准确率:0.931
#Wall time: 1min 1s
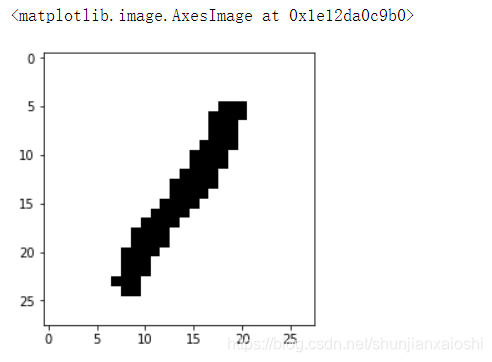
二值化图片,看是否对准确率的提升有帮助
# 二值化操作 将图片全都转为黑白二值图片 可能提升识别率
for i in range(5000):
for y in range(28):
for x in range(28):
if X[i][y,x] < 200:
X[i][y,x] = 0
else:
X[i][y,x] = 255
index = np.random.randint(0,5000,size = 1)[0]
plt.imshow(X[index],cmap = 'gray')
5000 张图片----->4000,1000 可以有很多分发
C50001000C^{1000}_{5000}C50001000
#重新创建一下y y被上面的二值化图片的y替换掉了
y = np.array([i for i in range(10)]*500)
y.sort()
y
%%time
accuracy = 0
for i in range(30):
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.2)
# 参数n_neighbors = 5告诉计算机找到最近的5个邻居
# 计算所有,找到最小的5个距离,最近的5个邻居
knn = KNeighborsClassifier(n_neighbors= 5,n_jobs=-1)
# 算法是‘学习‘,不是死记硬背,存到数据库一样,进行一一对比
knn.fit(X_train.reshape(4000,-1),y_train) #算法训练(学习)4000个数据
# 使用算法进行预测
# 保留了1000个数据,算法‘没见过‘这1000个数据
X_test = X_test.reshape(1000,784)
# 取出一个,找这一个5个邻居(4000个数据中)-----> 遍历------->d[:5]
# 取出一个,找这一个63个邻居(4000个数据中)-----> 遍历------>d[:63]
y_ = knn.predict(X_test.reshape(1000,-1)) #算法预测4000个数据
# 准确率是否可以100% ???
# (y_ == y_test).sum()/1000
accuracy += (y_ == y_test).mean()/30
print('-----------------多次划分训练预测的平均准确率:%0.3f'%(accuracy))
#-----------------多次划分训练预测的平均准确率:0.930
#Wall time: 1min 3s
得出结论,手写数字识别二值化处理对提高准确率意义不大

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)