超越 DeepSeek-R1!Seed-Thinking-v1.5:字节跳动开源MoE架构推理模型,200B总参数仅激活20B,推理效率提升5倍
该模型基于混合专家(MoE)架构构建,总参数量达到200B级别但每次推理仅激活20B参数。通过动态路由机制,系统能根据任务类型自动选择最合适的专家模块组合,在保持计算效率的同时实现复杂推理能力。其训练框架集成了强化学习算法与数据增强策略,采用超过百万条经人工验证的数学题、编程问题和科学问答作为训练基底。特别设计的流式生成系统(SRS)通过异步处理机制,将长文本生成效率提升300%。
·
Seed-Thinking-v1.5 是什么
该模型基于混合专家(MoE)架构构建,总参数量达到200B级别但每次推理仅激活20B参数。通过动态路由机制,系统能根据任务类型自动选择最合适的专家模块组合,在保持计算效率的同时实现复杂推理能力。
其训练框架集成了强化学习算法与数据增强策略,采用超过百万条经人工验证的数学题、编程问题和科学问答作为训练基底。特别设计的流式生成系统(SRS)通过异步处理机制,将长文本生成效率提升300%。
主要功能
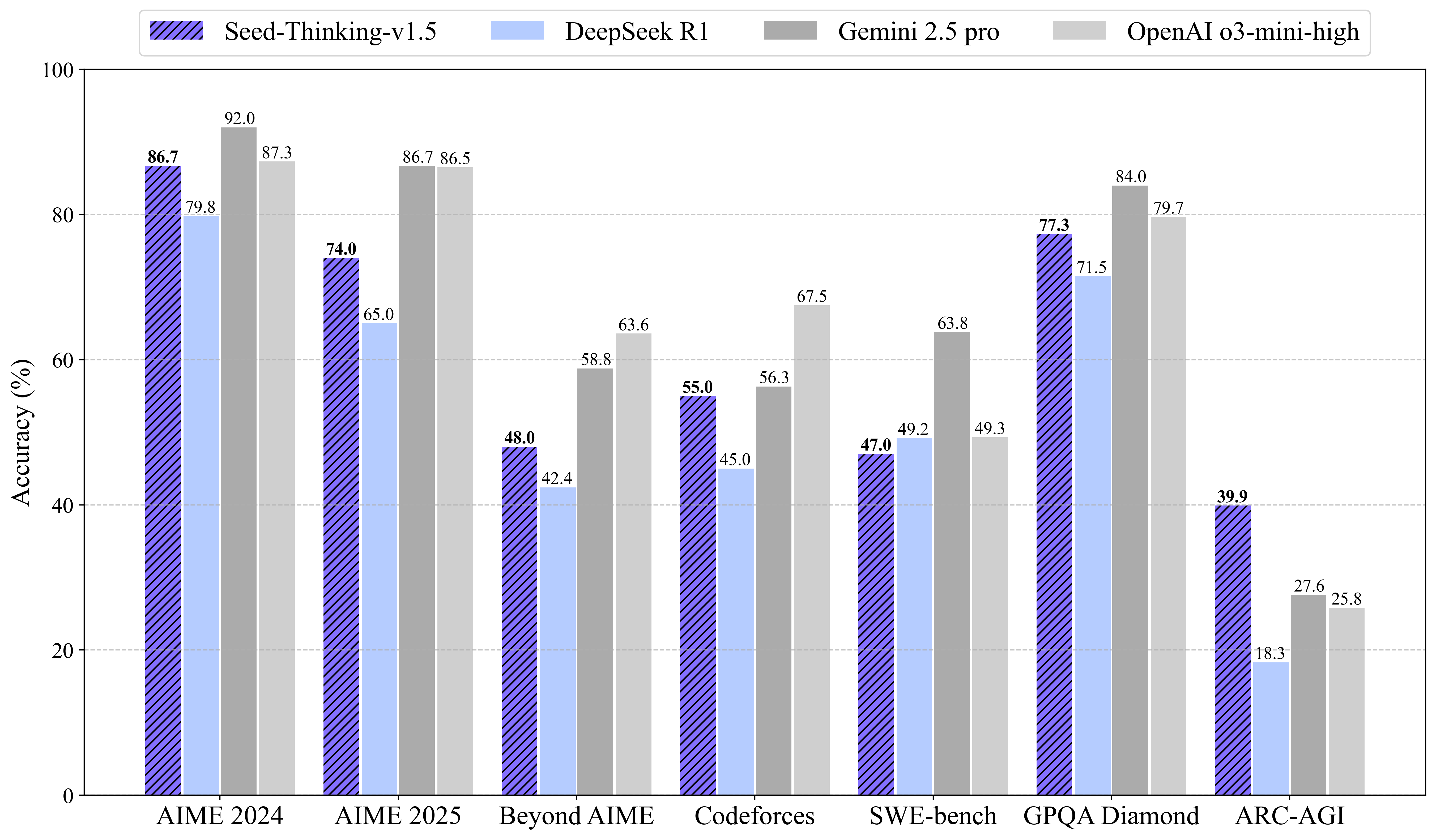
- 多领域推理:在AIME数学竞赛题、Codeforces编程题等7类测试中平均准确率超75%
- 动态参数激活:根据任务复杂度自动调节激活参数量,平衡精度与速度
- 流式推理优化:采用三级并行架构实现每秒处理3000token的吞吐量
技术原理
- 混合专家架构:包含128个专家模块,通过门控网络实现动态路由
- VAPO强化框架:结合价值函数与策略梯度,训练稳定性提升40%
- 数据增强引擎:运用对抗生成技术自动扩充训练样本多样性
- HybridFlow系统:支持张量/专家/序列三级并行,训练效率提升2.8倍
资源

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)