RNN、LSTM、GRU汇总
RNN、LSTM、GRU汇总
RNN、LSTM、GRU汇总
- 0、论文汇总
- 1、发展史
- 2、配置和架构
- 3、基本结构
- 4、参数说明
-
- 1、Lstm参数
- 2、RNN参数
0、论文汇总
1.RNN论文
传统RNN经典结构:Elman Network、Jordan Network、Bidirectional RNN
Jordan RNN于1986年提出:《SERIAL ORDER: A PARALLEL DISTRmUTED PROCESSING APPROACH》
Elman RNN于1990年提出:《Finding Structure in Time》
《LSTM原始论文:Long Short-Term Memory》
2、LSTM论文
论文原文
地址01:https://arxiv.org/pdf/1506.04214.pdf
地址02:https://www.bioinf.jku.at/publications/older/2604.pdf
《旧:Convolutional LSTM Network: A Machine Learning
Approach for Precipitation Nowcasting》
《LSTM原始论文:Long Short-Term Memory》
3、GRU
《GRU原始论文:Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation》
门控循环单元 (Gate Recurrent Unit, GRU) 于 2014 年提出,原论文为《Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling》。
4、其他汇总
维基百科RNN总结(发展史):https://en.wikipedia.org/wiki/Recurrent_neural_network
传统RNN经典结构:Elman Network、Jordan Network、Bidirectional RNN
Jordan RNN于1986年提出:《SERIAL ORDER: A PARALLEL DISTRmUTED PROCESSING APPROACH》
Elman RNN于1990年提出:《Finding Structure in Time》
《LSTM原始论文:Long Short-Term Memory》
《GRU原始论文:Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation》
门控循环单元 (Gate Recurrent Unit, GRU) 于 2014 年提出,原论文为《Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling》。
博客链接:https://blog.csdn.net/u013250861/article/details/125922368
时间系列相关:https://zhuanlan.zhihu.com/p/637171880
论文名:Recurrent Neural Network Regularization(正则化)
论文地址:https://arxiv.org/abs/1409.2329v5
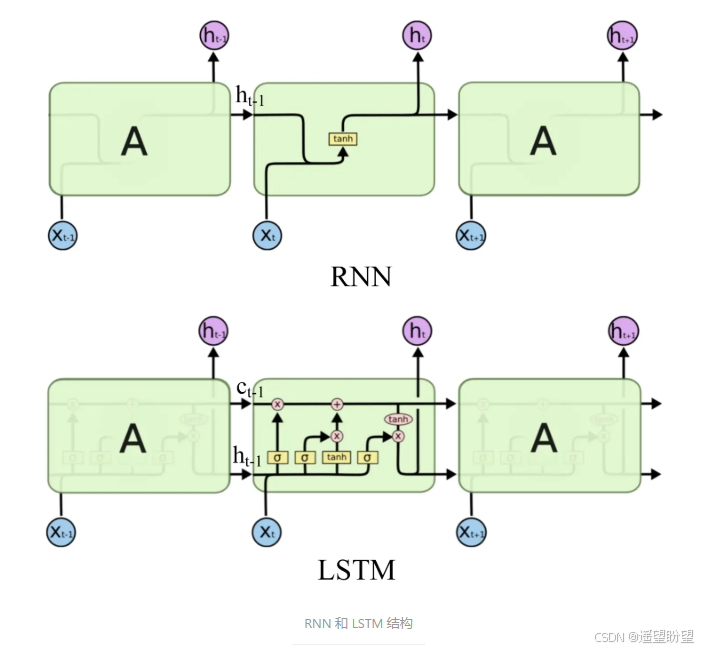
循环神经网络(Recurrent Neural Network,RNN)
适用于处理序列数据,如文本、语音等。它在隐藏层中引入了循环连接,使得神经元能够记住过去的信息。其中,长短期记忆网络(Long Short-Term Memory,LSTM)和门控循环单元(Gate Recurrent Unit,GRU)是 RNN 的改进版本,能够更好地处理长序列中的长期依赖关系。
公式:https://zhuanlan.zhihu.com/p/149869659
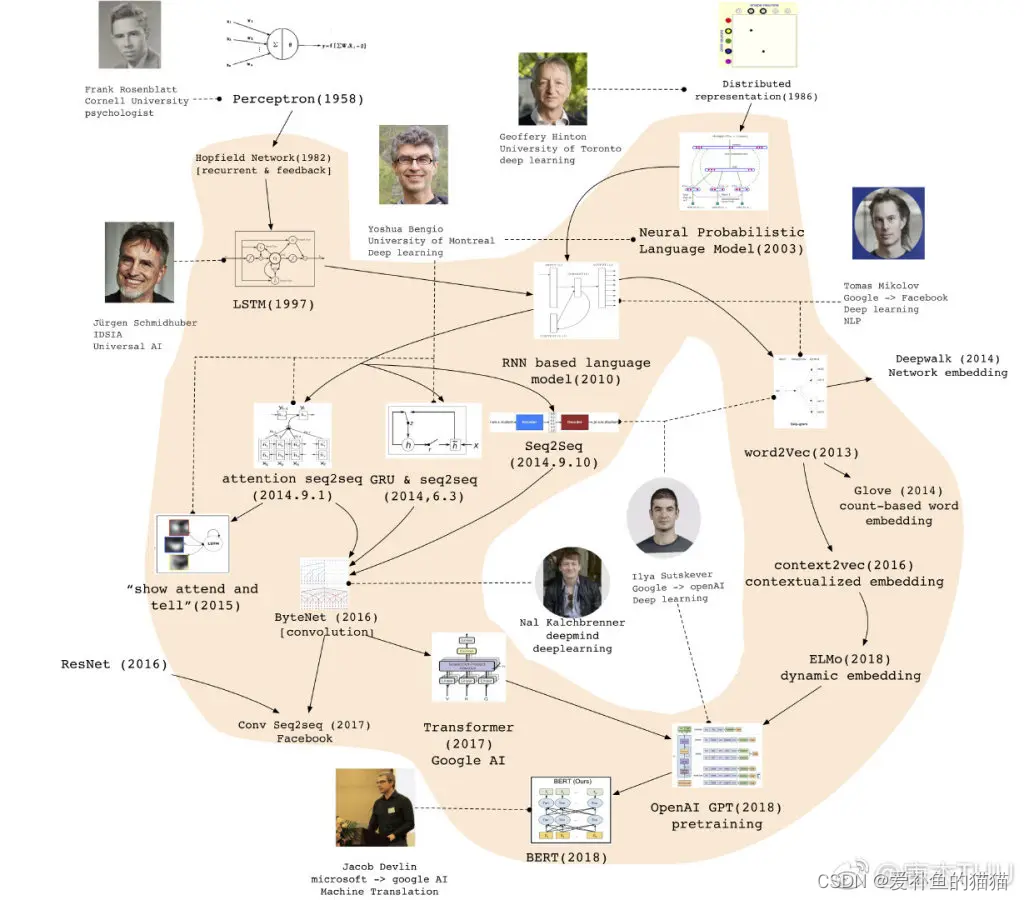
1、发展史
https://en.wikipedia.org/wiki/Recurrent_neural_network
现代 RNN 网络主要基于两种架构:LSTM 和 BRNN。[ 32 ]
在 20 世纪 80 年代神经网络复兴之际,循环网络再次受到研究。它们有时被称为“迭代网络”。[ 33 ]两个早期有影响力的作品是Jordan 网络(1986 年)和Elman 网络(1990 年),它们将 RNN 应用于认知心理学研究。1993 年,一个神经历史压缩系统解决了一项“非常深度学习”任务,该任务需要RNN 中随时间展开的1000 多个后续层。 [ 34 ]
长短期记忆(LSTM) 网络由Hochreiter和Schmidhuber于 1995 年发明,并在多个应用领域创下了准确率记录。[ 35 ] [ 36 ]它成为 RNN 架构的默认选择。
双向循环神经网络(BRNN) 使用两个以相反方向处理相同输入的 RNN。[ 37 ]这两者通常结合在一起,形成双向 LSTM 架构。
2006 年左右,双向 LSTM 开始彻底改变语音识别,在某些语音应用方面表现优于传统模型。[ 38 ] [ 39 ]它们还改进了大词汇量语音识别[ 3 ] [ 4 ]和文本到语音合成[ 40 ],并用于Google 语音搜索和Android 设备上的听写。[ 41 ]它们打破了机器翻译[ 42 ] 、语言建模[ 43 ]和多语言处理方面的记录。 [ 44 ]此外,LSTM 与卷积神经网络(CNN)相结合,改进了自动图像字幕制作。[ 45 ]
编码器-解码器序列传导的概念是在 2010 年代初发展起来的。最常被引用为 seq2seq 的创始人的论文是 2014 年的两篇论文。[ 46 ] [ 47 ] seq2seq架构采用两个 RNN(通常是 LSTM),一个“编码器”和一个“解码器”,用于序列传导,例如机器翻译。它们成为机器翻译领域的最先进技术,并在注意力机制和Transformers的发展中发挥了重要作用。
RNN类型**:
RNN–>LATM—>BPTT—>GUR–>RNN LM—>word2vec–>seq2seq–>BERT–>transformer–>GPT
反向传播(BP)和基于时间的反向传播算法BPTT
BPTT(back-propagation through time)算法是常用的训练RNN的方法,其实本质还是BP算法,只不过RNN处理时间序列数据,所以要基于时间反向传播,故叫随时间反向传播。BPTT的中心思想和BP算法相同,沿着需要优化的参数的负梯度方向不断寻找更优的点直至收敛。综上所述,BPTT算法本质还是BP算法,BP算法本质还是梯度下降法,那么求各个参数的梯度便成了此算法的核心。
RNN发展历史
RNN的常见算法分类:
参考连接:https://zhuanlan.zhihu.com/p/148172079
1)、完全递归网络(Fully recurrent network)
2)、Hopfield网络(Hopfield network)
3)、Elman networks and Jordannetworks
4)、回声状态网络(Echo state network)
5)、长短记忆网络(Long short term memery network)
6)、双向网络(Bi-directional RNN)
7)、持续型网络(Continuous-time RNN)
8)、分层RNN(Hierarchical RNN)
9)、复发性多层感知器(Recurrent multilayer perceptron)
10)、二阶递归神经网络(Second Order Recurrent Neural Network)
11)、波拉克的连续的级联网络(Pollack’s sequential cascaded networks)
2、配置和架构
https://en.wikipedia.org/wiki/Recurrent_neural_network
基于 RNN 的模型可以分为两部分:配置和架构。多个 RNN 可以组合成一个数据流,数据流本身就是配置。每个 RNN 本身可以具有任何架构,包括 LSTM、GRU 等。
1.配置
Standard 标准、Stacked RNN 堆叠 RNN、Bidirectional 双向、Encoder-decoder 编码器-解码器、PixelRNN

2.架构
-
Fully recurrent 完全循环
完全递归神经网络 (FRNN) 将所有神经元的输出连接到所有神经元的输入。换句话说,它是一个完全连接的网络 。这是最通用的神经网络拓扑,因为所有其他拓扑都可以通过将某些连接权重设置为零来表示,以模拟这些神经元之间缺少连接的情况。 -
Hopfield 霍普菲尔德
Hopfield 网络是一个 RNN,其中跨层的所有连接大小相等。它需要固定的输入,因此不是通用的 RNN,因为它不处理 pattern 序列。但是,它保证它将收敛。如果连接是使用 Hebbian 学习进行训练的,那么 Hopfield 网络可以作为强大的内容可寻址内存运行,抵抗连接更改。 -
Elman 网络和 Jordan 网络
Elman网络是一个三层网络(图中水平排列为x、 y 和 z ),并增加了一组上下文单元(图中为u )。中间层(隐藏层)以 1 的权重固定连接到这些上下文单元。[ 51 ]在每个时间步,输入都会前馈,并应用学习规则。固定的反向连接保存了上下文单元中隐藏单元先前值的副本(因为它们在应用学习规则之前通过连接传播)。因此,网络可以维持某种状态,使其能够执行标准多层感知器无法完成的序列预测等任务。
Jordan网络与 Elman 网络类似。上下文单元由输出层而非隐藏层提供。Jordan 网络中的上下文单元也称为状态层。它们与自身具有循环连接。 [ 51 ]
-
Long short-term memory 长短期记忆
长短期记忆(LSTM) 是最广泛使用的 RNN 架构。它旨在解决消失梯度问题。LSTM 通常由称为“遗忘门”的循环门增强。[ 54 ] LSTM 可防止反向传播的错误消失或爆炸。[ 55 ]相反,错误可以通过空间中展开的无限数量的虚拟层向后流动。也就是说,LSTM 可以学习需要记忆数千甚至数百万个离散时间步骤前发生的事件的任务。可以发展针对特定问题的 LSTM 类拓扑。[ 56 ]即使在重要事件之间有较长的延迟,LSTM 也能正常工作,并且可以处理混合了低频和高频分量的信号。
许多应用都使用 LSTM 堆栈,[ 57 ]因此被称为“深度 LSTM”。与基于隐马尔可夫模型(HMM) 和类似概念的先前模型不同,LSTM 可以学习识别上下文相关的语言。 [ 58 ] -
Gated recurrent unit 门控循环单元
门控循环单元(GRU) 于 2014 年推出,旨在简化 LSTM。它们以完整形式和几个进一步简化的变体使用。[ 59 ] [ 60 ]由于没有输出门,它们的参数比 LSTM 少。[ 61 ]它们在复音音乐建模和语音信号建模方面的表现与长短期记忆相似。[ 62 ] LSTM 和 GRU 之间似乎没有特别的性能差异。[ 62 ] [ 63 ] -
Bidirectional associative memory双向关联存储器
由 Bart Kosko 提出,[64] 双向关联记忆 (BAM) 网络是 Hopfield 网络的一种变体,它将关联数据存储为向量。双向性来自通过矩阵传递信息及其转置 。通常,双极编码优于关联对的二进制编码。最近,使用马尔可夫步进的随机 BAM 模型得到了优化,以提高网络稳定性和与实际应用的相关性。[65]BAM 网络有两层,其中任何一层都可以作为输入驱动,以调用关联并在另一层上生成输出。[66]
常见变体与改进
-
LSTM(长短期记忆网络):
引入输入门、遗忘门和输出门,通过门控机制选择性保留或遗忘信息,有效缓解梯度消失问题12。 -
GRU(门控循环单元):
简化 LSTM 结构,合并部分门控单元,减少参数量的同时保持性能4。 -
双向 RNN(BiRNN):
同时考虑序列的前向和后向信息,适用于需要上下文理解的场景(如命名实体识别)
3、基本结构
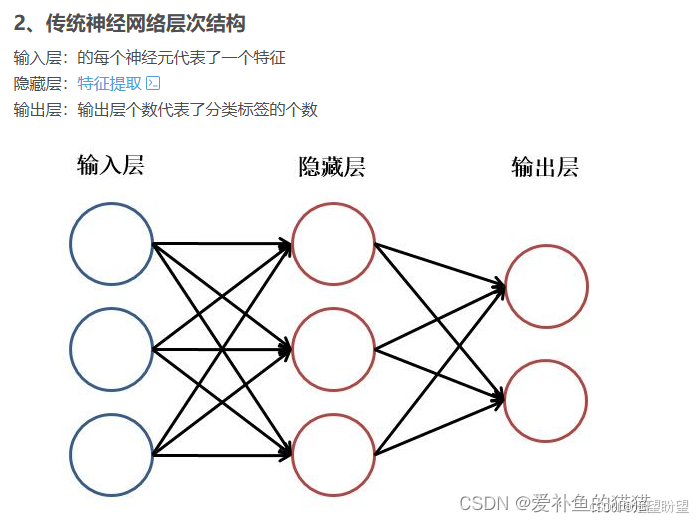
1.神经元
https://mp.weixin.qq.com/s/MIL14-IKjJ_mF66S3brNrg

2.RNN
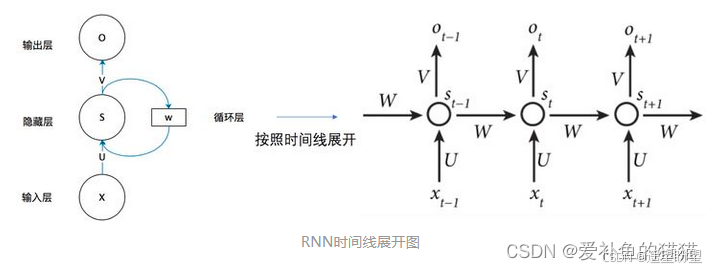
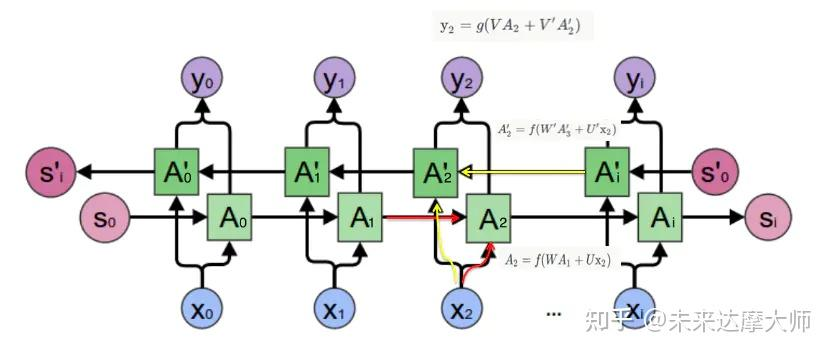
1. RNN和前馈网络区别:
循环神经网络是一种对序列数据有较强的处理能力的网络, 这些序列型的数据具有时序上的关联性的,既某一时刻网络的输出除了与当前时刻的输入相关之外,还与之前某一时刻或某几个时刻的输出相关。传统神经网络(包括CNN),输入和输出都是互相独立的,前馈神经网络并不能处理好这种关联性,因为它没有记忆能力,所以前面时刻的输出不能传递到后面的时刻。
循环神经网络,是指在全连接神经网络的基础上增加了前后时序上的关系,RNN包括三个部分:输入层、隐藏层和输出层。相对于前馈神经网络,RNN可以接收上一个时间点的隐藏状态。(在传统的神经网络模型中,是从输入层到隐含层再到输出层(三个层),层与层之间是全连接的(上下层之间),每层之间的节点是无连接的(同层之间)。)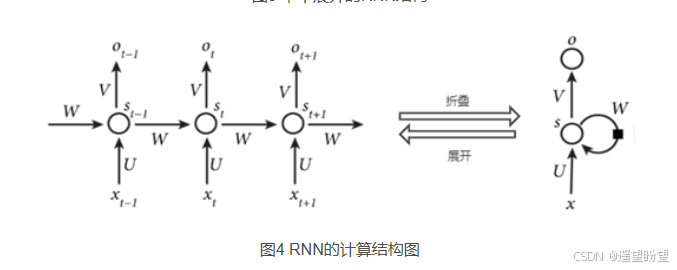
图中 x、s、o (或x、h、y)分别代表 RNN 神经元的输入、隐藏状态、输出。
U、W、V 是对向量 x、s、o(或x、h、y) 进行线性变换的矩阵。
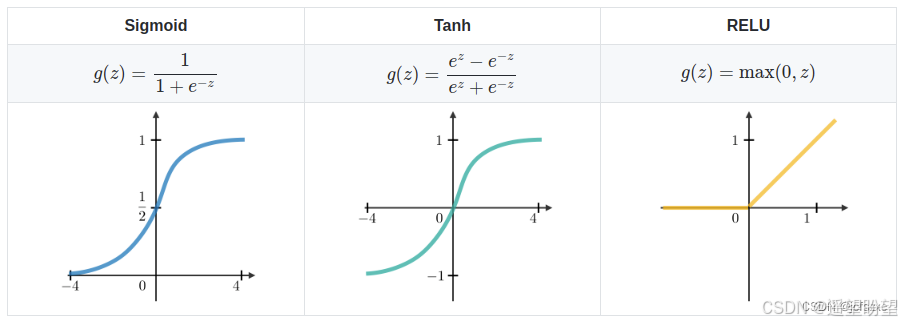
计算 St 时激活函数通常采用 tanh,计算输出 Ot 时激活函数通常是 softmax (分类)。
参考:
https://blog.csdn.net/kevinjin2011/article/details/125069293
https://blog.csdn.net/weixin_44986037/article/details/128923058
https://blog.csdn.net/weixin_44986037/article/details/128954608
2. 计算公式:
https://zhuanlan.zhihu.com/p/149869659
h2的计算和h1类似。要注意的是,在计算时,每一步使用的参数U、W、b都是一样的,也就是说每个步骤的参数都是共享的,这是RNN的重要特点,一定要牢记。
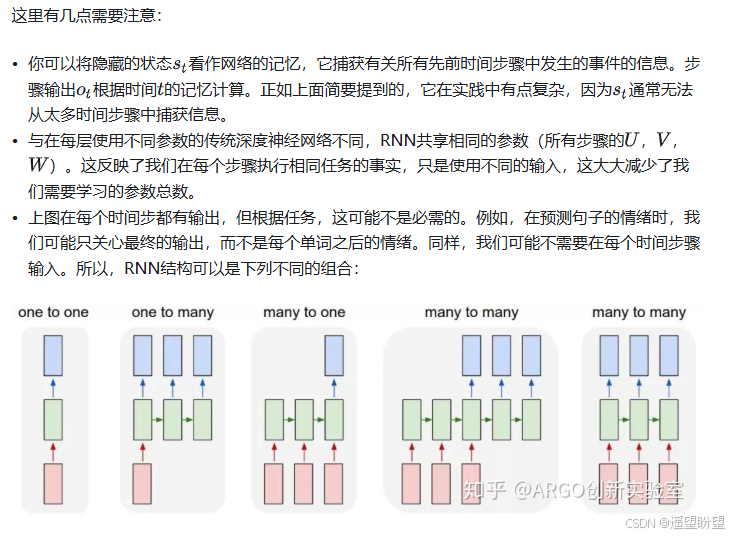 RNN分为一对一、一对多、多对一、多对多,其中多对多分为两种。
RNN分为一对一、一对多、多对一、多对多,其中多对多分为两种。
1.单个神经网络,即一对一。2.单一输入转为序列输出,即一对多。这类RNN可以处理图片,然后输出图片的描述信息。3.序列输入转为单个输出,即多对一。多用在电影评价分析。4.编码解码(Seq2Seq)结构。seq2seq的应用的范围非常广泛,语言翻译,文本摘要,阅读理解,对话生成等。5.输入输出等长序列。这类限制比较大,常见的应用有作诗机器人。
层次可分为:单层RNN、多层RNN、双向RNN
3. 梯度消失:
循环神经网络在进行反向传播时也面临梯度消失或者梯度爆炸问题,这种问题表现在时间轴上。如果输入序列的长度很长,人们很难进行有效的参数更新。通常来说梯度爆炸更容易处理一些。梯度爆炸时我们可以设置一个梯度阈值,当梯度超过这个阈值的时候可以直接截取。
有三种方法应对梯度消失问题:
(1)合理的初始化权重值。初始化权重,使每个神经元尽可能不要取极大或极小值,以躲开梯度消失的区域。
(2) 使用 ReLu 代替 sigmoid 和 tanh 作为激活函数。
(3) 使用其他结构的RNNs,比如长短时记忆网(LSTM)和 门控循环单元 (GRU),这是最流行的做法。
4. RNN类型:(查看发展史)
RNN–>LATM—>BPTT—>GUR–>RNN LM—>word2vec–>seq2seq–>BERT–>transformer–>GPT
反向传播(BP)和基于时间的反向传播算法BPTT
BPTT(back-propagation through time)算法是常用的训练RNN的方法,其实本质还是BP算法,只不过RNN处理时间序列数据,所以要基于时间反向传播,故叫随时间反向传播。BPTT的中心思想和BP算法相同,沿着需要优化的参数的负梯度方向不断寻找更优的点直至收敛。综上所述,BPTT算法本质还是BP算法,BP算法本质还是梯度下降法,那么求各个参数的梯度便成了此算法的核心。
5. 网络区别
RNN(循环神经网络,Recurrent Neural Network)和前馈神经网络(Feedforward Neural Network,也称为多层感知机,MLP)是两种常见的神经网络结构,它们在结构和应用场景上有显著的区别。以下是它们的主要区别:
-
前馈网络:
- 是一种最基础的神经网络结构,数据从输入层流向隐藏层,再流向输出层,没有反馈或循环。
- 每个神经元只接收前一层的输入,不与同一层或后面的层交互。
- 结构是静态的,没有记忆功能。
-
RNN:
- 引入了循环结构,允许信息在神经元之间循环传递。
- 隐藏层的状态会传递到下一个时间步,因此 RNN 具有“记忆”功能,可以处理序列数据。
- 结构是动态的,适合处理时间序列或序列数据。
3.LSTM
参考:
https://zhuanlan.zhihu.com/p/149869659
https://www.jianshu.com/p/247a72812aff
https://www.jianshu.com/p/0cf7436c33ae
https://blog.csdn.net/mary19831/article/details/129570030
LSTM 缓解梯度消失、梯度爆炸,RNN 中出现梯度消失的原因主要是梯度函数中包含一个连乘项
1、RNN中梯度问题
反向传播(求导)连乘项就是导致 RNN 出现梯度消失与梯度爆炸的罪魁祸首


对上面的部分解释:


由于预测的误差是沿着神经网络的每一层反向传播的,因此当雅克比矩阵的最大特征值大于1时,随着离输出越来越远,每层的梯度大小会呈指数增长,导致梯度爆炸;反之,若雅克比矩阵的最大特征值小于1,梯度的大小会呈指数缩小,产生梯度消失。对于普通的前馈网络来说,梯度消失意味着无法通过加深网络层次来改善神经网络的预测效果,因为无论如何加深网络,只有靠近输出的若干层才真正起到学习的作用。这使得循环神经网络模型很难学习到输入序列中的长距离依赖关系。
参考:
https://zhuanlan.zhihu.com/p/149869659
https://www.jianshu.com/p/247a72812aff
https://www.jianshu.com/p/0cf7436c33ae
2、LSTM结构
-
LSTM结构
LSTM 缓解梯度消失、梯度爆炸,RNN 中出现梯度消失的原因主要是梯度函数中包含一个连乘项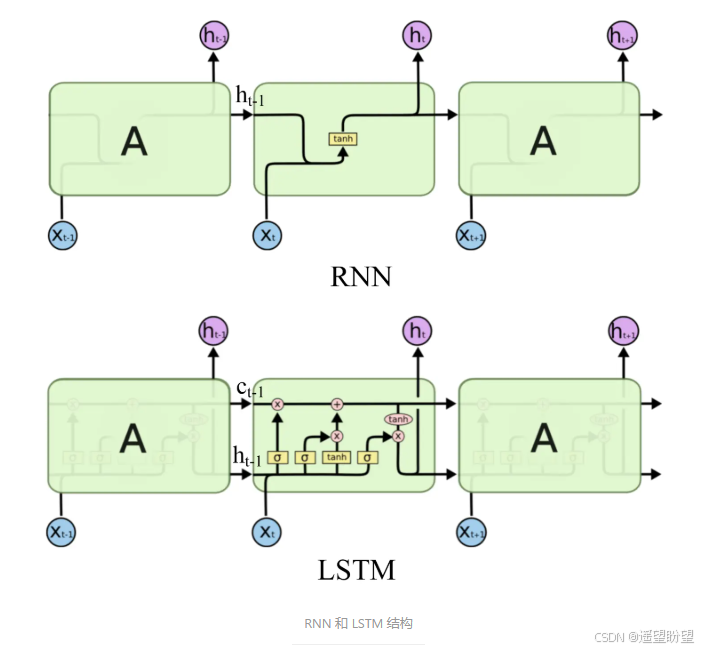
LSTM(长短时记忆网络)是一种常用于处理序列数据的深度学习模型,与传统的 RNN(循环神经网络)相比,LSTM引入了三个门( 输入门、遗忘门、输出门,如下图所示)和一个 细胞状态(cell state),这些机制使得LSTM能够更好地处理序列中的长期依赖关系。注意:小蝌蚪形状表示的是sigmoid激活函数
而 LSTM 的神经元在此基础上还输入了一个 cell 状态 ct-1, cell 状态 c 和 RNN 中的隐藏状态 h 相似,都保存了历史的信息,从 ct-2 ~ ct-1 ~ ct。在 LSTM 中 c 与 RNN 中的 h 扮演的角色很像,都是保存历史状态信息,而在 LSTM 中的 h 更多地是保存上一时刻的输出信息。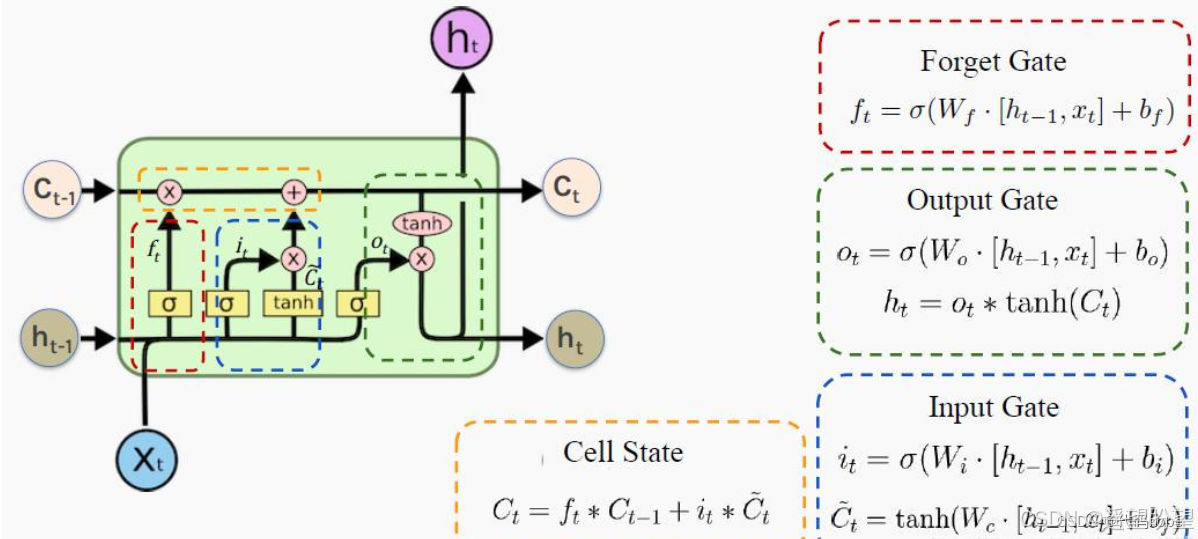
-
遗忘门:
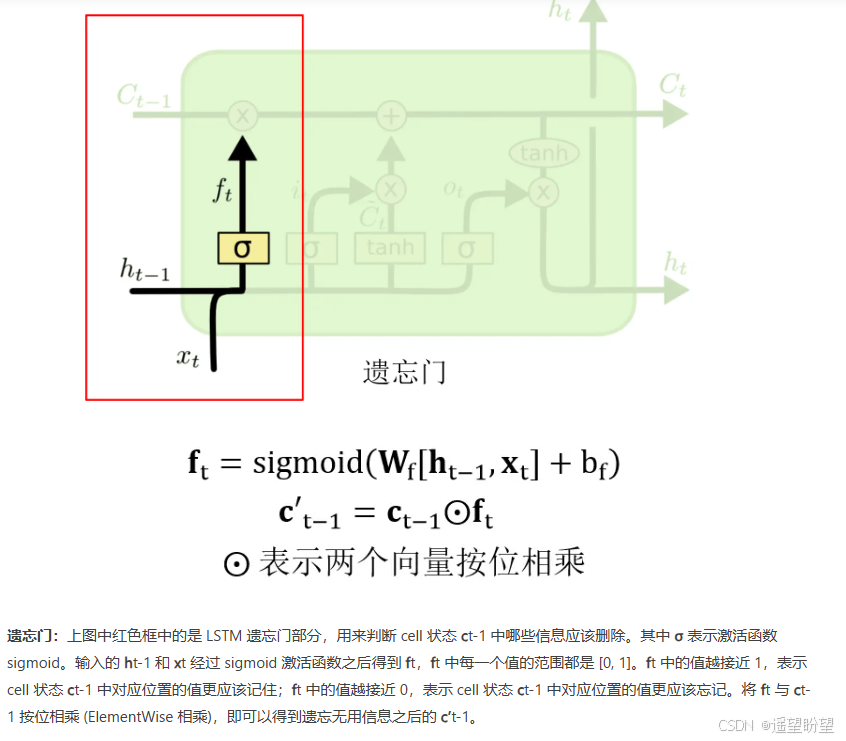
-
输入门
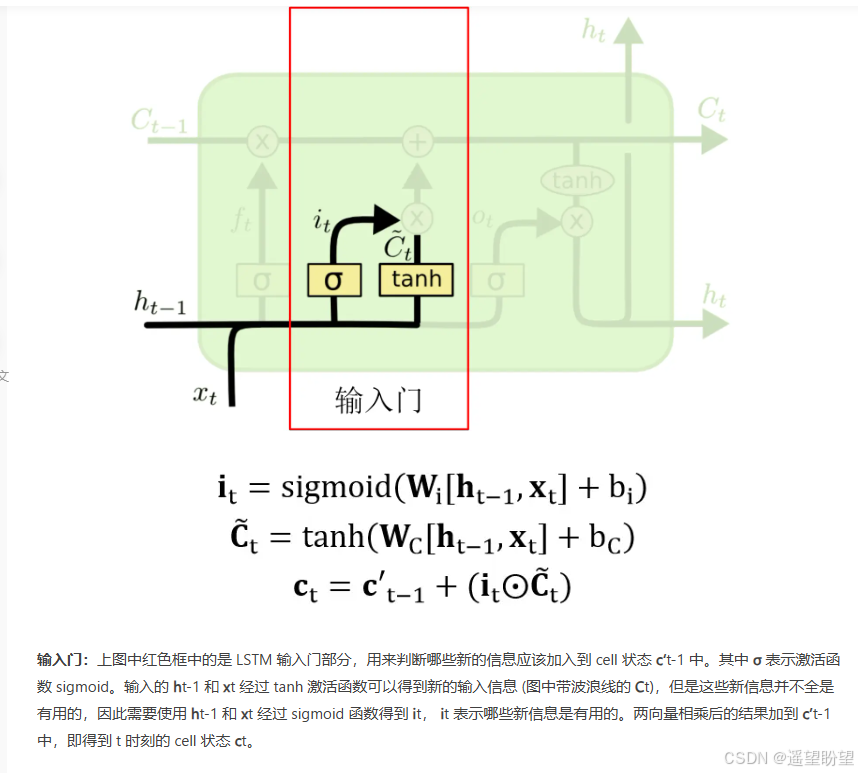
-
输出门
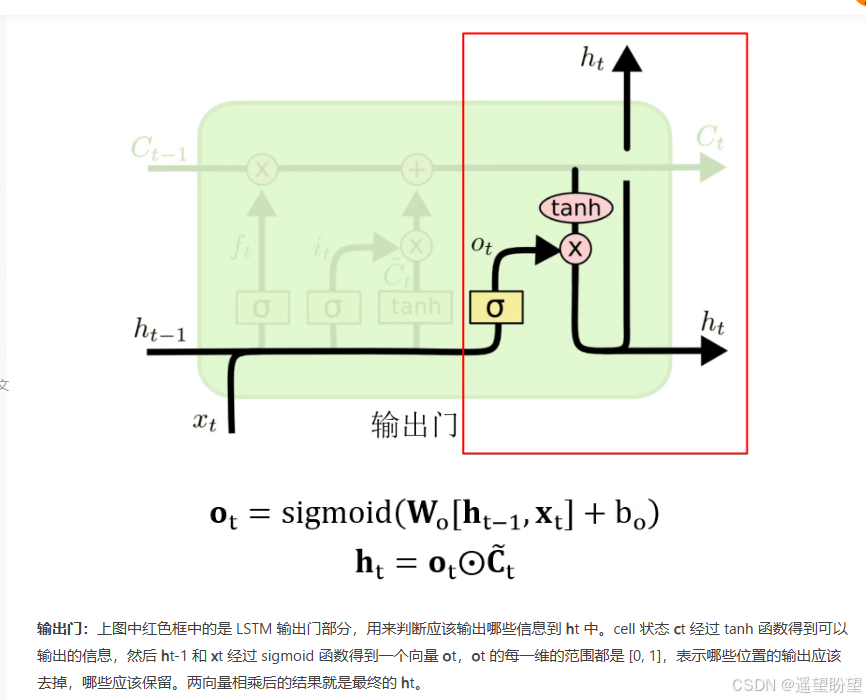
3、LSTM梯度缓解
梯度爆炸和梯度消失缓解


一、LSTM 反向传播求导核心推导
LSTM 的梯度反向传播需计算损失函数对各参数(权重 W , U W, U W,U、偏置 b b b)和隐藏状态的梯度,核心是细胞状态 c t c_t ct 和门控信号的梯度传递。以下为关键推导步骤(符号定义同正向传播, σ \sigma σ 为 sigmoid,导数 σ ′ = σ ( 1 − σ ) \sigma' = \sigma(1-\sigma) σ′=σ(1−σ); tanh ′ = 1 − tanh 2 \tanh' = 1-\tanh^2 tanh′=1−tanh2):
1. 定义反向传播变量
设 δ t = ∂ L ∂ h t \delta_t = \frac{\partial L}{\partial h_t} δt=∂ht∂L(当前时刻隐藏状态对损失的梯度),需推导 δ t \delta_t δt 对 h t − 1 h_{t-1} ht−1、 c t − 1 c_{t-1} ct−1 及各层参数的梯度。
2. 输出门 o t o_t ot 的梯度
∂ L ∂ o t = δ t ⊙ tanh ( c t ) (链式法则: h t = o t ⊙ tanh ( c t ) ) \frac{\partial L}{\partial o_t} = \delta_t \odot \tanh(c_t) \quad \text{(链式法则:$h_t = o_t \odot \tanh(c_t)$)} ∂ot∂L=δt⊙tanh(ct)(链式法则:ht=ot⊙tanh(ct))
对输出门权重 W o , U o W_o, U_o Wo,Uo 的梯度:
∂ L ∂ W o = ∂ L ∂ o t ⊙ o t ⊙ ( 1 − o t ) ⊙ x t T , ∂ L ∂ U o = ∂ L ∂ o t ⊙ o t ⊙ ( 1 − o t ) ⊙ h t − 1 T \frac{\partial L}{\partial W_o} = \frac{\partial L}{\partial o_t} \odot o_t \odot (1-o_t) \odot x_t^T, \quad \frac{\partial L}{\partial U_o} = \frac{\partial L}{\partial o_t} \odot o_t \odot (1-o_t) \odot h_{t-1}^T ∂Wo∂L=∂ot∂L⊙ot⊙(1−ot)⊙xtT,∂Uo∂L=∂ot∂L⊙ot⊙(1−ot)⊙ht−1T
3. 细胞状态 c t c_t ct 的梯度
∂ L ∂ c t = δ t ⊙ o t ⊙ ( 1 − tanh 2 ( c t ) ) + ∂ L ∂ c t + 1 ⊙ f t + 1 (当前时刻隐藏状态 + 下一时刻细胞状态的贡献) \frac{\partial L}{\partial c_t} = \delta_t \odot o_t \odot (1 - \tanh^2(c_t)) + \frac{\partial L}{\partial c_{t+1}} \odot f_{t+1} \quad \text{(当前时刻隐藏状态 + 下一时刻细胞状态的贡献)} ∂ct∂L=δt⊙ot⊙(1−tanh2(ct))+∂ct+1∂L⊙ft+1(当前时刻隐藏状态 + 下一时刻细胞状态的贡献)
4. 遗忘门 f t f_t ft、输入门 i t i_t it、候选细胞 c ~ t \tilde{c}_t c~t 的梯度
- 遗忘门(控制历史信息保留):
∂ L ∂ f t = ∂ L ∂ c t ⊙ c t − 1 ⊙ f t ⊙ ( 1 − f t ) \frac{\partial L}{\partial f_t} = \frac{\partial L}{\partial c_t} \odot c_{t-1} \odot f_t \odot (1-f_t) ∂ft∂L=∂ct∂L⊙ct−1⊙ft⊙(1−ft) - 输入门(控制新信息注入):
∂ L ∂ i t = ∂ L ∂ c t ⊙ c ~ t ⊙ i t ⊙ ( 1 − i t ) \frac{\partial L}{\partial i_t} = \frac{\partial L}{\partial c_t} \odot \tilde{c}_t \odot i_t \odot (1-i_t) ∂it∂L=∂ct∂L⊙c~t⊙it⊙(1−it) - 候选细胞状态(非线性变换):
∂ L ∂ c ~ t = ∂ L ∂ c t ⊙ i t ⊙ ( 1 − c ~ t 2 ) \frac{\partial L}{\partial \tilde{c}_t} = \frac{\partial L}{\partial c_t} \odot i_t \odot (1 - \tilde{c}_t^2) ∂c~t∂L=∂ct∂L⊙it⊙(1−c~t2)
5. 向过去时刻传递梯度
- 隐藏状态梯度:
δ t − 1 = ( W i T ∂ L ∂ i t + W f T ∂ L ∂ f t + W o T ∂ L ∂ o t + W c T ∂ L ∂ c ~ t ) ⊙ σ ′ ( h t − 1 ) \delta_{t-1} = \left( W_i^T \frac{\partial L}{\partial i_t} + W_f^T \frac{\partial L}{\partial f_t} + W_o^T \frac{\partial L}{\partial o_t} + W_c^T \frac{\partial L}{\partial \tilde{c}_t} \right) \odot \sigma'(h_{t-1}) δt−1=(WiT∂it∂L+WfT∂ft∂L+WoT∂ot∂L+WcT∂c~t∂L)⊙σ′(ht−1)
(各门将梯度传递回前一时刻隐藏状态, σ ′ \sigma' σ′ 为 sigmoid 导数,控制衰减) - 细胞状态梯度:
∂ L ∂ c t − 1 = ∂ L ∂ c t ⊙ f t \frac{\partial L}{\partial c_{t-1}} = \frac{\partial L}{\partial c_t} \odot f_t ∂ct−1∂L=∂ct∂L⊙ft
(核心路径:若 f t ≈ 1 f_t \approx 1 ft≈1,梯度近乎无损传递,缓解消失)
二、梯度消失的缓解:LSTM 结构设计核心
传统 RNN 梯度消失的本质是:反向传播时,梯度需经过多层激活函数(sigmoid/tanh 导数 < 1),导致 ∏ 导数 ≈ 0 \prod \text{导数} \approx 0 ∏导数≈0(指数衰减)。
LSTM 通过门控机制重构梯度传递路径,核心策略:
-
遗忘门主导的恒等映射
- 若 f t = 1 f_t = 1 ft=1(完全保留历史细胞状态),则 c t = c t − 1 + i t ⊙ c ~ t c_t = c_{t-1} + i_t \odot \tilde{c}_t ct=ct−1+it⊙c~t,此时 ∂ c t ∂ c t − 1 = f t = 1 \frac{\partial c_t}{\partial c_{t-1}} = f_t = 1 ∂ct−1∂ct=ft=1,梯度传递为 恒等映射(无衰减)。
- 实际中,遗忘门通过学习动态调整 f t f_t ft(接近 1 时保留历史信息,接近 0 时遗忘),避免梯度因激活函数导数衰减而消失。
-
分离非线性变换与梯度路径
- 输入门 i t i_t it 和候选细胞 c ~ t \tilde{c}_t c~t 的非线性操作(sigmoid/tanh)仅影响新信息注入,而历史信息传递( c t − 1 → c t c_{t-1} \to c_t ct−1→ct)由线性操作(乘以 f t f_t ft)主导,绕过了激活函数导数的衰减问题。
-
梯度的多路径传播
- 梯度可通过 c t → c t − 1 c_t \to c_{t-1} ct→ct−1(主要路径,线性)和 h t → h t − 1 h_t \to h_{t-1} ht→ht−1(次要路径,非线性)传递,前者的稳定性确保长距离依赖的梯度有效保留。
三、梯度爆炸的缓解:训练阶段的外部策略
LSTM 未从结构上解决梯度爆炸(权重矩阵乘积的行列式可能过大),需依赖以下训练技巧:
- 梯度裁剪(Gradient Clipping)
- 原理:直接限制梯度范数,避免数值溢出。
- 操作:设定阈值 C C C,若梯度范数 ∥ ∇ ∥ > C \|\nabla\| > C ∥∇∥>C,则将其缩放为:
∇ = C ⋅ ∇ ∥ ∇ ∥ \nabla = \frac{C \cdot \nabla}{\|\nabla\|} ∇=∥∇∥C⋅∇ - 优势:简单有效,不依赖模型结构,广泛应用于 RNN/LSTM 训练。
- 合理的权重初始化
- 正交初始化:确保权重矩阵正交(特征值为 1),避免奇异值过大导致的梯度放大。
- Xavier/Glorot 初始化:根据输入输出维度动态调整初始范围,使激活值和梯度的方差在层间保持稳定。
- 优势:从初始条件抑制权重矩阵的极端值,降低爆炸风险。
- 正则化与 Dropout
- L2 正则化:在损失函数中添加 λ ∥ W ∥ 2 \lambda\|W\|^2 λ∥W∥2,惩罚权重过大,迫使参数保持较小值。
- 门控层 Dropout:对输入门、遗忘门、输出门的输入施加 Dropout(而非细胞状态),避免破坏梯度主路径,同时增加模型鲁棒性。
- 自适应优化器
- 使用 RMSprop、Adam 等优化器,通过动态调整学习率(如 Adam 的二阶矩估计),缓解梯度爆炸的影响。需注意超参数(如 β 2 \beta_2 β2)的设置,避免过度衰减梯度。
四、总结
- LSTM 缓解梯度消失的本质:通过遗忘门控制的细胞状态线性传递(恒等映射),将传统 RNN 的“指数衰减路径”转化为“稳定路径”,确保长距离梯度有效传播。
- 梯度爆炸的解决:依赖训练技巧(梯度裁剪、权重初始化等),而非结构本身,因 LSTM 无法阻止权重矩阵因参数更新导致的行列式爆炸。
- 核心价值:LSTM 的门控机制(尤其是细胞状态的线性路径)是解决梯度消失的关键,而梯度爆炸需结合外部策略共同优化,二者结合使 LSTM 在长序列任务中表现优异。
参考:https://www.jianshu.com/p/247a72812aff
单层和多层(层数)
Lstm层数:(单层和多层:num_layers=1,LSTM 层数)
参考:
https://blog.csdn.net/qq_39777550/article/details/106659150
https://zhuanlan.zhihu.com/p/599514805
多层LSTM的输入与输出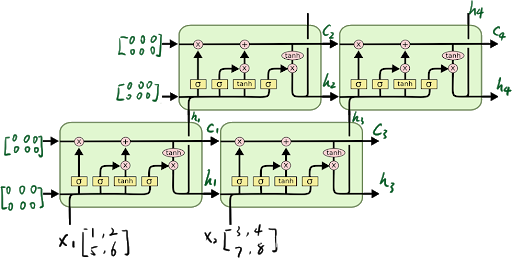
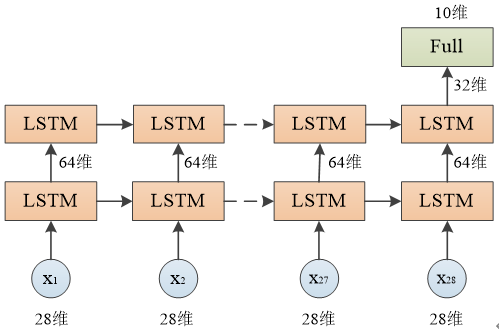
对于多层的LSTM,需要把第一层的每个时间步的输出作为第二层的时间步的输入,如上图所示。
对于num_layers层LSTM:
输入数据:
- X的格式: (seq_len,batch,input_size)
- h0的格式: (num_layers,batch,hidden_size)
- c0的格式: (num_layers,batch,hidden_size)
输出数据:
- H的格式: (seq_len,batch,hidden_size)
- hn的格式:(num_layers,batch,hidden_size)
- cn的格式:(num_layers,batch,hidden_size)
如果是双向的,即在LSTM()函数中,添加关键字bidirectional=True,则:
单向则num_direction=1,双向则num_direction=2
输入数据格式:
input(seq_len, batch, input_size)
h0(num_layers * num_directions, batch, hidden_size)
c0(num_layers * num_directions, batch, hidden_size)
输出数据格式:
output(seq_len, batch, hidden_size * num_directions)
hn(num_layers * num_directions, batch, hidden_size)
cn(num_layers * num_directions, batch, hidden_size)
单向和双向
参考:
https://zhuanlan.zhihu.com/p/599514805
https://zhuanlan.zhihu.com/p/443780902
BiLSTM 原理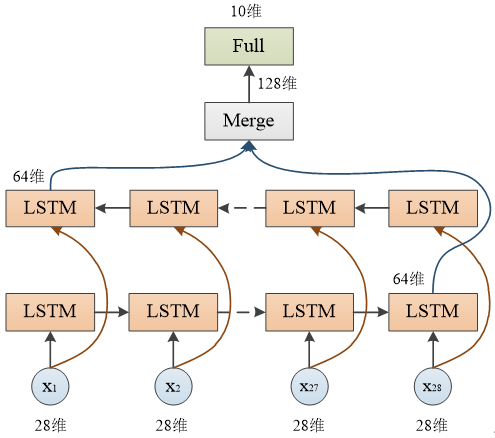
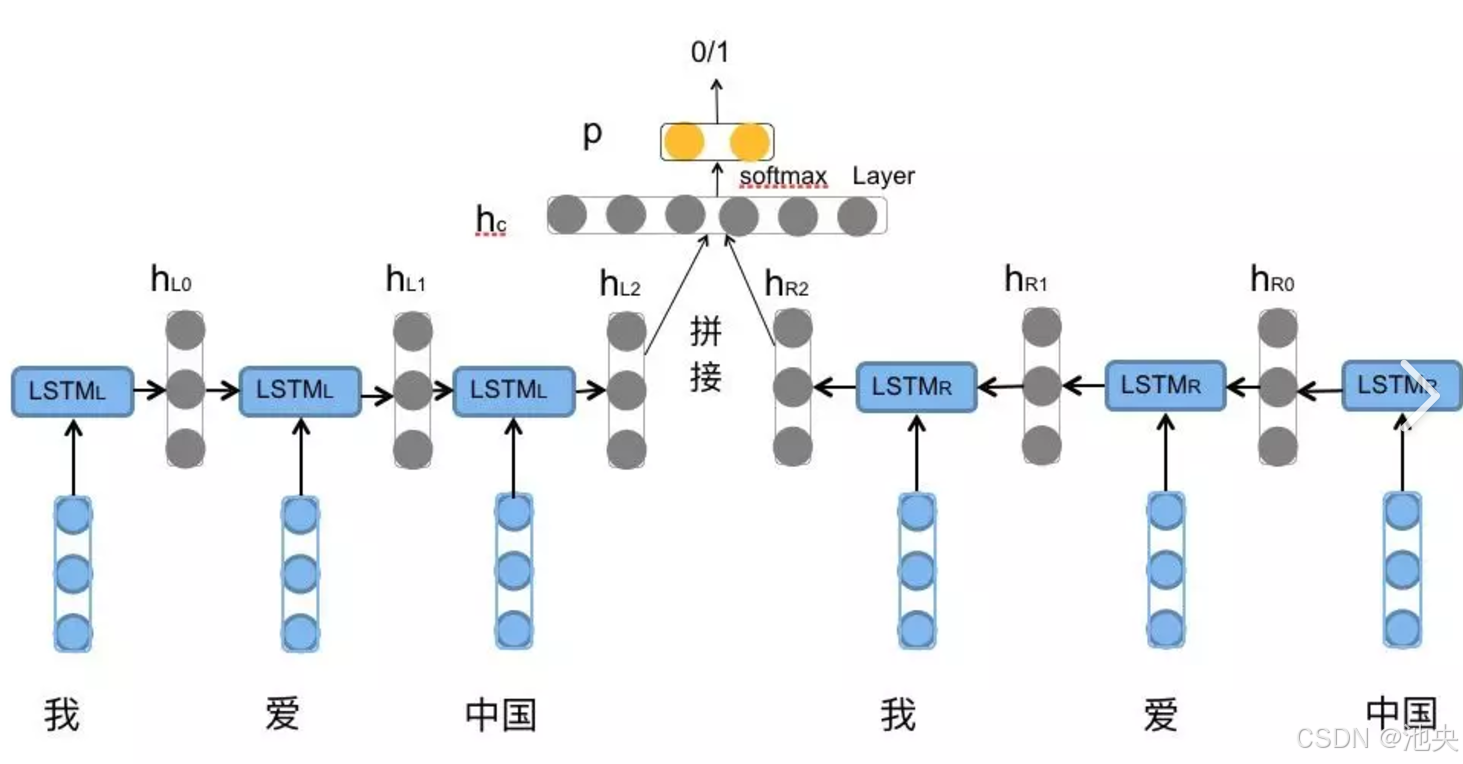
4.GRU
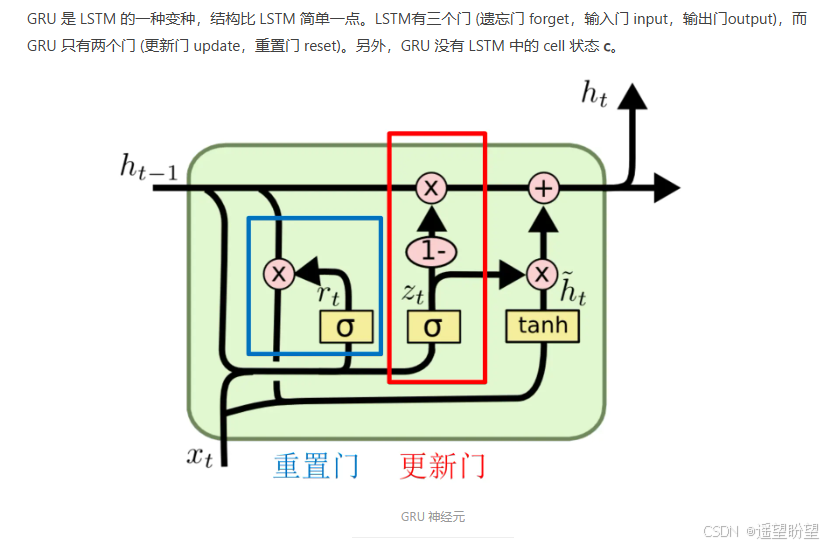

参考:
https://www.jianshu.com/p/0cf7436c33ae
4、参数说明
1、Lstm参数
lstm网络初始化和输入/输出参数说明,结合网络结构
https://zhuanlan.zhihu.com/p/100360301
LSTM 网络初始化和输入/输出参数说明(结合网络结构)
-
模型构造参数
nn.LSTM( input_size, # 输入特征维度 hidden_size, # 隐藏层维度(输出维度) num_layers=1, # LSTM 层数 bias=True, # 是否使用偏置项 batch_first=False, # 输入/输出是否以 batch 为第一维 dropout=0, # 除最后一层外的 dropout 概率 bidirectional=False # 是否使用双向 LSTM )
- A:默认情况下,PyTorch 的 LSTM 输入格式为
[seq_len, batch_size, input_size]。如果数据是按批次优先存储的(例如[batch_size, seq_len, input_size]),则需要设置batch_first=True。
-
单层和多层:
对于num_layers层LSTM:
输入数据:- X的格式: (seq_len,batch,input_size)
- h0的格式: (num_layers,batch,hidden_size)
- c0的格式: (num_layers,batch,hidden_size)
输出数据:
- H的格式: (seq_len,batch,hidden_size)
- hn的格式:(num_layers,batch,hidden_size)
- cn的格式:(num_layers,batch,hidden_size)
-
双向:(单向和多向)
如果是双向的,即在LSTM()函数中,添加关键字bidirectional=True,则:
单向则num_direction=1,双向则num_direction=2
输入数据格式:
input(seq_len, batch, input_size)
h0(num_layers * num_directions, batch, hidden_size)
c0(num_layers * num_directions, batch, hidden_size)
输出数据格式:
output(seq_len, batch, hidden_size * num_directions)
hn(num_layers * num_directions, batch, hidden_size)
cn(num_layers * num_directions, batch, hidden_size)
1. LSTM 网络结构
公式
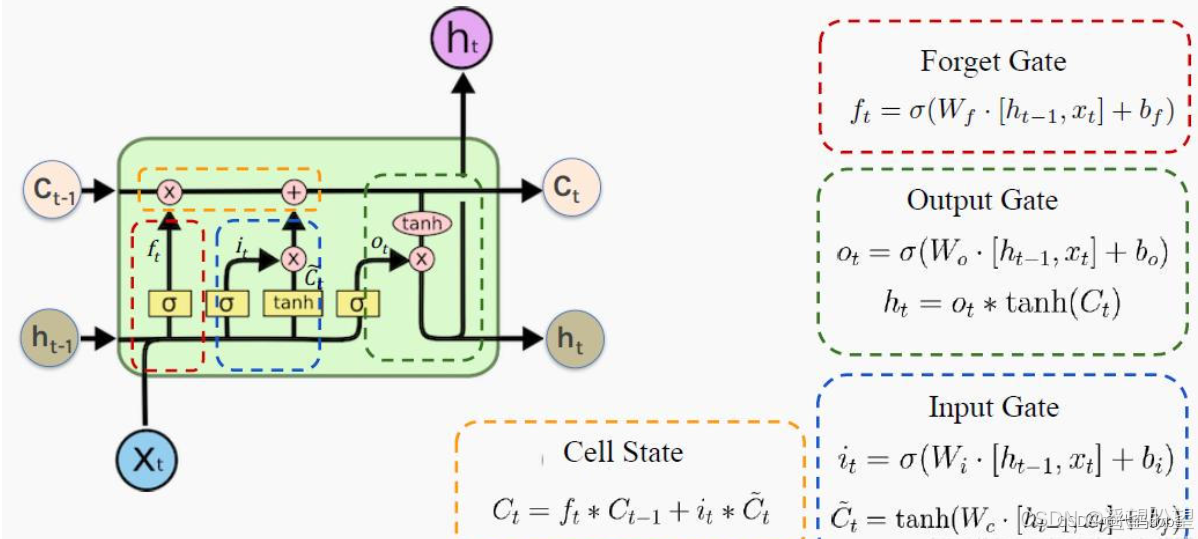
LSTM 核心结构包含 细胞状态(Cell State) 和 三个门控机制:
-
遗忘门(Forget Gate)
决定哪些信息从细胞状态中遗忘。
公式:
f t = σ ( W f ⋅ [ h t − 1 , x t ] + b f ) f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f) ft=σ(Wf⋅[ht−1,xt]+bf)- σ \sigma σ:Sigmoid 激活函数,输出范围 [0,1]。
- W f , b f W_f, b_f Wf,bf:遗忘门的权重和偏置。
-
输入门(Input Gate)
决定哪些新信息需要添加到细胞状态。
公式:- 输入门激活: i t = σ ( W i ⋅ [ h t − 1 , x t ] + b i ) i_t = \sigma(W_i \cdot [h_{t-1}, x_t] + b_i) it=σ(Wi⋅[ht−1,xt]+bi)
- 候选值: C ~ t = tanh ( W C ⋅ [ h t − 1 , x t ] + b C ) \tilde{C}_t = \tanh(W_C \cdot [h_{t-1}, x_t] + b_C) C~t=tanh(WC⋅[ht−1,xt]+bC)
- 更新细胞状态: C t = f t ⋅ C t − 1 + i t ⋅ C ~ t C_t = f_t \cdot C_{t-1} + i_t \cdot \tilde{C}_t Ct=ft⋅Ct−1+it⋅C~t
-
输出门(Output Gate)
决定细胞状态的哪些部分需要输出。
公式:- 输出门激活: o t = σ ( W o ⋅ [ h t − 1 , x t ] + b o ) o_t = \sigma(W_o \cdot [h_{t-1}, x_t] + b_o) ot=σ(Wo⋅[ht−1,xt]+bo)
- 隐藏状态: h t = o t ⋅ tanh ( C t ) h_t = o_t \cdot \tanh(C_t) ht=ot⋅tanh(Ct)
权重纬度(根据输入和输出的纬度计算)
总结
- 权重参数的计算依赖于输入维度(
input_size)和隐藏层维度(hidden_size)。 - 每组门控的权重矩阵维度为
[x, h]和[h, h],偏置向量维度为[h]。 - 总参数数量公式:
4 * hidden_size * (input_size + hidden_size + 1)。
层数
Lstm层数:(单层和多层:num_layers=1,LSTM 层数)
参考:
https://blog.csdn.net/qq_39777550/article/details/106659150
https://zhuanlan.zhihu.com/p/599514805
多层LSTM的输入与输出
对于多层的LSTM,需要把第一层的每个时间步的输出作为第二层的时间步的输入,如上图所示。
对于num_layers层LSTM:
输入数据:
- X的格式: (seq_len,batch,input_size)
- h0的格式: (num_layers,batch,hidden_size)
- c0的格式: (num_layers,batch,hidden_size)
输出数据:
- H的格式: (seq_len,batch,hidden_size)
- hn的格式:(num_layers,batch,hidden_size)
- cn的格式:(num_layers,batch,hidden_size)
如果是双向的,即在LSTM()函数中,添加关键字bidirectional=True,则:
单向则num_direction=1,双向则num_direction=2
输入数据格式:
input(seq_len, batch, input_size)
h0(num_layers * num_directions, batch, hidden_size)
c0(num_layers * num_directions, batch, hidden_size)
输出数据格式:
output(seq_len, batch, hidden_size * num_directions)
hn(num_layers * num_directions, batch, hidden_size)
cn(num_layers * num_directions, batch, hidden_size)
双向
参考:
https://zhuanlan.zhihu.com/p/599514805
https://zhuanlan.zhihu.com/p/443780902
BiLSTM 原理
2. LSTM 网络初始化参数
在 PyTorch 中,nn.LSTM 的初始化参数如下:
nn.LSTM(
input_size, # 输入特征维度
hidden_size, # 隐藏层维度(输出维度)
num_layers=1, # LSTM 层数
bias=True, # 是否使用偏置项
batch_first=False, # 输入/输出是否以 batch 为第一维
dropout=0, # 除最后一层外的 dropout 概率
bidirectional=False # 是否使用双向 LSTM
)
2. 参数详解
| 参数名 | 含义 | 示例说明 |
|---|---|---|
| input_size | 每个时间步的输入特征维度。 | 例如,每个词用 50 维向量表示,则 input_size=50。 |
| hidden_size | 隐藏层的神经元数量(即输出维度)。 | hidden_size=64 表示每个时间步的输出是 64 维向量。 |
| num_layers | 堆叠的 LSTM 层数。 | num_layers=2 表示两个 LSTM 层依次连接。 |
| bias | 是否使用偏置项(Bias)。 | bias=True 表示每个门控函数(输入门、遗忘门、输出门)都有偏置项。 |
| batch_first | 输入/输出是否以 batch_size 为第一维。 |
若为 True,输入格式为 [batch_size, seq_len, input_size]。 |
| dropout | 除最后一层外的 dropout 概率(防止过拟合)。 | dropout=0.2 表示每层输出中随机丢弃 20% 的神经元。 |
| bidirectional | 是否使用双向 LSTM(正向 + 反向处理序列)。 | 若为 True,输出维度翻倍(hidden_size * 2)。 |
2. 输入参数格式
LSTM 的输入是一个 三维张量,其格式由 batch_first 参数决定:
- 默认格式(
batch_first=False):[seq_len, batch_size, input_size] batch_first=True时的格式:[batch_size, seq_len, input_size]
输入参数说明:
| 参数名 | 含义 | 示例说明 |
|---|---|---|
| seq_len | 序列长度(时间步数)。 | 例如,一个句子有 10 个词,则 seq_len=10。 |
| batch_size | 批量大小(每次训练的样本数)。 | 例如,一次训练使用 32 个样本,则 batch_size=32。 |
| input_size | 每个时间步的输入特征维度。 | 例如,每个词用 50 维向量表示,则 input_size=50。 |
示例:
- 若输入格式为
[30, 5, 7],表示:- 每个样本有 30 个时间步(
seq_len=30), - 批量大小为 5(
batch_size=5), - 每个时间步的输入特征为 7 维(
input_size=7)。
- 每个样本有 30 个时间步(
3. 输出参数格式
LSTM 的输出包括以下三个部分:
output:每个时间步的输出。hn:最终的隐藏状态。cn:最终的细胞状态。
(1) output
- 形状:
- 默认格式:
[seq_len, batch_size, hidden_size * num_directions] batch_first=True时:[batch_size, seq_len, hidden_size * num_directions]
- 默认格式:
- 作用:
- 包含每个时间步的输出结果。
- 在分类任务中,通常只取最后一个时间步的输出(
output[:, -1, :])作为最终预测。 - 在序列生成任务中,可能需要所有时间步的输出。
(2) hn 和 cn
- 形状:
[num_layers * num_directions, batch_size, hidden_size] - 作用:
hn:最终的隐藏状态,保存模型对长期信息的记忆。cn:最终的细胞状态,用于控制长期信息的更新。- 通常用于保存模型的长期记忆(如序列生成任务)。
双向 LSTM 的影响:
- 若
bidirectional=True,输出维度会翻倍(hidden_size * 2),因为模型同时处理正向和反向序列。
4. 示例代码(PyTorch)
import torch
import torch.nn as nn
# 定义 LSTM 模型
class LSTMModel(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size, batch_first=True):
super(LSTMModel, self).__init__()
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=batch_first)
self.fc = nn.Linear(hidden_size, output_size) # 全连接层
def forward(self, x):
# x: [batch_size, seq_len, input_size] (若 batch_first=True)
out, (hn, cn) = self.lstm(x) # out: [batch_size, seq_len, hidden_size]
out = self.fc(out[:, -1, :]) # 取最后一个时间步的输出进行分类
return out
# 参数设置
input_size = 7 # 输入特征维度
hidden_size = 64 # 隐藏层维度
num_layers = 2 # LSTM 层数
output_size = 1 # 输出维度
model = LSTMModel(input_size, hidden_size, num_layers, output_size)
print(model)
# 示例输入(batch_first=True)
x = torch.randn(5, 30, 7) # [batch_size=5, seq_len=30, input_size=7]
output = model(x)
print("Output shape:", output.shape) # [5, 1]
3、 代码示例
rnn = nn.LSTM(10, 20, 2) # 一个单词向量长度为10,隐藏层节点数为20,LSTM有2层
input = torch.randn(5, 3, 10) # 输入数据由3个句子组成,每个句子由5个单词组成,单词向量长度为10
h0 = torch.randn(2, 3, 20) # 2:LSTM层数*方向 3:batch 20: 隐藏层节点数
c0 = torch.randn(2, 3, 20) # 同上
output, (hn, cn) = rnn(input, (h0, c0))
print(output.shape, hn.shape, cn.shape)
>>> torch.Size([5, 3, 20]) torch.Size([2, 3, 20]) torch.Size([2, 3, 20])
7. 输入/输出参数对应关系
| 输入参数 | 输出参数 |
|---|---|
input_size |
决定输入特征维度,影响输出的初始维度(hidden_size)。 |
hidden_size |
决定每个时间步的输出维度(output 的第三维)。 |
num_layers |
决定 hn 和 cn 的第一维(num_layers * num_directions)。 |
bidirectional |
若为 True,输出维度会翻倍(hidden_size * 2)。 |
batch_first |
控制输入和输出的第一维是否为 batch_size。 |
8. 常见问题
Q1:为什么需要 batch_first=True?
- A:默认情况下,PyTorch 的 LSTM 输入格式为
[seq_len, batch_size, input_size]。如果数据是按批次优先存储的(例如[batch_size, seq_len, input_size]),则需要设置batch_first=True。
Q2:如何处理双向 LSTM 的输出?
- A:双向 LSTM 的输出维度为
hidden_size * 2。例如,若hidden_size=64,输出为128维。可以通过全连接层调整维度:self.fc = nn.Linear(hidden_size * 2, output_size)
Q3:如何提取特定时间步的输出?
- A:通过索引操作提取。例如,提取第3个时间步的输出:
out = output[:, 2, :] # 第3个时间步(索引从0开始)
9. 应用场景
(1) 序列分类任务
- 输入:
[batch_size, seq_len, input_size] - 输出:取最后一个时间步的输出(
output[:, -1, :])进行分类。
(2) 序列生成任务
- 输入:
[seq_len, batch_size, input_size] - 输出:使用所有时间步的输出(
output)生成序列。
(3) 时间序列预测
- 输入:
[batch_size, seq_len, input_size] - 输出:预测未来时间步的值(例如,使用
output[:, -1, :]作为预测输入)。
"""
首先,features, _ = self.lstm(obs) 这一行将输入的观测数据 obs 传入 LSTM 层。
LSTM 层通常会返回两个值:所有时间步的输出(features),以及最后一个时间步的隐藏状态(这里用 _ 忽略了)。
features 的形状通常是 (batch_size, seq_len, hidden_size),即每个样本、每个时间步、每个隐藏单元的输出。
接下来,return features[:, -1, :] 表示返回每个样本在序列最后一个时间步的 LSTM 输出。
这里 : 表示所有样本,-1 表示序列的最后一个时间步,: 表示所有隐藏单元。
这样做的目的是只保留每个序列最后时刻的特征,通常用于后续的决策或分类任务。
features[:, -1, :] 取出每个样本最后一个时间步的 LSTM 输出,形状为 (batch_size, hidden_size)。
"""
output[:, -1, :] 直接取出 最后时间步 的隐藏状态。
对于单向 LSTM,这与 h_n[-1] 等价;双向或多层时需注意维度与拼接顺序。
通过以上说明和示例,可以灵活地处理 LSTM 的输入/输出参数,并根据具体任务需求调整模型结构!如果需要进一步帮助,请随时提问。
2、RNN参数
RNN 网络初始化和输入/输出参数说明(结合网络结构)
和lstm类似,参考lstm的设置
1. RNN 网络结构
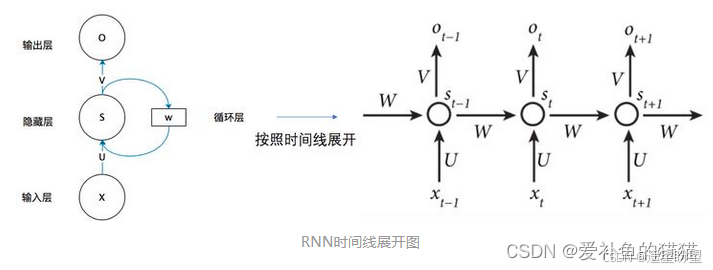

RNN 核心结构包含 隐藏状态(Hidden State) 和 激活函数:
-
隐藏状态更新公式:
h t = tanh ( W x h x t + W h h h t − 1 + b ) h_t = \text{tanh}(W_{xh} x_t + W_{hh} h_{t-1} + b) ht=tanh(Wxhxt+Whhht−1+b) -
x t x_t xt: 当前时间步的输入。
- h t − 1 h_{t-1} ht−1: 前一时间步的隐藏状态。
- W x h , W h h W_{xh}, W_{hh} Wxh,Whh: 输入到隐藏层、隐藏层到隐藏层的权重矩阵。
- b b b: 偏置项。
-
多层 RNN:
- 若
num_layers=2,第一层的输出作为第二层的输入。 - 每层的隐藏状态独立更新。
- 若
-
双向 RNN:
- 若
bidirectional=True,RNN 同时处理正向和反向序列。 - 输出维度为
hidden_size * 2。
- 若
2. RNN 网络初始化参数
在 PyTorch 中,nn.RNN 的初始化参数如下:
nn.RNN(
input_size, # 输入特征维度
hidden_size, # 隐藏层维度(输出维度)
num_layers=1, # RNN 层数
nonlinearity='tanh', # 激活函数('tanh' 或 'relu')
bias=True, # 是否使用偏置项
batch_first=False, # 输入/输出是否以 batch 为第一维
dropout=0, # 除最后一层外的 dropout 概率
bidirectional=False # 是否使用双向 RNN
)
3. 参数详解
| 参数名 | 含义 | 示例说明 |
|---|---|---|
| input_size | 每个时间步的输入特征维度。 | 例如,每个词用 50 维向量表示,则 input_size=50。 |
| hidden_size | 隐藏层的神经元数量(即输出维度)。 | hidden_size=64 表示每个时间步的输出是 64 维向量。 |
| num_layers | 堆叠的 RNN 层数。 | num_layers=2 表示两个 RNN 层依次连接。 |
| nonlinearity | 激活函数(默认 'tanh',也可选 'relu')。 |
nonlinearity='relu' 表示使用 ReLU 激活函数。 |
| bias | 是否使用偏置项(Bias)。 | bias=True 表示每个时间步的计算包含偏置项。 |
| batch_first | 输入/输出是否以 batch_size 为第一维。 |
若为 True,输入格式为 [batch_size, seq_len, input_size]。 |
| dropout | 除最后一层外的 dropout 概率(防止过拟合)。 | dropout=0.2 表示每层输出中随机丢弃 20% 的神经元。 |
| bidirectional | 是否使用双向 RNN(正向 + 反向处理序列)。 | 若为 True,输出维度翻倍(hidden_size * 2)。 |
4. 输入参数格式
RNN 的输入是一个 三维张量,其格式由 batch_first 参数决定:
- 默认格式(
batch_first=False):[seq_len, batch_size, input_size] batch_first=True时的格式:[batch_size, seq_len, input_size]
输入参数说明:
| 参数名 | 含义 | 示例说明 |
|---|---|---|
| seq_len | 序列长度(时间步数)。 | 例如,一个句子有 10 个词,则 seq_len=10。 |
| batch_size | 批量大小(每次训练的样本数)。 | 例如,一次训练使用 32 个样本,则 batch_size=32。 |
| input_size | 每个时间步的输入特征维度。 | 例如,每个词用 50 维向量表示,则 input_size=50。 |
示例:
- 若输入格式为
[30, 5, 7],表示:- 每个样本有 30 个时间步(
seq_len=30), - 批量大小为 5(
batch_size=5), - 每个时间步的输入特征为 7 维(
input_size=7)。
- 每个样本有 30 个时间步(
5. 输出参数格式
RNN 的输出包括以下两个部分:
output:每个时间步的输出。hn:最终的隐藏状态。
(1) output
- 形状:
- 默认格式:
[seq_len, batch_size, hidden_size * num_directions] batch_first=True时:[batch_size, seq_len, hidden_size * num_directions]
- 默认格式:
- 作用:
- 包含每个时间步的输出结果。
- 在分类任务中,通常只取最后一个时间步的输出(
output[:, -1, :])作为最终预测。 - 在序列生成任务中,可能需要所有时间步的输出。
(2) hn
- 形状:
[num_layers * num_directions, batch_size, hidden_size] - 作用:
- 最终的隐藏状态,保存模型对长期信息的记忆。
- 用于保存模型的长期记忆(如序列生成任务)。
双向 RNN 的影响:
- 若
bidirectional=True,输出维度会翻倍(hidden_size * 2),因为模型同时处理正向和反向序列。
6. 示例代码(PyTorch)
import torch
import torch.nn as nn
# 定义 RNN 模型
class RNNModel(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size, batch_first=True):
super(RNNModel, self).__init__()
self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=batch_first)
self.fc = nn.Linear(hidden_size, output_size) # 全连接层
def forward(self, x):
# x: [batch_size, seq_len, input_size] (若 batch_first=True)
out, hn = self.rnn(x) # out: [batch_size, seq_len, hidden_size]
out = self.fc(out[:, -1, :]) # 取最后一个时间步的输出进行分类
return out
# 参数设置
input_size = 7 # 输入特征维度
hidden_size = 64 # 隐藏层维度
num_layers = 2 # RNN 层数
output_size = 1 # 输出维度
model = RNNModel(input_size, hidden_size, num_layers, output_size)
print(model)
# 示例输入(batch_first=True)
x = torch.randn(5, 30, 7) # [batch_size=5, seq_len=30, input_size=7]
output = model(x)
print("Output shape:", output.shape) # [5, 1]
7. 输入/输出参数对应关系
| 输入参数 | 输出参数 |
|---|---|
input_size |
决定输入特征维度,影响输出的初始维度(hidden_size)。 |
hidden_size |
决定每个时间步的输出维度(output 的第三维)。 |
num_layers |
决定 hn 的第一维(num_layers * num_directions)。 |
bidirectional |
若为 True,输出维度会翻倍(hidden_size * 2)。 |
batch_first |
控制输入和输出的第一维是否为 batch_size。 |
8. 常见问题
Q1:为什么需要 batch_first=True?
- A:默认情况下,PyTorch 的 RNN 输入格式为
[seq_len, batch_size, input_size]。如果数据是按批次优先存储的(例如[batch_size, seq_len, input_size]),则需要设置batch_first=True。
Q2:如何处理双向 RNN 的输出?
- A:双向 RNN 的输出维度为
hidden_size * 2。例如,若hidden_size=64,输出为128维。可以通过全连接层调整维度:self.fc = nn.Linear(hidden_size * 2, output_size)
Q3:如何提取特定时间步的输出?
- A:通过索引操作提取。例如,提取第3个时间步的输出:
out = output[:, 2, :] # 第3个时间步(索引从0开始)
9. 应用场景
(1) 序列分类任务
- 输入:
[batch_size, seq_len, input_size] - 输出:取最后一个时间步的输出(
output[:, -1, :])进行分类。
(2) 序列生成任务
- 输入:
[seq_len, batch_size, input_size] - 输出:使用所有时间步的输出(
output)生成序列。
(3) 时间序列预测
- 输入:
[batch_size, seq_len, input_size] - 输出:预测未来时间步的值(例如,使用
output[:, -1, :]作为预测输入)。
通过以上说明和示例,可以灵活地处理 RNN 的输入/输出参数,并根据具体任务需求调整模型结构!如果需要进一步帮助,请随时提问。
10. RNN权重参数是根据输入和输出的纬度计算的
是的,你说得对!RNN(包括 LSTM 和 GRU)中的权重参数数量,确实与输入维度、隐藏单元数量以及层数紧密相关。下面我来详细解释一下权重是如何计算的:
单层 RNN 权重参数计算公式
假设你有如下设置:
input_size = x:每个时间步的输入维度hidden_size = h:隐藏状态维度- 使用单向单层 RNN
RNN 单元包含的权重:
| 名称 | 维度 | 含义 |
|---|---|---|
| Wₓₕ(输入到隐藏层) | (h, x) |
输入 x 乘以该权重矩阵 |
| Wₕₕ(隐藏到隐藏) | (h, h) |
前一时刻隐藏状态 h 乘以该矩阵 |
| bₕ(偏置) | (h,) 或 (1, h) |
每个隐藏单元一个偏置项 |
✅ 总参数数量为:
参数总数 = h ⋅ x + h ⋅ h + h = h ( x + h + 1 ) \text{参数总数} = h \cdot x + h \cdot h + h = h(x + h + 1) 参数总数=h⋅x+h⋅h+h=h(x+h+1)
多层 RNN 参数计算
如果使用 num_layers = n 层:
- 第一层:
input_size = x - 第二层及以上:输入维度变为
hidden_size,因为前一层输出作为后一层输入
所以:
总参数数 = h ( x + h + 1 ) + ( n − 1 ) ⋅ h ( h + h + 1 ) = h ( x + h + 1 + ( n − 1 ) ( 2 h + 1 ) ) \text{总参数数} = h(x + h + 1) + (n - 1) \cdot h(h + h + 1) = h(x + h + 1 + (n - 1)(2h + 1)) 总参数数=h(x+h+1)+(n−1)⋅h(h+h+1)=h(x+h+1+(n−1)(2h+1))
双向 RNN 参数计算
如果设置 bidirectional=True,则每层会有两个方向(forward & backward):
- 参数翻倍:每层的参数数需乘以 2
- 输出维度变为
hidden_size * 2
📝 小结
- 是的,权重确实是根据输入维度、隐藏维度、层数、方向数计算出来的;
- LSTM 和 GRU 会更复杂一些(每个门控机制都有自己的一套权重),比如 LSTM 的参数数量是:
4 ⋅ h ( x + h + 1 ) 4 \cdot h(x + h + 1) 4⋅h(x+h+1)
因为它有 4 个门(输入、遗忘、输出、候选)。
如果你需要我进一步帮你推公式,或者想了解 PyTorch 中如何打印这些参数数量,我可以带你手把手算一遍 😉 要不要试一下?

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)