FitNets: Hints for Thin Deep Nets
尽管增加网络深度通常能提升性能,但更深层的网络往往非线性更强,这使得基于梯度的训练变得更加困难。近期提出的知识蒸馏(knowledge distillation)方法旨在获得更小、执行更快的模型,其研究表明,学生网络可以模仿大型教师网络或集成网络的软输出(soft output)。本文中,我们扩展了这一思想:不仅使用教师网络的输出,还利用其学习到的中间表征(intermediate represe
FitNets:为薄而深网络提供的提示
发表 ICLR 2015
教师模型:3层maxout卷积层、1层maxout全连接层和顶层softmax(9M)
学生模型:17层maxout卷积层、1层maxout全连接层和顶层softmax的FitNet(2.5M)
效果:学生模型的参数为教师模型的1/3,性能教师90.18 - > 学生91.61
问题:传统高性能网络(如教师模型)通常宽而浅(参数量大、计算成本高),难以部署在资源受限设备(如手机、嵌入式系统)中。能否通过知识迁移技术,将宽浅教师模型的能力压缩到参数量更少但更深的学生模型中?
目的:设计一种方法,训练出比教师网络更深更窄(Thin & Deep)的学生模型 参数量大幅减少,性能不劣于教师(甚至更优)。
结论:引入中间层提示(Hint-based Training),提出通用压缩框架:适用于多种架构(Maxout/ReLU)和任务(分类/检测)。
A BSTRACT
尽管增加网络深度通常能提升性能,但更深层的网络往往非线性更强,这使得基于梯度的训练变得更加困难。近期提出的知识蒸馏(knowledge distillation)方法旨在获得更小、执行更快的模型,其研究表明,学生网络可以模仿大型教师网络或集成网络的软输出(soft output)。本文中,我们扩展了这一思想:不仅使用教师网络的输出,还利用其学习到的中间表征(intermediate representations)作为提示(hints),从而训练出比教师网络更深更窄(deeper and thinner)的学生网络,以提升训练效果和最终性能。由于学生网络的中间隐藏层通常比教师网络的更小,我们引入了额外参数,将学生网络的隐藏层映射到教师网络隐藏层的预测结果上。这种方法可以训练出泛化能力更强或运行速度更快的深层学生网络——这一权衡取决于学生网络的容量选择。例如,在CIFAR-10数据集上,一个参数量减少近10.4倍的深层学生网络,其性能反而超越了更大的前沿教师网络。
1 INTRODUCTION
深度网络近年来在计算机视觉任务(如图像分类和目标检测)中展现出最先进的性能(Simonyan & Zisserman, 2014; Szegedy et al., 2014)。然而,顶级性能的系统通常需要非常宽且深的网络结构,包含大量参数。这类宽深模型一旦训练完成,其显著缺点是在推理阶段会消耗大量时间,因为它们需要进行海量的乘法运算。此外,庞大的参数量也使得模型对内存需求极高。因此,宽而深的顶级网络并不适合内存或时间受限的应用场景。文献中已有多种尝试通过模型压缩来减轻推理时的计算负担。Bucila等人(2006)提出训练一个神经网络来模仿复杂大型集成模型的输出,该方法利用集成模型标注未标记数据,并通过这些数据训练神经网络以复现集成模型的学习函数,从而获得相近的准确率。Ba和Caruana(2014)近期采用这一思想,将深而宽的网络压缩为更浅但更宽的网络,其中压缩模型通过深度网络(或深度网络集成)标注的数据来模仿复杂模型的功能。更近期的知识蒸馏(Knowledge Distillation, KD)(Hinton & Dean, 2014)作为一种模型压缩框架被提出,它通过师生范式简化深度网络的训练:学生网络根据教师网络输出的软化版本(softened output)进行惩罚性学习。该框架将深度网络集成(教师)压缩为深度相似的学生网络,训练时学生网络需同时预测教师输出和真实分类标签。此前所有关于卷积神经网络的研究均聚焦于将教师网络或网络集成压缩为宽度和深度相似的网络,或更浅更宽的网络,未能充分利用深度优势。深度是表征学习的核心要素,因为它促进特征复用,并在更高层形成更抽象、更鲁棒的表征(Bengio et al., 2013)。深度的重要性已通过(1)理论验证:对于某些函数族,深层表征的表达能力相较浅层呈指数级提升(Montufar et al., 2014);(2)实证验证:ImageNet竞赛的两大顶级模型分别使用了19层和22层的深度卷积网络(Simonyan & Zisserman, 2014; Szegedy et al., 2014)。然而,训练深度架构已被证明具有挑战性(Larochelle et al., 2007; Erhan et al., 2009),因其由连续非线性组成,导致高度非凸和非线性的函数。大量研究致力于缓解这一优化问题。一方面,预训练策略(无论无监督(Hinton et al., 2006; Bengio et al., 2007)还是有监督(Bengio et al., 2007))通过逐层贪婪训练初始化网络参数,使其落入潜在的优质吸引域。各层根据中间目标依次训练。类似地,半监督嵌入(Weston et al., 2008)通过指导中间层辅助极深网络的学习。Cho等人(2012)在纯无监督场景中,通过每隔一层借用另一模型的激活函数来简化DBM的优化问题。近期研究(Chen-Yu et al., 2014; Szegedy et al., 2014; Gulcehre & Bengio, 2013)表明,对深度架构的中间层添加监督有助于训练。具体方法是在中间隐藏层上叠加带softmax层的有监督MLP,以确保其相对于标签的判别性。另一种课程学习策略(Curriculum Learning, CL)(Bengio, 2009)通过调整训练数据分布,使网络逐步接收难度递增且与已学概念匹配的样本,从而优化训练。课程学习类似连续性方法,可加速收敛并找到高度非凸代价函数更优的局部极小值。本文中,我们旨在利用深度优势解决网络压缩问题,提出一种称为FitNets的新方法训练窄而深的网络,以压缩宽且较浅(但仍深)的网络。该方法基于知识蒸馏(KD)(Hinton & Dean, 2014)并扩展其思想,允许训练更窄更深的学生模型。我们引入教师网络隐藏层的中间级提示(hints)来指导学生训练过程,即要求学生网络(FitNet)学习能够预测教师网络中间表征的中间表征。提示机制使得训练更窄更深的网络成为可能。实验结果证实,更深的模型能提升泛化能力,而更窄的模型显著降低计算负担。我们在MNIST、CIFAR-10、CIFAR-100、SVHN和AFLW基准数据集上验证了该方法,证明其性能匹配或超越教师网络,同时显著减少参数量和乘法运算量。
2 METHOD
本节将详细阐述从更浅更宽的教师网络训练FitNets的师生框架。首先,我们回顾近期提出的知识蒸馏(KD)方法;其次,重点介绍用于全程指导FitNet训练的提示(hints)算法;最后,说明FitNet如何分阶段训练。
2.1 REVIEW OF KNOWLEDGE DISTILLATION
为获得更快的推理速度,我们探索了近期提出的压缩框架(Hinton & Dean, 2014),该框架通过更宽网络集成(教师网络)的软化输出训练学生网络。其核心思想是让学生网络不仅能学习真实标签提供的信息,还能捕捉教师网络习得的精细结构。该框架可概括如下:
设教师网络 T的输出为softmax概率 PT=softmax(aT),其中 aT为教师网络在某个样本上的预激活值(pre-softmax activations)。若教师模型为单一网络,aT表示输出层的加权和;若为集成模型,则 PT或 aT通过对不同网络输出的算术或几何平均获得。设学生网络 S的参数为 WS,输出概率 PS=softmax(aS),其中 aS为学生网络的预激活输出。训练学生网络使其输出 PS同时逼近教师输出 PT和真实标签 ytrue。由于 PT可能过于接近真实标签的one-hot编码,需引入松弛参数 τ>1 以软化教师输出信号,从而在训练中提供更多信息。此软化同样作用于学生输出(PτS)与教师软化输出(PτT)的对比:
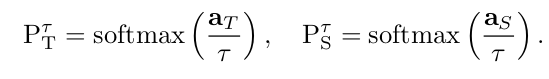
学生网络的训练目标为最小化以下损失函数:
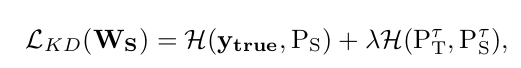
其中 H为交叉熵,λ为可调平衡参数。式(2)第一项为学生输出与真实标签的传统交叉熵,第二项强制学生网络学习教师软化输出。
据我们所知,原始KD设计仅适用于学生网络模仿相似深度的教师架构。尽管我们发现即使学生网络稍深于教师,KD框架仍能取得不错效果,但随着学生网络深度增加,KD训练仍受困于深度网络优化难题(见第4.1节)。
2.2 HINT-BASED TRAINING
为帮助训练比教师网络更深的FitNets,我们引入了教师网络的提示(hints)。提示定义为教师网络某一隐藏层的输出,用于指导学生网络的学习过程。相应地,我们选择FitNet的一个隐藏层(引导层,guided layer)来学习教师网络的提示层(hint layer),目标是使引导层能够预测提示层的输出。需注意的是,引入提示是一种正则化手段,因此提示层/引导层的配对需谨慎选择,以避免学生网络被过度正则化。引导层设置得越深,网络灵活性越低,FitNets越可能遭受过正则化问题。本文中,我们选择教师网络的中间层作为提示层,并同样选择学生网络的中间层作为引导层。由于教师网络通常比FitNet更宽,所选提示层的输出维度可能大于引导层。为此,我们在引导层后添加一个回归器(regressor),其输出尺寸与提示层匹配。接着,通过最小化以下损失函数,联合训练FitNet从第一层到引导层的参数以及回归器参数:
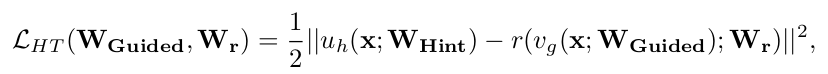
其中 uh和 vg分别为教师/学生网络至提示层/引导层的深度嵌套函数(参数为 WHint 和 WGuided),r 为引导层顶部的回归器函数(参数为 Wr)。需保证 uh和 r的输出可比,即二者需采用相同的非线性激活函数。
然而,若引导层和提示层为卷积层,使用全连接回归器将显著增加参数量和内存消耗。设教师提示层的空间尺寸和通道数分别为 Nh,1×Nh,2和 Oh,FitNet引导层的对应尺寸为 Ng,1×Ng,2和 Og。全连接回归器的参数量为 Nh,1×Nh,2×Oh×Ng,1×Ng,2×Og。为缓解此问题,我们改用卷积回归器。该回归器的设计使其感受野与教师提示层对输入图像的空间覆盖区域近似,从而回归器输出与教师提示层空间尺寸相同。给定教师提示层空间尺寸 Nh,1×Nh,2,回归器以FitNet引导层输出(尺寸 Ng,1×Ng,2)为输入,并通过调整卷积核尺寸 k1×k2满足 Ng,i−ki+1=Nh,i(i∈{1,2})。此时卷积回归器的参数量降至 k1×k2×Oh×Og,远低于全连接方案。
2.3 FITNET STAGE - WISE TRAINING
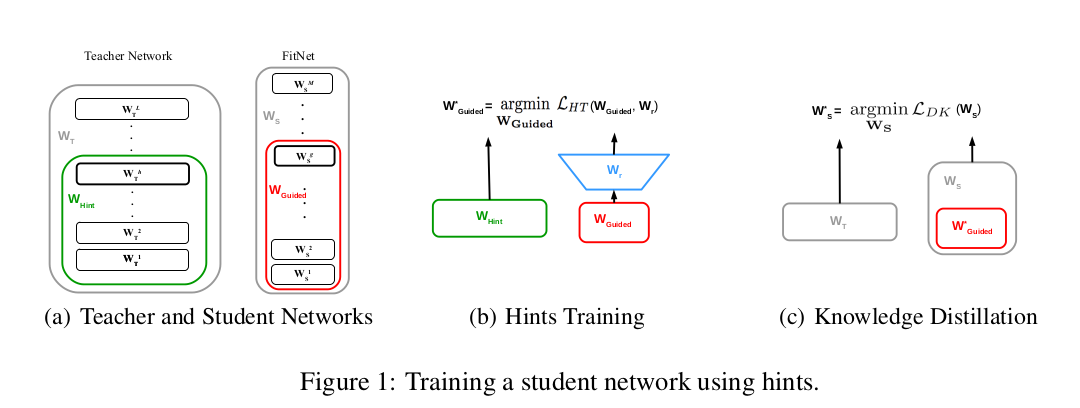
我们遵循师生范式分阶段训练FitNet。图1概括了训练流程:从一个已训练的教师网络和随机初始化的FitNet开始(图1(a)),首先在FitNet的引导层顶部添加参数为 Wr的回归器,并训练FitNet至引导层的参数 WGuided以最小化式(3)(图1(b));接着基于预训练参数,训练整个FitNet的参数 WS以最小化式(2)(图1(c))。算法1详细描述了FitNet的训练过程。
算法1 FitNet分阶段训练
输入:教师网络的已训练参数 WT、FitNet的随机初始化参数 WS,以及分别对应提示层和引导层的索引 h 和 g。设 WHint为教师网络至提示层 h的参数,WGuided 为FitNet至引导层 g的参数,Wr为回归器参数。第一阶段基于教师提示层的预测误差预训练学生网络至引导层(第4行);第二阶段对整个网络进行知识蒸馏训练(第6行)。
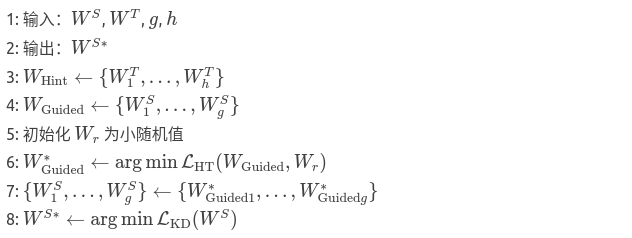
2.4 RELATION TO CURRICULUM LEARNING
本节中,我们认为基于提示的训练与知识蒸馏(KD)的结合可视为课程学习(Curriculum Learning, Bengio 2009)的一种特殊形式。课程学习通过为学习者设计从简单到复杂的训练样本序列,已被证明能加速收敛并提升模型泛化能力。其扩展工作(Gulcehre & Bengio, 2013)进一步表明,在训练中对中间层施加指导性提示可显著降低训练难度。然而,Bengio(2009)需依赖人工启发式规则衡量样本“简单性”,而Gulcehre & Bengio(2013)的提示需依赖对终端任务的先验知识,这些策略通常仅针对特定问题有效。
我们的方法通过引入教师模型解决了上述局限性。教师网络学习到的中间表征作为提示指导FitNet优化,同时教师置信度通过式(2)中的交叉熵项量化样本“简单性”——高置信度样本(教师输出概率分布远离均匀分布)对损失的贡献更大,而低置信度样本(输出接近均匀分布)对学生参数影响较弱。换言之,教师根据自身置信度对训练样本施加差异化惩罚。式(2)中的参数λ控制教师交叉熵的权重,进而调节各样本的重要性。为促进学习复杂样本(低教师置信度样本),我们在训练中线性衰减λ。整个课程可分为两阶段:首先通过提示层/引导层迁移学习中间概念,随后联合训练整个学生网络并衰减λ,使得教师高置信的简单样本初期主导训练,随λ减小逐渐降低其影响。因此,本文提出的基于提示的训练是一种通用课程学习方法,其任务先验信息完全从教师模型中自动推导。
3 RESULTS ON BENCHMARK DATASETS
本节将在多个基准数据集上展示实验结果,所有网络的架构及训练细节详见补充材料。
3.1 CIFAR-10 AND CIFAR-100
CIFAR-10与CIFAR-100数据集(Krizhevsky & Hinton, 2009)由32×32像素的RGB图像组成,分别包含10类和100类。两者均有5万训练图像和1万测试图像,其中CIFAR-10每类1000样本,CIFAR-100每类100样本。参照Goodfellow等(2013b),我们对数据进行了对比度归一化和ZCA白化处理。
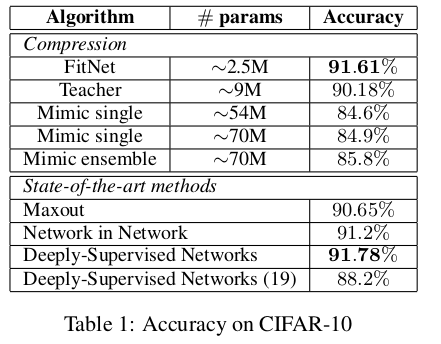
CIFAR-10实验:为验证方法,我们按Goodfellow等(2013b)训练了一个由maxout卷积层构成的教师网络,并设计了一个包含17层maxout卷积层、1层maxout全连接层和顶层softmax的FitNet,参数量约为教师1/3。学生网络第11层被训练以模仿教师第2层特征。与Goodfellow等(2013b)、Chen-Yu等(2014)一致,训练时采用随机翻转数据增强。表1结果显示:学生模型在显著减少参数量的同时性能超越教师模型,表明深度对提升表征能力至关重要;与模型压缩方法相比,学生网络准确率达91.61%,远超Ba & Caruana(2014)的85.8%(参数量减少28倍),且与当时最优方法持平。
关于中间层提示的选择,可能存在直接使用分类目标作为提示的替代方案。我们探索了四种方案:(1) 分阶段训练:第一阶段以分类目标优化网络前半部分,第二阶段优化整个网络。但第一阶段的参数初始化未能有效辅助第二阶段学习;
(2) 分阶段KD训练:第一阶段用分类目标,第二阶段用式(2)损失,同样因初始化不足导致失败;
(3) 联合优化:将引导层监督提示与输出层分类目标相加联合训练,但即使尝试不同初始化和RMSprop学习率仍无法收敛;
(4) 联合优化引导层监督提示与式(2)损失,添加分类目标提示仍无法训练此类窄深网络。
作为对比,我们采用深度监督网络(DSN)对每层添加提示联合训练,19层架构测试性能仅88.2%,显著低于FitNets的91.61%,表明中间层使用强判别性分类提示可能过于激进,而教师网络的平滑提示泛化性更优。
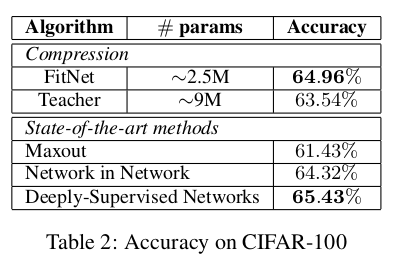
CIFAR-100实验:采用与CIFAR-10相同的教师网络和FitNet架构,训练时增加随机翻转增强。表2结果显示:FitNet性能超越教师模型且参数量减少3倍,与前沿方法相比接近最优水平。
3.2 SVHN
SVHN数据集(Netzer等,2011)由Google街景采集的32×32彩色门牌号图像组成,包含73,257张训练集图像、26,032张测试集图像及531,131张更简单的附加样本。我们遵循Goodfellow等(2013b)的评估流程,采用其maxout网络作为教师模型,并训练了一个由11层maxout卷积层、1层全连接层和softmax层构成的13层FitNet。
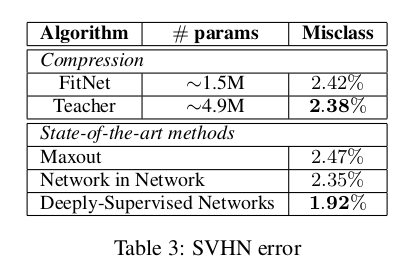
表3显示,尽管仅使用教师网络32%的参数量,我们的FitNet仍取得了与教师相当的准确率,且性能与Maxout和Network in Network等前沿方法持平。
3.3 MNIST
作为训练流程的验证,我们在MNIST数据集(LeCun等,1998)上评估了所提方法。MNIST包含28×28像素的手写数字(0-9)灰度图像,6万训练样本和1万测试样本。我们按照Goodfellow等(2013b)的方法训练了一个maxout卷积层教师网络,并设计了一个深度为教师2倍、参数量约8%的FitNet。学生网络第4层被训练以模仿教师第2层特征。
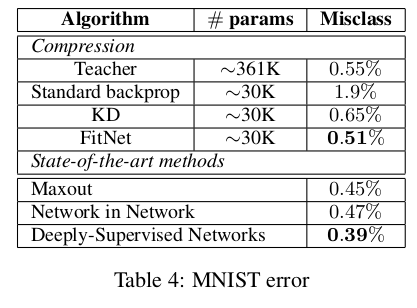
表4展示了实验结果:为验证提示机制的影响,我们分别采用(1)标准反向传播(基于分类标签)、(2)知识蒸馏(KD)和(3)基于提示的训练(HT)训练FitNet。当使用标准反向传播时,该窄深架构错误率为1.9%;使用KD后降至0.65%,证实了教师网络的有效性;而加入提示后错误率进一步降至0.51%。此外,学生网络性能略优于教师网络,同时参数量减少12倍。
3.4 AFLW
AFLW(Koestinger等,2011)是一个真实世界的人脸数据库,包含2.5万张标注图像。为在人脸识别场景中评估所提框架,我们将图像标注区域调整为16×16像素块作为正样本,并从ImageNet(Russakovsky等,2014)数据集中提取2.5万张不包含人脸的16×16像素块作为负样本,使用90%的样本训练网络。本实验旨在评估方法在不同架构上的适用性,因此我们训练了一个包含3层ReLU卷积层和sigmoid输出层的教师网络,并设计了两个FitNet:FitNet 1的计算量仅为教师的1/15,FitNet 2为教师的1/2.5,两者均含7层ReLU卷积和sigmoid输出层。教师网络在验证集上的错误率为4.21%。使用知识蒸馏(KD)训练FitNet 1时错误率为4.58%,而基于提示的训练(HT)将其降至2.55%;对于FitNet 2,KD错误率为1.95%,HT进一步降至1.85%。这些结果表明该方法可扩展至不同架构,且提示机制对窄架构尤其有效。
4 A NALYSIS OF EMPIRICAL RESULTS
我们通过比较使用不同训练方法的各种网络,来实证研究我们方法的优势。这些训练方法包括:标准反向传播(针对标签的交叉熵损失)、知识蒸馏(Knowledge Distillation, KD)以及基于提示的训练(Hint-based Training, HT)。实验在CIFAR-10数据集上进行(Krizhevsky & Hinton, 2009)。
我们在固定计算预算的情况下,比较了深度逐渐增加的网络。每个网络由连续的卷积层组成,卷积核大小为3×3,后接Maxout非线性激活函数和非重叠的2×2最大池化(max-pooling)。最后一个最大池化操作会在所有剩余的空间维度上取最大值,从而生成一个1×1的向量表示。我们在不同网络之间仅改变网络的深度和每层卷积的通道数,即为了满足固定的计算预算,随着网络深度的增加,每层卷积的通道数会相应减少。
4.1 ASSISTING THE TRAINING OF DEEP NETWORKS
在本节中,我们研究了基于提示的训练(HT)的影响。我们考虑了两种大约为30M和107M操作的计算预算,这些操作对应于图像前向传播所需的乘法次数。对于每种计算预算,我们分别训练由3、5、7和9层卷积层组成的网络,后接一个全连接层和一个Softmax层。我们比较了这些网络在使用标准反向传播、知识蒸馏(KD)和基于提示的训练(HT)时的性能。图2展示了在CIFAR-10数据集上的测试结果,其中我们在验证集上使用提前停止(early stopping),即我们不会在训练集加上验证集上重新训练模型。
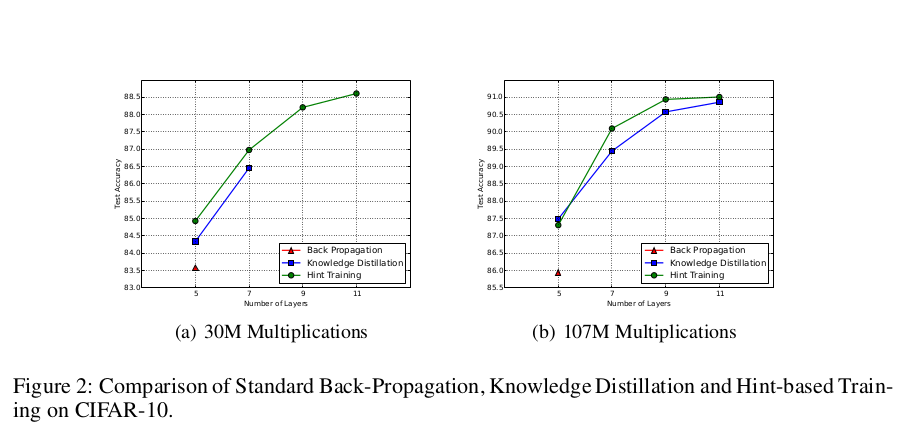
由于FitNets的深度较大且容量较小,它们很难训练。如图2(a)所示,使用标准反向传播,我们无法成功训练超过5层的30M乘法次数的网络。而使用知识蒸馏(KD),我们成功地训练了最多7层的网络。将KD中的教师交叉熵加入到训练目标函数中(公式(2))会更加关注容易的样本,即那些教师网络非常确信的样本,并可能导致训练成本的一个更平滑版本(Bengio, 2009)。尽管有一些优化上的好处,但值得注意的是,知识蒸馏训练仍然受到深度增加的限制,在7层网络时达到其极限。相比之下,基于提示的训练(HT)能够缓解这些优化问题,并成功训练了13层的30M乘法次数的网络。HT与KD之间的唯一区别在于参数空间的起始点:随机选择还是通过教师的提示获得。一方面,高度非线性函数(如非常深的网络)中局部极小值和鞍点的激增表明,在参数空间中随机找到一个好的起始点是困难的(Dauphin et al., 2014)。另一方面,图2(a)的结果表明,基于提示的训练(HT)可以引导学生网络到达参数空间中更好的初始位置,从而通过随机梯度下降来最小化代价函数。因此,从优化的角度来看,HT提供了显著的好处。此外,当固定容量和层数时,使用HT训练的网络往往比其他训练方法表现出更好的测试性能。例如,在图2(b)中,使用提示训练的7层网络相比未使用提示的模型,在测试集上获得了+0.7%的性能提升(准确率从89.45%提高到90.1%)。正如Erhan等人(2009)指出的那样,预训练策略可以充当正则化器。这些结果表明,HT是一个比KD更强的正则化器,因为它带来了更好的测试集泛化性能。最后,图2还强调了在固定计算预算下,更深的模型表现优于较浅的模型。事实上,考虑使用提示训练的网络,11层网络相比5层网络在107M乘法次数的情况下绝对提升了4.11%,在30M乘法次数的情况下绝对提升了3.4%。因此,实验验证了我们的假设:在固定计算量的情况下,我们可以通过增加模型的深度来实现更快的计算和更好的泛化性能。
总结来说,该实验表明:1、使用HT,我们能够训练比标准反向传播和KD更深的模型;2、在固定容量的情况下,更深的模型表现优于较浅的模型。
4.2 TRADE-OFF BETWEEN MODELP ERFORMANCE AND EFFICIENCY
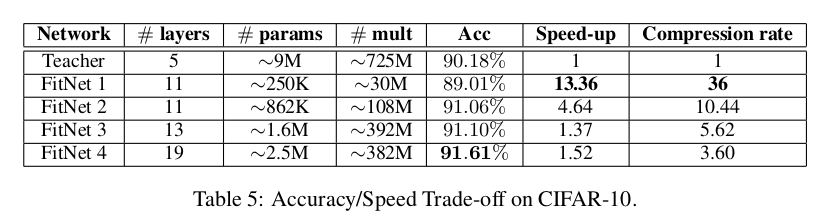
为了评估FitNets的效率,我们在GPU上测量了它们处理CIFAR-10测试样本所需的总推理时间以及参数压缩率。表5报告了各种FitNets相对于教师模型的速度提升和压缩率,同时列出了它们的层数、容量和准确率。在本实验中,我们按照Goodfellow等人(2013b)的方法,在训练集加上验证集上重新训练我们的FitNets,以确保与教师模型进行公平比较。
FitNet 1是我们最小的网络,其容量仅为教师模型的1/36,但它的速度比教师模型快了一个数量级,并且性能仅下降了1.3%。FitNet 2略微增加了容量,其性能比教师模型高出0.9%,同时仍然保持4.64倍的速度优势。通过进一步增加FitNet 3和FitNet 4的网络容量和深度,我们实现了高达1.6%的性能提升,同时仍然比教师模型更快。尽管压缩率引入了速度与准确率之间的权衡,FitNets依然显著更快,并且即使在低容量的情况下,也能达到或超过教师模型的性能。
一些研究工作(如矩阵分解方法,Jaderberg等人, 2014; Denton等人, 2014)专注于加速深度网络的卷积层,但会稍微降低性能。这些方法与FitNets是互补的,可以进一步加速FitNet的卷积层。
其他相关工作(如量化方案,Chen等人, 2010; Jégou等人, 2011; Gong等人, 2014)旨在减少存储需求。与FitNets不同,这些方法在压缩网络参数时通常会导致性能的小幅下降。而通过利用深度,FitNets能够在将参数数量减少10倍的情况下,仍然实现相对于教师模型的性能提升。然而,我们认为量化方法也是与FitNets互补的,可以进一步减少存储需求。比较教师网络滤波器与FitNet滤波器之间的冗余程度,以及FitNet滤波器在不显著降低性能的情况下能够被压缩到什么程度,将是一个有趣的研究方向。这一分析超出了本文的范围,留作未来的工作。
5 CONCLUSION
我们提出了一种新颖的框架,通过引入教师网络隐藏层的中间级提示(hints),来指导学生网络的训练过程,从而将宽而深的网络压缩为更薄但更深的网络。利用这些提示,我们可以训练出参数更少、非常深的学生模型,这些模型能够比教师模型更好地泛化和/或运行得更快。我们提供了实证证据,表明通过使用教师网络的隐藏状态对薄而深网络的内部层进行提示,其效果比仅用分类目标进行提示具有更好的泛化能力。我们在基准数据集上的实验进一步强调,低容量的深网络能够提取出与参数量多至10倍的网络相当甚至更好的特征表示。基于提示的训练方法表明,应该投入更多精力探索新的训练策略,以充分挖掘深度网络的潜力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)