论文精读:YOLOE: Real-Time Seeing Anything
YOLOE;源码链接。整体来说是YOLO-World一篇拓展,使其支持各种Prompt方式,但训练stage很多,这点可能训练会不方便,另外,对于实际应用来说:应该是个不错的部署工作。
文章目录
前言
本文介绍一篇来自清华的开放词汇检测论文:YOLOE;源码链接。

1、背景
本文在yolo-world基础上,拓展使其支持开方词汇检测、分割、以及visual prompt和prompt free来实现检测任务。笔者感觉其灵感来自DINO-X,后续我会单独写一篇博客来介绍,读者有兴趣可自行阅读。
2、方法
论文的行文思路是如何实现各种prompt检测的,如下图所示:左下角是visual prompt模块,右下角是重参Text模块、右上角部分是prompt free模块,即不指定prompt会尽可能检索词库里的物体。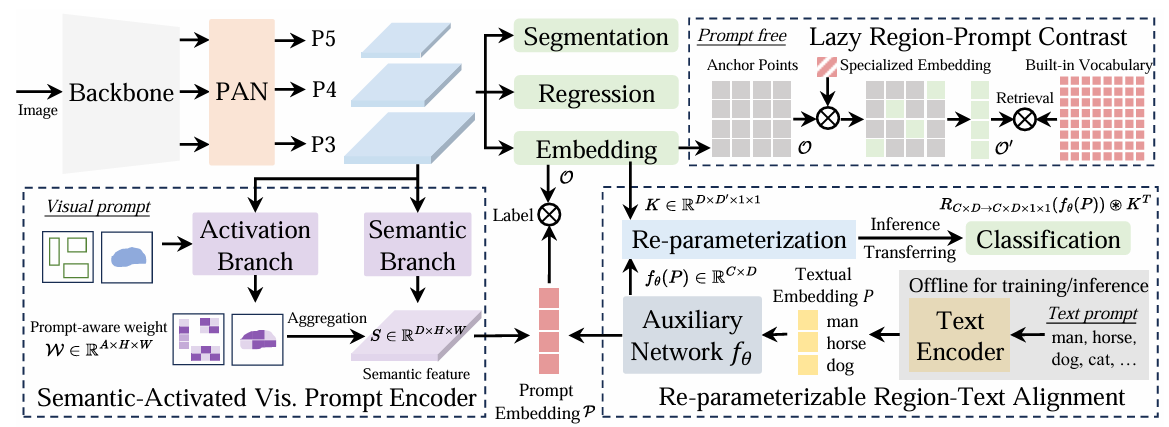
而图中其余部分:左上角部分其实就是yolo-world,其中Seg、Reg表示分割和检测头,而Embedding则是每个anchor包含的语义向量:比如维度是[8400,256],其中8400表示anchor个数,后续该Embedding即O跟各种prompt进行对比学习,来实现物体类别判断。
下面将分别介绍各个prompt模块是如何实现的。
2.1.重参Region-Text对齐模块

如上图所示,首先Text经过TextEncoder提取出特征嵌入向量P,然后经过 f θ f_\theta fθ 经过一次变换,得到Prompt Embedding。注意,上述部分在部署阶段是可以离线做的,即不影响模型性能,也就是Re-parameterization过程。 整体流程比较简单, f θ f_\theta fθ 则是如下图,选用了一个FFN:
2.2.VisualPrompt模块

这块就是如何将box或者mask等视觉prompt转化成PromptEmbedding,输入需要借助经过PAN模块的P3-P5特征层,子模块设计了一个激活分支和语义分支,其中S表示语义分支输出,W表示激活分支输出:
这里简单说下S和W是如何聚合的,作者采用类似分组卷积思想,将S分成A组,即下面公式中的G_i,通过下面公式将W的A那个维度给销掉了,从而得到PromptEmbedding,使其维度对齐其余的Prompt embedding。
2.3.PromptFree

该部分作者使用了一种LazyRegionPromptContrast方式:首先自己内建了一个词汇库特征向量,然后又额外创建一条可学习的Specialized Embedding,然后跟每个Anchor_Points的特征向量进行乘积,但考虑到检索复杂度太大,因此,在进行Retrieval前,进行了一步过滤:就是人为卡了个阈值 δ \delta δ 。
2.4.损失函数
分配策略采用simOTA ,损失就是二元交叉熵和定位以及Seg Loss。
3、实验
3.1.训练集
跟yolo-world一样O365+GQA,只不过用SAM得到mask来进行Seg分支训练。训练阶段比较复杂,分为好几个阶段,分别训练不同的prompt分支。(感觉这块不完美)。
3.2.实验结果
依旧看LVIS指标,看起来确实比YOLO-world效果明显。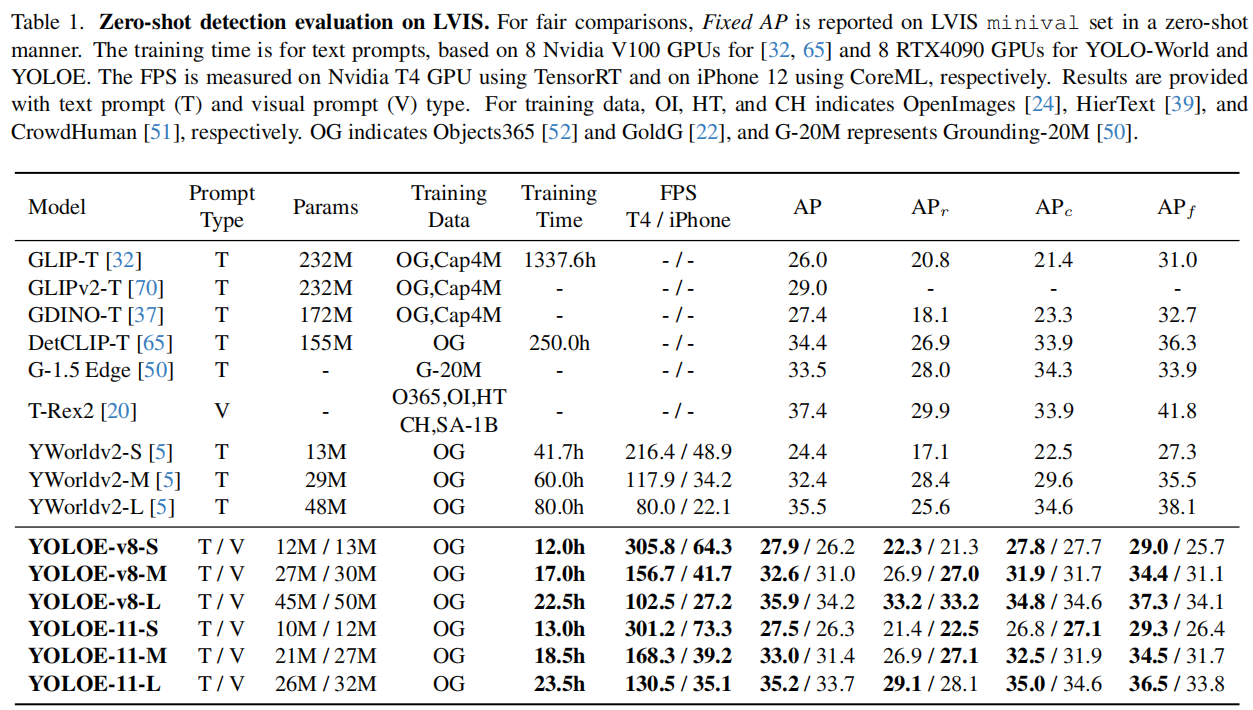
还有prompt free的前景物体召回实验结果:
总结
整体来说是YOLO-World一篇拓展,使其支持各种Prompt方式,但训练stage很多,这点可能训练会不方便,另外,对于实际应用来说:应该是个不错的部署工作。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 31
31 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)