Multi-scale Bottleneck Transformer for Weakly Supervised Multimodal Violence Detection
弱监督多模态暴力检测旨在通过利用多个模态(如RGB、光流和音频)来学习暴力检测模型,同时仅依赖视频级标注。在实现高效多模态暴力检测(MVD)的过程中,信息冗余、模态不平衡和模态异步被确认为三大关键挑战。针对这些挑战,本文提出了一种新的弱监督MVD方法。具体而言,我们引入了一个基于多尺度瓶颈变换器(MSBT)的融合模块,该模块通过减少瓶颈令牌的数量逐步浓缩信息并融合每对模态,同时利用基于瓶颈令牌的加

标题:多尺度瓶颈Transformer的弱监督多模态暴力检测
原文链接:https://arxiv.org/pdf/2405.05130
源码链接:https://github.com/shengyangsun/MSBT
发表:ICME-2024
Abstract
弱监督多模态暴力检测旨在通过利用多个模态(如RGB、光流和音频)来学习暴力检测模型,同时仅依赖视频级标注。在实现高效多模态暴力检测(MVD)的过程中,信息冗余、模态不平衡和模态异步被确认为三大关键挑战。针对这些挑战,本文提出了一种新的弱监督MVD方法。具体而言,我们引入了一个基于多尺度瓶颈变换器(MSBT)的融合模块,该模块通过减少瓶颈令牌的数量逐步浓缩信息并融合每对模态,同时利用基于瓶颈令牌的加权方案突出更重要的融合特征。此外,我们提出了一种时间一致性对比损失,以对每对融合特征进行语义对齐。在最大规模的XD-Violence数据集上的实验表明,所提方法达到了最新的性能水平。代码可访问https://github.com/shengyangsun/MSBT。
关键词:视频异常检测,多模态暴力检测,弱监督
I. INTRODUCTION
视频暴力检测旨在识别视频中的暴力事件。近年来,随着多模态数据(例如音视频数据集XD-Violence [1])的可用性不断提高,多模态暴力检测(MVD)[2],[3] 引起了越来越多的关注。为了实现高效的多模态暴力检测,我们识别出需要解决的三大关键挑战:
- 信息冗余:每种模态都包含冗余信息,这些冗余可能会引入不必要的语义偏差 [4]。
- 模态不平衡:一种模态中的信息量可能远远超过其他模态。如果对所有模态一视同仁,可能会导致检测性能下降 [5]。
- 模态异步:即使信号是同步的,不同模态之间可能仍然存在时间上的不一致。例如,在典型的“虐待”事件中,施暴者通常先打击受害者,随后才传出尖叫声 [2]。
现有的MVD方法主要关注音视频模态,尝试解决上述一个或多个挑战。例如,在文献 [6] 中,通过多种注意力机制关注最相关的信息,从而减少背景干扰和信息冗余问题。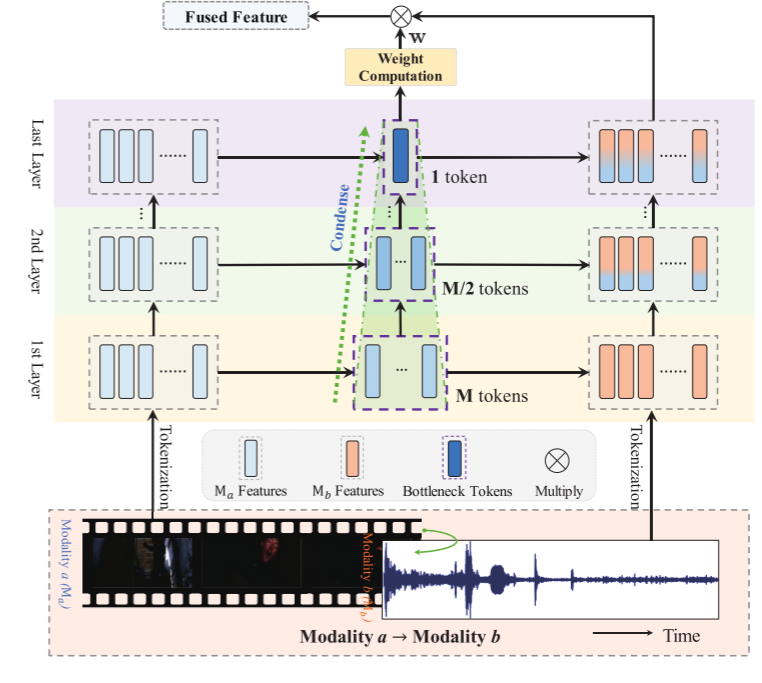
图1.我们的多模态融合模块的图示。它由一个多尺度瓶颈变压器和一个基于瓶颈令牌的加权方案组成。当输入一对模态时,瓶颈令牌首先压缩模态a的信息,然后在每层将其传输到模态b。此外,在一层凝聚的瓶颈令牌被传递到下一层进行进一步凝聚。最后一层的令牌可用于测量传输的信息量,因此可以用来对融合的特征进行加权。最好以彩色观看。
为了解决前两个挑战,我们提出了一个多模态融合模块,如图1所示。该模块包括一个基于多尺度瓶颈变换器(MSBT)的融合机制和一个基于瓶颈令牌的加权方案,用于融合每对模态。受到成功应用于音视频分类任务的瓶颈变换器 [4],[7] 启发,我们设计的MSBT使用少量瓶颈令牌在模态之间传递压缩信息。然而,与 [4],[7] 不同的是,我们引入了一种逐步压缩机制,通过在连续层中减少瓶颈令牌数量,逐步减少信息冗余。此外,考虑到最终层学习的瓶颈令牌也反映了模态之间传递的信息量,我们设计了基于瓶颈令牌的加权方案,用于对每对融合特征进行加权,避免对所有模态一视同仁。
为了解决第三个挑战,我们提出了一种时间一致性对比(TCC)损失,其设计基于以下观察:一方面,大多数音视频数据本质上是同步的,尽管其中一部分可能是异步的 [2];另一方面,即使存在模态异步,我们基于变换器的融合机制也能在时间维度上隐式对齐每对模态。因此,TCC损失旨在进一步对同一时刻的视频中所有模态的融合特征进行语义对齐,从而有效解决模态异步问题。
我们构建了一个完全基于变换器的网络架构,该架构集成了基于MSBT的融合模块,以及MIL损失和TCC损失,用于学习多模态暴力检测模型。我们的方法在以下几个方面具有独特性:
- 提出了一种基于多尺度瓶颈变换器(MSBT)的融合模块。它通过减少瓶颈令牌的数量逐步传递压缩信息,并利用基于瓶颈令牌的加权方案对融合特征进行加权,从而有效解决信息冗余和模态不平衡问题。
- 提出了一种时间一致性对比(TCC)损失,用于在视频的同一时刻语义对齐每对融合特征,有效应对模态异步问题。
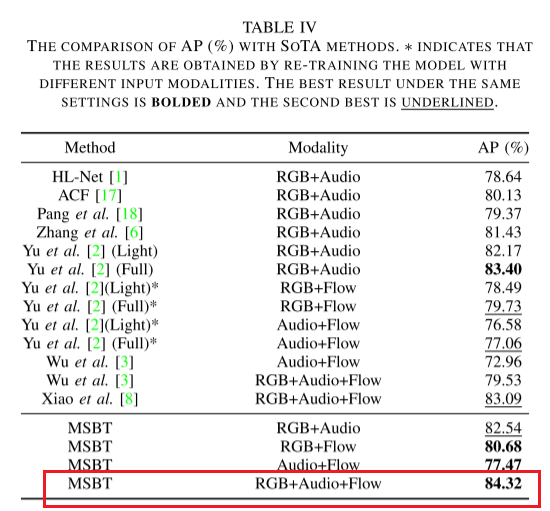
- 在XD-Violence上的实验结果表明,所提方法达到了最新的性能水平,特别是在同时考虑RGB、光流和音频模态时。此外,我们的方法可以扩展到任意数量的输入模态,具有潜在支持更多模态(例如深度或红外视频流)的能力。
II. RELATED WORKS
A. Weakly Supervised Multimodal Violence Detection
暴力检测与异常检测密切相关。近年来,多模态数据的可用性,特别是大规模多模态视频数据集 [1] 的发布,激发了人们对多模态暴力/异常检测的兴趣 [2], [3], [6], [8]。大量研究致力于音频和视觉模态的融合,发展了多种融合方法,如基于拼接 [1] 和交叉注意力 [2] 的技术。尽管这些工作中使用的注意力机制在一定程度上隐式解决了信息冗余问题,但专门设计用于应对信息冗余、模态不平衡和模态异步这三大挑战的研究相对较少,只有 [2] 处理了其中的一到两个挑战。
B. Multimodal Transformers
由于自注意力及其变体的内在特性,变换器能够以模态无关的方式工作,并可扩展到多个模态 [9], [10]。然而,尽管异构模态的表示在变换器中被统一,信息冗余和模态不平衡问题仍然在实现有效融合的过程中构成挑战。为了解决信息冗余问题,Nagrani 等人 [4] 提出了多模态瓶颈变换器(MBT),该方法利用少量瓶颈令牌进行模态交互。受到该方法的启发,我们提出了多尺度瓶颈变换器(MSBT)。不同于MBT使用固定数量的瓶颈令牌,我们的MSBT通过减少令牌数量实现更高效的信息压缩。此外,针对模态不平衡问题,我们利用学习到的令牌(这些令牌指示传递的信息内容)对融合特征进行加权。
C. Multimodal Contrastive Learning
对比学习已成功应用于在不同任务中实现模态语义对齐 [2], [10], [11]。例如,Shvetsova 等人 [10] 设计了一种组合对比损失,该损失考虑了输入模态的所有组合,包括单模态和模态对,用于多模态视频检索。Yu 等人 [2] 提出了一种模态感知的对比实例学习,通过音视频跨模态对比进行暴力检测。在本研究中,我们设计了一种时间一致性对比(TCC)损失,该损失将同一时刻的融合特征视为正样本,不同时刻的特征视为负样本。与这些工作不同的是,我们的损失仅考虑每对模态融合后的特征,而忽略单模态特征,以应对可能存在的模态异步问题。
III. METHODOLOGY
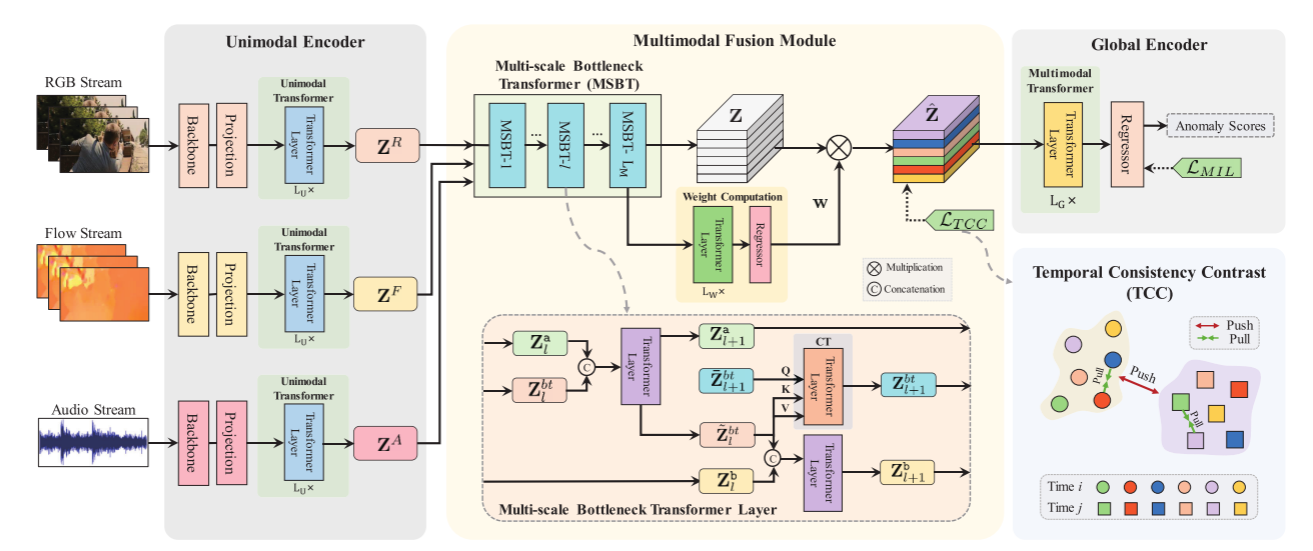
图2.拟议框架的概述。它包括三个单模态编码器、一个多模态融合模块和一个用于多模态特征生成的全局编码器。每个单模态编码器包括一个模态特定的特征提取骨干和一个用于标记化的线性投影层,以及一个模态共享的转换器,用于在一个模态内进行上下文聚合。融合模块包含一个多尺度瓶颈变压器(MSBT),用于融合任意对模态,子模块用于加权连接的融合特征。由转换器实现的全局编码器聚合了所有模式上的上下文。最后,将生成的多模态特征输入到回归器中以预测异常分数。整个网络由一个多实例学习(MIL)损失lml和一个时间一致性对比(TCC)损失LTCC来学习。最好以彩色观看。
本研究旨在解决弱监督暴力检测问题,处理一组未剪辑的视频,这些视频同时包含RGB、光流和音频流。为此,我们提出了一个多模态暴力检测框架,如图2所示。按照常见做法 [12],每个视频被划分为T个非重叠的片段。RGB、光流或音频片段通过单模态编码器进行处理,该编码器由一个预训练的特征提取骨干网络和一个线性投影层组成,用于生成模态特定的特征。随后,模态特定的特征被输入到一个融合模块中,该模块利用多尺度瓶颈变换器(MSBT)对所有模态对进行特征融合,并进一步将融合特征进行拼接和加权处理。最后,融合特征经过一个全局编码器以聚合上下文信息,然后输入到一个回归器中以预测异常分数。
A. Unimodal Encoder
我们首先构建了三个单模态编码器,用于为输入片段生成模态特定的特征。一个模态的输入片段通过一个预训练的特征提取骨干网络(例如,用于RGB或光流的I3D模型 [13],以及用于音频的VGGish模型 [14])进行标记化,随后通过一个线性投影层,输出一个嵌入特征向量 z ∈ R 1 × D E z \in \mathbb{R}^{1 \times D_E} z∈R1×DE,其中 D E D_E DE为所有模态统一的特征维度。接着,我们采用一个基础变换器 [15] 在每个模态内聚合上下文信息。即,嵌入特征被输入到一个具有 L U L_U LU 层的单模态变换器中,其中每一层由多头自注意力(MSA)和前馈网络(FFN)模块组成。第 l 层变换器的计算定义如下:
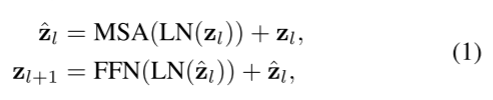
其中, LN ( ⋅ ) \text{LN}(\cdot) LN(⋅)表示层归一化(Layer Normalization)。MSA 和 FFN 的实现遵循之前的研究 [15]。需要注意的是,在单模态编码器中,特征提取器和线性投影层是模态特定的,而单模态变换器由所有模态共享。
B. Multimodal Fusion
我们将单模态编码器生成的视频模态特定特征分别表示为 Z R Z_R ZR, Z F Z_F ZF, 和 Z A Z_A ZA,对应 RGB、光流和音频模态。具体来说, Z a = [ z L U + 1 a ( 1 ) , … , z L U + 1 a ( T ) ] ∈ R T × D E Z_a = [z_{LU+1}^a(1), \dots, z_{LU+1}^a(T)] \in \mathbb{R}^{T \times D_E} Za=[zLU+1a(1),…,zLU+1a(T)]∈RT×DE,其中 a ∈ M = { R , F , A } a \in M = \{R, F, A\} a∈M={R,F,A}表示一种模态, T T T 是片段数量, z L U + 1 a z_{LU+1}^a zLU+1a 是单模态变换器的输出。随后,我们通过 MSBT 和基于瓶颈标记的加权方案实现多模态融合,具体如下。
Multi-scale Bottleneck Transformer.
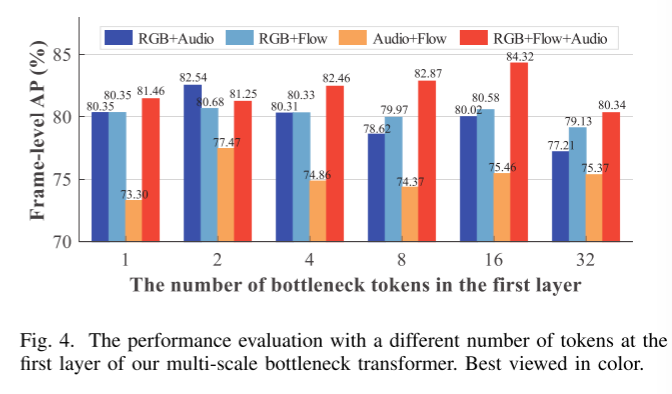
瓶颈变换器 [4], [7] 在多模态融合中展示了其高效性和有效性,其通过少量瓶颈标记来浓缩模态信息,从而显著减少信息冗余。受此启发,我们提出了多尺度瓶颈变换器(MSBT),它具有 L M L_M LM层,用于融合每两种模态的特征。多尺度策略在不同层次使用递减数量的瓶颈标记,以逐步浓缩信息,这不同于 [4], [7] 中对所有层使用固定数量标记的方法,从而实现了更高效的融合性能。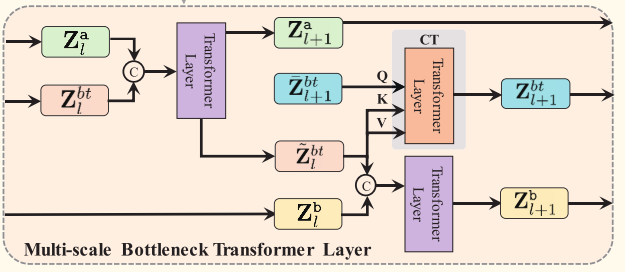
具体来说,给定来自两个不同模态 a , b ∈ M a, b \in M a,b∈M 的模态特定特征 Z a , Z b Z_a, Z_b Za,Zb,MSBT 在第 l 层通过以下方式将模态 a 的信息融合到模态 b :
其中, [ ⋅ ∣ ∣ ⋅ ] [ \cdot || \cdot ] [⋅∣∣⋅]表示拼接操作, Z b t l ∈ R N b t l × D E Z_{bt}^l \in \mathbb{R}^{N_{bt}^l \times D_E} Zbtl∈RNbtl×DE ( N b t l ≪ T ( N_{bt}^l \ll T (Nbtl≪T) 是输入第 l 层的瓶颈标记,由上一层学习得到 ( Z b t 1 ( Z_{bt}^1 (Zbt1 是随机初始化的),用于携带模态 a 的已浓缩信息。在当前层,这些标记首先通过公式 (2) 重新聚合模态 a 的信息,然后通过公式 (3) 将信息传递到模态 b ,从而得到融合结果 Z b l + 1 Z_b^{l+1} Zbl+1。
此外,我们的 MSBT 中的瓶颈标记还用于将模态 a 的浓缩信息从当前层传递到下一层。为此,我们在第 l 层额外初始化了一组新的瓶颈标记 Z ˉ b t l + 1 ∈ R N b t l + 1 × D E \bar{Z}_{bt}^{l+1} \in \mathbb{R}^{N_{bt}^{l+1} \times D_E} Zˉbtl+1∈RNbtl+1×DE。标记数量减半,即 N b t l + 1 = ⌊ N b t l / 2 ⌋ N_{bt}^{l+1} = \lfloor N_{bt}^l / 2 \rfloor Nbtl+1=⌊Nbtl/2⌋,以存储更为浓缩的信息。通过基于交叉注意力的变换器实现信息的层间传递: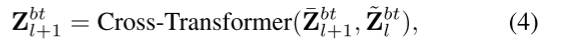
其中,交叉变换器 Cross-Transformer ( x , y ) \text{Cross-Transformer}(x, y) Cross-Transformer(x,y)通过注意力机制计算 Attention ( x W Q , y W K , y W V ) \text{Attention}(xW_Q, yW_K, yW_V) Attention(xWQ,yWK,yWV)。配对融合过程如图1和图2所示。在将模态特定特征 Z a Z_a Za融合到 Z b Z_b Zb 时,我们将 Z b L M + 1 Z_b^{L_M+1} ZbLM+1 作为融合结果,并记为 Z a b Z_{ab} Zab。本质上,这种融合方法将模态 a 的浓缩信息传递到模态 b ,表明两种模态的融合是非对称的。因此,在融合所有模态对后,我们得到六个融合特征: Z R F , Z F R , Z R A , Z A R , Z F A , Z A F Z_{RF}, Z_{FR}, Z_{RA}, Z_{AR}, Z_{FA}, Z_{AF} ZRF,ZFR,ZRA,ZAR,ZFA,ZAF。
Bottleneck Token-based Weighting.
一种直接获取所有模态融合特征的方法是将所有模态对的融合特征拼接起来: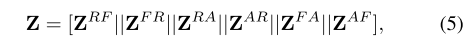
其中 Z ∈ R T × ( N F ⋅ D E ) Z \in \mathbb{R}^{T \times (N_F \cdot D_E)} Z∈RT×(NF⋅DE), N F N_F NF是模态对的数量。然而,我们发现最终层学习到的瓶颈标记(即 Z ~ b t L M \tilde{Z}_{bt}^{L_M} Z~btLM)可用于测量从一个模态传递到另一个模态的信息量。因此,我们提出利用学习到的瓶颈标记对所有模态对的融合特征加权,突出更重要的特征。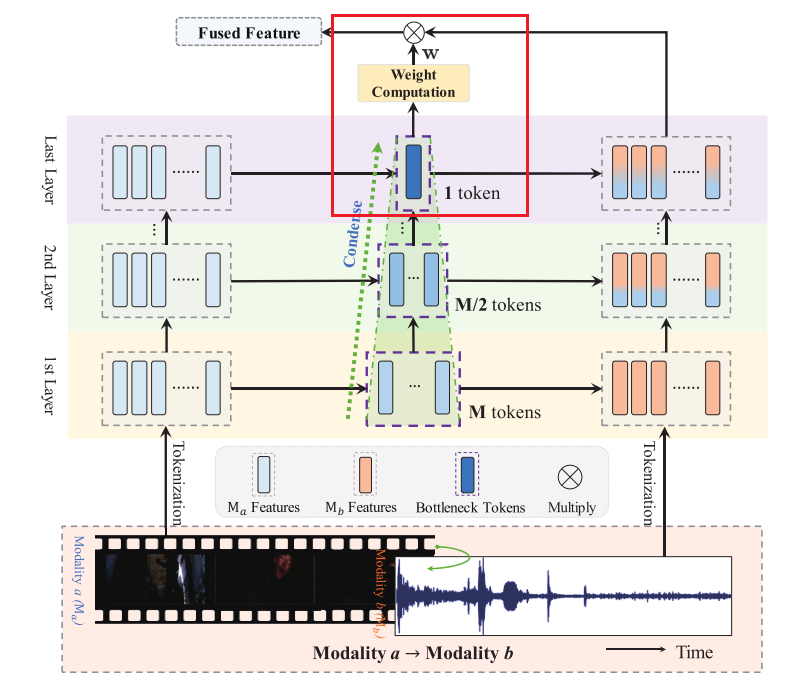
权重通过将标记输入到一个 L W L_W LW 层变换器和一个回归器中得到: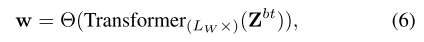
其中, Z b t Z_{bt} Zbt 是所有配对融合得到的最终瓶颈标记的堆叠, Transformer ( L W × ) ( ⋅ \text{Transformer}(L_W\times)(\cdot Transformer(LW×)(⋅表示一个 L W L_W LW 层变换器, Θ ( ⋅ ) \Theta(\cdot) Θ(⋅)是一个三层多层感知机(MLP)实现的回归器, w = [ w 1 , … , w N F ] ∈ R 1 × N F w = [w_1, \dots, w_{N_F}] \in \mathbb{R}^{1 \times N_F} w=[w1,…,wNF]∈R1×NF。最终的加权特征为: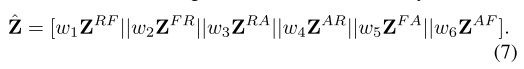
C. Temporal Consistency Contrast
虽然部分音视频数据可能是异步的 [2],但大多数数据在本质上是同步的。此外,当模态异步性存在时,我们的 MSBT 中基于自注意力的融合方案能够隐式地对齐两个模态。因此,我们期望同一时刻的成对融合特征在语义上是相似的。为实现这一目标,我们提出了时间一致性对比(TCC)损失,该损失将同一时刻的所有融合特征吸引在一起,并将其与不同时间的特征区分开来。当给定一个视频时,该损失的形式化定义为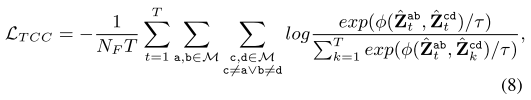

其中 ϕ ( ⋅ , ⋅ ) \phi(\cdot, \cdot) ϕ(⋅,⋅) 计算余弦相似度, τ \tau τ是一个温度超参数, Z ^ \hat{Z} Z^ 的下标 t t t 或 k k k 表示对应的片段。
D. Network Training
在弱监督设置下,训练集中的每个视频都标注有一个二进制标签 y ∈ { 0 , 1 } y \in \{0, 1\} y∈{0,1},表示该视频是否为暴力视频。当生成了一个视频所有片段的融合特征后,我们采用一个全局编码器,该编码器通过一个 LG 层的 Transformer 来建模所有模态的全局上下文,并进一步使用回归器来产生异常得分。即,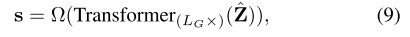
其中 s ∈ R T s \in \mathbb{R}^T s∈RT为视频中所有片段的异常得分, Ω ( ⋅ ) \Omega(\cdot) Ω(⋅)是一个通过三层多层感知机(MLP)实现的回归器。然后,我们采用广泛使用的 Top-K 多实例学习(MIL)损失 [2], [16] 来训练回归器,并使用时间一致性对比损失(TCC)进行特征正则化。
为了计算一个视频的 MIL 损失,我们对 Top-K 异常得分取平均值,即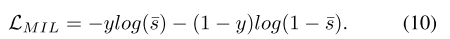
其中 T K ( s ) T_K(s) TK(s) 表示得分集合 s 中的 Top-K 最大值集合。然后,MIL 损失定义为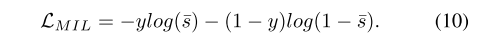
整个训练损失是 Top-K MIL 损失 L M I L L_{MIL} LMIL 和时间一致性对比损失 L T C C L_{TCC} LTCC 的组合: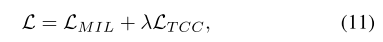
其中 λ \lambda λ是平衡两个项的超参数。
IV. EXPERIMENTS
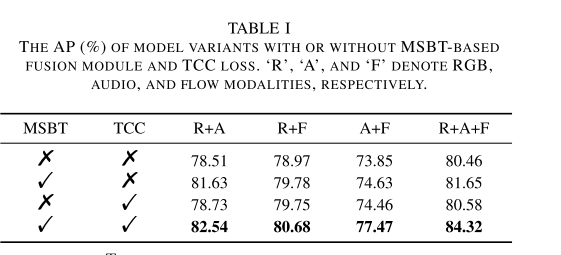
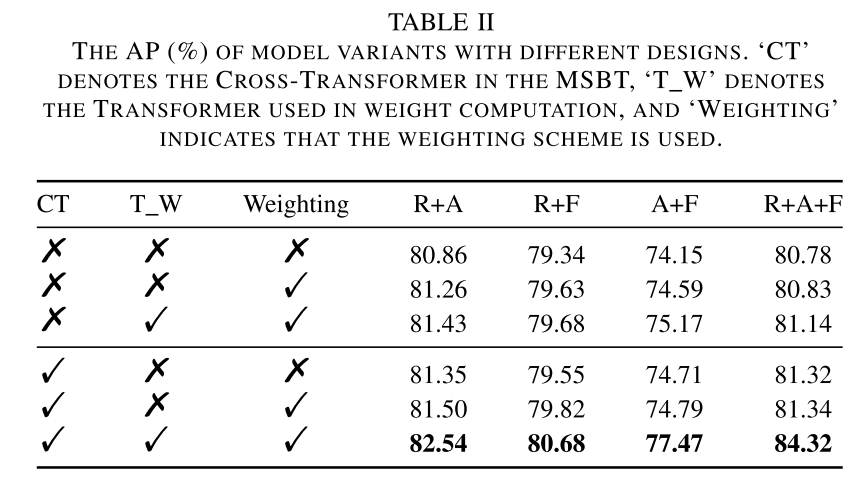


V. CONCLUSION
在这项工作中,我们提出了一种新的多模态暴力检测方法。该方法构建了一个完全基于 Transformer 的网络架构,并采用基于 MIL 的框架进行弱监督学习。此外,我们设计了一种基于多尺度瓶颈 Transformer(MSBT)的融合方法,有效地融合了多种模态,并提出了时间一致性对比(TCC)损失,以更好地学习具有辨别性的特征。我们在 XD-Violence 数据集上的实验验证了所提方法的有效性。实验结果表明,所提方法在考虑三种模态时,能够达到最先进的性能。此外,我们的方法也具有可扩展性,可以适应任意数量的输入模态,未来有可能加入更多模态,如深度图像或红外视频流等。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 30
30 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)