关于attention中num_head 多头的小思考
在transformer中我们需要将自注意力q,k,v进行注意力attention计算,但有时候,我们用一个行向量表示一个样本的时候,发现行向量太长了,这样整体的计算匹配机制比较差,为了提高注意力匹配率,我们引入了多头注意力。
·
文章目录
1. 多头注意力
在transformer中我们需要将自注意力q,k,v进行注意力attention计算,但有时候,我们用一个行向量表示一个样本的时候,发现行向量太长了,这样整体的计算匹配机制比较差,为了提高注意力匹配率,我们引入了多头注意力。
- excel 描述,假设我们需要对一个矩阵进行num_heads=3,其多头数为3,那么其实本质上就是将特征维度上进行分割,把一个长的行向量样本切割为num_heads=3份进行分割。具体如下:
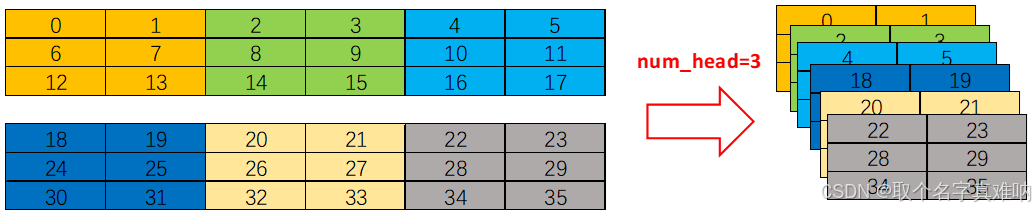
2. pytorch 源码
- pytorch
import torch
import torch.nn as nn
import torch.nn.functional as F
torch.set_printoptions(precision=3, sci_mode=False)
if __name__ == "__main__":
run_code = 0
bs = 2
seq_len = 3
model_dim = 6
matrix_total = bs * seq_len * model_dim
a_matrix = torch.arange(matrix_total).reshape((bs, seq_len, model_dim)).to(torch.float32)
print(f"a_matrix.shape=\n{a_matrix.shape}")
print(f"a_matrix=\n{a_matrix}")
num_head = 3
head_dim = model_dim // num_head
b_matrix = a_matrix.reshape((bs, seq_len, num_head, head_dim))
print(f"b_matrix.shape=\n{b_matrix.shape}")
print(f"b_matrix=\n{b_matrix}")
c_matrix = b_matrix.transpose(1,2)
print(f"c_matrix.shape=\n{c_matrix.shape}")
print(f"c_matrix=\n{c_matrix}")
d_matrix = c_matrix.reshape(bs*num_head,seq_len,head_dim)
print(f"d_matrix.shape=\n{d_matrix.shape}")
print(f"d_matrix=\n{d_matrix}")
- result
a_matrix.shape=
torch.Size([2, 3, 6])
a_matrix=
tensor([[[ 0., 1., 2., 3., 4., 5.],
[ 6., 7., 8., 9., 10., 11.],
[12., 13., 14., 15., 16., 17.]],
[[18., 19., 20., 21., 22., 23.],
[24., 25., 26., 27., 28., 29.],
[30., 31., 32., 33., 34., 35.]]])
b_matrix.shape=
torch.Size([2, 3, 3, 2])
b_matrix=
tensor([[[[ 0., 1.],
[ 2., 3.],
[ 4., 5.]],
[[ 6., 7.],
[ 8., 9.],
[10., 11.]],
[[12., 13.],
[14., 15.],
[16., 17.]]],
[[[18., 19.],
[20., 21.],
[22., 23.]],
[[24., 25.],
[26., 27.],
[28., 29.]],
[[30., 31.],
[32., 33.],
[34., 35.]]]])
c_matrix.shape=
torch.Size([2, 3, 3, 2])
c_matrix=
tensor([[[[ 0., 1.],
[ 6., 7.],
[12., 13.]],
[[ 2., 3.],
[ 8., 9.],
[14., 15.]],
[[ 4., 5.],
[10., 11.],
[16., 17.]]],
[[[18., 19.],
[24., 25.],
[30., 31.]],
[[20., 21.],
[26., 27.],
[32., 33.]],
[[22., 23.],
[28., 29.],
[34., 35.]]]])
d_matrix.shape=
torch.Size([6, 3, 2])
d_matrix=
tensor([[[ 0., 1.],
[ 6., 7.],
[12., 13.]],
[[ 2., 3.],
[ 8., 9.],
[14., 15.]],
[[ 4., 5.],
[10., 11.],
[16., 17.]],
[[18., 19.],
[24., 25.],
[30., 31.]],
[[20., 21.],
[26., 27.],
[32., 33.]],
[[22., 23.],
[28., 29.],
[34., 35.]]])

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)