常见的优化器(Optimizer)原理
记录下常见的优化算法。一、概述优化算法是训练过程中寻求最优解的方法,分类如下:性能对比如下:二、梯度下降法2.1 梯度下降(GD)梯度下降是通过 Loss 对的一阶导数来找下降方向,并且以迭代的方式来更新参数,更新方式为 :其中,为学习率。2.2随机梯度下降(SGD)随机梯度下降法(Stochastic Gradient Descent,SGD):均匀地、随机选取其中一个样本,用它代表整体样本,即
目录
记录下常见的优化算法。
重点是这篇paper:https://arxiv.org/pdf/1609.04747.pdf
一、概述
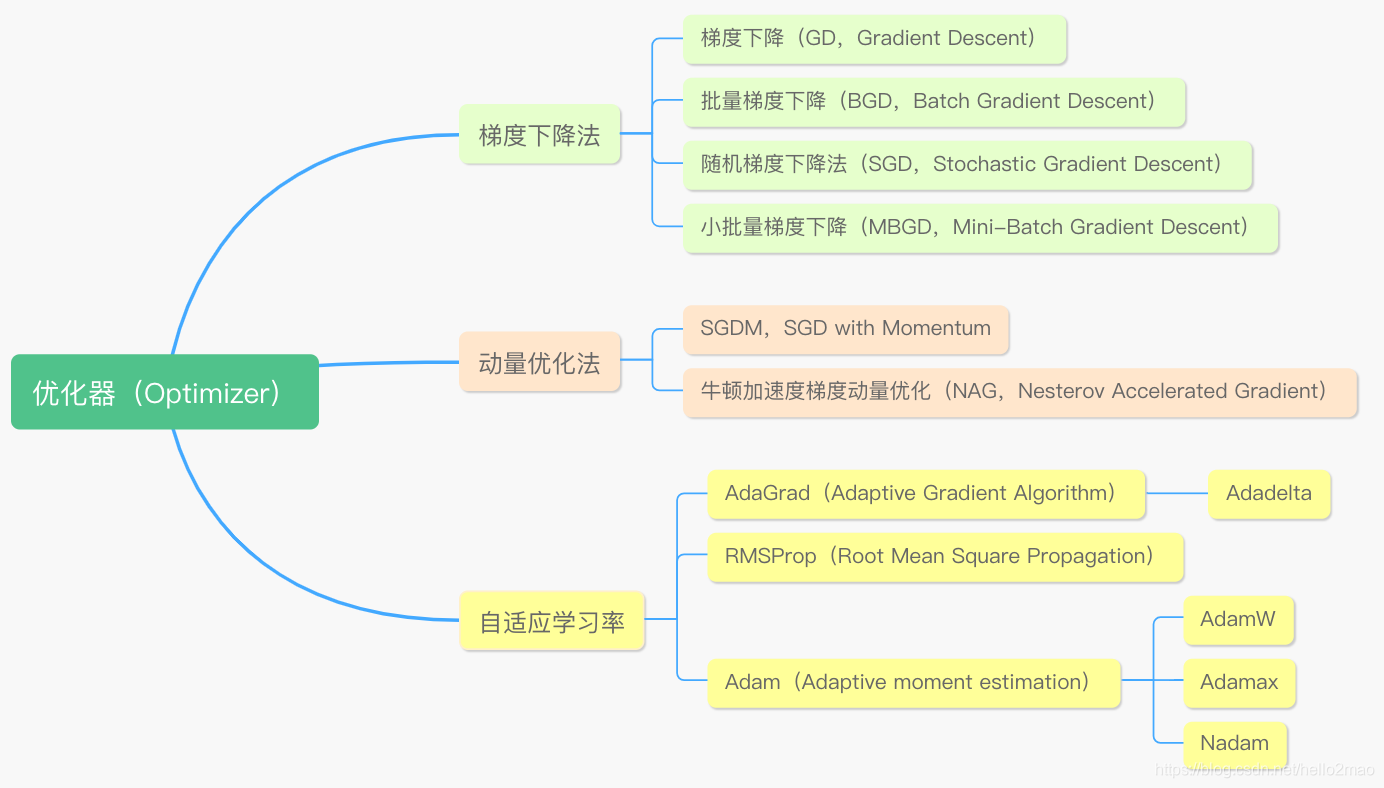
优化算法是训练过程中寻求最优解的方法,分类如下:
二、梯度下降法
2.1 梯度下降(GD)
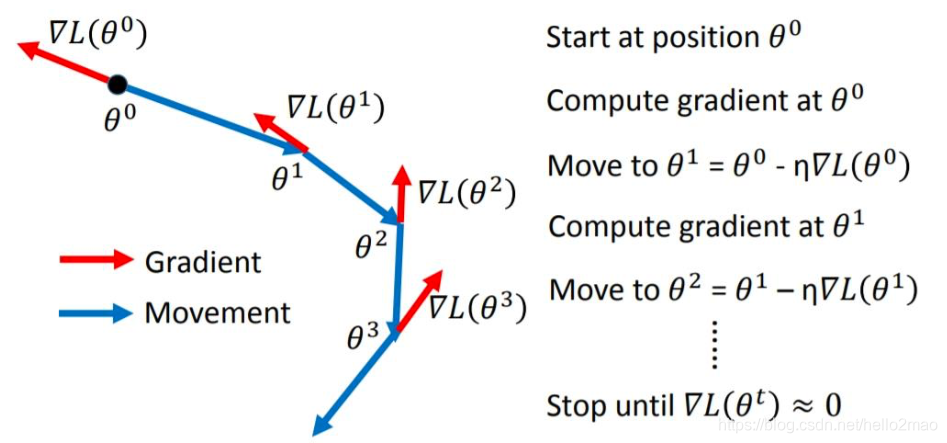
梯度下降是通过 Loss 对的一阶导数来找下降方向,并且以迭代的方式来更新参数,更新方式为 :
其中,为学习率。
2.2 随机梯度下降(SGD)
随机梯度下降法(Stochastic Gradient Descent,SGD):均匀地、随机选取其中一个样本,用它代表整体样本,即把它的值乘以N,就相当于获得了梯度的无偏估计值。
SGD的更新公式为:
2.3 小批量梯度下降法(MBGD)
每次迭代使用m个样本来对参数进行更新,MBGD的更新公式为:
2.4 优缺点
优点:
- 简单;
缺点:
- 训练速度慢;
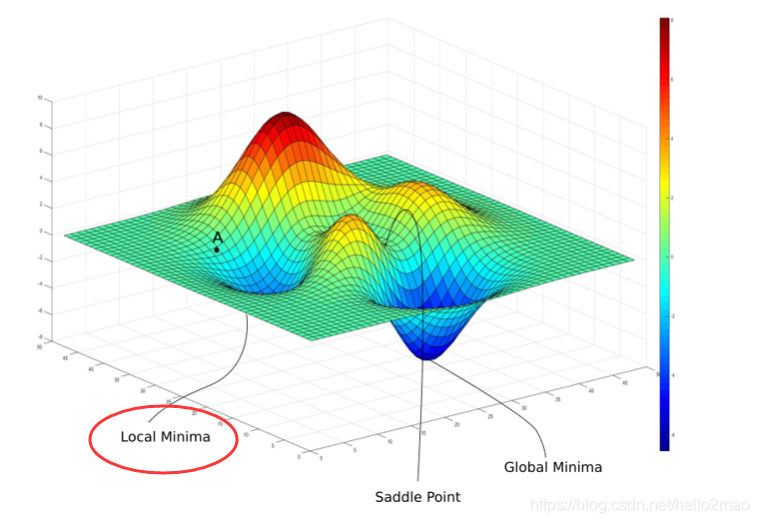
- 会进入Local Minima或者Saddle Point导致gradient为0;
三、动量优化法
3.1 SGD+Momentum
使当前训练数据的梯度受到之前训练数据的梯度的影响,即增加一个动量。
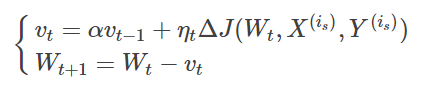
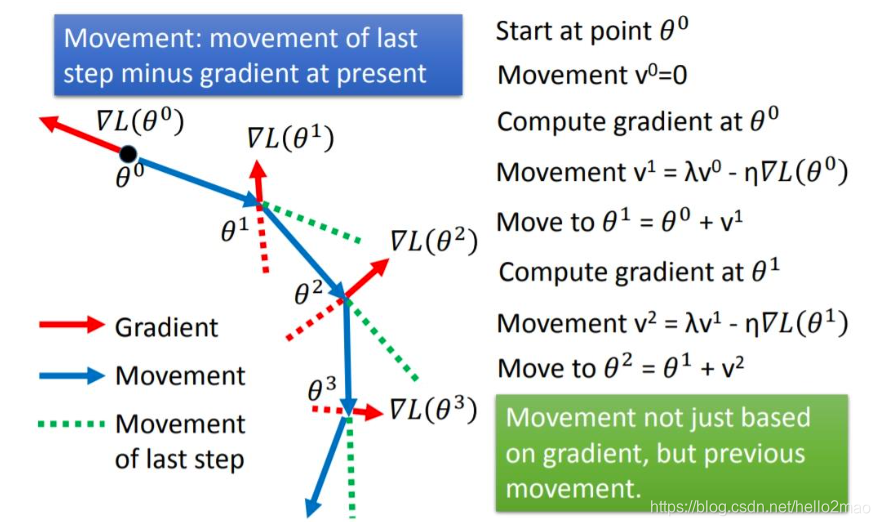
3.2 NAG
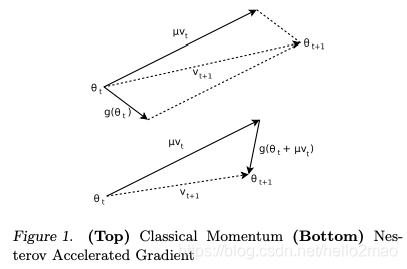
牛顿加速梯度动量优化方法(NAG, Nesterov accelerated gradient):拿着上一步的速度先走一小步,再看当前的梯度然后再走一步。
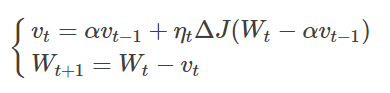
SGDM对比NAG如下:
四、自适应学习率
4.1 AdaGrad
AdaGrad算法通过记录历史梯度,能够随着训练过程自动减小学习率。
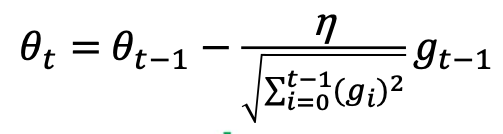
4.2 RMSProp
RMSProp简单修改了Adagrad方法,它做了一个梯度平方的滑动平均。
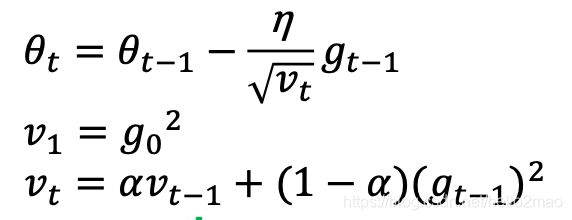
4.3 Adam
Adam看起来像是RMSProp的Momentum版。
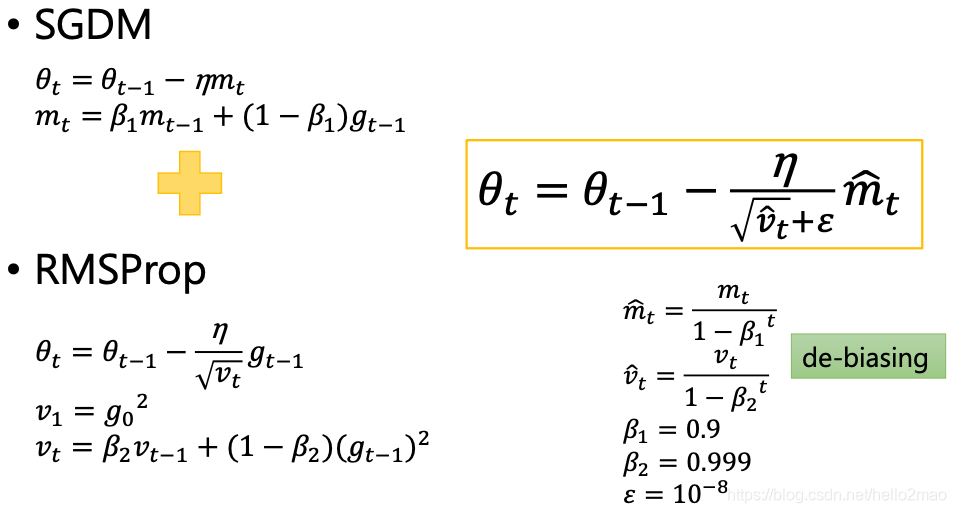
即:
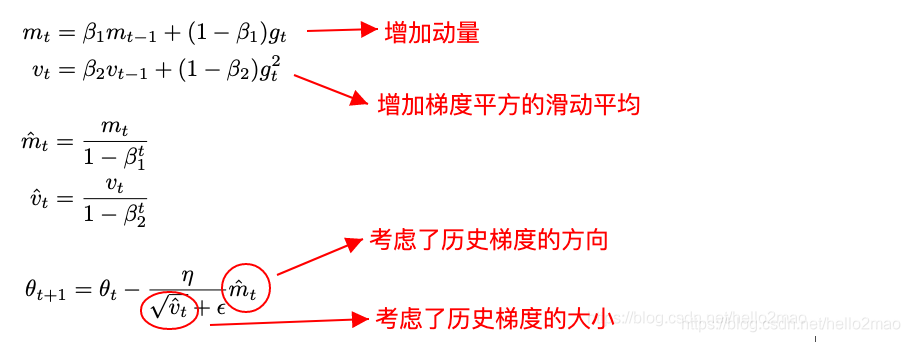
五、性能比较
用一份数据配合pytorch简单测试比较下几个优化器:
代码和数据见:https://github.com/hello2mao/Learn-MachineLearning/tree/master/DeepLearning/OptimizerTest
# PyTorch
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
# For plotting
import matplotlib.pyplot as plt
# For data preprocess
import numpy as np
import pandas as pd
import csv
class MyDataset(Dataset):
''' Dataset for loading and preprocessing the dataset '''
def __init__(self,
path,
mode='train'):
self.mode = mode
# Read data into numpy arrays
with open(path, 'r') as fp:
data = list(csv.reader(fp))
data = np.array(data[1:])[:, 1:].astype(float)
feats = list(range(93))
if mode == 'test':
# Testing data
# data: 893 x 93 (40 states + day 1 (18) + day 2 (18) + day 3 (17))
data = data[:, feats]
self.data = torch.FloatTensor(data)
else:
# Training data (train/dev sets)
# data: 2700 x 94 (40 states + day 1 (18) + day 2 (18) + day 3 (18))
target = data[:, -1]
data = data[:, feats]
# Splitting training data into train & dev sets
if mode == 'train':
indices = [i for i in range(len(data)) if i % 10 != 0]
elif mode == 'dev':
indices = [i for i in range(len(data)) if i % 10 == 0]
# Convert data into PyTorch tensors
self.data = torch.FloatTensor(data[indices])
self.target = torch.FloatTensor(target[indices])
# Normalize features
self.data[:, 40:] = \
(self.data[:, 40:] - self.data[:, 40:].mean(dim=0, keepdim=True)) \
/ self.data[:, 40:].std(dim=0, keepdim=True)
self.dim = self.data.shape[1]
print('Finished reading the {} set of Dataset ({} samples found, each dim = {})'
.format(mode, len(self.data), self.dim))
def __getitem__(self, index):
# Returns one sample at a time
if self.mode in ['train', 'dev']:
# For training
return self.data[index], self.target[index]
else:
# For testing (no target)
return self.data[index]
def __len__(self):
# Returns the size of the dataset
return len(self.data)
class Net(nn.Module):
''' A simple deep neural network '''
def __init__(self, input_dim):
super(Net, self).__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, 64),
nn.ReLU(),
nn.Linear(64, 1)
)
def forward(self, x):
''' Given input of size (batch_size x input_dim), compute output of the network '''
return self.net(x).squeeze(1)
def get_device():
''' Get device (if GPU is available, use GPU) '''
return 'cuda' if torch.cuda.is_available() else 'cpu'
def prep_dataloader(path, mode, batch_size, n_jobs=0):
''' Generates a dataset, then is put into a dataloader. '''
dataset = MyDataset(path, mode=mode) # Construct dataset
dataloader = DataLoader(
dataset, batch_size,
shuffle=(mode == 'train'), drop_last=False,
num_workers=n_jobs, pin_memory=True) # Construct dataloader
return dataloader
myseed = 42069 # set a random seed for reproducibility
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
np.random.seed(myseed)
torch.manual_seed(myseed)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(myseed)
# get the current available device ('cpu' or 'cuda')
device = get_device()
tr_path = 'covid.train.csv'
batch_size = 270
data_tr = pd.read_csv(tr_path)
tr_set = prep_dataloader(tr_path, 'train', batch_size)
# nets
net_SGD = Net(tr_set.dataset.dim).to(device)
net_Momentum = Net(tr_set.dataset.dim).to(device)
net_RMSprop = Net(tr_set.dataset.dim).to(device)
net_Adam = Net(tr_set.dataset.dim).to(device)
nets = [net_SGD, net_Momentum, net_RMSprop, net_Adam]
# optimizers
learning_rate = 0.001
opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=learning_rate)
opt_Momentum = torch.optim.SGD(
net_Momentum.parameters(), lr=learning_rate, momentum=0.8, nesterov=True)
opt_RMSprop = torch.optim.RMSprop(
net_RMSprop.parameters(), lr=learning_rate, alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(),
lr=learning_rate, betas=(0.9, 0.99))
optimizers = [opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam]
n_epochs = 3000
loss_func = nn.MSELoss(reduction='mean')
loss_histories = [[], [], [], []]
for epoch in range(n_epochs):
# iterate through the dataloader
for step, (x, y) in enumerate(tr_set):
for net, optimizer, loss_history in zip(nets, optimizers, loss_histories):
optimizer.zero_grad() # set gradient to zero
# move data to device (cpu/cuda)
x, y = x.to(device), y.to(device)
# forward pass (compute output)
y_hat = net(x)
loss = loss_func(y_hat, y) # compute loss
loss.backward() # compute gradient (backpropagation)
optimizer.step() # update model with optimizer
loss_history.append(loss.data.numpy())
if step % 50 == 0 and epoch % 50 == 0:
print(
'epoch: {:4d}, SGD: {:.4f}, Momentum: {:.4f}, RMSprop: {:.4f}, Adam: {:.4f}'.format(epoch, loss_histories[0][-1],
loss_histories[1][-1],
loss_histories[2][-1],
loss_histories[3][-1]))
print('Finished training after {} epochs'.format(epoch))
labels = ['SGD', 'Momentum', 'RMSprop', 'Adam', ]
for i, loss_history in enumerate(loss_histories):
plt.plot(loss_history, label=labels[i])
plt.legend(loc='best')
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.ylim((0, 6.0))
plt.xlim((0, len(tr_set.dataset)))
print('epoch: {}/{},steps:{}/{}'.format(epoch+1,
n_epochs, step*batch_size, len(tr_set.dataset)))
plt.show()
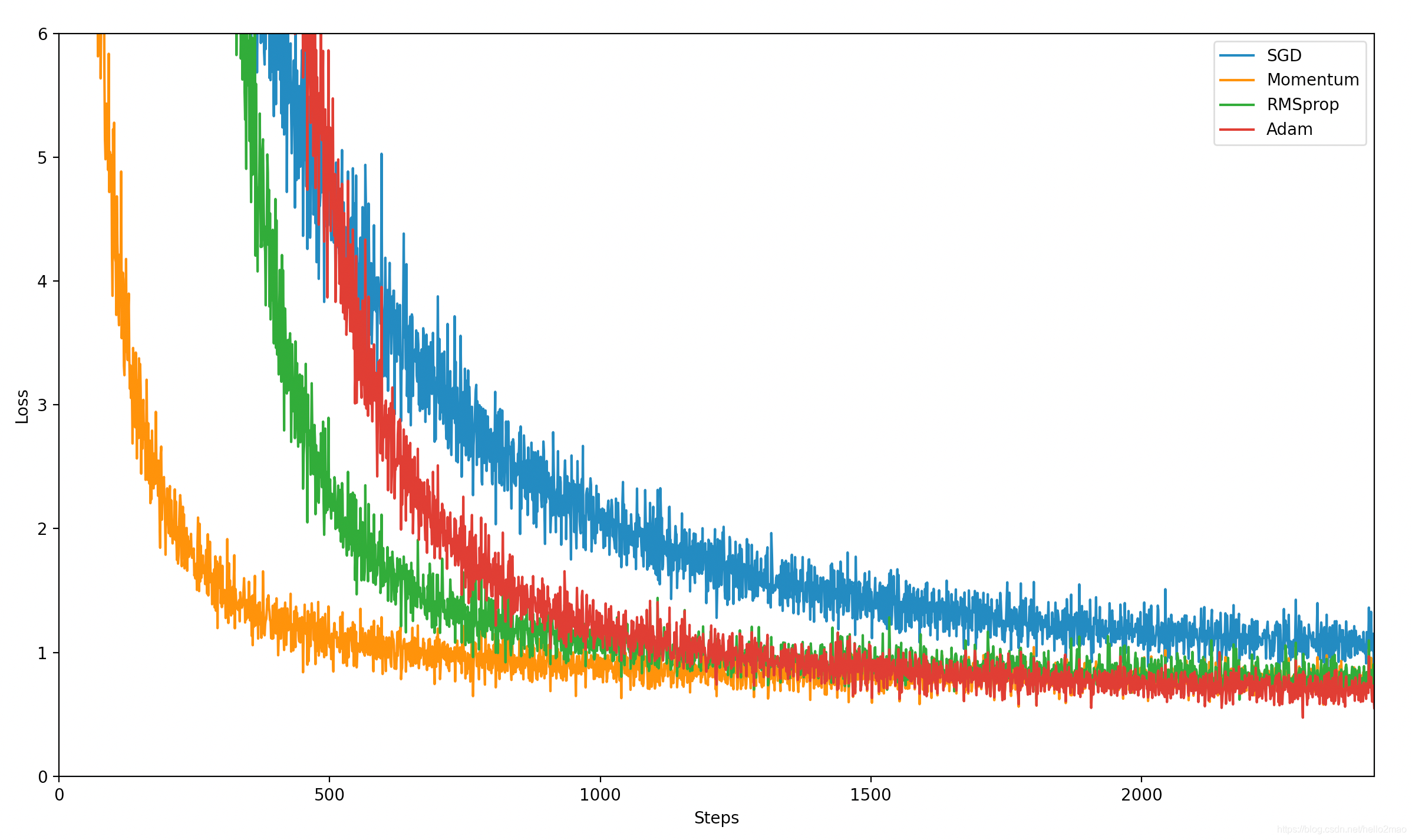
自己测试的数据果然看不出优劣,可以看下其他人的测试结果(详见:https://shaoanlu.wordpress.com/2017/05/29/sgd-all-which-one-is-the-best-optimizer-dogs-vs-cats-toy-experiment/):
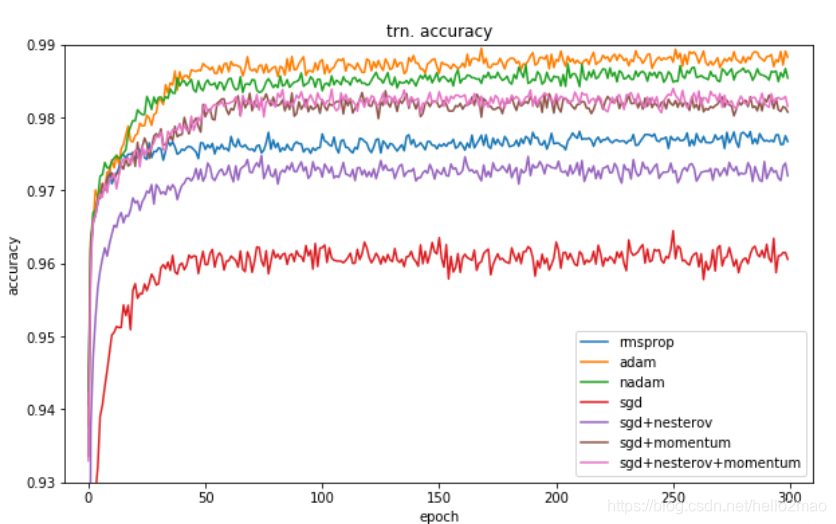
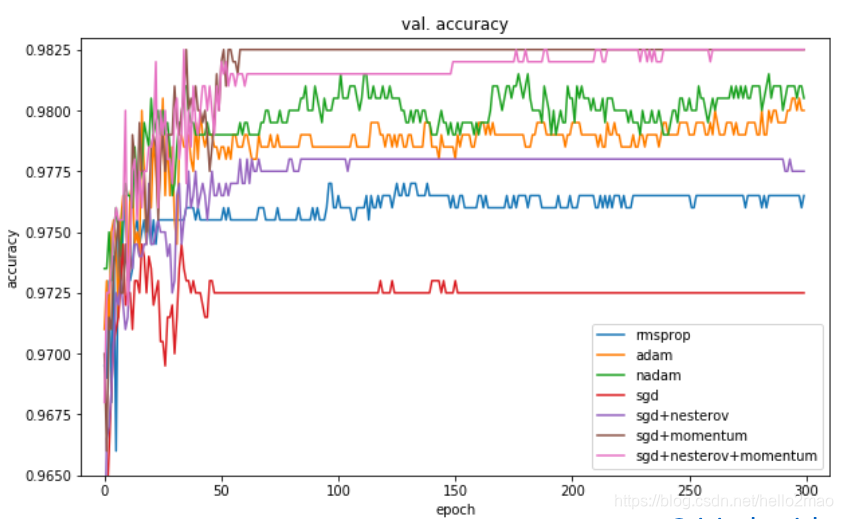
可以看到,在训练数据上,Adam表现比较好,在验证数据上,SGDM表现比较好,所以一般选择Adam或者SGDM ^_^.
六、Ref

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)