python自然语言处理课后答案
持续更新中…使用的是《python自然语言处理》这本书,只给部分笔者做的答案,不敢保证都对,仅供参考我的目录持续更新中...第一章1.41.61.131.141.181.211.222.232.242.252.262.28第一章1.4len(text2)#先弄成都小写,去掉大小写区别,在求个数len(set([w.lower() for w in set(a)]))1.6tex...
·
持续更新中…
使用的是《python自然语言处理》这本书,只给部分笔者做的答案,不敢保证都对,仅供参考
第一章
1.4
len(text2)
#先弄成都小写,去掉大小写区别,再求个数
len(set([w.lower() for w in set(a)]))
1.6
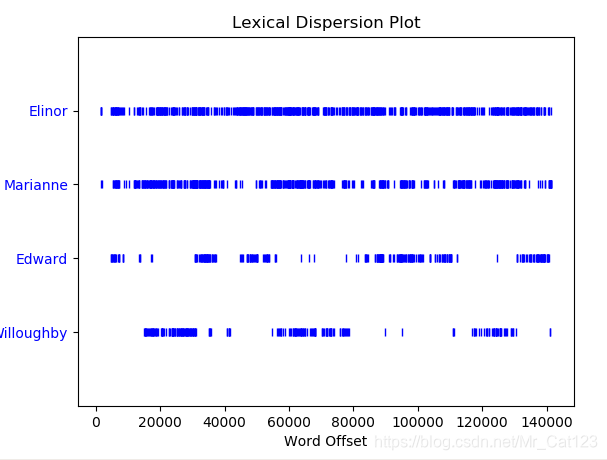
text2.dispersion_plot(['Elinor','Marianne','Edward','Willoughby'])
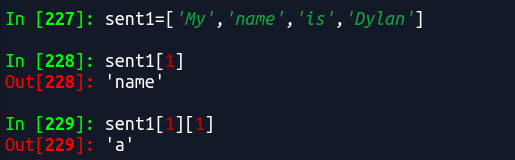
1.13
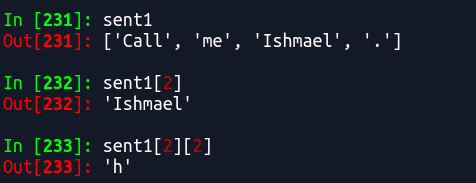
1.14

1.18
sorted(set(sent1+sent2+sent3...))
1.21
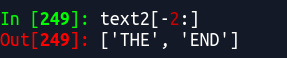
1.22
words = sorted([w.lower() for w in text5 if len(w)==4])
fdist = FreqDist(words)
fdist.most_common()
#or plot the first 10 words
fdist.plot(10)
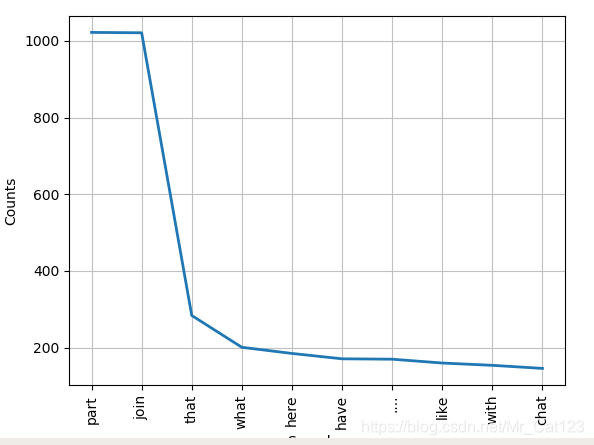
2.23
列表:
[w for w in text6 if w.isupper()]
每行一个: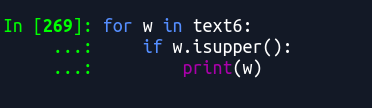
2.24
(a)
[w for w in text6 if w.endswith('ize')]
[]
(b)
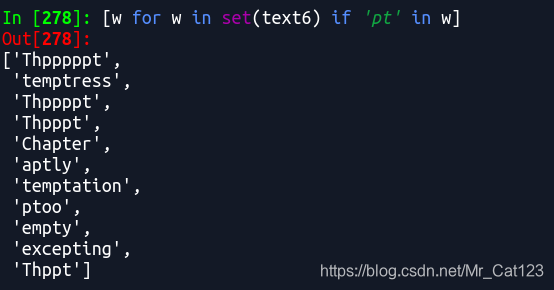
可以看到上面有重复的单词,故将上面的text6改为set(text6)
©
(d)
[w for w in set(text6) if w.istitle()]
2.25
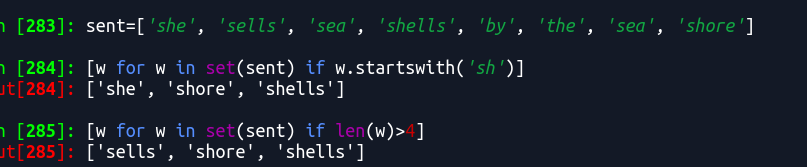
2.26
用来求全篇的字符/字母长度,如果要求字的平均长度可以如下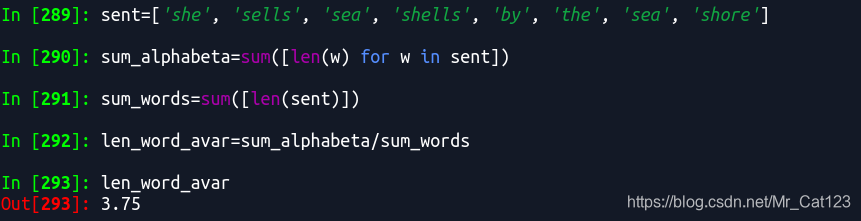
2.28
def percent(word,text):
return FreqDist(text)[word]/len(text)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 3
3 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)