语音中常用输入特征的提取过程:MFCC、FBank
声纹识别中常用输入特征的提取过程:MFCC、FBank介绍梅尔(Mel)频率掩蔽效应和临界带宽Mel滤波器MFCC提取流程1.预加重2.加窗3.DFT4.Mel滤波5.DCT变换Fbank提取流程总结介绍要了解 MFCC 的提取流程,我们先复习一下一些相关知识。梅尔(Mel)频率梅尔频率为人耳所感知到的声音频率。当音频的物理频率 fff 在1kHz 以下,其梅尔频率 Mel(f)Mel(f)Mel
介绍
要了解 MFCC 和 Fbank 的提取流程,先简单介绍一下梅尔频率、临界带宽、梅尔滤波器等相关知识。
梅尔(Mel)频率
梅尔频率为人耳所感知到的声音频率。当音频的物理频率 f f f 在1kHz 以下,其梅尔频率 M e l ( f ) Mel(f) Mel(f) 与 f f f 近似为线性关系,而在1kHz 以上则近似为对数关系。两者的对应关系可用下式来近似:
M e l ( f ) = 1127 l n ( 1 + f / 700 ) Mel(f)=1127{\rm ln} (1+f/700) Mel(f)=1127ln(1+f/700)
在 f > f> f> 1kHz 时,对数曲线如下: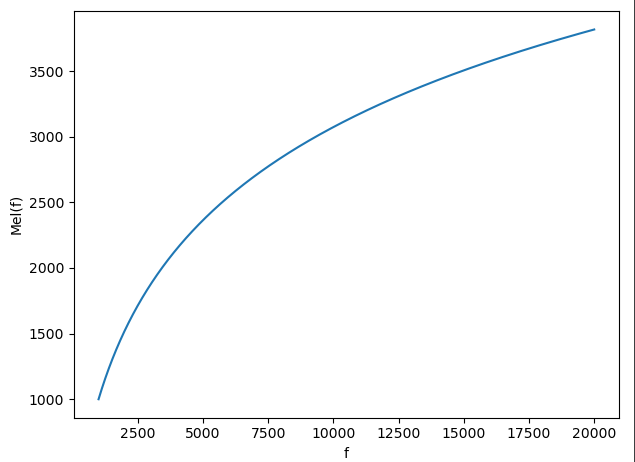
曲线斜率逐渐减小,即改变相同的 f f f,在频率较低处的 M e l ( f ) Mel(f) Mel(f) 变化更大,而在频率较高处的 M e l ( f ) Mel(f) Mel(f) 变化更小,因此人耳对较低频率更为敏感,而对较高频率更为不敏感。
掩蔽效应和临界带宽
当两个声音的频率差小于某个带宽 W W W 时,人耳无法分辨而把两个声音听成一个的现象称为掩蔽效应, W W W 则称为临界带宽。当声压恒定时,一段音频的频率在临界带宽内变化,人耳所感知到的只是该带宽中心频率的一个纯音,而无法感知其频率变化。
根据前面的分析,人耳对较低频率更为敏感,因此较低频率处的掩蔽效应较弱,临界带宽更小;而频率较高处的掩蔽效应更强,临界带宽更大。(这里说的临界带宽是在物理频率刻度下,梅尔频率刻度下临界带宽是一直不变的,因此梅尔频率更符合人的听觉感知)
Mel滤波器
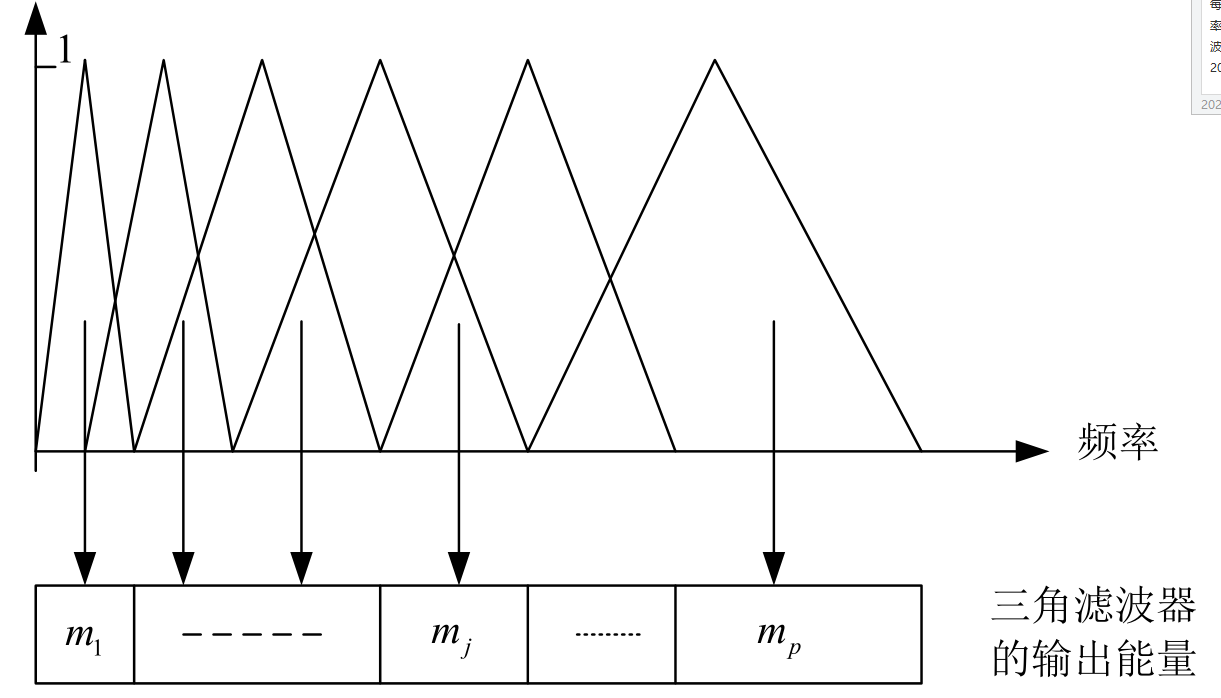
Mel滤波器是一组三角形滤波器,每个滤波器都是在一个临界带宽内的带通滤波器,由于临界带宽随着频率越来越大,因此滤波器组由密到疏,且带宽内中心频率的响应要大,两边响应要小。
进行滤波时,每个带通滤波器 j j j 和信号幅度的加权和 m j m_j mj 为该滤波器的输出,若有 p p p 个滤波器,则可提取到 p p p 维的特征 [ m 1 , m 2 , . . . , m p ] [m_1, m_2, ..., m_p] [m1,m2,...,mp]。
(至于为什么是三角形的,我觉得也可以换成别的,只要是带通即可)
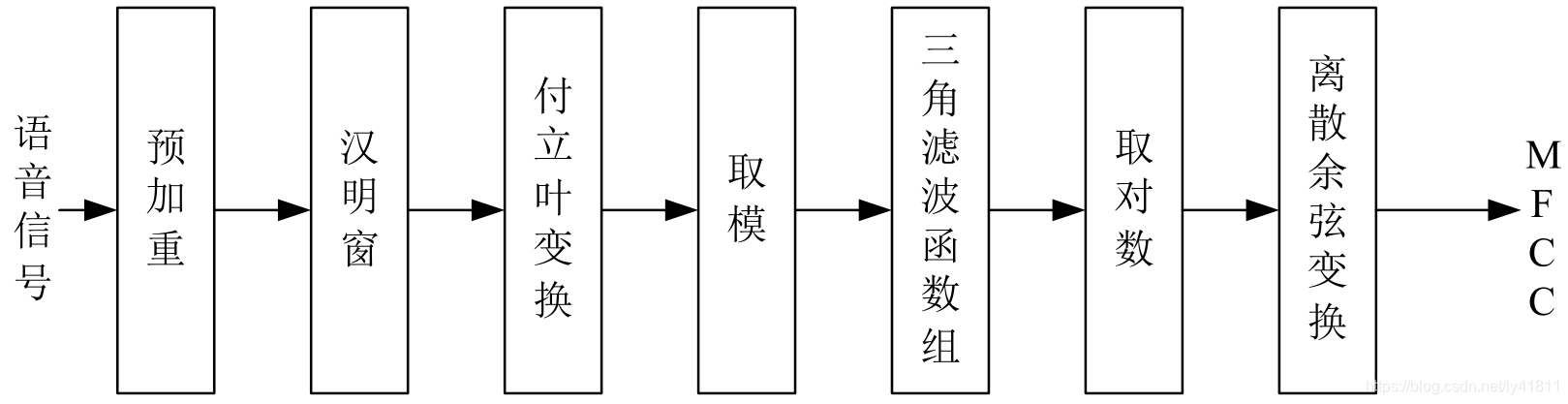
MFCC提取流程
1.预加重
假设 x ( n ) x(n) x(n) 为原信号,则按照下式进行加重:
y ( n ) = x ( n ) − 0.97 x ( n − 1 ) y(n)=x(n)-0.97x(n-1) y(n)=x(n)−0.97x(n−1)
y ( n ) y(n) y(n) 为加重后的信号。
从频率角度看,相当于把原信号经过了一个高通滤波器:
H ( z ) = 1 − 0.97 z − 1 H(z)=1-0.97z^{-1} H(z)=1−0.97z−1
目的是为了更突出高频,减轻口唇辐射的影响。
2.加窗
S w ( n ) = y ( n ) ∗ W ( n ) S_w(n)=y(n)*W(n) Sw(n)=y(n)∗W(n)
一般采用汉明窗。
语音信号本身不平稳,但是分帧后在每一帧内被当做平稳的来处理,因此会导致帧的起始和结尾处不连续,加窗使得全局更连续,减少吉伯斯效应。
由于加汉明窗削弱了两边的数据,因此在帧移时部分重叠,保证被削弱的部分在下一帧出现。
3.DFT

4.Mel滤波
为了更贴合人耳感知,把原信号的物理频率刻度换成 Mel 刻度。
设一组有 M M M个带通滤波器,其中第 m m m 个滤波器的加权系数为 H m H_m Hm,则滤波得到的特征为 S = [ S 1 , S 2 , . . . , S M ] S=[S_1, S_2, ..., S_M] S=[S1,S2,...,SM], 其中 S i S_i Si 为第 i i i 个滤波器的输出能量:

取对数是实现同态信号处理,便于后面去除卷积信道噪声。
5.DCT变换
由于 Mel 滤波器组之间有重叠,因此上一步得到的特征维度之间会有相关性。有些情况下不需要特征的相关特性,因此利用 DCT 去相关:

注意DCT变换后,能量基本集中在低频,因此只需取前面几维即可,相当于对上一步得到的特征进行了降维操作。
Fbank提取流程
FBank 特征不需要做 DCT 去相关,即在第4步 Mel 滤波后,得到的特征即为 FBank 特征。FBank 各维度之间有相关性,而一般来说 CNN 能够有效地利用这种相关性,因此 CNN 中用 FBank 作为输入性能更好。
总结

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)