算法学习笔记 渐进时间复杂度和求解递归式(代入法、递归树、主方法)
参考算法导论:第3章函数的增长 3.1节 渐近记号;第4章分治策略:4.3节 用代入法求解递归式;4.4节 用递归树方法求解递归式;4.5节 用主方法求解递归式;4.6节 证明主定理文章目录1. 渐近时间复杂度1.1 渐近记号渐近记号、函数与运行时间Θ\ThetaΘ 记号OOO 记号Ω\OmegaΩ 记号等式和不等式中的渐近记号ooo 记号ω\omegaω 记号比较各种函数常用数学函数单调性向下取
参考算法导论:
- 第3章函数的增长 3.1节 渐近记号;3.2节 标准记号与常用函数
- 第4章分治策略:4.3节 用代入法求解递归式;4.4节 用递归树方法求解递归式;4.5节 用主方法求解递归式;4.6节 证明主定理
- 第17章摊还分析
文章目录
1. 渐近时间复杂度
算导第2章定义的「算法运行时间的增长量级」简单地刻画了算法效率,还允许比较可选算法的相对性能。一旦输入规模 n n n 变得足够大,最坏情况运行时间为 Θ ( n log n ) \Theta(n\log n) Θ(nlogn) 的归并排序,将战胜最坏情况运行时间为 Θ ( n 2 ) \Theta(n^2) Θ(n2) 的插入排序。正如算导第2章对插入排序所做的,虽然有时能够确定一个算法的精确运行时间,但是通常并不值得花力气来计算它、以获得多余的精度。对于足够大的输入,精确运行时间中的倍增常量和低阶项、被增长规模本身的影响所支配。
当输入规模足够大、大到运行时间的增长量级只与其有关时 input sizes large enough to make only the order of growth of the running time relevant ,我们要研究算法的渐近效率 asymptotic efficiency 。也就是说,我们关心当输入规模无限增加时,在极限中算法的运行时间如何随着输入规模的变大而增加 how the running time of an algorithm increases with the size of the input in the limit, as the size of the input increases without bound 。通常,渐近地更有效的某个算法、对除很小的输入外的所有情况,将是更好的选择。
下面给出几种标准方法、定义几类“渐近符号”来简化算法的渐近分析。用来描述算法渐近运行时间的记号,根据「定义域为自然数集 N = { 0 , 1 , 2 , … } \N = \{ 0, 1, 2, \dots \} N={0,1,2,…} 的函数」来定义。这样的记号,对描述最坏情况运行时间的函数 T ( n ) T(n) T(n) 是方便的,因为该函数通常只定义在整数输入规模上。然而,我们发现有时按各种方式活用 abuse 渐近记号是方便的。例如,可以扩展该记号到实数域、或选择性地限制其到自然数的一个子集。然而,我们应该确保能理解该记号的精确含义,以便在活用时不会误用它 We should make sure, however, to understand the precise meaning of the notation so that when we abuse, we do not misuse it 。因此本节还介绍了一些常用的活用法。
1.1 渐近记号、函数与运行时间
正如插入排序的最坏情况运行时间为 Θ ( n 2 ) \Theta(n^2) Θ(n2) 一样,我们将主要使用渐近记号来描述算法的运行时间。然而,渐近记号实际上应用于函数。算法导论第2章中把插入排序的最坏情况运行时间刻画为 a n 2 + b n + c an^2 + bn+ c an2+bn+c ,其中 a , b , c a, b, c a,b,c 是常量,而通过把插入排序的运行时间写成 Θ ( n 2 ) \Theta(n^2) Θ(n2) ,我们除去了该函数的某些细节。因为渐近记号适用于函数,我们所写成的 Θ ( n 2 ) \Theta(n^2) Θ(n2) 就是函数 a n 2 + b n + c an^2 + bn+c an2+bn+c ,所以上述情况碰巧刻画了插入排序的最坏情况运行时间。
自然地,「对其使用渐近记号的函数」通常用于刻画算法的运行时间,但是渐近记号也可以适用于刻画算法的某个其他方面(例如,算法使用的空间大小)的函数,甚至可以适用于和算法没有任何关系的函数。
即使我们使用渐近记号来刻画算法的运行时间,我们也需要了解意指哪个运行时间。有时候对最坏情况运行时间感兴趣,然而我们常常希望刻画任何输入的运行时间。即做出一种综合性地、覆盖所有输入、而不仅仅是最坏情况的陈诉。我们将看到「完全适合刻画任何输入的运行时间的渐近记号」。
1.2 Θ \Theta Θ 记号
算导第2章中,插入排序的最坏情况运行时间为 T ( n ) = Θ ( n 2 ) T(n) = \Theta(n^2) T(n)=Θ(n2) 。让我们来定义这个记号意指什么。对一个给定的函数 g ( n ) g(n) g(n) ,用 Θ ( g ( n ) ) \Theta(g(n)) Θ(g(n)) 来表示以下函数的集合:
Θ ( g ( n ) ) = { f ( n ) ∣ 存 在 正 常 量 c 1 , c 2 和 n 0 , 使 得 对 所 有 n ≥ n 0 , 有 0 ≤ c 1 g ( n ) ≤ f ( n ) ≤ c 2 g ( n ) } \Theta(g(n)) = \{ f(n) \mid 存在正常量c_1, c_2和n_0,\\ 使得对所有n\ge n_0,有0\le c_1 g(n) \le f(n) \le c_2 g(n) \} Θ(g(n))={f(n)∣存在正常量c1,c2和n0,使得对所有n≥n0,有0≤c1g(n)≤f(n)≤c2g(n)}
若存在正常量 c 1 , c 2 c_1, c_2 c1,c2 ,使得对于足够大的 n n n ,函数 f ( n ) f(n) f(n) 能“夹入” c 1 g ( n ) c_1 g(n) c1g(n) 与 c 2 g ( n ) c_2 g(n) c2g(n) 之间,则 f ( n ) f(n) f(n) 属于集合 Θ ( g ( n ) ) \Theta(g(n)) Θ(g(n)) 。因为 Θ ( g ( n ) ) \Theta(g(n)) Θ(g(n)) 是一个集合,所以可以记 f ( n ) ∈ Θ ( g ( n ) ) f(n) \in \Theta(g(n)) f(n)∈Θ(g(n)) ,以指出 f ( n ) f(n) f(n) 是 Θ ( g ( n ) ) \Theta(g(n)) Θ(g(n)) 的成员。作为替代,我们通常记 f ( n ) = Θ ( g ( n ) ) f(n) = \Theta(g(n)) f(n)=Θ(g(n)) 以表达相同的概念。因为我们按这种方式活用了等式,所以可能感到困惑,但是在本节的后面将看到这样做有其好处。
图3-1(a)给出了函数 f ( n ) f(n) f(n) 与 g ( n ) g(n) g(n) 的一幅直观画面,其中 f ( n ) = Θ ( g ( n ) ) f(n) = \Theta(g(n)) f(n)=Θ(g(n)) 。对在 n 0 n_0 n0 及其右边 n n n 的所有值, f ( n ) f(n) f(n) 的值位于或高于 c 1 g ( n ) c_1 g(n) c1g(n) 且位于或低于 c 2 g ( n ) c_2 g(n) c2g(n) 。即对所有 n ≥ n 0 n \ge n_0 n≥n0 ,函数 f ( n ) f(n) f(n) 在一个常量因子内等于 g ( n ) g(n) g(n) 。我们称 g ( n ) g(n) g(n) 是 f ( n ) f(n) f(n) 的一个渐近紧确界 asymptotically tight bound 。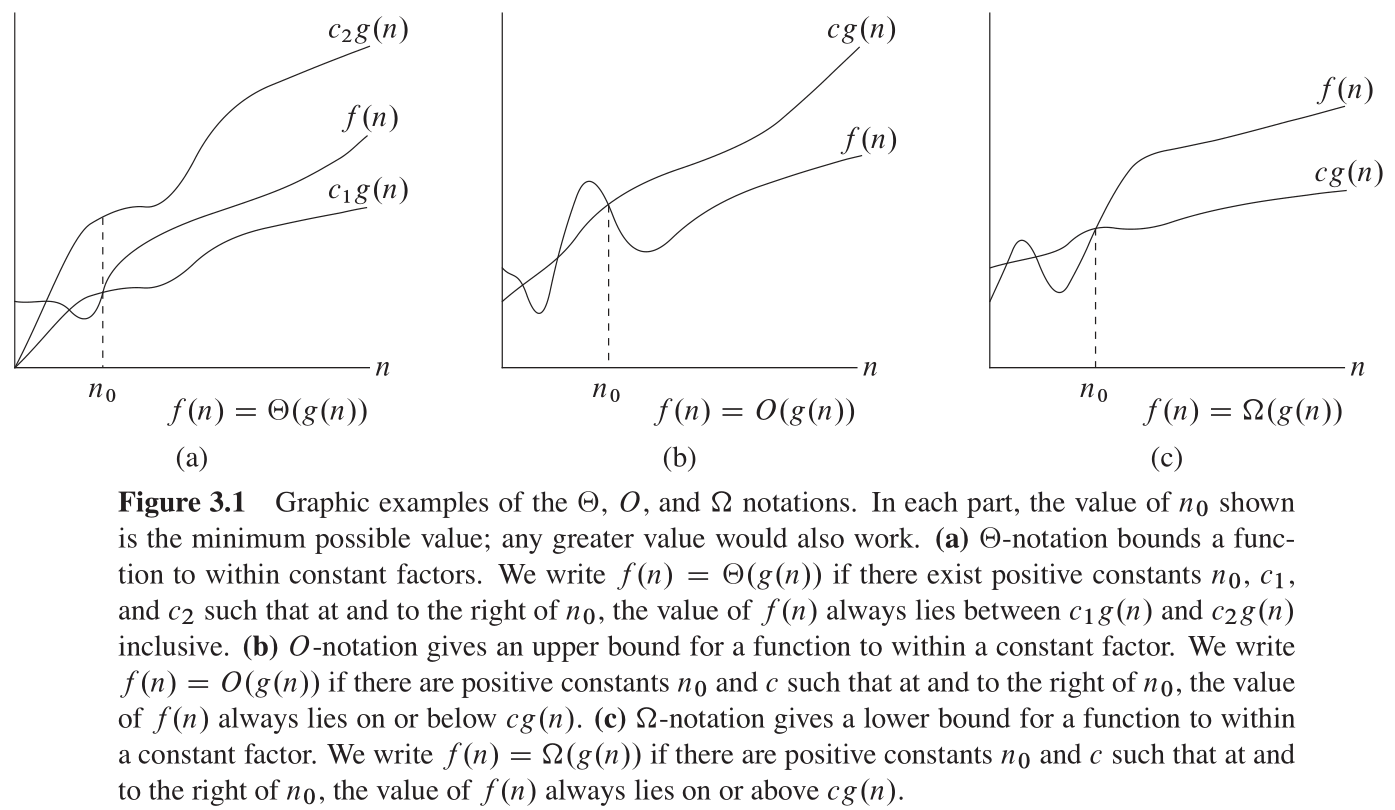
Θ ( g ( n ) ) \Theta(g(n)) Θ(g(n)) 的定义,要求每个成员 f ( n ) ∈ Θ ( g ( n ) ) f(n) \in \Theta(g(n)) f(n)∈Θ(g(n)) 均渐近非负 asymptotically nonnegative ,即当 n n n 足够大时, f ( n ) f(n) f(n) 非负(渐近正函数 asymptotically positive 就是对所有足够大的 n n n 均为正的函数)。因此,函数 g ( n ) g(n) g(n) 本身必为渐近非负,否则集合 Θ ( g ( n ) ) \Theta(g(n)) Θ(g(n)) 为空。所以,我们假设用在 Θ \Theta Θ 记号中的每个函数均渐近非负。这个假设对定义的其他渐近记号也成立。
在算导第2章中,介绍了 Θ \Theta Θ 记号的一种非形式化的概念,相当于扔掉低阶项、并忽略最高阶项前的系数。让我们通过形式化定义证明 1 2 n 2 − 3 n = Θ ( n 2 ) \dfrac{1}{2} n^2 - 3n = \Theta(n^2) 21n2−3n=Θ(n2) 来简要地证实这种直觉。为此,我们必须确定正常量 c 1 , c 2 , n 0 c_1, c_2, n_0 c1,c2,n0 ,使得对所有 n ≥ n 0 n \ge n_0 n≥n0 ,有: c 1 n 2 ≤ 1 2 n 2 − 3 n ≤ c 2 n 2 c_1 n^2 \le \dfrac{1}{2} n^2 - 3n \le c_2 n^2 c1n2≤21n2−3n≤c2n2
用 n 2 n^2 n2 除上式得: c 1 ≤ 1 2 − 3 n ≤ c 2 c_1 \le \dfrac{1}{2} - \dfrac{3}{n} \le c_2 c1≤21−n3≤c2 通过选择任何正常量 c 2 ≥ 1 / 2 c_2 \ge 1/2 c2≥1/2 ,可以使左边的不等式对任何 n ≥ 7 n \ge 7 n≥7 的值成立。因此,通过选择 c 1 = 1 / 14 , c 2 = 1 / 2 c_1 = 1/14, c_2 = 1/2 c1=1/14,c2=1/2 且 n 0 = 7 n_0 = 7 n0=7 ,可以证明 1 2 n 2 − 3 n = Θ ( n 2 ) \dfrac{1}{2} n^2 - 3n = \Theta(n^2) 21n2−3n=Θ(n2) 。当然,还存在对这些正常量的其他选择,但是重要的是存在某个选择。要注意的是,这些常量依赖于函数 1 2 n 2 − 3 n \dfrac{1}{2} n^2 - 3n 21n2−3n ;属于 Θ ( n 2 ) \Theta(n^2) Θ(n2) 的不同函数通常需要不同的常量。
我们还可以使用形式化定义来证明 6 n 3 ≠ Θ ( n 2 ) 6n^3 \ne \Theta(n^2) 6n3=Θ(n2) 。采用反证法,假设存在 c 2 c_2 c2 和 n 0 n_0 n0 ,使得对所有 n ≥ n 0 n \ge n_0 n≥n0 ,有 6 n 3 ≤ c 2 n 2 6n^3 \le c_2 n^2 6n3≤c2n2 。然而用 n 2 n^2 n2 除该式,得 n ≤ c 2 / 6 n \le c_2 / 6 n≤c2/6 ,因为 c 2 c_2 c2 为正常量,所以对任意大的 n n n ,该不等式不可能成立。
直觉上,一个渐近正函数的低阶项在确定渐近确界时可以被忽略,因为对大的 n n n ,它们是无足轻重的。当 n n n 较大时,即使最高阶项的一个很小的部分,都足以支配所有低阶项。因此,将 c 1 c_1 c1 置为稍小于最高阶项系数的值、并将 c 2 c_2 c2 置为稍大于最高阶项系数的值,能使 Θ \Theta Θ 记号定义中的不等式得到满足。最高阶项系数同样可以被忽略,因为它仅仅根据一个等于该系数的常量因子来改变 c 1 , c 2 c_1, c_2 c1,c2 。
作为一个例子,考虑任意二次函数 f ( n ) = a n 2 + b n + c f(n) = an^2 + bn+c f(n)=an2+bn+c ,其中 a , b , c a, b, c a,b,c 均为常量、且 a > 0 a > 0 a>0 。扔掉低阶项、并忽略常量后得 f ( n ) = Θ ( n 2 ) f(n) = \Theta(n^2) f(n)=Θ(n2) 。为了形式化地证明相同的结论,我们取常量 c 1 = a / 4 , c 2 = 7 a / 4 , n 0 = 2 × max ( ∣ b ∣ / a , ∣ c ∣ / a ) c_1 = a/4,\ c_2 = 7a/4,\ n_0 = 2 \times \max( | b| / a, \sqrt{ |c| /a }) c1=a/4, c2=7a/4, n0=2×max(∣b∣/a,∣c∣/a) ,可以证明对所有 n ≥ n 0 n\ge n_0 n≥n0 ,有 0 ≤ c 1 n 2 ≤ a n 2 + b n + c ≤ c 2 n 2 0 \le c_1 n^2 \le an^2+ bn+c \le c_2 n^2 0≤c1n2≤an2+bn+c≤c2n2 。
一般来说,对任意多项式 p ( n ) = ∑ i = 0 d a i n i p(n) =\displaystyle \sum^d_{i=0} a_in^i p(n)=i=0∑daini ,其中 a i a_i ai 为常量且 a d > 0 a_d > 0 ad>0 ,我们有 p ( n ) = Θ ( n d ) p(n) = \Theta(n^d) p(n)=Θ(nd)(参见算导思考题3-1)。因为任意常量是一个 0 0 0 阶多项式,所以可以把任意常量函数表示成 Θ ( n 0 ) \Theta(n^0) Θ(n0) 或 Θ ( 1 ) \Theta(1) Θ(1) 。然而,后一种记号是一种轻微的活用,因为该表达式并未指出什么变量趋于无穷,真正的问题在于通常的函数记号没有区分函数和函数值。我们将经常使用记号 Θ ( 1 ) \Theta(1) Θ(1) 来表示一个常量或者关于某个变量的一个常量函数。
1.3 O O O 记号
Θ \Theta Θ 记号渐近地给出一个函数的上界和下界。当只有一个渐近上界 asymptotic upper bound 时,使用 O O O 记号,对于给定的函数 g ( n ) g(n) g(n) ,用 O ( g ( n ) ) O(g(n)) O(g(n))(英语发音 big-oh of g of n )来表示以下函数的集合:
O ( g ( n ) ) = { f ( n ) ∣ 存 在 正 常 量 c 和 n 0 , 使 得 对 所 有 n ≥ n 0 , 有 0 ≤ f ( n ) ≤ c g ( n ) } O(g(n)) = \{ f(n) \mid 存在正常量c和n_0, 使得对所有n\ge n_0,有0\le f(n) \le cg(n) \} O(g(n))={f(n)∣存在正常量c和n0,使得对所有n≥n0,有0≤f(n)≤cg(n)}
我们使用 O O O 记号来给出「函数的一个在常量因子内的上界」。图3-1(b)展示了 O O O 记号背后的直觉知识。对在 n 0 n_0 n0 及其右边的所有值 n n n ,函数 f ( n ) f(n) f(n) 的值总小于或等于 c g ( n ) cg(n) cg(n) 。
我们记 f ( n ) = O ( g ( n ) ) f(n) = O(g(n)) f(n)=O(g(n)) 以指出函数 f ( n ) f(n) f(n) 是集合 O ( g ( n ) ) O(g(n)) O(g(n)) 的成员。注意, f ( n ) = Θ ( g ( n ) ) f(n) = \Theta(g(n)) f(n)=Θ(g(n)) 蕴含着 f ( n ) = O ( g ( n ) ) f(n) = O(g(n)) f(n)=O(g(n)) ,因为 Θ \Theta Θ 记号是一个比 O O O 记号更强的概念。按集合论中的写法,我们有 Θ ( g ( n ) ) ⊆ O ( g ( n ) ) \Theta(g(n)) \subseteq O(g(n)) Θ(g(n))⊆O(g(n)) 。因此,关于任意二次函数 a n 2 + b n + c ( a > 0 ) an^2 + bn+c\ (a > 0) an2+bn+c (a>0) 在 Θ ( n 2 ) \Theta(n^2) Θ(n2) 中的证明,也说明了任意这样的二次函数在 O ( n 2 ) O(n^2) O(n2) 中。更令人惊奇的是,当 a > 0 a > 0 a>0 时,任意线性函数 a n + b an + b an+b 也在 O ( n 2 ) O(n^2) O(n2) 中,通过取 c = a + ∣ b ∣ c = a + | b| c=a+∣b∣ 和 n 0 = max ( 1 , − b / a ) n_0 = \max (1,\ -b/ a) n0=max(1, −b/a) ,可以很容易地证明这个结论。
有时在文献中,也会发现 O O O 记号非形式化地描述渐近确界,即已经使用 Θ \Theta Θ 记号定义的东西。然而在算导中,当书写 f ( n ) = O ( g ( n ) ) f(n) = O(g(n)) f(n)=O(g(n)) 时,仅仅要求 g ( n ) g(n) g(n) 的某个常量倍数是 f ( n ) f(n) f(n) 的渐近上界、而不要求它是一个多么紧确的上界。在算法论文中,标准的做法是区分渐近上界和渐近确界。
使用 O O O 记号,我们常常可以仅通过检查算法的总体结构、以描述算法的运行时间。例如,算导第2章中插入排序算法的双重嵌套循环结构、对最坏情况运行时间立即产生一个 O ( n 2 ) O(n^2) O(n2) 的上界:内层循环每次迭代的代价以 O ( 1 ) O(1) O(1)(常量)为上界(?),下标 i , j i,j i,j 均最多为 n n n ,对于 n 2 n^2 n2 个 i i i 和 j j j 值对的每一对,内循环最多执行一次。
既然 O O O 记号描述上界,那么当我们用它来限定一个算法的最坏情况运行时间时,我们就有一个「该算法在每个输入上的运行时间」的界 Since O-notation describes an upper bound, when we use it to bound the worst-case running time of an algorithm, we have a bound on the running time of the algorithm on every input ,这就是前面讨论的综合性陈诉。因此,对插入排序的最坏情况运行时间的界 O ( n 2 ) O(n^2) O(n2) 也适用于该算法对每个输入的运行时间。然而,对插入排序的最坏情况运行时间的界 Θ ( n 2 ) \Theta(n^2) Θ(n2) 并未暗示插入排序对每个输入的运行时间的界也是 Θ ( n 2 ) \Theta(n^2) Θ(n2) ,例如在算导第2章曾看到,当输入已排好序时,插入排序的运行时间为 Θ ( n ) \Theta(n) Θ(n) 。从技术上看,称插入排序的运行时间为 O ( n 2 ) O(n^2) O(n2) is an abuse ,因为对于给定的 n n n ,实际的运行时间是变化的,依赖于规模为 n n n 的特定输入。当我们说“运行时间为 O ( n 2 ) O(n^2) O(n2) 时”,意指存在一个是 O ( n 2 ) O(n^2) O(n2) 的函数 f ( n ) f(n) f(n) ,使得对 n n n 的任意值,不管选择什么特定的规模为 n n n 的输入,其运行时间的上界都是 f ( n ) f(n) f(n) 。等价地,我们是在说其最坏情况运行时间为 O ( n 2 ) O(n^2) O(n2) 。
1.4 Ω \Omega Ω 记号
正如 O O O 记号提供了一个函数的渐近上界, Ω \Omega Ω 记号提供了渐近下界 asymptotic lower bound 。对于给定的函数 g ( n ) g(n) g(n) ,用 Ω ( g ( n ) ) \Omega(g(n)) Ω(g(n))(英语发音为 “big-omega of g of n )来表示以下函数的集合:
Ω ( g ( n ) ) = { f ( n ) ∣ 存 在 正 常 量 c 和 n 0 , 使 得 对 所 有 n ≥ n 0 , 有 0 ≤ c g ( n ) ≤ f ( n ) } \Omega(g(n)) = \{ f(n) \mid 存在正常量c和n_0,使得对所有n\ge n_0,有0\le cg(n) \le f(n) \} Ω(g(n))={f(n)∣存在正常量c和n0,使得对所有n≥n0,有0≤cg(n)≤f(n)}
图3-1©给出了 Ω \Omega Ω 记号的直观解释。对在 n 0 n_0 n0 及其右边的所有值 n n n , f ( n ) f(n) f(n) 的值总是大于或等于 c g ( n ) cg(n) cg(n) 。
根据目前所看到的这些渐近记号的定义,容易证明以下重要定理(参见算导练习3.1-5)。
定理3.1 对任意两个函数 f ( n ) f(n) f(n) 和 g ( n ) g(n) g(n) ,我们有 f ( n ) = Θ ( g ( n ) ) f(n) = \Theta(g(n)) f(n)=Θ(g(n)) ,当且仅当 f ( n ) = O ( g ( n ) ) f(n) = O(g(n)) f(n)=O(g(n)) 且 f ( n ) = Ω ( g ( n ) ) f(n) = \Omega(g(n)) f(n)=Ω(g(n)) 。
作为应用本定理的一个例子,关于对任意常量 a , b , c a, b, c a,b,c ,其中 a > 0 a > 0 a>0 ,有 a n 2 + b n + c = Θ ( n 2 ) an^2 + bn+c = \Theta(n^2) an2+bn+c=Θ(n2) 的证明,直接蕴含 a n 2 + b n + c = Ω ( n 2 ) an^2 + bn+c = \Omega(n^2) an2+bn+c=Ω(n2) 和 a n 2 + b n + c = O ( n 2 ) an^2+bn+c= O(n^2) an2+bn+c=O(n2) 。实际上不是像该例子中所做的,应用定理3.1从渐近确界获得渐近上界和下界,而是通常用它从渐近上界和下界来证明渐近确界。
当称一个算法的运行时间(无修饰语)为 Ω ( g ( n ) ) \Omega(g(n)) Ω(g(n)) 时,我们意指对每个 n n n 值,不管选择什么特定的规模为 n n n 的输入,只要 n n n 足够大,对那个输入的运行时间至少是 g ( n ) g(n) g(n) 的常量倍。等价地,我们在对一个算法的最好情况运行时间给出一个下界。
例如,插入排序的最好情况运行时间为 Ω ( n ) \Omega(n) Ω(n) ,这蕴含着插入排序的运行时间为 Ω ( n ) \Omega(n) Ω(n) 。所以插入排序的运行时间介于 Ω ( n ) \Omega(n) Ω(n) 和 O ( n 2 ) O(n^2) O(n2) ,因为它落入 n n n 的线性函数与 n n n 的二次函数之间的任何地方,而且这两个界是尽可能渐近地紧确的:例如,插入排序的运行时间不是 Ω ( n 2 ) \Omega(n^2) Ω(n2) ,因为存在一个输入(例如当输入已排好序时),对该输入、插入排序在 Θ ( n ) \Theta(n) Θ(n) 时间内运行。然而,这与称插入排序的最坏情况运行时间为 Ω ( n 2 ) \Omega(n^2) Ω(n2) 并不矛盾,因为存在一个输入,使得该算法需要 Ω ( n 2 ) \Omega(n^2) Ω(n2) 的时间。
1.5 等式和不等式中的渐近记号
我们已经看到,渐近记号可以如何用于数学公式中。例如,在介绍 O O O 记号时,记 n = O ( n 2 ) n = O(n^2) n=O(n2) 。还写过 2 n 2 + 3 n + 1 = 2 n 2 + Θ ( n ) 2n^2 +3n+1 = 2n^2 + \Theta(n) 2n2+3n+1=2n2+Θ(n) 。如何解释这样的公式呢?
当渐近记号独立存在于等式(或不等式)的右边(即不在一个更大的公式内)时 When the asymptotic notation stands alone on the right-hand side of an equation (or inequality) ,如在 n = O ( n 2 ) n = O(n^2) n=O(n2) 中,已经定义等号意指集合的成员关系: n ∈ O ( n 2 ) n \in O(n^2) n∈O(n2) 。
然而,一般来说,当渐近记号出现在某个公式中时,我们将其解释为代表某个我们不关注名称的匿名函数,例如公式 2 n 2 + 3 n + 1 = 2 n 2 + Θ ( n ) 2n^2 + 3n + 1 = 2n^2 + \Theta(n) 2n2+3n+1=2n2+Θ(n) 意指 2 n 2 + 3 n + 1 = 2 n 2 + f ( n ) 2n^2 + 3n+1 = 2n^2 + f(n) 2n2+3n+1=2n2+f(n) ,其中 f ( n ) f(n) f(n) 是集合 Θ ( n ) \Theta(n) Θ(n) 中的某个函数。在这个例子中,假设 f ( n ) = 3 n + 1 f(n) = 3n+1 f(n)=3n+1 ,该函数确实在 Θ ( n ) \Theta(n) Θ(n) 中。按这种方式使用渐近记号,可以帮助消除一个等式中无关紧要的细节与混乱。例如,算导第2章中把归并排序的最坏情况运行时间表示为递归式: T ( n ) = 2 T ( n / 2 ) + Θ ( n ) T(n) = 2T(n/2) + \Theta(n) T(n)=2T(n/2)+Θ(n) 。如果只对 T ( n ) T(n) T(n) 的渐近行为感兴趣,那么没有必要准确说明所有低阶项,它们都被理解为包含在由项 Θ ( n ) \Theta(n) Θ(n) 表示的匿名函数中。
一个表达式中匿名函数的数目,可以理解为等同于渐近记号出现的次数 The number of anonymous functions in an expression is understood to be equal to the number of times the asymptotic notation appears 。例如,在表达式 ∑ i = 1 n O ( i ) \displaystyle \sum^n_{i=1} O(i) i=1∑nO(i) 中,只有一个匿名函数(一个 i i i 的函数)。因此,这个表达式不同于 O ( 1 ) + O ( 2 ) + ⋯ + O ( n ) O(1) + O(2) + \dots + O(n) O(1)+O(2)+⋯+O(n) ,实际上后者没有一个清晰的解释(?)。
在某些例子中,渐近记号出现在等式的左边,例如: 2 n 2 + Θ ( n ) = Θ ( n 2 ) 2n^2 + \Theta(n) =\Theta(n^2) 2n2+Θ(n)=Θ(n2) 。我们使用以下规则来解释这种等式:无论怎样选择等号左边的匿名函数,总有一种办法来选择等号右边的匿名函数使等式成立。因此,我们的例子意指:对任意函数 f ( n ) ∈ Θ ( n ) f(n) \in \Theta(n) f(n)∈Θ(n) ,存在某个函数 g ( n ) ∈ Θ ( n 2 ) g(n) \in \Theta(n^2) g(n)∈Θ(n2) ,使得对所有的 n n n ,有 2 n 2 + f ( n ) = g ( n ) 2n^2+f(n) = g(n) 2n2+f(n)=g(n) 。换句话说,等式右边比左边提供的细节更粗糙。
我们可以将许多这样的关系链在一起,例如: 2 n 2 + 3 n + 1 = 2 n 2 + Θ ( n ) = Θ ( n 2 ) 2n^2+3n+1 = 2n^2 + \Theta(n) = \Theta(n^2) 2n2+3n+1=2n2+Θ(n)=Θ(n2) 可以用上述规则分别解释每个等式。第一个等式表明,存在某个函数 f ( n ) ∈ Θ ( n ) f(n) \in \Theta(n) f(n)∈Θ(n) ,使得对所有的 n n n ,有 2 n 2 + 3 n + 1 = 2 n 2 + f ( n ) 2n^2 + 3n+1 = 2n^2 + f(n) 2n2+3n+1=2n2+f(n) 。第二个等式表明,对任意函数 g ( n ) ∈ Θ ( n ) g(n) \in \Theta(n) g(n)∈Θ(n)(如刚刚提到的 f ( n ) f(n) f(n) ),存在某个函数 h ( n ) ∈ Θ ( n 2 ) h(n) \in \Theta(n^2) h(n)∈Θ(n2) ,使得对所有的 n n n ,有 2 n 2 + g ( n ) = h ( n ) 2n^2 + g(n) = h(n) 2n2+g(n)=h(n) 。注意,这种解释蕴含着 2 n 2 + 3 n + 1 = Θ ( n 2 ) 2n^ 2+3n+1 = \Theta(n^2) 2n2+3n+1=Θ(n2) ,这就是等式链直观上提供给我们的东西。
1.6 o o o 记号
由 O O O 记号提供的渐近上界,可能是、也可能不是渐近紧确的。界 2 n 2 = O ( n 2 ) 2n^2 = O(n^2) 2n2=O(n2) 是渐近紧确的,但是界 2 n = O ( n 2 ) 2n = O(n^2) 2n=O(n2) 却不是。我们使用 o o o 记号来表述一个非渐近紧确的上界。形式化地定义 o ( g ( n ) ) o(g(n)) o(g(n))(英语发音为 little-oh of g of n )为以下集合:
o ( g ( n ) ) = { f ( n ) ∣ 对 任 意 正 常 量 c > 0 , 存 在 正 常 量 n 0 > 0 , 使 得 对 所 有 n ≥ n 0 , 有 0 ≤ f ( n ) < c g ( n ) } o(g(n)) = \{ f(n) \mid 对任意正常量 c>0,存在正常量n_0 > 0,\\ 使得对所有n\ge n_0, 有0\le f(n) < cg(n) \} o(g(n))={f(n)∣对任意正常量c>0,存在正常量n0>0,使得对所有n≥n0,有0≤f(n)<cg(n)}
O O O 记号与 o o o 记号的定义类似。主要的区别是在 f ( n ) = O ( g ( n ) ) f(n) = O(g(n)) f(n)=O(g(n)) 中,界 0 ≤ f ( n ) ≤ c g ( n ) 0 \le f(n) \le cg(n) 0≤f(n)≤cg(n) 对某个常量 c > 0 c > 0 c>0 成立,但在 f ( n ) = o ( g ( n ) ) f(n) = o(g(n)) f(n)=o(g(n)) 中,界 0 ≤ f ( n ) < c g ( n ) 0 \le f(n) < cg(n) 0≤f(n)<cg(n) 对所有常量 c > 0 c > 0 c>0 成立。直观上,在 o o o 记号中,当 n n n 趋于无穷时,函数 f ( n ) f(n) f(n) 相对于 g ( n ) g(n) g(n) 来说变得微不足道了,即: lim n → ∞ f ( n ) g ( n ) = 0 (3.1) \tag{3.1} \begin{aligned} \lim _{n \to \infin} \dfrac{f(n)} {g(n)} = 0\end{aligned} n→∞limg(n)f(n)=0(3.1)
有些学者使用这个极限作为 o o o 记号的定义。算导中的定义还限定匿名函数是渐近非负的 restricts the anonymous functions to be asymptotically nonnegative 。
1.7 ω \omega ω 记号
ω \omega ω 记号与 Ω \Omega Ω 记号的关系,类似于 o o o 记号与 O O O 记号的关系。我们使用 ω \omega ω 记号来表示一个非渐近紧确的下界。定义它的一种方式是: f ( n ) ∈ ω ( g ( n ) ) 当 且 仅 当 g ( n ) ∈ o ( f ( n ) ) f(n) \in \omega(g(n)) \ 当且仅当\ g(n) \in o(f(n)) f(n)∈ω(g(n)) 当且仅当 g(n)∈o(f(n)) 然而,我们形式化地定义 ω ( g ( n ) ) \omega(g(n)) ω(g(n))(英语发音 little-omega of g of n )为以下集合:
ω ( g ( n ) ) = { f ( n ) ∣ 对 任 意 正 常 量 c > 0 , 存 在 常 量 n 0 > 0 , 使 得 对 所 有 n ≥ n 0 , 有 0 ≤ c g ( n ) < f ( n ) } \omega(g(n)) = \{ f(n) \mid 对任意正常量c > 0,存在常量n_0 > 0,\\ 使得对所有n\ge n_0, 有0\le cg(n) < f(n) \} ω(g(n))={f(n)∣对任意正常量c>0,存在常量n0>0,使得对所有n≥n0,有0≤cg(n)<f(n)} 例如, n 2 / 2 = ω ( n ) n^2 / 2 = \omega(n) n2/2=ω(n) ,但是 n 2 / 2 ≠ ω ( n 2 ) n^2/ 2 \ne \omega(n^2) n2/2=ω(n2) 。关系 f ( n ) = ω ( g ( n ) ) f(n) = \omega(g(n)) f(n)=ω(g(n)) 蕴含着: lim n → ∞ f ( n ) g ( n ) = ∞ \lim_{n \to \infin} \dfrac{f(n)}{g(n)} = \infin n→∞limg(n)f(n)=∞
也就是说,如果这个极限存在,那么当 n n n 趋于无穷时, f ( n ) f(n) f(n) 相对于 g ( n ) g(n) g(n) 来说变得任意大了。
1.8 比较各种函数
(实数的)许多关系性质也适用于渐近比较。下面假定 f ( n ) , g ( n ) f(n), g(n) f(n),g(n) 渐近为正。
- 传递性:
f ( n ) = Θ ( g ( n ) ) 且 g ( n ) = Θ ( h ( n ) ) ⟹ f ( n ) = Θ ( h ( n ) ) f ( n ) = O ( g ( n ) ) 且 g ( n ) = O ( h ( n ) ) ⟹ f ( n ) = O ( h ( n ) ) f ( n ) = Ω ( g ( n ) ) 且 g ( n ) = Ω ( h ( n ) ) ⟹ f ( n ) = Ω ( h ( n ) ) f ( n ) = o ( g ( n ) ) 且 g ( n ) = o ( h ( n ) ) ⟹ f ( n ) = o ( h ( n ) ) f ( n ) = ω ( g ( n ) ) 且 g ( n ) = ω ( h ( n ) ) ⟹ f ( n ) = ω ( h ( n ) ) \begin{aligned} &f(n) = \Theta(g(n)) 且g(n) = \Theta(h(n)) &\implies f(n) = \Theta(h(n)) \\ &f(n) = O(g(n)) 且 g(n) = O(h(n)) &\implies f(n) = O(h(n)) \\ &f(n) = \Omega(g(n)) 且 g(n) = \Omega(h(n)) &\implies f(n) = \Omega(h(n)) \\ &f(n) = o(g(n)) 且 g(n) = o(h(n)) &\implies f(n) = o(h(n)) \\ &f(n) = \omega(g(n)) 且 g(n) = \omega(h(n)) &\implies f(n) = \omega(h(n)) \end{aligned} f(n)=Θ(g(n))且g(n)=Θ(h(n))f(n)=O(g(n))且g(n)=O(h(n))f(n)=Ω(g(n))且g(n)=Ω(h(n))f(n)=o(g(n))且g(n)=o(h(n))f(n)=ω(g(n))且g(n)=ω(h(n))⟹f(n)=Θ(h(n))⟹f(n)=O(h(n))⟹f(n)=Ω(h(n))⟹f(n)=o(h(n))⟹f(n)=ω(h(n)) - 自反性: f ( n ) = Θ ( f ( n ) ) f ( n ) = O ( f ( n ) ) f ( n ) = Ω ( f ( n ) ) \begin{aligned} &f(n) = \Theta(f(n)) \\ &f(n) = O(f(n)) \\ &f(n) = \Omega(f(n)) \end{aligned} f(n)=Θ(f(n))f(n)=O(f(n))f(n)=Ω(f(n))
- 对称性: f ( n ) = Θ ( g ( n ) ) ⇔ g ( n ) = Θ ( f ( n ) ) f(n) = \Theta(g(n)) \Lrarr g(n) = \Theta(f(n)) f(n)=Θ(g(n))⇔g(n)=Θ(f(n))
- 转置对称性: f ( n ) = O ( g ( n ) ) ⇔ g ( n ) = Ω ( f ( n ) ) f ( n ) = o ( g ( n ) ) ⇔ g ( n ) = ω ( f ( n ) ) \begin{aligned} &f(n) = O(g(n)) \Lrarr g(n) = \Omega(f(n)) \\ &f(n) = o(g(n)) \Lrarr g(n) = \omega(f(n)) \end{aligned} f(n)=O(g(n))⇔g(n)=Ω(f(n))f(n)=o(g(n))⇔g(n)=ω(f(n))
因为这些性质对渐近记号成立,所以可以在两个函数 f , g f,g f,g 的渐近比较与两个实数 a , b a, b a,b 的比较之间、做一种类比。
f ( n ) = O ( g ( n ) ) 类 似 于 a ≤ b f ( n ) = Ω ( g ( n ) ) 类 似 于 a ≥ b f ( n ) = Θ ( g ( n ) ) 类 似 于 a = b f ( n ) = o ( g ( n ) ) 类 似 于 a < b f ( n ) = ω ( g ( n ) ) 类 似 于 a > b \begin{aligned} &f(n) = O(g(n))\ 类似于\ a\le b \\ &f(n) = \Omega(g(n))\ 类似于\ a\ge b \\ &f(n) = \Theta(g(n))\ 类似于\ a= b \\ &f(n) = o(g(n))\ 类似于\ a\lt b \\ &f(n) = \omega(g(n))\ 类似于\ a\gt b \\ \end{aligned} f(n)=O(g(n)) 类似于 a≤bf(n)=Ω(g(n)) 类似于 a≥bf(n)=Θ(g(n)) 类似于 a=bf(n)=o(g(n)) 类似于 a<bf(n)=ω(g(n)) 类似于 a>b 则若 f ( n ) = o ( g ( n ) ) f(n) = o(g(n)) f(n)=o(g(n)) ,则称 f ( n ) f(n) f(n) 渐近小于 asymptotically smaller g ( n ) g(n) g(n) ;若 f ( n ) = ω ( g ( n ) ) f(n) = \omega(g(n)) f(n)=ω(g(n)) ,则称 f ( n ) f(n) f(n) 渐近大于 asymptotically larger g ( n ) g(n) g(n) 。然而,实数的下列性质,不能携带到渐近记号:
- 三分性:对任意两个实数 a , b a, b a,b ,下列三种情况恰有一种必须成立: a < b , a = b , a > b a < b, a= b, a>b a<b,a=b,a>b(【离散数学】集合论 第四章 函数与集合(6) 三歧性定理、两集合基数判等定理(基数的比较)、Cantor定理)。
- 虽然任意两个实数都可以进行比较,但不是所有函数都可渐近比较。也就是说对两个函数 f ( n ) , g ( n ) f(n), g(n) f(n),g(n) ,也许 f ( n ) = O ( g ( n ) ) , f ( n ) = Ω ( g ( n ) ) f(n) = O(g(n)),\ f(n) = \Omega(g(n)) f(n)=O(g(n)), f(n)=Ω(g(n)) 都不成立。例如,我们不能使用渐近记号来比较函数 n n n 和 n 1 + sin n n^{1 + \sin n} n1+sinn ,因为 n 1 + sin n n^{1+\sin n} n1+sinn 中的幂值在 0 0 0 与 2 2 2 之间摆动,取介于两者之间的所有值。
2. 常用数学函数
本节将回顾一些「在算法分析中常见的标准的数学函数」的行为,还将阐明渐近记号的使用。
2.1 单调性
若 m ≤ n m\le n m≤n 蕴含 f ( m ) ≤ f ( n ) f(m) \le f(n) f(m)≤f(n) ,则函数 f ( n ) f(n) f(n) 是单调递增 monotonically increasing 的。类似的,若 m ≤ n m \le n m≤n 蕴含 f ( m ) ≥ f ( n ) f(m) \ge f(n) f(m)≥f(n) ,则函数 f ( n ) f(n) f(n) 是单调递减 monotonically decreasing 的。若 m < n m < n m<n 蕴含 f ( m ) < f ( n ) f(m) < f(n) f(m)<f(n) ,则函数 f ( n ) f(n) f(n) 是严格递增 strictly increasing 的。若 m < n m < n m<n 蕴含 f ( m ) > f ( n ) f(m) > f(n) f(m)>f(n) ,则函数 f ( n ) f(n) f(n) 是严格递减 strictly decreasing 的。
2.2 向下取整与向上取整
对任意实数 x x x ,我们用 ⌊ x ⌋ \lfloor x \rfloor ⌊x⌋ 表示小于或等于 x x x 的最大整数(读作 the floor of x ),并用 ⌈ x ⌉ \lceil x \rceil ⌈x⌉ 表示大于或等于 x x x 的最小整数(读作 the ceiling of x )。对所有实数 x x x : x − 1 < ⌊ x ⌋ ≤ x ≤ ⌈ x ⌉ < x + 1 (3.3) \tag{3.3} x - 1 < \lfloor x \rfloor \le x \le \lceil x \rceil < x+1 x−1<⌊x⌋≤x≤⌈x⌉<x+1(3.3)
对任意整数 n n n : ⌈ n / 2 ⌉ + ⌊ n / 2 ⌋ = n \lceil n/ 2\rceil + \lfloor n / 2\rfloor = n ⌈n/2⌉+⌊n/2⌋=n 对任意实数 x ≥ 0 x \ge 0 x≥0 和整数 a , b > 0 a, b> 0 a,b>0 : ⌈ ⌈ x / a ⌉ b ⌉ = ⌈ x a b ⌉ ⌊ ⌊ x / a ⌋ b ⌋ = ⌊ x a b ⌋ ⌈ a b ⌉ ≤ a + ( b − 1 ) b ⌊ a b ⌋ ≥ a − ( b − 1 ) b \begin{aligned} \lceil \dfrac{ \lceil x / a \rceil}{b} \rceil = \lceil \dfrac{x} {ab} \rceil \\ \lfloor \dfrac{ \lfloor x / a \rfloor}{b} \rfloor = \lfloor \dfrac{x} {ab} \rfloor \\ \lceil \dfrac{a}{b} \rceil \le \dfrac{a+(b-1) } {b} \\ \lfloor \dfrac{a}{b} \rfloor \ge \dfrac{a - (b-1) } {b} \end{aligned} ⌈b⌈x/a⌉⌉=⌈abx⌉⌊b⌊x/a⌋⌋=⌊abx⌋⌈ba⌉≤ba+(b−1)⌊ba⌋≥ba−(b−1)
向下取整函数 f ( x ) = ⌊ x ⌋ f(x) = \lfloor x \rfloor f(x)=⌊x⌋ 是单调递增的,向上取整函数 f ( x ) = ⌈ x ⌉ f(x) = \lceil x \rceil f(x)=⌈x⌉ 也是单调递增的。
2.3 模运算
对任意整数 a a a 和任意正整数 n n n , a m o d n a \bmod n amodn 的值就是商 quotient a / n a /n a/n 的余数 remainder, or residue : a m o d n = a − n ⌊ a / n ⌋ (3.8) \tag{3.8} a \bmod n = a - n \lfloor a / n \rfloor amodn=a−n⌊a/n⌋(3.8) 结果有 0 ≤ a m o d n < n (3.9) \tag{3.9} 0 \le a \bmod n < n 0≤amodn<n(3.9) 给定一个整数除以另一个整数的余数的良定义后,可以方便地引入表示余数相等(即同余)的特殊记号 it is convenient to provide special notation to indicate equality of remainders ——若 ( a m o d n ) = ( b m o d n ) (a \bmod n) = (b \bmod n) (amodn)=(bmodn) ,则记 a ≡ b ( m o d n ) a \equiv b\ (\bmod\ n) a≡b (mod n) ,并称模 n n n 时 a a a 等价于 b b b a is equivalent to b, modulo n 。即, a ≡ b ( m o d n ) a \equiv b\ (\bmod n) a≡b (modn) 当且仅当 a a a 和 b b b 除以正整数 n n n 的余数相同。等价地, a ≡ b ( m o d n ) a\equiv b\ (\bmod\ n) a≡b (mod n) 当且仅当 n n n 是 b − a b -a b−a 的一个因子(或写成 n ∣ ( b − a ) n \mid (b - a) n∣(b−a) )。若模 n n n 时 a a a 不等价于 b b b ,则记 a ≡ b ( m o d n ) a \cancel{\equiv} b\ (\bmod\ n) a≡
b (mod n) 。
2.4 多项式
给定一个非负整数 d d d , n n n 的 d d d 次多项式 a polynomial in n of degree d 为「具有以下形式的一个函数 p ( n ) p(n) p(n) 」: p ( n ) = ∑ i = 0 d a i n i p(n)= \sum^d_{i = 0} a_i n^i p(n)=i=0∑daini 其中常量 a 0 , a 1 , … , a d a_0, a_1, \dots, a_d a0,a1,…,ad 是多项式的系数且 a d ≠ 0 a_d \ne 0 ad=0 。一个多项式为渐近正的、当且仅当 a d > 0 a_d > 0 ad>0 。对于一个 d d d 次渐近正的多项式 p ( n ) p(n) p(n) ,有 p ( n ) = Θ ( n d ) p(n) = \Theta(n^d) p(n)=Θ(nd) 。
对任意实常量 a ≥ 0 a \ge 0 a≥0 ,函数 n a n^a na 单调递增;对任意实常量 a ≤ 0 a \le 0 a≤0 ,函数 n a n^a na 单调递减。若对某个常量 k k k ,有 f ( n ) = O ( n k ) f(n)= O(n^k) f(n)=O(nk) ,则称函数 f ( n ) f(n) f(n) 是多项式有界 polynomially bounded 的。
2.5 指数
对所有实数 a > 0 , m , n a > 0,\ m, n a>0, m,n ,有以下恒等式:
a 0 = 1 a 1 = a a − 1 = 1 a ( a m ) n = a m n ( a m ) n = ( a n ) m a m a n = a m + n \begin{aligned} &a^0 = 1 \\ &a^1 = a\\ &a^{-1} = \dfrac{1}{a} \\ &(a^m)^n = a^{mn} \\ &(a^m)^n = (a^n)^m \\ &a^ma^n = a^{m+n} \end{aligned} a0=1a1=aa−1=a1(am)n=amn(am)n=(an)maman=am+n 对所有 n n n 和 a ≥ 1 a\ge 1 a≥1 ,函数 a n a^n an 关于 n n n 单调递增。方便时,我们假定 0 0 = 1 0^0 = 1 00=1 。
可以通过以下事实,使多项式与指数的增长率互相关联。对所有实常量 a ( a > 1 ) , b a\ (a > 1), b a (a>1),b ,有: lim n → ∞ n b a n = 0 (3.10) \lim_{n \to \infin} \dfrac{n^b} {a^n} = 0 \tag{3.10} n→∞limannb=0(3.10)
据此可得: n b = o ( a n ) n^b = o(a^n) nb=o(an)
因此,任意底大于 1 1 1 的指数函数比任意多项式函数增长得快。
使用 e e e 来表示自然对数函数的底 2.71828 … 2.71828\dots 2.71828… ,对所有实数 x x x ,我们有: e x = 1 + x + x 2 2 ! + x 3 3 ! + ⋯ = ∑ i = 0 ∞ x i i ! (3.11) e^x = 1 + x + \dfrac{x^2}{2!} + \dfrac{x^3}{3!} +\dots = \sum^{\infin}_{i = 0} \dfrac{x^i}{i!} \tag{3.11} ex=1+x+2!x2+3!x3+⋯=i=0∑∞i!xi(3.11) 对所有实数 x x x ,我们有不等式: e x ≥ 1 + x (3.12) e^x \ge 1 + x \tag{3.12} ex≥1+x(3.12)
其中只有当 x = 0 x = 0 x=0 时等号才成立。当 ∣ x ∣ ≤ 1 |x | \le 1 ∣x∣≤1 时,我们有近似估计: 1 + x ≤ e x ≤ 1 + x + x 2 (3.13) 1 + x \le e^x \le 1 + x +x^2 \tag{3.13} 1+x≤ex≤1+x+x2(3.13) 当 x → 0 x \to 0 x→0 时,用 1 + x 1 + x 1+x 作为 e x e^x ex 的近似是相当好的: e x = 1 + x + Θ ( x 2 ) e^x = 1+ x+ \Theta(x^2) ex=1+x+Θ(x2)






2. 递归式
递归式与递归方法(如分治等)是紧密相关的,因为使用递归式可以很自然地刻画这些算法(如分治算法)的运行时间。一个递归式 recurrence 就是一个等式或不等式,它通过「在更小的输入上的函数值」来描述一个函数 A recurrence is an equation or inequality that describes a function in terms of its value on smaller inputs 。例如,在算导2.3.2节中,我们用递归式描述了 MERGE-SORT 过程的最坏情况运行时间 T ( n ) T(n) T(n) :
T ( n ) = { Θ ( 1 ) 若 n = 1 2 T ( n / 2 ) + Θ ( n ) 若 n > 1 T(n) = \begin{cases} \Theta(1) \quad &若n=1 \\ 2T(n/2) + \Theta(n) \quad &若n>1 \end{cases} T(n)={Θ(1)2T(n/2)+Θ(n)若n=1若n>1 求解可得 T ( n ) = Θ ( n log n ) T(n) = \Theta(n\log n) T(n)=Θ(nlogn) 。
递归式可以有很多形式。例如,一个递归算法可能将问题划分为规模不等的子问题,如 2 / 3 2/3 2/3 对 1 / 3 1/3 1/3 的划分。如果分解和合并步骤都是线性时间的,这样的算法会产生递归式 T ( n ) = T ( 2 n / 3 ) + T ( n / 3 ) + Θ ( n ) T(n) = T(2n/3 ) + T(n/3) + \Theta(n) T(n)=T(2n/3)+T(n/3)+Θ(n) 。
子问题的规模不必是原问题规模的一个固定比例。例如,线性查找的递归版本(练习2.1-3)仅生成一个子问题,其规模仅比原问题的规模少一个元素。每次递归调用将花费常量时间、再加上「下一层递归调用的时间」,因此递归式为 T ( n ) = T ( n − 1 ) + Θ ( 1 ) T(n) = T(n-1) + \Theta(1) T(n)=T(n−1)+Θ(1) 。
我们主要需要掌握三种求解递归式的方法,即得出算法的 Θ \Theta Θ 或 O O O 渐近界的方法:
- 代入法。我们猜测一个界,然后用数学归纳法证明这个界是正确的。
- 递归树法。将递归式转换为一棵树,其结点表示不同层次的递归调用产生的代价。然后采用边界和技术来求解递归式。
- 主方法。可求解「形如以下公式的递归式」的界。 T ( n ) = a T ( n / b ) + f ( n ) (4.2) T(n) = aT(n/b) + f(n) \tag{4.2} T(n)=aT(n/b)+f(n)(4.2) 其中 a ≥ 1 , b > 1 a \ge 1, b > 1 a≥1,b>1 , f ( n ) f(n) f(n) 是一个给定的函数。这种形式的递归式很常见,它刻画了这样一个分治算法:生成 a a a 个子问题,每个子问题的规模是原问题规模的 1 / b 1/b 1/b ,分解和合并步骤总共花费时间为 f ( n ) f(n) f(n) 。
为了使用主方法,必须要熟记三种情况,但是一旦掌握了这种方法,确定很多简单递归式的渐近界就变得很容易。在算导第四章分治策略中,就使用主方法来确定最大子数组问题和矩阵相乘问题的分治算法的运行时间,其他使用分治策略的算法也将用主方法进行分析。
我们偶尔会遇到不是等式、而是不等式的递归式,例如:
- T ( n ) ≤ 2 T ( n / 2 ) + Θ ( n ) T(n) \le 2 T(n/2) + \Theta(n) T(n)≤2T(n/2)+Θ(n) 。因为这样一种递归式仅描述了 T ( n ) T(n) T(n) 的一个上界,因此可以用大 O O O 符号、而非 Θ \Theta Θ 符号来描述其解。
- 类似地,如果不等式为 T ( n ) ≥ 2 T ( n / 2 ) + Θ ( n ) T(n) \ge 2T(n/2) + \Theta(n) T(n)≥2T(n/2)+Θ(n) ,则由于递归式只给出了 T ( n ) T(n) T(n) 的一个下界,我们应使用 Ω \Omega Ω 符号来描述其解。
递归式技术细节
在实际应用中,我们会忽略递归式声明和求解的一些技术细节。例如,如果对 n n n 个元素调用 MERGE-SORT ,当 n n n 为奇数时,两个子问题的规模分别为 ⌊ n / 2 ⌋ \lfloor n / 2\rfloor ⌊n/2⌋ 和 ⌈ n / 2 ⌉ \lceil n / 2\rceil ⌈n/2⌉ ,准确来说都不是 n / 2 n / 2 n/2 ,因为当 n n n 是奇数时, n / 2 n / 2 n/2 不是一个整数。技术上,描述 MERGE-SORT 最坏情况运行时间的准确的递归式为:
T ( n ) = { Θ ( 1 ) 若 n = 1 T ( ⌈ n / 2 ⌉ ) + T ( ⌊ n / 2 ⌋ ) + Θ ( n ) 若 n > 1 (4.3) T(n) = \begin{cases} \Theta(1) \quad &若n=1 \\ T( \lceil n / 2\rceil ) + T( \lfloor n / 2\rfloor ) + \Theta(n) \quad &若n>1 \end{cases} \tag{4.3} T(n)={Θ(1)T(⌈n/2⌉)+T(⌊n/2⌋)+Θ(n)若n=1若n>1(4.3)
边界条件是另一类我们通常忽略的细节。由于对于一个常量规模的输入,算法的运行时间为常量,因此对于足够小的 n n n ,表示算法运行时间的递归式一般为 T ( n ) = Θ ( 1 ) T(n) = \Theta(1) T(n)=Θ(1) 。因此,出于方便,我们一般忽略递归式的边界条件,假设对很小的 n n n , T ( n ) T(n) T(n) 为常量。例如,递归式 ( 4.1 ) (4.1) (4.1) 常被表示为: T ( n ) = 2 T ( n / 2 ) + Θ ( n ) (4.4) T(n) = 2T(n/2) + \Theta(n) \tag{4.4} T(n)=2T(n/2)+Θ(n)(4.4)
去掉了 n n n 很小时函数值的显式描述。原因在于,虽然改变 T ( 1 ) T(1) T(1) 的值会改变递归式的精确解,但改变幅度不会超过一个常数因子,因而函数的增长阶不会变化。
当声明、求解递归式时,我们常常忽略向下取整、向上取整及边界条件。我们先忽略这些细节,稍后再确定这些细节对结果是否有较大影响。通常影响不大,但我们需要知道什么时候会影响不大。这一方面可以依靠经验来判断,另一方面,一些定理也表明,对于很多刻画分治算法的递归式,这些细节不会影响其渐近界(参见算导定理4.1)。但是这里会讨论某些细节,展示递归式求解方法的要点。
3. 用代入法求解递归式
在渐近时间复杂度分析中,常常用递归式 recurrences 刻画算法的运行时间。下面学习如何求解递归式,并从代入法 substitution method 开始。
代入法求解递归式分为两步:
- 猜测解的形式
Guess the form of the solution; - 用数学归纳法求出解中的常数,并证明解是正确的
Use mathematical induction to find the constants and show that the solution works。
当将归纳假设应用于较小的值时,我们将猜测的解代入函数 We substitute the guessed solution for the function when applying the inductive hypothesis to smaller values(就是在一个归纳假设下进行归纳证明!),因此得名为“代入法”。这种方法很强大,但我们必须能猜出解的形式,以便将其代入。
我们可以用代入法为递归式建立上界或下界。例如,我们确定下面递归式的上界:
T ( n ) = 2 T ( ⌊ n / 2 ⌋ ) + n (4.19) T(n) = 2T( \lfloor n / 2 \rfloor ) + n\tag{4.19} T(n)=2T(⌊n/2⌋)+n(4.19)
该递归式与递归式 ( 4.3 ) , ( 4.4 ) (4.3),(4.4) (4.3),(4.4) 相似。我们猜测其解为 T ( n ) = O ( n log n ) T(n) = O(n\log n) T(n)=O(nlogn) 。代入法要求证明:恰当选择正常数 c > 0 c > 0 c>0 ,可有 T ( n ) ≤ c n log n T(n) \le c n \log n T(n)≤cnlogn 。首先假定此上界对所有正数 m < n m < n m<n 都成立,特别是对于 m = ⌊ n / 2 ⌋ m = \lfloor n / 2\rfloor m=⌊n/2⌋ ,有 T ( ⌊ n / 2 ⌋ ) ≤ c ⌊ n / 2 ⌋ log ( ⌊ n / 2 ⌋ ) T(\lfloor n / 2\rfloor) \le c \lfloor n /2 \rfloor \log( \lfloor n / 2\rfloor) T(⌊n/2⌋)≤c⌊n/2⌋log(⌊n/2⌋) 。将其代入递归式,得到:
T ( n ) ≤ 2 ( c ⌊ n / 2 ⌋ log ( ⌊ n / 2 ⌋ ) ) + n ≤ c n log ( n / 2 ) + n = c n log n − c n log 2 + n = c n log n − c n + n ≤ c n log n T(n) \le 2 ( c\ \lfloor n / 2\rfloor \log ( \lfloor n / 2\rfloor )) +n \le cn \log (n / 2) + n\\ = cn\log n - cn\log 2 + n \\ = cn\log n - cn + n \le cn \log n T(n)≤2(c ⌊n/2⌋log(⌊n/2⌋))+n≤cnlog(n/2)+n=cnlogn−cnlog2+n=cnlogn−cn+n≤cnlogn 其中,只要 c ≥ 1 c \ge 1 c≥1 ,最后一步都会成立。
处理边界
数学归纳法要求我们证明解在边界条件下也成立。为证明这一点,我们通常证明对于归纳证明,边界条件适合作为基本情况。对递归式 ( 4.19 ) (4.19) (4.19) 我们必须证明,通过选择足够大的常数 c c c ,可以使得上界 T ( n ) ≤ c n log n T(n) \le cn \log n T(n)≤cnlogn 对边界条件也成立。这一要求有时可能引起问题。例如,为了方便讨论,假设 T ( 1 ) = 1 T(1) = 1 T(1)=1 是递归式唯一的边界条件。对 n = 1 n = 1 n=1 ,边界条件 T ( n ) ≤ c n log n T(n) \le cn\log n T(n)≤cnlogn 推导出 T ( 1 ) ≤ c × 1 log 1 = 0 T(1) \le c \times 1 \log 1 = 0 T(1)≤c×1log1=0 ,与 T ( 1 ) = 1 T(1) = 1 T(1)=1 矛盾。因此,我们的归纳证明的基本情况不成立。
我们稍微多付出一点努力,就可以克服这个障碍,对特定的边界条件证明归纳假设成立。例如,在递归式 ( 4.19 ) (4.19) (4.19) 中,渐近符号仅要求我们对 n ≥ n 0 n \ge n_0 n≥n0 证明 T ( n ) ≤ c n log n T(n) \le cn \log n T(n)≤cnlogn ,其中 n 0 n_0 n0 是我们可以自己选择 we get to choose 的常数,我们可以充分利用这一点。我们保留麻烦的边界条件 T ( 1 ) T(1) T(1) ,但将其从归纳证明中移除。为了做到这一点,首先观察到对于 n > 3 n > 3 n>3 ,递归式并不直接依赖 T ( 1 ) T(1) T(1) 。因此,将归纳证明中的基本情况 T ( 1 ) T(1) T(1) 替换为 T ( 2 ) , T ( 3 ) T(2), T(3) T(2),T(3) ,并令 n 0 = 2 n_0 = 2 n0=2 。注意,我们将递归式的基本情况 ( n = 1 ) (n = 1) (n=1) 和归纳证明的基本情况 ( n = 2 and n = 3 ) (n =2\ \textrm{and}\ n=3) (n=2 and n=3) 区分开来了。由于 T ( 1 ) = 1 T(1) = 1 T(1)=1 ,从递归式推导出 T ( 2 ) = 4 , T ( 3 ) = 5 T(2) = 4, T(3) = 5 T(2)=4,T(3)=5 。现在可以完成归纳证明:对某个常数 c ≥ 1 c \ge 1 c≥1 , T ( n ) ≤ c n log n T(n) \le c n \log n T(n)≤cnlogn ,方法是选择足够大的 c c c ,满足 T ( 2 ) ≤ c 2 log 2 T(2) \le c 2 \log 2 T(2)≤c2log2 和 T ( 3 ) ≤ c 3 log 3 T(3) \le c 3 \log 3 T(3)≤c3log3 。事实上,任何 c ≥ 2 c \ge 2 c≥2 都能保证 n = 2 , n = 3 n = 2, n = 3 n=2,n=3 的基本情况成立。对于我们所要讨论的大多数递归式来说,扩展边界条件使归纳假设对较小的 n n n 成立,是一种简单直接的方法,我们将不再总是显式说明这方面的细节。
做出好的猜测
遗憾的是,并不存在通用的方法来猜测递归式的正确解。猜测解要靠经验,偶尔还需要创造力。幸运的是,我们可以使用一些启发式方法、帮助自己成为一个好的猜测者。也可以使用递归树来做出好的猜测,在算法导论4.4节看到这一方法。
如果要求解的递归式与曾见到的递归式相似,那么猜测一个类似的解是合理的。例如,考虑如下递归式: T ( n ) = 2 T ( ⌊ n / 2 ⌋ + 17 ) + n T(n) = 2T( \lfloor n / 2\rfloor + 17) + n T(n)=2T(⌊n/2⌋+17)+n 看起来很困难,因为在等式右边 T T T 的参数中增加了 17 17 17 。但直观上,增加的这一项不会显著影响递归式的解。当 n n n 较大时, ⌊ n / 2 ⌋ \lfloor n / 2\rfloor ⌊n/2⌋ 和 ⌊ n / 2 ⌋ + 17 \lfloor n / 2 \rfloor + 17 ⌊n/2⌋+17 的差距不大:都是接近 n n n 的一半。因此,我们猜测 T ( n ) = O ( n log n ) T(n) = O(n\log n) T(n)=O(nlogn) ,可以使用代入法验证这个猜测是正确的(见算导练习4.3-6)。
另一种做出好的猜测的方法是,先证明递归式较松的上界和下界,然后缩小不确定的范围。例如,对递归式 ( 4.19 ) (4.19) (4.19) ,我们可以从下界 T ( n ) = Ω ( n ) T(n) = \Omega(n) T(n)=Ω(n) 开始,因为递归式中包含 n n n 这一项,还可以证明一个初始上界 T ( n ) = O ( n 2 ) T(n) = O(n^2) T(n)=O(n2) 。然后,我们可以逐渐降低上界、提升下界,直到收敛到渐近紧确界 T ( n ) = Θ ( n log n ) T(n) = \Theta(n\log n) T(n)=Θ(nlogn) 。
微妙的细节
有时我们可能正确猜出了递归式解的渐近界,但莫名其妙地在归纳证明时失败了。问题常常出在归纳假设不够强,无法证出准确的界。当遇到这种障碍时,如果修改猜测,将它减去一个低阶的项,数学证明常常能顺利进行。
考虑如下递归式: T ( n ) = T ( ⌊ n / 2 ⌋ ) + T ( ⌈ n / 2 ⌉ ) + 1 T(n) = T( \lfloor n / 2 \rfloor) + T( \lceil n / 2\rceil ) + 1 T(n)=T(⌊n/2⌋)+T(⌈n/2⌉)+1 我们猜测 T ( n ) = O ( n ) T(n)= O(n) T(n)=O(n),并尝试证明对某个恰当选出的常数 c c c , T ( n ) ≤ c n T(n) \le cn T(n)≤cn 成立。将我们的猜测代入递归式,得到: T ( n ) ≤ c ⌊ n / 2 ⌋ + c ⌈ n / 2 ⌉ + 1 = c n + 1 T(n) \le c\lfloor n / 2 \rfloor + c \lceil n / 2\rceil + 1 = cn + 1 T(n)≤c⌊n/2⌋+c⌈n/2⌉+1=cn+1
这并不意味着,对任意 c c c 都有 T ( n ) ≤ c n T(n) \le cn T(n)≤cn 。我们可能忍不住尝试猜测一个更大的界,比如 T ( n ) = O ( n 2 ) T(n) = O(n^2) T(n)=O(n2) ,虽然从这个猜测也能推出结果,但原来的猜测 T ( n ) = O ( n ) T(n) = O(n) T(n)=O(n) 是正确的。然而为了证明它是正确的,我们必须做出更强的归纳假设。
直接上,我们的猜测是解决正确的:只差一个常数 1 1 1 ,一个低阶项。但是,除非我们证明与归纳假设严格一致的形式,否则数学归纳法还是会失败。克服这个困难的方法是,从先前的猜测中减去一个低阶项。新的猜测为 T ( n ) ≤ c n − d T(n) \le cn - d T(n)≤cn−d , d d d 是大于等于 0 0 0 的一个常数。我们现在有:
T ( n ) ≤ ( c ⌊ n / 2 ⌋ − d ) + ( c ⌈ n / 2 ⌉ − d ) + 1 = c n − 2 d + 1 ≤ c n − d T(n) \le (c \lfloor n / 2 \rfloor - d) + (c \lceil n / 2\rceil - d) + 1 \\ = cn - 2d + 1 \le cn - d T(n)≤(c⌊n/2⌋−d)+(c⌈n/2⌉−d)+1=cn−2d+1≤cn−d 只要 d ≥ 1 d \ge 1 d≥1 ,此式就成立。与以前一样,我们必须选择足够大的 c c c 来处理边界条件。
你可能发现,减去一个低阶项的想法与直觉是相悖的。毕竟,如果证明上界失败了,就应该将猜测增加、而不是减少,更松的界难道不是更容易证明吗?不一定!当利用归纳法证明一个上界时,实际上证明一个更弱的上界可能会更困难一些,因为为了证明一个更弱的上界,我们在归纳证明中也必须使用同样更弱的界。在当前的例子中,当递归式包含超过一个递归项时,将猜测的界减去一个递归项,意味着每次对每个递归项都减去一个低阶项。在上例中,我们减去常数 d d d 两次,一次是对 T ( ⌊ n / 2 ⌋ T( \lfloor n / 2 \rfloor T(⌊n/2⌋ 项,另一次是对 T ( ⌈ n / 2 ⌉ T( \lceil n / 2 \rceil T(⌈n/2⌉ 项。我们以不等式 T ( n ) ≤ c n − 2 d + 1 T(n) \le cn - 2d + 1 T(n)≤cn−2d+1 结束,可以很容易地找到一个 d d d 值,使得 c n − 2 d + 1 cn - 2d + 1 cn−2d+1 小于等于 c n − d cn - d cn−d 。
避免陷阱
使用渐近符号很容易出错。例如,在递归式 ( 4.19 ) (4.19) (4.19) 中,我们可能错误地“证明” T ( n ) = O ( n ) T(n)= O(n) T(n)=O(n) :猜测 T ( n ) ≤ c n T(n) \le cn T(n)≤cn ,并论证: T ( n ) ≤ 2 ( c ⌊ n / 2 ⌋ ) + n ≤ c n + n = O ( n ) T(n) \le 2 (c \lfloor n / 2\rfloor) + n \le cn + n = O(n) T(n)≤2(c⌊n/2⌋)+n≤cn+n=O(n) 因为 c c c 是常数。错误在于我们并未证出「与归纳假设严格一致的格式 the exact form of the inductive hypothesis 」,即 T ( n ) ≤ c n T(n) \le cn T(n)≤cn 。因此,当要证明 T ( n ) = O ( n ) T(n) = O(n) T(n)=O(n) 时,需要显式地证出 T ( n ) ≤ c n T(n) \le cn T(n)≤cn 。
改变常量
有时,一个小的代数运算可以将一个未知的递归式,变为你所熟悉的形式。例如,考虑如下递归式: T ( n ) = 2 T ( ⌊ n ⌋ ) + log n T(n) = 2T( \lfloor \sqrt{n} \rfloor) + \log n T(n)=2T(⌊n⌋)+logn 它看起来很困难。但我们可以通过改变变量来简化它。为方便起见,我们不必担心值的舍入误差问题,只考虑 n \sqrt{n} n 是整数的情形即可。令 m = log n m = \log n m=logn ,得到: T ( 2 m ) = 2 T ( 2 m / 2 ) + m T(2^m)=2T ( 2^{m/2}) +m T(2m)=2T(2m/2)+m
现在重命名 S ( m ) = T ( 2 m ) S(m) = T(2^m) S(m)=T(2m) ,得到新的递归式: S ( m ) = 2 S ( m / 2 ) + m S(m) = 2S(m / 2) + m S(m)=2S(m/2)+m 它与递归式 ( 4.19 ) (4.19) (4.19) 非常像。这个新的递归式确实与 ( 4.19 ) (4.19) (4.19) 具有相同的解: S ( m ) = O ( m log m ) S(m) = O(m\log m) S(m)=O(mlogm) 。再从 S ( m ) S(m) S(m) 转换为 T ( n ) T(n) T(n) ,我们得到: T ( n ) = T ( 2 m ) = S ( m ) = O ( m log m ) = O ( log n log log n ) T(n) = T(2^m) = S(m) = O(m \log m) = O(\log n \log \log n) T(n)=T(2m)=S(m)=O(mlogm)=O(lognloglogn)

3. 用递归树方法求解递归式
虽然我们可以用代入法、简洁地证明一个解确实是递归式的正确解,但想出一个好的猜测可能会很困难。画出递归树 recursion tree ,如在算导2.3.2节分析归并排序的递归式时所做的那样,是设计好的猜测的一种简单而直接的方法。在递归树中,每个结点表示一个单一子问题的代价,子问题对应某次递归函数调用。我们将树中每层中的代价求和,得到每层代价,然后将所有层的代价求和,得到所有层次的递归调用的总代价。
递归树最适合用来生成好的猜测,然后即可用代入法来验证猜测是否正确。当使用递归树来生成好的猜测时,常常需要忍受一点儿“不精确” sloppiness ,因为稍后才会验证猜想是否正确。但如果在画递归树和代价求和时非常仔细,就可以用递归树直接证明解是否正确。在本节中,我们使用递归树生成好的猜测,在算导4.6节中,使用递归树直接证明主方法的基础定理。
我们以递归式 T ( n ) = 3 T ( ⌊ n / 4 ⌋ ) + Θ ( n 2 ) T(n) = 3T(\lfloor n / 4\rfloor ) + \Theta(n^2) T(n)=3T(⌊n/4⌋)+Θ(n2) 为例来看一下,如何用递归树生成一个好的猜测。首先关注如何寻找解的一个上界。因为我们知道,舍入对求解递归式通常没有影响(此处就是我们需要忍受不精确的一个例子),因此可以为递归式 T ( n ) = 3 T ( ⌊ n / 4 ⌋ ) + c n 2 T(n) = 3T( \lfloor n / 4 \rfloor) + cn^2 T(n)=3T(⌊n/4⌋)+cn2 创建一棵递归树,其中已将渐近符号改写为隐含的常数系数 c > 0 c > 0 c>0 。
图4-5显示了如何从递归式 T ( n ) = 3 T ( ⌊ n / 4 ⌋ ) + c n 2 T(n) = 3T( \lfloor n / 4\rfloor ) +cn^2 T(n)=3T(⌊n/4⌋)+cn2 构造出递归树。为方便起见,我们假定 n n n 是 4 4 4 的幂(忍受不精确的另一个例子),这样所有子问题的规模均为正数。图4-5(a)显示了 T ( n ) T(n) T(n) ,它在图4-5(b)中扩展为一棵等价的递归树。根结点中的 c n 2 cn^2 cn2 项表示在递归调用顶层的代价 the cost at the top level of recursion ,根结点的三棵子树表示规模为 n / 4 n / 4 n/4 的子问题所产生的代价 the costs incurred by the subproblems of size n/4 。图4-5 c)显示了进一步构造递归树的过程,通过将图4-5(b)中代价为 T ( n / 4 ) T(n/4) T(n/4) 的结点逐一扩展,根的三个子结点的代价为 c ( n / 4 ) 2 c(n / 4)^2 c(n/4)2 。我们继续扩展树中每个结点,将其分解为由递归式确定的组成部分 its constituent parts as determined by the recurrence 。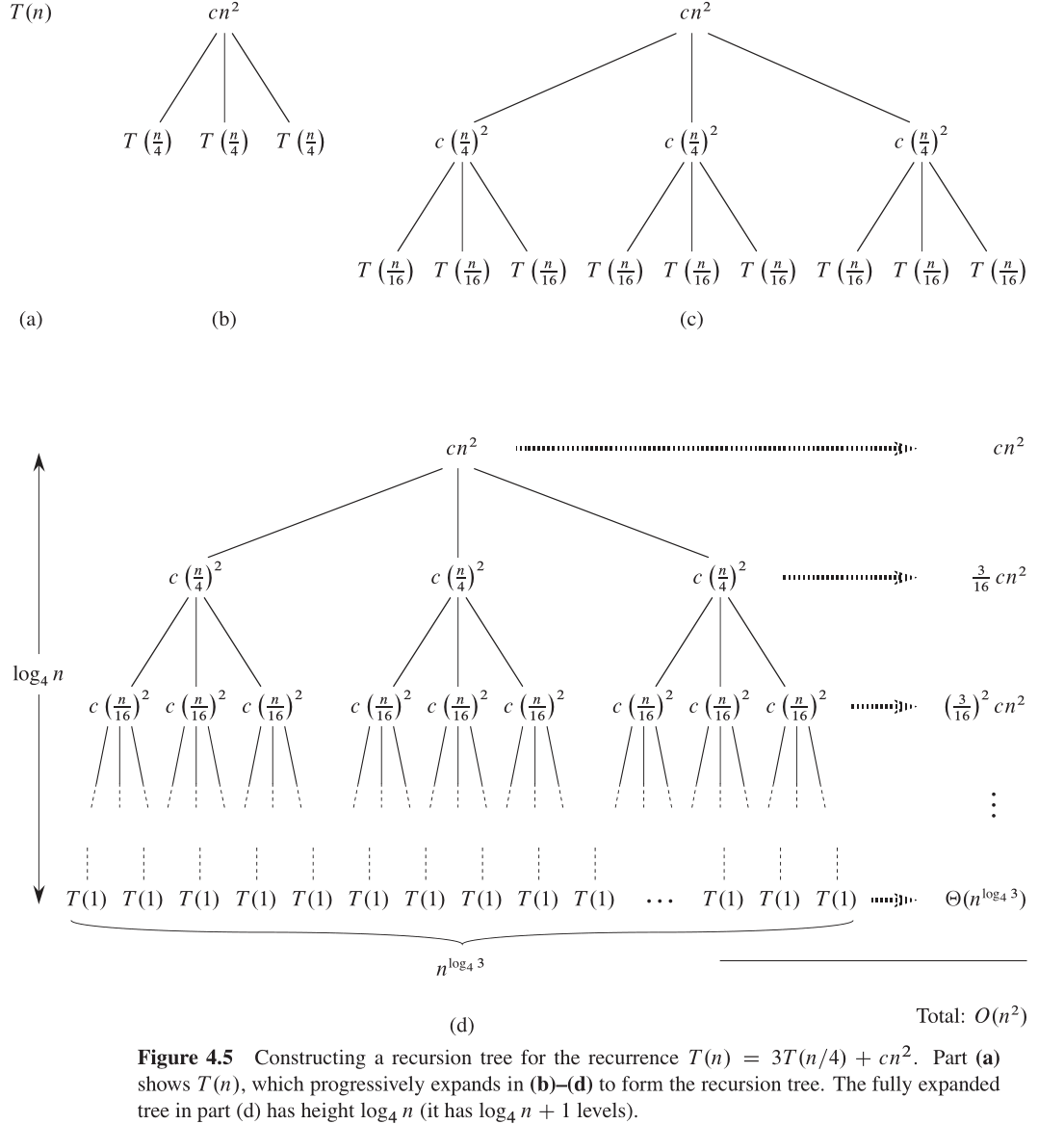
因为子问题的规模每一步减少为上一步的 1 / 4 1/4 1/4 ,所以最终必然会达到边界条件。那么根结点与规模为 1 1 1 的子问题距离多远呢?深度(从 0 0 0 开始)为 i i i 的结点对应规模为 n / 4 i n/ 4^i n/4i 的子问题,因此当 n / 4 i = 1 n / 4^i = 1 n/4i=1 或等价地 i = log 4 n i = \log_4 n i=log4n 时,子问题规模变为 1 1 1 。因此,递归树有 log 4 n + 1 \log_4 n+1 log4n+1 层(深度为 0 , 1 , 2 , … , log 4 n 0, 1, 2,\dots, \log_4 n 0,1,2,…,log4n )。
接下来确定树的每一层的代价。每层的结点数都是上一层的 3 3 3 倍,因此深度为 i i i 的结点数为 3 i 3^i 3i 。因为每一层子问题规模都是上一层的 1 / 4 1 / 4 1/4 ,所以对 i = 0 , 1 , 2 , … , log 4 n − 1 i = 0, 1, 2, \dots, \log_4n-1 i=0,1,2,…,log4n−1 ,深度为 i i i 的每个结点的代价为 c ( n / 4 i ) 2 c(n / 4^i) ^2 c(n/4i)2 。做一下乘法可得,对 i = 0 , 1 , 2 , … , log 4 n − 1 i = 0, 1, 2, \dots, \log_4n-1 i=0,1,2,…,log4n−1 ,深度为 i i i 的所有结点的代价为 3 i c ( n / 4 i ) 2 = ( 3 / 16 ) i c n 2 3^i c (n / 4^i) ^2 = (3 / 16)^i cn ^2 3ic(n/4i)2=(3/16)icn2 。树的最底层深度为 log 4 n \log_4 n log4n ,有 3 log 4 n = n log 4 3 3^{ \log_4 n} = n^{ \log_4 3} 3log4n=nlog43 个结点(对数函数互换公式),每个结点的代价为 T ( 1 ) T(1) T(1) ,总代价为 n log 4 3 T ( 1 ) n^{ \log_4 3 } T(1) nlog43T(1) 即 Θ ( n log 4 3 ) \Theta(n^{\log_4 3}) Θ(nlog43) ,因为假定 T ( 1 ) T(1) T(1) 是常量。
现在我们求所有层次的代价之和,确定整棵树的代价:
T ( n ) = c n 2 + 3 16 c n 2 + ( 3 16 ) 2 c n 2 + ⋯ + ( 3 16 ) log 4 n − 1 c n 2 + Θ ( n log 4 3 ) = ∑ i = 0 log 4 n − 1 ( 3 16 ) i c n 2 + Θ ( n log 4 3 ) = ( 3 / 16 ) log 4 n − 1 ( 3 / 16 ) − 1 c n 2 + Θ ( n log 4 3 ) \begin{aligned} T(n) &= cn^2 + \dfrac{3}{16} cn^2 + ( \dfrac{3}{16}) ^2 cn^2 + \dots + ( \dfrac{3}{16}) ^{\log_4 n -1} cn^2 + \Theta(n ^{ \log _4 3}) \\ &= \sum^{ \log_4 n - 1}_{i = 0} (\dfrac{3}{16})^i cn^2 + \Theta(n^{ \log_4 3}) \\ &=\dfrac{ (3 / 16)^{ \log_4 n } - 1} { (3 / 16) - 1} cn^2 + \Theta(n^{\log_4 3}) \end{aligned} T(n)=cn2+163cn2+(163)2cn2+⋯+(163)log4n−1cn2+Θ(nlog43)=i=0∑log4n−1(163)icn2+Θ(nlog43)=(3/16)−1(3/16)log4n−1cn2+Θ(nlog43)
最后的这个公式看起来有些凌乱,但我们可以再次充分利用一定程度的不精确,并利用无限递减几何级数作为上界。回退一步(应用算导公式 A . 6 A.6 A.6 ),我们得到:
T ( n ) = ∑ i = 0 log 4 n − 1 ( 3 16 ) i c n 2 + Θ ( n log 4 3 ) < ∑ i = 0 ∞ ( 3 16 ) i c n 2 + Θ ( n log 4 3 ) = 1 1 − ( 3 / 16 ) c n 2 + Θ ( n log 4 3 ) = 16 13 c n 2 + Θ ( n log 4 3 ) = O ( n 2 ) \begin{aligned} T(n) &= \sum^{ \log_4 n - 1}_{i = 0} (\dfrac{3}{16})^i cn^2 + \Theta(n^{ \log_4 3}) \\ &< \sum^{\infin}_{i=0} (\dfrac{3}{16}) ^i cn^2 + \Theta(n^{\log_4 3}) \\ &= \dfrac{1}{1 - (3 / 16)} cn^2 + \Theta(n^{\log_4 3}) \\ &= \dfrac{16}{13} cn^2 + \Theta(n^{\log_4 3}) \\ &= O(n^2) \end{aligned} T(n)=i=0∑log4n−1(163)icn2+Θ(nlog43)<i=0∑∞(163)icn2+Θ(nlog43)=1−(3/16)1cn2+Θ(nlog43)=1316cn2+Θ(nlog43)=O(n2) 这样,对原始的递归式 T ( n ) = 3 T ( ⌊ n / 4 ⌋ ) + Θ ( n 2 ) T(n) = 3 T( \lfloor n / 4\rfloor) + \Theta(n^2) T(n)=3T(⌊n/4⌋)+Θ(n2) ,我们推导出了一个猜测 T ( n ) = O ( n 2 ) T(n) = O(n^2) T(n)=O(n2) 。在本例中, c n 2 cn^2 cn2 的系数形成了一个递减几何级数,可得出这些系数的和的一个上界——常数 16 / 13 16/13 16/13 。由于根结点对总代价的贡献为 c n 2 cn^2 cn2 ,所以根结点的代价占总代价的一个常数比例 the root contributes a constant fraction of the total cost 。换句话说,根结点的代价支配了整棵树的总代价 the cost of the root dominates the total cost of the tree 。
实际上,如果 O ( n 2 ) O(n^2) O(n2) 确实是递归式的上界(稍后就会证明这一点),那么它必然是一个紧确界。为什么?因为第一次(即最顶层?)递归调用的代价为 Θ ( n 2 ) \Theta(n^2) Θ(n2) ,因此 Ω ( n 2 ) \Omega(n^2) Ω(n2) 必然是递归式的一个下界。
现在用代入法验证猜测是正确的,即 T ( n ) = O ( n 2 ) T(n) = O(n^2) T(n)=O(n2) 是递归式 T ( n ) = 3 T ( ⌊ n / 4 ⌋ ) + Θ ( n 2 ) T(n) = 3T( \lfloor n / 4\rfloor ) + \Theta(n^2) T(n)=3T(⌊n/4⌋)+Θ(n2) 的一个上界。我们希望证明 T ( n ) ≤ d n 2 T(n) \le dn^2 T(n)≤dn2 对某个常数 d > 0 d > 0 d>0 成立。与之前一样,使用常数 c > 0 c > 0 c>0 ,我们有:
T ( n ) ≤ 3 T ( ⌊ n / 4 ⌋ ) + c n 2 ≤ 3 d ⌊ n / 4 ⌋ 2 + c n 2 ≤ 3 d ( n / 4 ) 2 + c n 2 = 3 16 d n 2 + c n 2 ≤ d n 2 \begin{aligned} T(n) &\le 3T( \lfloor n / 4\rfloor ) + cn^2 \le 3d \lfloor n / 4\rfloor ^2 + cn^2\\ &\le 3d(n /4)^2 + cn^2 = \dfrac{3}{16} dn^2 + cn^2 \le dn^2 \end{aligned} T(n)≤3T(⌊n/4⌋)+cn2≤3d⌊n/4⌋2+cn2≤3d(n/4)2+cn2=163dn2+cn2≤dn2 当 d ≥ ( 16 / 13 ) c d \ge (16/13)c d≥(16/13)c 时,最后一步推导成立。
在另一个更复杂的例子中,图4-6显示了如下递归式的递归树: T ( n ) = T ( n / 3 ) + T ( 2 n / 3 ) + O ( n ) T(n) = T(n / 3)+ T(2n/3) + O(n) T(n)=T(n/3)+T(2n/3)+O(n)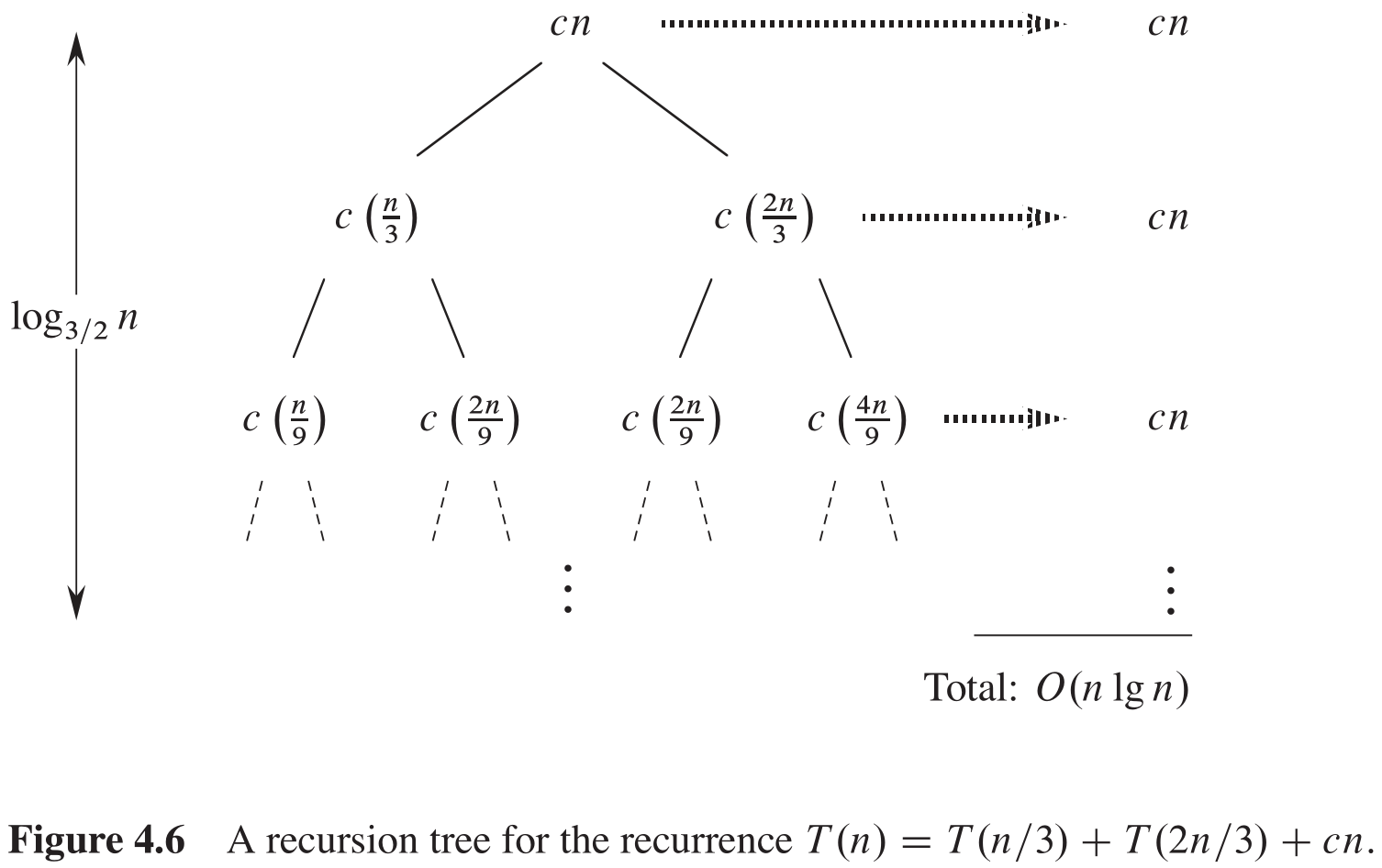
(为简单起见,再次忽略了舍入问题)与之前一样,令 c c c 表示 O ( n ) O(n) O(n) 项中的常数因子。对图中显示出的递归树的每个层次,当求代价之和时,我们发现每层的代价均为 c n cn cn 。从根到叶的最长简单路径是 n → ( 2 / 3 ) n → ( 2 / 3 ) 2 n → ⋯ → 1 n \to (2 / 3) n \to (2 / 3)^2n \to \dots \to 1 n→(2/3)n→(2/3)2n→⋯→1 。由于当 k = log 3 / 2 n k = \log_{3 / 2} n k=log3/2n 时, ( 2 / 3 ) k n = 1 (2/3)^k n = 1 (2/3)kn=1 ,因此树高为 log 3 / 2 n \log_{3/2} n log3/2n(再加 1 1 1 ?)。
直觉上,我们期望递归式的解最多是层数乘以每层的代价,即 O ( c n log 3 / 2 n ) = O ( n log n ) O(cn \log_{3/2} n) = O(n\log n) O(cnlog3/2n)=O(nlogn) 。但图4-6仅显示了递归树的顶部几层,并不是递归树中每个层次的代价都是 c n cn cn 。考虑叶结点的代价。如果递归树是一棵高度为 log 3 / 2 n \log_{3/2} n log3/2n 的完全二叉树,则叶结点的数量应为 2 log 3 / 2 n = n log 3 / 2 2 2^{\log_{3/2} n} = n ^{ \log_{3/2} 2} 2log3/2n=nlog3/22 。由于每个叶结点的代价为常数,因此所有叶结点的总代价为 Θ ( n log 3 / 2 2 ) \Theta(n^{\log_{3/2} 2}) Θ(nlog3/22) 。而且,当从根结点逐步向下走时,越来越多的内结点是缺失的。因此,递归树中靠下的层次对总代价的贡献小于 c n cn cn 。我们可以计算出所有代价的准确值,但记住我们只是希望得到一个猜测,用于代入法。我们还是忍受一些不精确,尝试证明猜测的上界 O ( n log n ) O(n\log n) O(nlogn) 是正确的。
我们确实可以用代入法,验证 O ( n log n ) O(n\log n) O(nlogn) 是递归式解的一个上界。我们来证明 T ( n ) ≤ d n log n T(n) \le dn \log n T(n)≤dnlogn ,其中 d d d 是一个适当的正常数。我们有:
T ( n ) ≤ T ( n / 3 ) + T ( 2 n / 3 ) + c n ≤ d ( n / 3 ) log ( n / 3 ) + d ( 2 n / 3 ) log ( 2 n / 3 ) + c n = ( d ( n / 3 ) log n − d ( n / 3 ) log 3 ) + ( d ( 2 n / 3 ) log n − d ( 2 n / 3 ) log ( 3 / 2 ) ) + c n = d n log n − d ( ( n / 3 ) log 3 + ( 2 n / 3 ) log ( 3 / 2 ) ) + c n = d n log n − d ( ( n / 3 ) log 3 + ( 2 n / 3 ) log 3 − ( 2 n / 3 ) log 2 ) + c n = d n log n − d n ( log 3 − 2 / 3 ) + c n ≤ d n log n \begin{aligned} T(n) &\le T(n / 3) + T(2n / 3) + cn \\ &\le d(n / 3) \log (n/3) + d(2n/ 3) \log (2n / 3) + cn \\ &= ( d(n/3) \log n - d(n / 3) \log 3) + ( d( 2n/ 3) \log n - d(2n / 3) \log (3/2) ) + cn \\ &= dn \log n - d (( n / 3) \log 3 + ( 2n/ 3) \log ( 3/ 2)) + cn \\ &= dn\log n - d (( n / 3) \log 3 + (2n/3) \log 3 - (2n/ 3) \log 2) + cn \\ &= dn\log n - dn(\log 3 - 2 / 3) + cn \\ &\le dn \log n\end{aligned} T(n)≤T(n/3)+T(2n/3)+cn≤d(n/3)log(n/3)+d(2n/3)log(2n/3)+cn=(d(n/3)logn−d(n/3)log3)+(d(2n/3)logn−d(2n/3)log(3/2))+cn=dnlogn−d((n/3)log3+(2n/3)log(3/2))+cn=dnlogn−d((n/3)log3+(2n/3)log3−(2n/3)log2)+cn=dnlogn−dn(log3−2/3)+cn≤dnlogn
只要 d ≥ c log 3 − ( 2 / 3 ) d \ge \dfrac{c}{ \log 3 - (2 / 3) } d≥log3−(2/3)c 。因此,无需对递归树的代价进行更精确的计算。
用主方法求解递归式
主方法为如下形式的递归式,提供了一种“菜谱式”的求解方法:
T ( n ) = a T ( n / b ) + f ( n ) (4.20) T(n) = aT(n / b) + f(n) \tag{4.20} T(n)=aT(n/b)+f(n)(4.20)
其中 a ≥ 1 a \ge 1 a≥1 和 b > 1 b > 1 b>1 是常数, f ( n ) f(n) f(n) 是渐近正函数。为了使用主方法,需要牢记三种情况,但随后就可以很容易地求解很多递归式,通常不需要纸和笔的帮助。
递归式 ( 4.20 ) (4.20) (4.20) 描述的是这样一种算法的运行时间:它将规模为 n n n 的问题分解为 a a a 个子问题,每个子问题规模为 n / b n / b n/b ,其中 a , b a, b a,b 都是正常数。 a a a 个子问题递归地进行求解,每个花费时间 T ( n / b ) T(n / b) T(n/b) 。函数 f ( n ) f(n) f(n) 包含了问题分解和子问题解合并的代价。例如,描述 Strassen 算法的递归式中 a = 7 , b = 2 , f ( n ) = Θ ( n 2 ) a = 7, b = 2, f(n) = \Theta(n^2) a=7,b=2,f(n)=Θ(n2) 。
从技术的正确性方面看,此递归式实际上并不是良定义 well defined 的,因为 n / b n/ b n/b 可能不是整数。但将 a a a 项 T ( n / b ) T(n / b) T(n/b) 都替换为 T ( ⌊ n / b ⌋ ) T( \lfloor n / b \rfloor) T(⌊n/b⌋) 或 T ( ⌈ n / b ⌉ ) T( \lceil n / b \rceil) T(⌈n/b⌉) 并不会影响递归式的渐近性质(之后证明这个断言)。因此,我们通常发现,当写下这种形式的分治算法的递归式时,忽略舍入问题是很方便的。
1. 主定理
主方法依赖于下面的定理:
定理4.1(主定理)令 a ≥ 1 , b > 1 a\ge 1, b>1 a≥1,b>1 是常数, f ( n ) f(n) f(n) 是一个函数, T ( n ) T(n) T(n) 是定义在非负整数上的递归式: T ( n ) = a T ( n / b ) + f ( n ) T(n) = aT(n / b) + f(n) T(n)=aT(n/b)+f(n) 其中我们将 n / b n / b n/b 解释为 ⌊ n / b ⌋ \lfloor n / b \rfloor ⌊n/b⌋ 或 ⌈ n / b ⌉ \lceil n / b \rceil ⌈n/b⌉ 。那么 T ( n ) T(n) T(n) 有如下渐近界:
- 若对某个常数 ε > 0 \varepsilon > 0 ε>0 有 f ( n ) = O ( n log b a − ε ) f(n) = O(n^{\log_b a - \varepsilon}) f(n)=O(nlogba−ε) ,则 T ( n ) = Θ ( n log b a ) T(n) = \Theta(n^{\log_b a}) T(n)=Θ(nlogba) 。
- 若 f ( n ) = Θ ( n log b a ) f(n) = \Theta(n^{\log_b a}) f(n)=Θ(nlogba) ,则有 T ( n ) = Θ ( n log b a log n ) T(n) = \Theta(n^{\log_b a} \log n) T(n)=Θ(nlogbalogn) 。
- 若对某个常数 ε > 0 \varepsilon > 0 ε>0 有 f ( n ) = Ω ( n log b a + ε ) f(n) = \Omega(n^{ \log_b a + \varepsilon } ) f(n)=Ω(nlogba+ε) ,且对某个常数 c < 1 c < 1 c<1 和所有足够大的 n n n 有 a f ( n / b ) ≤ c f ( n ) a f(n / b) \le cf(n) af(n/b)≤cf(n) ,则 T ( n ) = Θ ( f ( n ) ) T(n) = \Theta(f(n)) T(n)=Θ(f(n)) 。
在使用主定理之前,花一点时间尝试理解一下它的含义。对于三种情况的每一种,我们将函数 f ( n ) f(n) f(n) 与函数 n log b a n^{ \log_b a} nlogba 进行比较。直觉上,两个函数较大者决定了递归式的解。若函数 n log b a n^{\log_b a} nlogba 更大,如情况1,则解为 T ( n ) = Θ ( n log b a ) T(n) = \Theta(n ^{ \log_b a}) T(n)=Θ(nlogba) 。若函数 f ( n ) f(n) f(n) 更大,如情况3,则解为 T ( n ) = Θ ( f ( n ) ) T(n) = \Theta(f(n)) T(n)=Θ(f(n)) 。若两个函数大小相当,如情况2,则乘上一个对数因子,解为 T ( n ) = Θ ( n log b a log n ) = Θ ( f ( n ) log n ) T(n) = \Theta( n^{ \log_b a} \log n)= \Theta(f(n) \log n) T(n)=Θ(nlogbalogn)=Θ(f(n)logn) 。
在此直觉之外,我们需要了解一些技术细节。在第一种情况中,不是 f ( n ) f(n) f(n) 小于 n log b a n^{\log_b a} nlogba 就够了,而是要多项式意义上的小于 polynomially smaller 。也就是说, f ( n ) f(n) f(n) 必须渐近小于 n log b a n^{ \log_b a} nlogba 、且要相差一个因子 n ε n^{ \varepsilon} nε ,其中 ε \varepsilon ε 是大于 0 0 0 的常数 f(n) must be asymptotically smaller than nlogba by a factor of nε for some constant ε > 0 。在第三种情况中,不是 f ( n ) f(n) f(n) 大于 n log b a n^{ \log_b a} nlogba 就够了,而是要多项式意义的大于 polynomially larger ,而且还要满足“正则 regularity ”条件 a f ( n / b ) ≤ c f ( n ) a f(n/b) \le cf(n) af(n/b)≤cf(n) 。我们将会遇到的多项式界的函数中,多数都满足此条件 This condition is satisfied by most of the polynomially bounded functions that we shall encounter 。
注意:这三种情况并未覆盖 f ( n ) f(n) f(n) 的所有可能性。情况1和情况2之间有一定间隙, f ( n ) f(n) f(n) 可能小于 n log b a n^{ \log_b a} nlogba 但不是多项式意义上的小于。类似地,情况2和情况3之间也有一定间隙, f ( n ) f(n) f(n) 可能大于 n log b a n^{\log_b a} nlogba 但不是多项式意义上的大于。如果函数 f ( n ) f(n) f(n) 落在这两个间隙中,或者情况3中要求的正则条件不成立,就不能使用主方法来求解递归式 If the function f(n) falls into one of these gaps, or if the regularity condition in case 3 fails to hold, you cannot use the master method to solve the recurrence 。
2. 使用主方法
使用主方法很简单,我们只需确定主定理的哪种情况成立,即可得到解。我们先看下面这个例子: T ( n ) = 9 T ( n / 3 ) + n T(n) = 9T(n/3) + n T(n)=9T(n/3)+n
对于这个递归式,我们有 a = 9 , b = 3 , f ( n ) = n a = 9, b = 3, f(n) = n a=9,b=3,f(n)=n ,因此 n log b a = n log 3 9 = Θ ( n 2 ) n^{\log_b a } = n^{ \log_3 9} = \Theta(n^2) nlogba=nlog39=Θ(n2) 。由于 f ( n ) = O ( n log 3 9 − ε ) f(n) = O( n^{ \log_3 9 - \varepsilon }) f(n)=O(nlog39−ε) ,其中 ε = 1 \varepsilon = 1 ε=1 ,因此可以应用主定理的情况1,从而得到解 T ( n ) = Θ ( n 2 ) T(n) = \Theta(n^2) T(n)=Θ(n2) 。
现在考虑: T ( n ) = T ( 2 n / 3 ) + 1 T(n)= T(2n/3) + 1 T(n)=T(2n/3)+1
其中 a = 1 , b = 3 / 2 , f ( n ) = 1 a = 1, b = 3/2, f(n) = 1 a=1,b=3/2,f(n)=1 ,因此 n log b a = n log 3 / 2 1 = n 0 = 1 n^{\log_b a} = n^{ \log_{ 3/2} 1} = n^0 = 1 nlogba=nlog3/21=n0=1 。由于 f ( n ) = Θ ( n log b a ) = Θ ( 1 ) f(n) = \Theta(n^{\log_b a}) = \Theta(1) f(n)=Θ(nlogba)=Θ(1) ,因此应用情况2,从而得到解 T ( n ) = Θ ( log n ) T(n) = \Theta(\log n) T(n)=Θ(logn) 。
对于递归式: T ( n ) = 3 T ( n / 4 ) + n log n T(n) = 3T(n / 4) + n\log n T(n)=3T(n/4)+nlogn
我们有 a = 3 , b = 4 , f ( n ) = n log n a = 3, b = 4, f(n) = n\log n a=3,b=4,f(n)=nlogn ,因此 n log b a = n log 4 3 = O ( n 0.793 ) n^{ \log_b a} = n^{\log_4 3} = O(n^{0.793}) nlogba=nlog43=O(n0.793) 。由于 f ( n ) = Ω ( n log 4 3 + ε ) f(n) = \Omega(n^{ \log_4 3 + \varepsilon}) f(n)=Ω(nlog43+ε) ,其中 ε ≈ 0.2 \varepsilon \approx 0.2 ε≈0.2 ,因此如果可以证明正则条件成立,则可应用情况3。当 n n n 足够大时,对于 c = 3 / 4 c = 3/4 c=3/4 , a f ( n / b ) = 3 ( n / 4 ) log ( n / 4 ) ≤ ( 3 / 4 ) n log n = c f ( n ) af(n / b) = 3(n / 4) \log (n / 4) \le (3 / 4) n\log n = cf(n) af(n/b)=3(n/4)log(n/4)≤(3/4)nlogn=cf(n) 。因此由情况3,递归式的解为 T ( n ) = Θ ( n log n ) T(n) = \Theta(n\log n) T(n)=Θ(nlogn) 。
主方法不能用于如下递归式: T ( n ) = 2 T ( n / 2 ) + n log n T(n) = 2T(n / 2) + n\log n T(n)=2T(n/2)+nlogn
虽然这个递归式看起来有恰当的形式: a = 2 , b = 2 , f ( n ) = n log n a = 2, b = 2, f(n)= n\log n a=2,b=2,f(n)=nlogn ,以及 n log b a = n n^{\log_b a} = n nlogba=n 。我们可能错误地认为应该应用情况3,因为 f ( n ) = n log n f(n) = n\log n f(n)=nlogn 渐近大于 n log b a = n n^{\log_b a} = n nlogba=n 。问题出在它并不是多项式意义上的大于 The problem is that it is not polynomially larger(渐近大于不等同于多项式意义上的大于!)。对任意正常数 ε \varepsilon ε ,比值 f ( n ) / n log b a = ( n log n ) / n = log n f(n) / n^{ \log_b a} = (n \log n) / n = \log n f(n)/nlogba=(nlogn)/n=logn 都渐近小于 n ε n^{\varepsilon} nε 。因此,递归式落入了情况2和情况3之间的间隙(此递归式的解参见算导练习4.6-2)。或者说,对任意正常数 ε > 0 \varepsilon > 0 ε>0 , f ( n ) = n log n = Ω ( n log b a + ε ) = Ω ( n × n ε ) f(n) = n\log n = \Omega(n^{ \log_b a + \varepsilon}) = \Omega(n\times n^{\varepsilon}) f(n)=nlogn=Ω(nlogba+ε)=Ω(n×nε) 都不成立,更别说正则条件了。
我们利用主方法,求解算导4.1节和4.2节见过的递归式 ( 4.7 ) (4.7) (4.7) : T ( n ) = 2 T ( n / 2 ) + Θ ( n ) T(n) = 2T(n / 2) +\Theta(n) T(n)=2T(n/2)+Θ(n)
它刻画了最大子数组问题和归并排序分治算法的运行时间(按照通常的做法,我们忽略了递归式中基本情况的描述)。这里,我们有 a = 2 , b = 2 , f ( n ) = Θ ( n ) a = 2, b= 2, f(n)= \Theta(n) a=2,b=2,f(n)=Θ(n) ,因此 n log b a = n log 2 2 = n n^{ \log_b a} = n^{\log_2 2} = n nlogba=nlog22=n 。由于 f ( n ) = Θ ( n ) f(n) = \Theta(n) f(n)=Θ(n) ,应用情况2,于是得到解 T ( n ) = Θ ( n log n ) T(n) = \Theta(n \log n) T(n)=Θ(nlogn) 。
算导递归式 ( 4.17 ) (4.17) (4.17) : T ( n ) = 8 T ( n / 2 ) + Θ ( n 2 ) T(n) = 8T(n/2) + \Theta(n^2) T(n)=8T(n/2)+Θ(n2) 它描述了矩阵乘法问题第一个分治算法的运行时间。我们有 a = 8 , b = 2 , f ( n ) = Θ ( n 2 ) a = 8, b = 2, f(n) = \Theta(n^2) a=8,b=2,f(n)=Θ(n2) ,因此 n log b a = n log 2 8 = n 3 n^{ \log_b a} = n^{ \log_2 8} = n^3 nlogba=nlog28=n3 。由于 n 3 n^3 n3 多项式意义上大于 f ( n ) f(n) f(n)(即对某个正常数 ε = 1 \varepsilon = 1 ε=1 , f ( n ) = O ( n 3 − ε ) f(n) = O(n^{3 - \varepsilon}) f(n)=O(n3−ε)),应用情况1,解为 T ( n ) = Θ ( n 3 ) T(n) = \Theta(n^3) T(n)=Θ(n3) 。
最后考虑算导递归式 ( 4.18 ) (4.18) (4.18) : T ( n ) = 7 T ( n / 2 ) + Θ ( n 2 ) T(n) = 7T(n/2) + \Theta(n^2) T(n)=7T(n/2)+Θ(n2) 它描述了 Strassen 算法的运行时间。这里,我们有 a = 7 , b = 2 , f ( n ) = Θ ( n 2 ) a = 7, b= 2, f(n) =\Theta(n^2) a=7,b=2,f(n)=Θ(n2) ,因此 n log b a = n log 2 7 n^{\log_b a} = n^{\log_2 7} nlogba=nlog27 。将 log 2 7 \log_2 7 log27 改写为 log 7 \log 7 log7 ,由于 2.80 < log 7 < 2.81 2.80 < \log 7 < 2.81 2.80<log7<2.81 ,我们知道对 ε = 0.8 \varepsilon = 0.8 ε=0.8 ,有 f ( n ) = O ( n log 7 − ε ) f(n) = O(n^{\log 7 - \varepsilon}) f(n)=O(nlog7−ε) 。再次应用情况1,我们得到解 T ( n ) = Θ ( n log 7 ) T(n) = \Theta(n^{\log 7}) T(n)=Θ(nlog7) 。
证明主定理
算导4.6节给出了主定理(定理4.1)的证明。但如果只是为了使用主定理,可以不必理解这个证明。证明分为两个部分。第一部分分析主递归式 ( 4.20 ) (4.20) (4.20) ——为简单起见,假定 T ( n ) T(n) T(n) 仅定义在 b ( b > 1 ) b\ (b > 1) b (b>1) 的幂上,即仅对 n = 1 , b , b 2 , … n = 1, b, b^2, \dots n=1,b,b2,… 定义,这一部分给出了「为理解主定理是正确的」所需的所有直接知识。随后,第二部分显示了如何将分析扩展到所有正整数 n n n ;这一部分应用了处理向下和向上取整问题的数学技巧。
在这一节,有时会稍微滥用渐近符号,用来描述仅仅定义在 b b b 的幂上的函数的行为。回忆一下,渐近符号的定义要求对所有足够大的数都证明函数的界、而不是仅仅对 b b b 的幂。因为可以定义出「仅仅应用于集合 { b i ∣ i = 0 , 1 , 2 , … } \{ b^i \mid i = 0, 1, 2, \dots \} {bi∣i=0,1,2,…} 上、而非所有非负数上的新的渐近符号」,所以这种滥用问题不大。























有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 5
5 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)