Transformer学习笔记-注意力机制到底在做什么,Q/K/V怎么来的
Transformer学习笔记-注意力机制到底在做什么,Q/K/V怎么来的
Transformer论文中使用了注意力Attention机制,注意力Attention机制的最核心的公式为: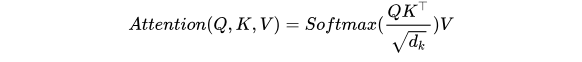
向量点乘
从理解这个公式开始: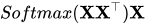

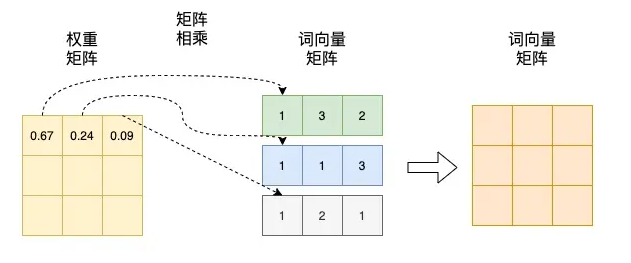
这个矩阵中,每行为一个词的词向量。矩阵与自身的转置相乘,生成了目标矩阵,目标矩阵其实就是一个词的词向量与各个词的词向量的相似度。
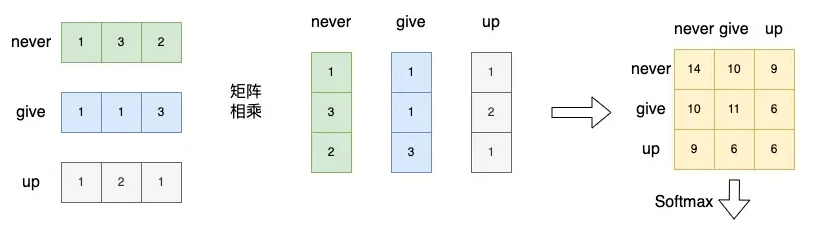
Softmax的作用是对向量做归一化,那么就是对相似度的归一化,得到了一个归一化之后的权重矩阵,矩阵中,某个值的权重越大,表示相似度越高。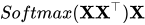
,将得到的归一化的权重矩阵与词向量矩阵相乘。权重矩阵中某一行分别与词向量的一列相乘,词向量矩阵的一列其实代表着不同词的某一维度。经过这样一个矩阵相乘,相当于一个加权求和的过程,得到结果词向量是经过加权求和之后的新表示,而权重矩阵是经过相似度和归一化计算得到的。
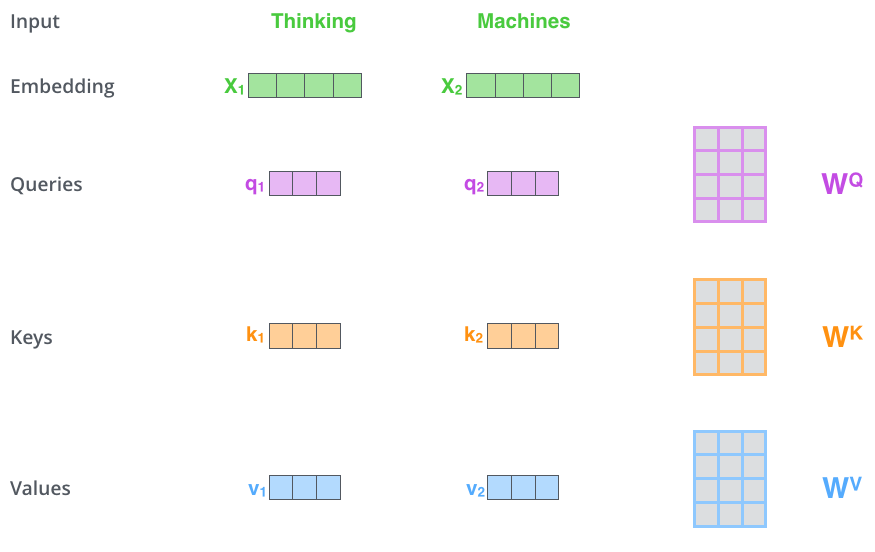
Q、K、V
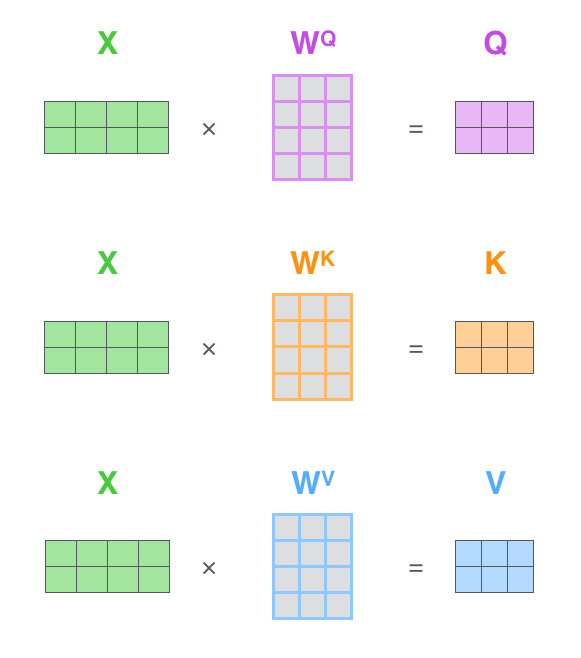
Q为Query、K为Key、V为Value。Q、K、V是从哪儿来的呢?Q、K、V其实都是从同样的输入矩阵X线性变换而来的。我们可以简单理解成:
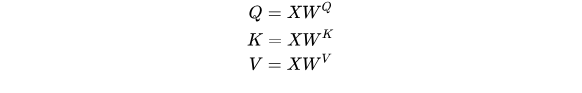
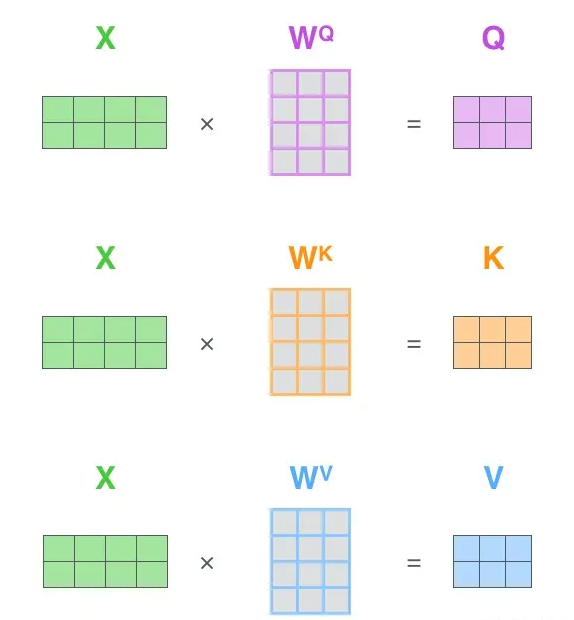
W^Q, W^K, W^V是三个可训练的参数矩阵。输入矩阵X
分别相乘,生成Q、K和V,相当于经历了一次线性变换。Attention不直接使用X,而是使用经过矩阵乘法生成的这三个矩阵,因为使用三个可训练的参数矩阵,可增强模型的拟合能力。
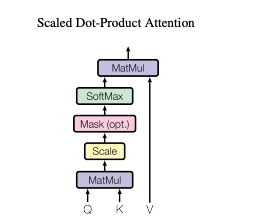


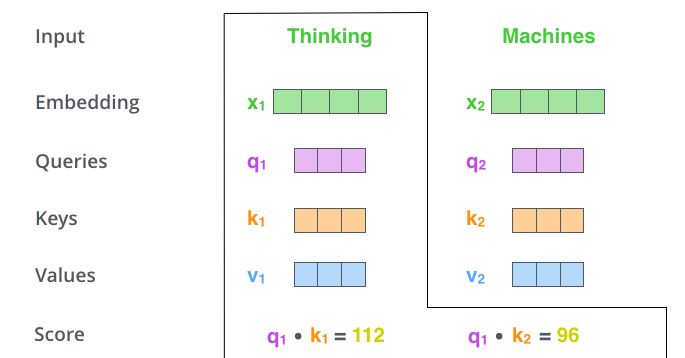
第二步是进行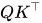 计算,得到相似度。
计算,得到相似度。
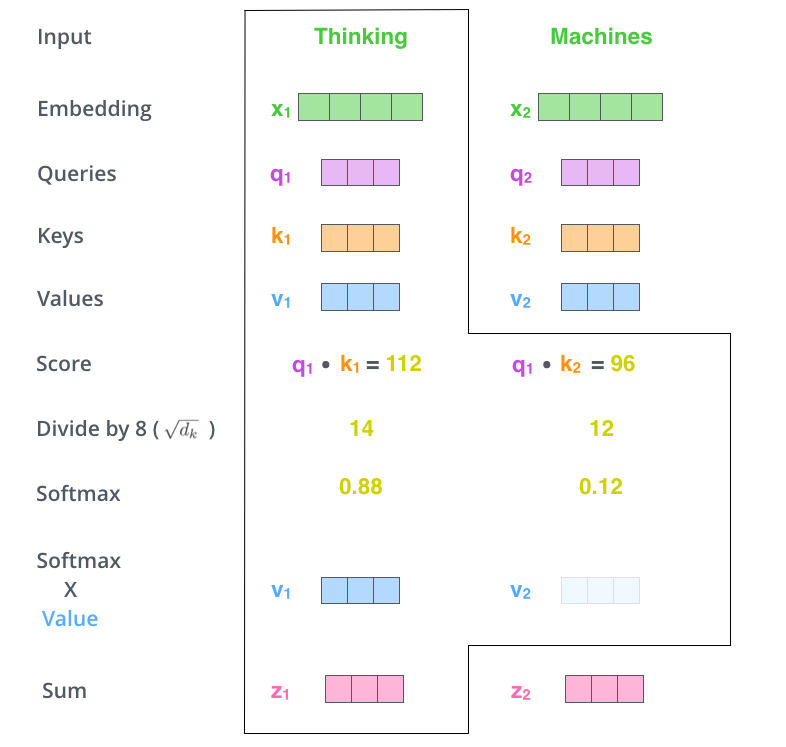
第三步,将刚得到的相似度除以
,再进行Softmax。经过Softmax的归一化后,每个值是一个大于0小于1的权重系数,且总和为0,这个结果可以被理解成一个权重矩阵。
第四步是使用刚得到的权重矩阵,与V相乘,计算加权求和。

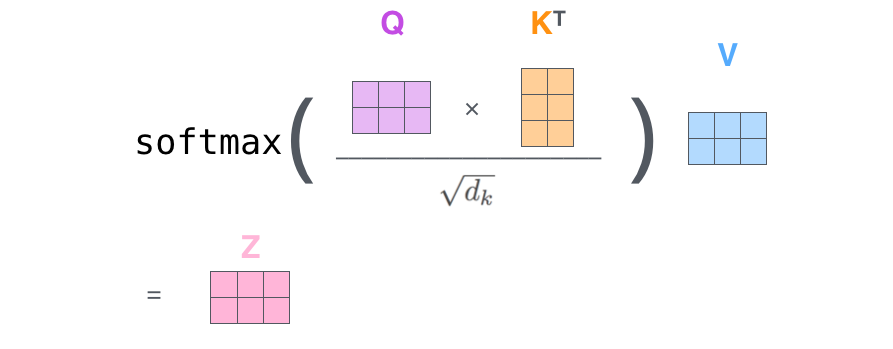
多头注意力

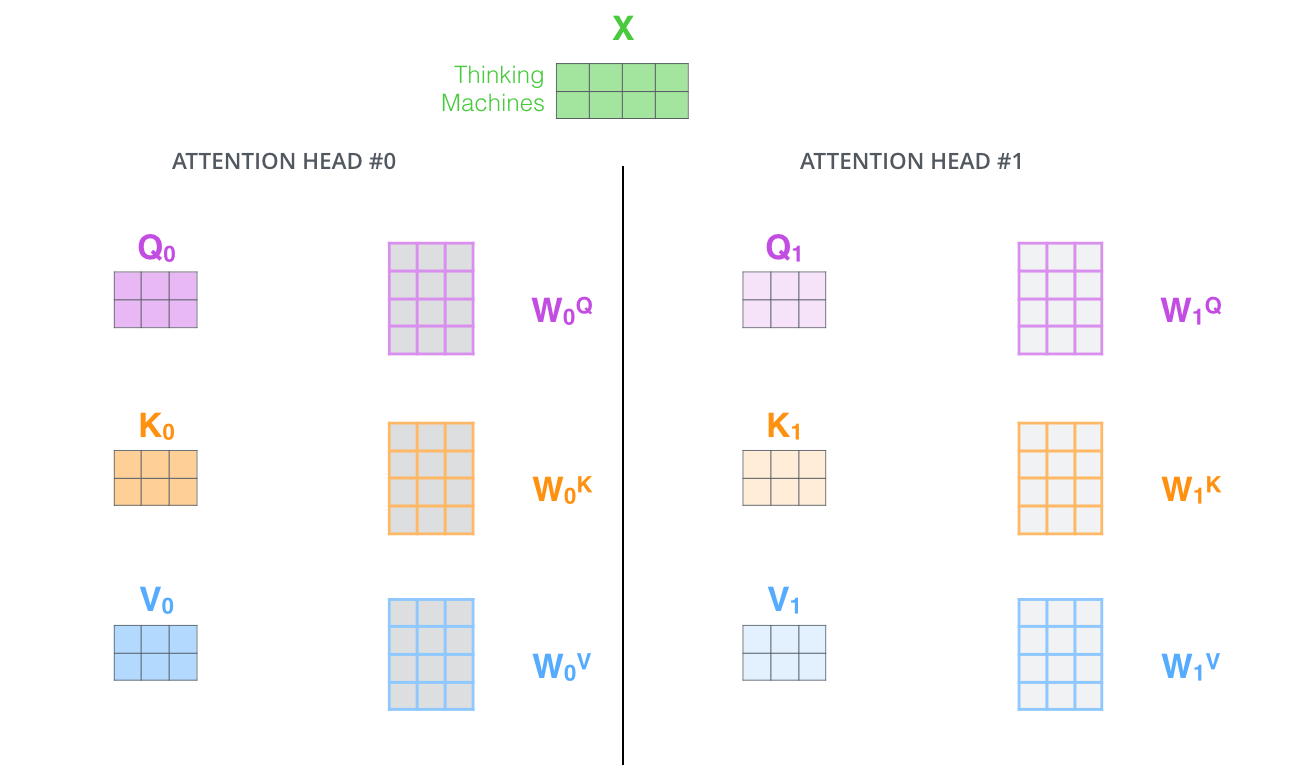
比如我们定义8组参数,同样的输入,将得到8个不同的输出。
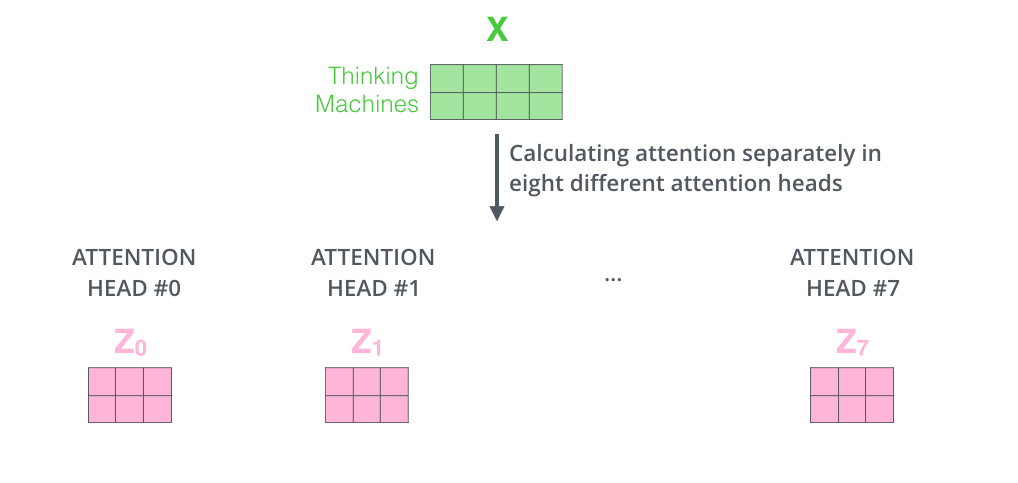
在输出到下一层前,我们需要将8个输出拼接到一起,乘以矩阵W^O,将维度降低回我们想要的维度。
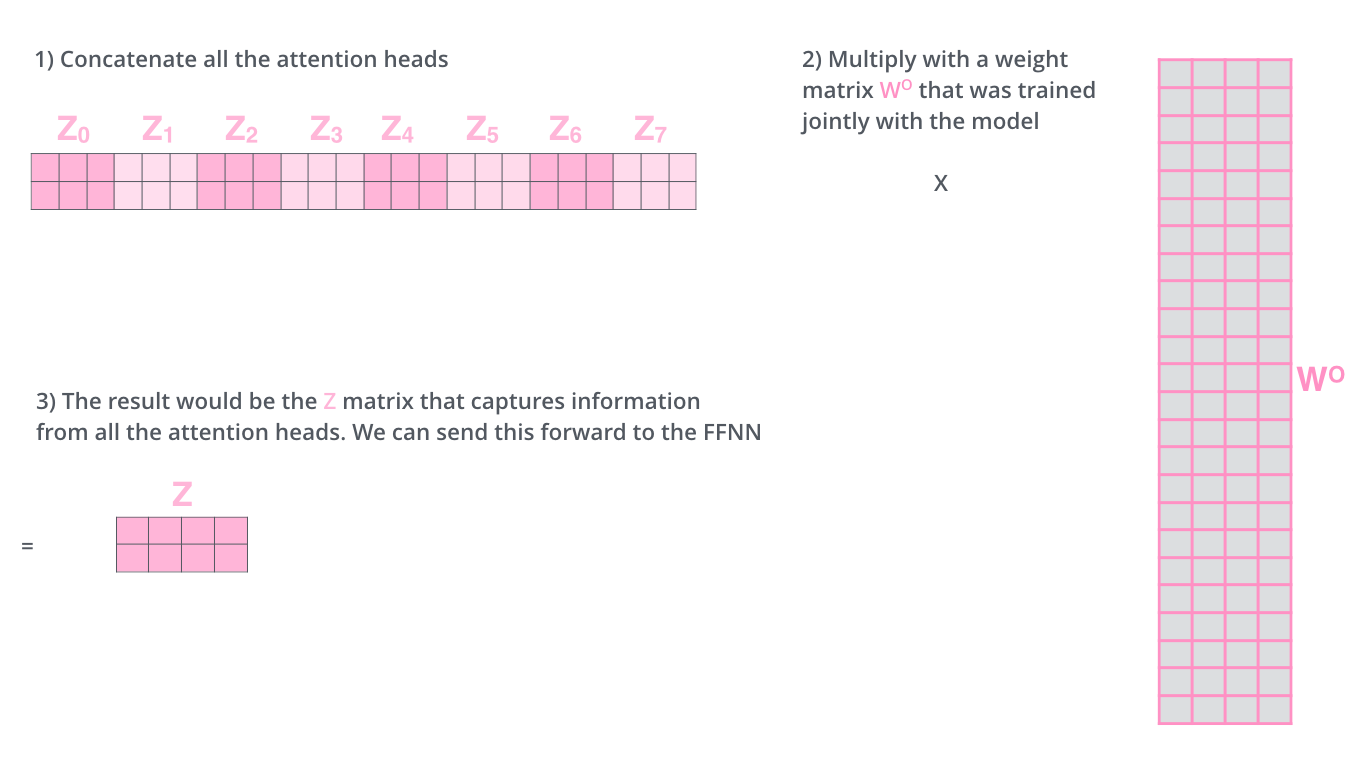
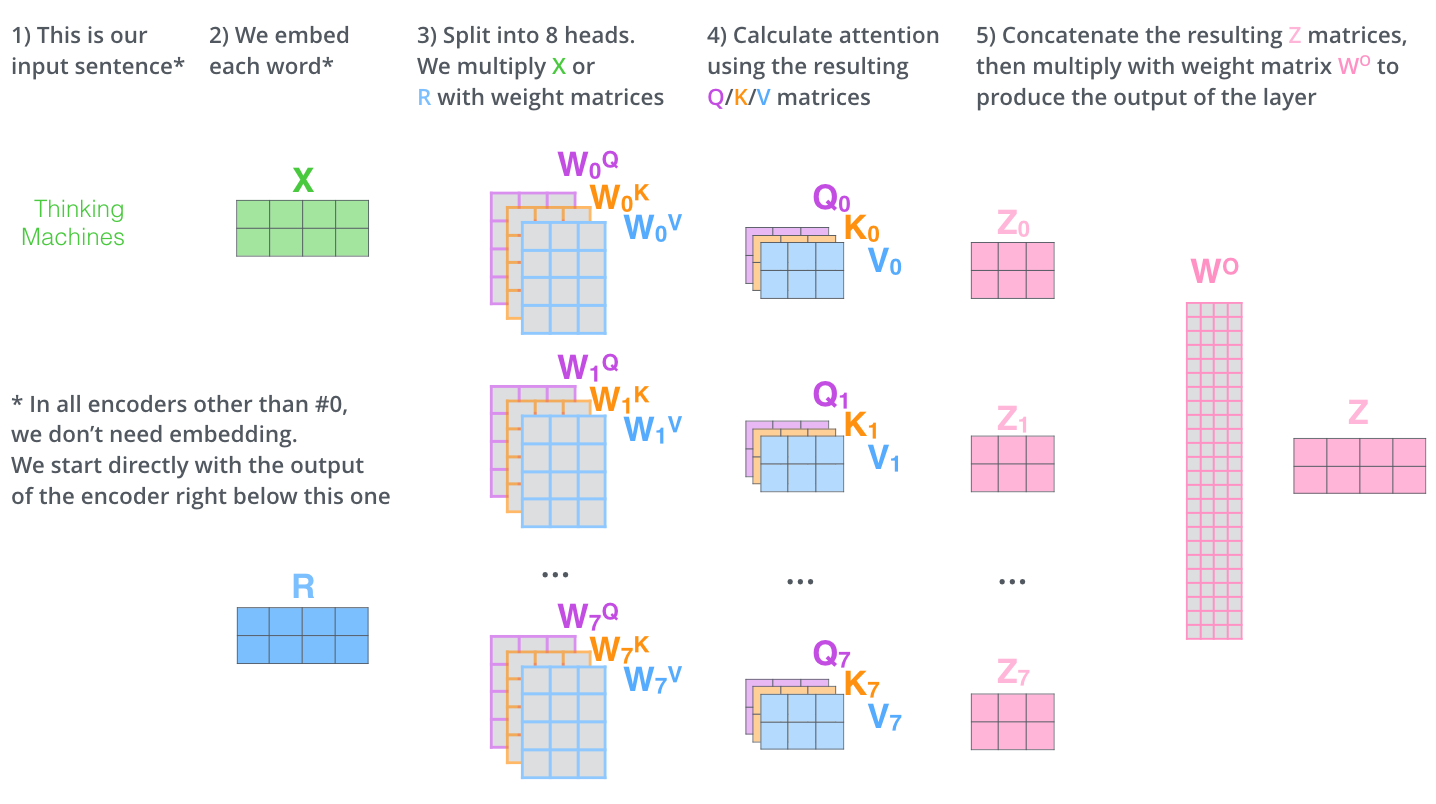
多头注意力的计算过程如下图所示。对于下图中的第2)步,当前为第一层时,直接对输入词进行编码,生成词向量X;当前为后续层时,直接使用上一层输出。
经典的attention is all you need论文解释使用的案例,表达attention相关性。

多头即h个QKV的并行计算
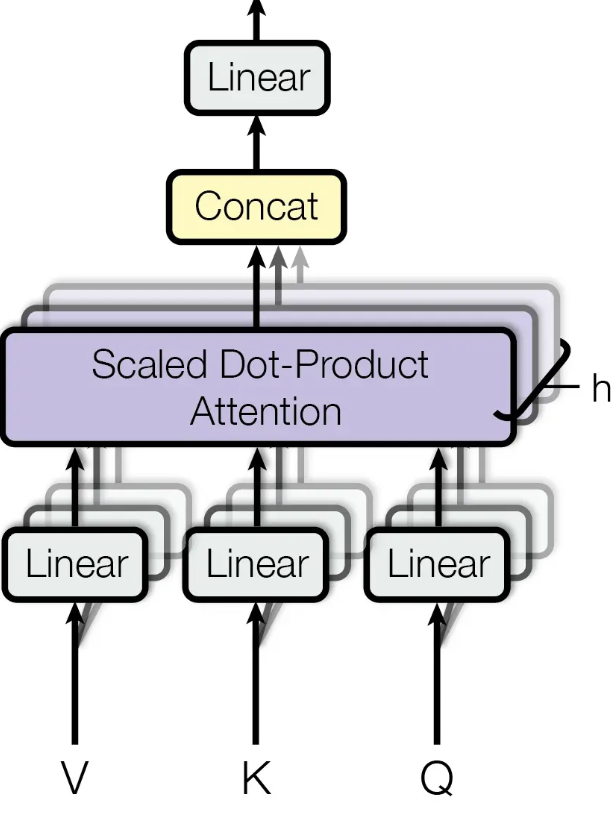
参考:
https://www.zhihu.com/tardis/zm/art/414084879?source_id=1005

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)