[论文与源码解读]DexPoint项目拆解
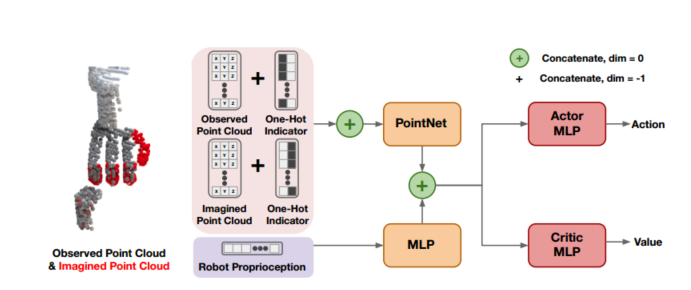
从图中可以看到,点云输入后有一层PointNet,机器人状态后有一层MLP,文章似乎并没有对这部分详细介绍,我个人的理解是PointNet的核心功能是分割和特征提取,MLP就是一层网络结构,整个网络结构输入端将点云和机器人状态隔开,主干网络采用PPO,图中的Actor-Critic是强化学习中常见的网络结构,其中典型的就是PPO。sim2real:本文中训练的时候用了一种罐子和一种形状的门把手,在
目录
引言
最近在研究以点云为输入的端到端强化学习,发现很多大佬在做,并且在多个机器人顶级会议上发表了文章并且将代码开源,有时候看这种论文和项目对小白来说是比较困难的,所以开一篇专题对他们的工作进行拆解和解读.
先上项目源链接:https://github.com/yzqin/dexpoint-release.git
作者b站:Mango-Man的个人空间-Mango-Man个人主页-哔哩哔哩视频
论文,效果,源码都在里面了,不得不说顶级课题组的工作内容就是规整
本博客仅做为自己更好学习理解的分享,无任何商业目的,如有任何侵权请联系我删除.
论文解读
在这里就不搞论文翻译那套了,前面一些内容是作者为什么要用端到端,以及这种方法的优势等等,还有马尔可夫决策这些基础知识,博客尽可能把核心点提炼出来
论文主要内容概括:一套以点云作为输入,直接控制灵巧手的端到端强化学习框架,在这篇论文中作者使用这套框架实现了灵巧手抓取,以及灵巧手开门两项任务
我理解的关键内容:
- 点云到action的训练框架
- 灵巧手以及工件的点云补全
- 接近,接触,抬升的加权奖励设计
硬件环境
实验硬件环境:灵巧手,工件,以及第三方视角的相机
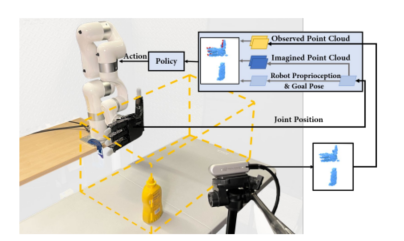
模型任务
本篇论文是先在sim仿真环境中训练灵巧手抓取并抬升一个罐子,以及转动门把手并推开门这两个任务(后续还有DexArt是用相同的端到端框架去完成了铰链物体的一系列任务)
sim2real:本文中训练的时候用了一种罐子和一种形状的门把手,在实际执行的时候用了另外两种形状的罐子和另外两种形状的门把手
强化学习模型
搭建强化学习训练工程有以下几个部分,也和论文中的写作框架类似
-
模型输入设计:即状态state,观测空间
(1):观测点云
(2):补全的点云
(3):包含关节位置和末端位置的机器人状态
从图中可以看到,点云输入后有一层PointNet,机器人状态后有一层MLP,文章似乎并没有对这部分详细介绍,我个人的理解是PointNet的核心功能是分割和特征提取,MLP就是一层网络结构,整个网络结构输入端将点云和机器人状态隔开,主干网络采用PPO,图中的Actor-Critic是强化学习中常见的网络结构,其中典型的就是PPO
-
动作空间设计:即动作action
本文动作空间为连续的6-DOF臂+16-DOF的手共22个自由度,也就可以理解为长度为22的一维向量
-
奖励设计:即马尔可夫奖励Reward
整个动作流程分为两个部分,抓取和抬升
1.抓取奖励(到达奖励+接触奖励):计算每根手指到物体的距离,离得越近奖励越大;拇指接触物体且其他手指接触大于等于2给予奖励,这样的设计可以达成至少三指抓取的效果
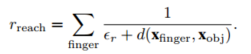
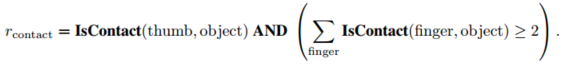
2.抬升奖励(接触奖励 * 抬升奖励):接触奖励可能为0或1,必须接触才能抬升,所以这里用乘法
抬升奖励,计算物体和目标位置的距离给予奖励,rreach形式类似,这里没有将抬升奖励详细描述
![]()
最后将这些奖励进行加权,奖励设计完成
![]()
训练与实验
最终结果在这就不赘述了,作者公布了训练曲线以及抓取效果,成功率等等.个人认为比较重要的是训练过程中点云的预处理环节
点云处理
- 选定ROI区域,只记录关注区域的点云
- 均匀下采样至512个点,其核心原因是网络的输入数据维度必须是相同的
- 在仿真环境的点云中添加白噪声,这里是为了sim2real效果
- 转换点云坐标系,方便网络理解
源码解读:
先来看一下文件树,可见核心内容在dexpoint文件夹中,解读开源项目主要还是为了借鉴自己需要的部分,所以一开始不能面面俱到.需要注意的是dexpoint项目中包含了环境定义,环境定义中包含了动作action执行后和环境互动的奖励,不包含训练代码和强化学习网络,这两个在dexart项目中.
dexpoint-release/
├── .editorconfig
├── .gitignore
├── CITATION.cff
├── LICENSE
├── README.md
├── pyproject.toml
├── setup.py
├── docker/
│ └── Dockerfile # 用于创建 Docker 镜像的配置文件,用于服务器无界面训练
├── dexpoint/
│ ├── __init__.py
│ ├── env/ # 包含项目的环境相关代码
│ │ ├── rl_env/ # 强化学习环境相关代码
│ │ │ └── base.py # 强化学习环境基类,定义了环境的基本接口和方法
│ │ └── sim_env/ # 模拟环境相关代码
│ │ └── constructor.py # 创建引擎和渲染器,添加默认场景灯光,下载模型文件
│ ├── kinematics/ # 运动学相关代码
│ │ └── kinematics_helper.py # 运动学辅助类,用于计算机器人的运动学信息
│ ├── real_world/ # 与现实世界交互的代码
│ └── utils/ # 工具函数和辅助类
│ ├── camera_utils.py # 处理相机纹理和生成想象点云的工具函数
│ ├── common_robot_utils.py # 生成机器人信息,加载和修改机器人模型的工具函数
│ ├── egad_object_utils.py # 加载 EGAD 数据集物体的工具函数
│ ├── model_utils.py # 构建机器人模型的工具函数,如自由根和球关节
│ ├── shapenet_utils.py # 加载 ShapeNet 数据集物体的工具函数
│ └── ycb_object_utils.py # 加载 YCB 数据集物体的工具函数
├── assets/ # 存放机器人和物体模型等静态文件
│ ├── .gitignore
│ ├── egad/
│ ├── misc/
│ ├── robot/ # 包含机器人的模型文件和配置信息
│ ├── shapenet/
│ │ ├── 02876657.txt
│ │ └── 02946921.txt
│ └── ycb/
├── docs/
│ └── teaser.png
└── example/ # 学习如何使用 DexPoint 环境的入口文件
├── example_dexpoint_grasping.py # 演示如何使用 DexPoint 环境进行抓取任务
├── example_use_imagination_env.py # 演示如何使用包含想象点的点云环境
├── example_use_multi_camera_visual_env.py # 演示如何使用多种视觉模态的环境
├── example_use_pc_env.py # 演示如何使用点云环境
└── example_use_state_only_env.py # 演示如何使用仅使用状态的环境Dexpoint文件夹
env文件夹
base.py
- 动作恢复机制,玩过gym会知道,强化学习最后的输出是0-1的动作映射,用这个把这个映射恢复到正常动作的值
def recover_action(action, limit):
action = (action + 1) / 2 * (limit[:, 1] - limit[:, 0]) + limit[:, 0]
return action
- 强化学习环境基类,用户自定义的环境需要继承这个类,去定义自己的奖励和环境
class BaseRLEnv(BaseSimulationEnv, gym.Env):
def __init__(self, use_gui=True, frame_skip=5, use_visual_obs=False, **renderer_kwargs):- 获取观测模型:这里函数没有实现,需要用户自行实现,来取得自己模型的state
def get_observation(self):
raise NotImplementedError在这里我们直接可以转到去看作者是如何重写获取观测函数的,通过标志位改为调用实际的观测函数,这里包含相机,机器人等观测数据
if self.use_visual_obs:
self.get_observation = self.get_visual_observation
if not self.no_rgb:
add_default_scene_light(self.scene, self.renderer)
else:
self.get_observation = self.get_oracle_state def get_visual_observation(self):
camera_obs = self.get_camera_obs()
robot_obs = self.get_robot_state()
oracle_obs = self.get_oracle_state()
camera_obs.update(dict(state=robot_obs, oracle_state=oracle_obs))
return camera_obs- 计算奖励方法,这里同样可以转到作者的奖励函数设计,看看论文中奖励的代码实现,可以看到和论文中的代码实现一致,注意通过代码可以看到之前加权奖励中,论文没有展开的惩罚项,是关节速度惩罚和控制器误差惩罚,更具体的讲解把这段代码丢进AI分析就好了
@abstractmethod
def get_reward(self, action):
pass def get_reward(self, action):
finger_object_dist = np.linalg.norm(self.object_in_tip, axis=1, keepdims=False)
finger_object_dist = np.clip(finger_object_dist, 0.03, 0.8)
reward = np.sum(1.0 / (0.06 + finger_object_dist) * self.finger_reward_scale)
# at least one tip and palm or two tips are contacting obj. Thumb contact is required.
is_contact = np.sum(self.robot_object_contact) >= 2
if is_contact:
reward += 0.5
lift = np.clip(self.object_lift, 0, 0.2)
reward += 10 * lift
if lift > 0.02:
reward += 1
target_obj_dist = np.linalg.norm(self.target_in_object)
reward += 1.0 / (0.04 + target_obj_dist)
if target_obj_dist < 0.1:
theta = self.target_in_object_angle[0]
reward += 4.0 / (0.4 + theta) * self.rotation_reward_weight
action_penalty = np.sum(np.clip(self.robot.get_qvel(), -1, 1) ** 2) * -0.01
controller_penalty = (self.cartesian_error ** 2) * -1e3
return (reward + action_penalty + controller_penalty) / 10- get_info:说实话这个没太看懂,也没找到对应的实现在哪里,可能就是额外的接口?
- 更新环境缓存信息,即刷新仿真环境,这里我就直接把作者的实现一起放进来了,具体实现也在relocate_env.py里面
def update_cached_state(self):
return
def update_cached_state(self):
for i, link in enumerate(self.finger_tip_links):
self.finger_tip_pos[i] = self.finger_tip_links[i].get_pose().p
check_contact_links = self.finger_contact_links + [self.palm_link]
contact_boolean = self.check_actor_pair_contacts(check_contact_links, self.manipulated_object)
self.robot_object_contact[:] = np.clip(np.bincount(self.finger_contact_ids, weights=contact_boolean), 0, 1)
self.object_pose = self.manipulated_object.get_pose()
self.palm_pose = self.palm_link.get_pose()
self.palm_pos_in_base = self.palm_pose.p - self.base_frame_pos
self.object_in_tip = self.object_pose.p[None, :] - self.finger_tip_pos
self.object_lift = self.object_pose.p[2] - self.object_height
self.target_in_object = self.target_pose.p - self.object_pose.p
self.target_in_object_angle[0] = np.arccos(
np.clip(np.power(np.sum(self.object_pose.q * self.target_pose.q), 2) * 2 - 1, -1 + 1e-8, 1 - 1e-8))- is_done函数,顾名思义一轮训练结束的标志,和上面一样,直接把作者的实现放在这里,将物体抬升到一定高度表示本轮训练结束
@abstractmethod
def is_done(self):
pass
def is_done(self):
return self.object_lift < OBJECT_LIFT_LOWER_LIMIT- 参数获取:获取机器人自由度数和训练超参数最大步长
#机器人自由度
@property
def action_dim(self):
return self.robot.dof
#最大训练步长
@property
@abstractmethod
def horizon(self):
return 0- setup方法,这里直接复制AI的结论了,和init功能类似进行一些设置,设置机器人和环境的初始状态。根据机器人的名称加载机器人模型,并设置其初始姿态。根据机器人类型(自由机器人或机械臂机器人)设置不同的速度限制和运动学模型。选择不同的步长函数来执行动作。根据是否使用视觉观测设置不同的观测函数,并添加默认的场景光照。
-
free_sim_step用于处理自由机器人的模拟步骤,主要关注机器人的整体运动控制。 arm_sim_step用于处理带机械臂的机器人的模拟步骤,同时考虑了机械臂和灵巧手的运动控制。- step方法:强化学习中的时间步,执行一个时间步的环境交互。调用
rl_step方法执行动作,更新缓存的状态和想象信息。获取当前环境的观测值、奖励值、判断环境是否结束,并获取额外信息。如果达到最大时间步长,则将环境标记为结束,并在信息中记录是否是时间限制导致的结束。最后返回观测值、奖励值、结束标志和额外信息。 在这里有些疑惑上面三个step的关系,step函数是环境交互的核心入口,它根据机器人的配置选择调用arm_sim_step或free_sim_step来执行具体的动作。arm_sim_step和free_sim_step分别处理带机械臂的机器人和自由机器人的运动模拟,它们为step函数提供了具体的动作执行逻辑。这种分工协作的设计使得代码具有良好的可扩展性和灵活性,可以方便地处理不同类型的机器人。- 文件中其余的方法是一些抽象函数的实现,或者一些传感器类型设置
relocate_env.py
函数实现已经在上面拆解过了,强化学习中比较关键的几个要素,环境,奖励,动作,算法模型;env就是用于建立环境,获取观测数据的,并且环境里已经写好了获得奖励的函数,那么对于强化学习中的环境问题,我们更应该关注项目中的action动作是如何作用在环境中的.
- 声明AllegroRelocateRLEnv类,继承BaseRLEnv,也就是作者自己抓取任务的环境细节,并且对base中的很多抽象函数重写了,这里就不全都列举了,上面解析base.py的时候已经直接对应到这个文件里的内容了
def get_robot_state(self):
def get_reward(self, action):
def reset(self, *, seed: Optional[int] = None, return_info: bool = False, options: Optional[dict] = None):
def is_done(self):
def horizon(self):- 传进action的是定义在base.py中的step方法,而调用step方法的是在example中,也就是说
example_dexpoint_grasping.py line46~50调用base类中的step
rl_steps = 1000
for _ in range(rl_steps):
action = np.zeros(env.action_space.shape)
action[0] = 0.002 # Moving forward ee link in x-axis
obs, reward, done, info = env.step(action)base.py line204~217完成一系列交互过程,其中的交互在relocate_env.py中具体实现
def step(self, action: np.ndarray):
self.rl_step(action)
self.update_cached_state()
self.update_imagination(reset_goal=False)
obs = self.get_observation()
reward = self.get_reward(action)
done = self.is_done()
info = self.get_info()
# Reference: https://github.com/openai/gym/blob/master/gym/wrappers/time_limit.py
# Need to consider that is_done and timelimit can happen at the same time
if self.current_step >= self.horizon:
info["TimeLimit.truncated"] = not done
done = True
return obs, reward, done, info这里其实会发现一个问题,训练过程中的action应该是模型输出的,但代码中却将action写死的,回到之前的,dexpoint的重点其实在环境搭建上,需要自己引入模型,并仿照example中的action传输将模型的输出动作与环境交互,这里应该是写死action之后,可以观测到机械臂的运动,以及运动过程中的奖励,并没有模型的训练.
pc_processing.py
点云处理工具,主要功能就是选定ROI区域,添加高斯噪声以提高sim2real效果,最关键的下采样数目num_points作为传入参数,是在其他文件中配置的512,与论文一致.
Example文件夹
因为拆解项目最重要的是把数据流打通,上面已经介绍了最主要的就是action是如何作用的环境中的,这里就简单介绍一些每个文件的区别,直接粘贴AI的答案了
example_dexpoint_grasping.py综合展示了物体抓取和重新定位任务的环境配置和实验流程。example_use_imagination_env.py突出了想象信息在环境中的应用。example_use_multi_camera_visual_env.py强调了多相机和多模态视觉观测的使用。example_use_pc_env.py专注于点云环境的使用。example_use_state_only_env.py则展示了仅使用状态信息的简化环境。
总结
梳理了一下代码和论文的一一对应关系,以及强化学习模型中的几个关键要素的数据流和代码实现,目前还是缺少如何把算法模型添加到里面的步骤,作者也说了可以在DexArt中看到,后面会继续拆解DexArt项目

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)