登录社区云,与社区用户共同成长
邀请您加入社区
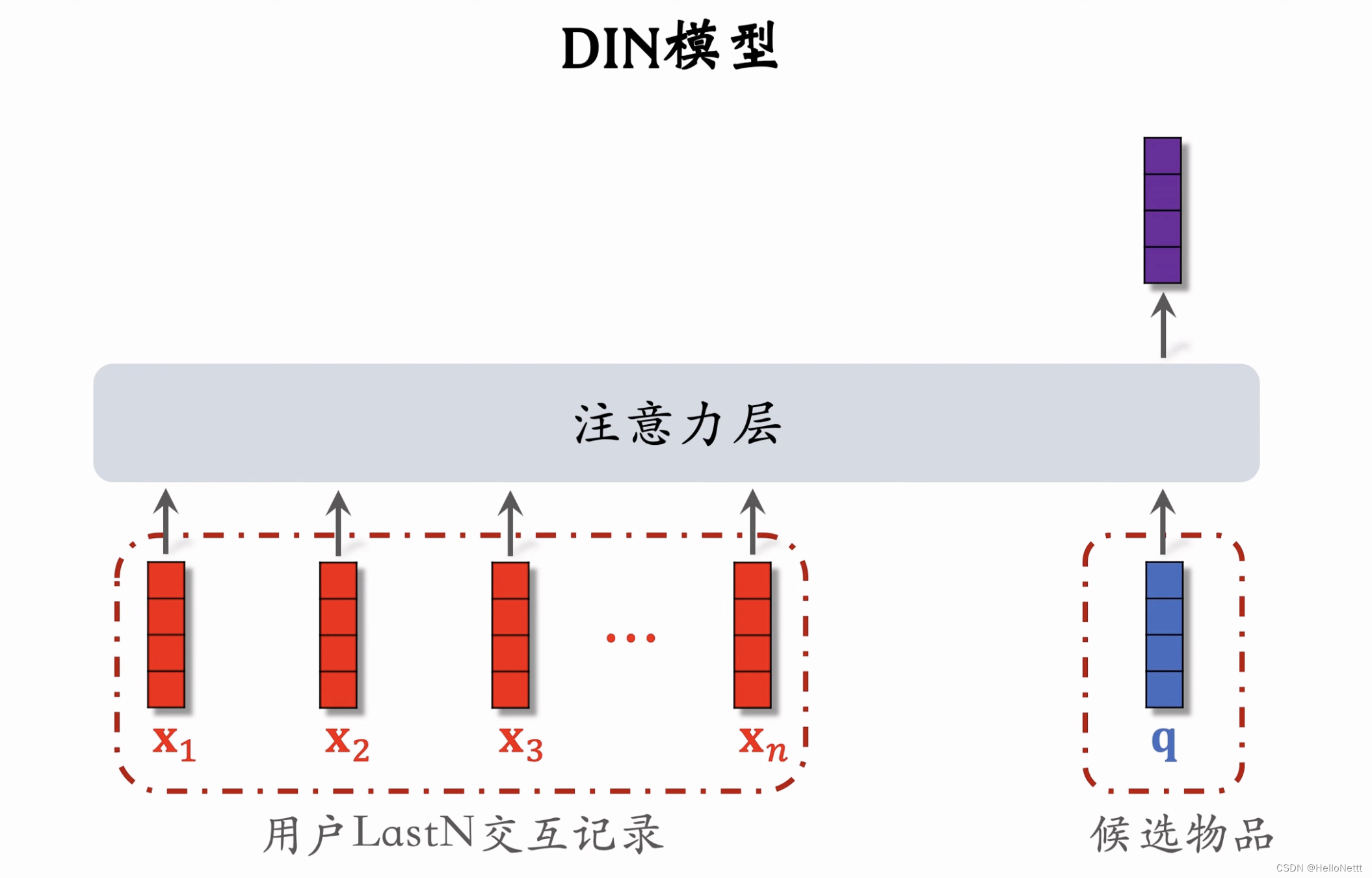
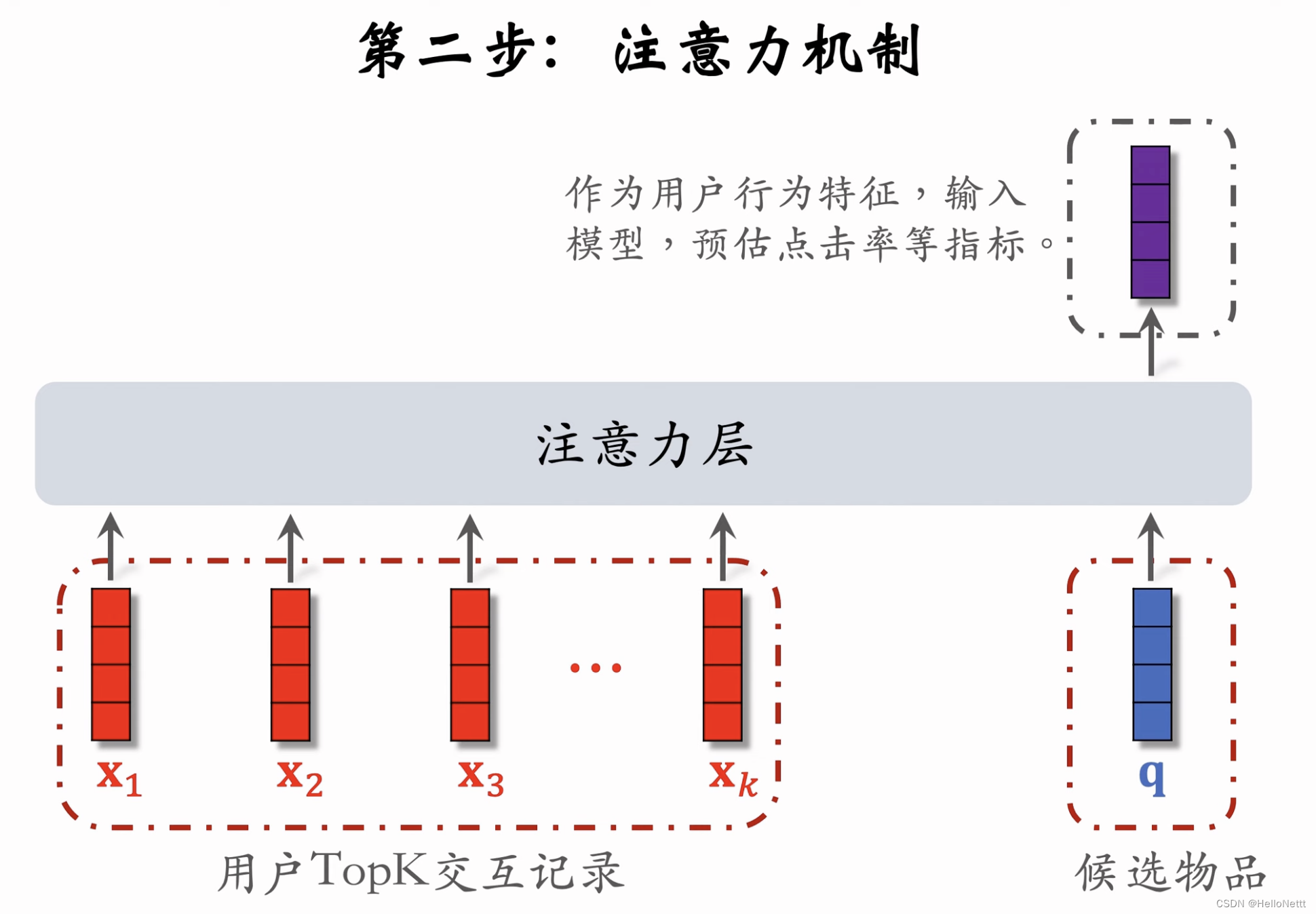
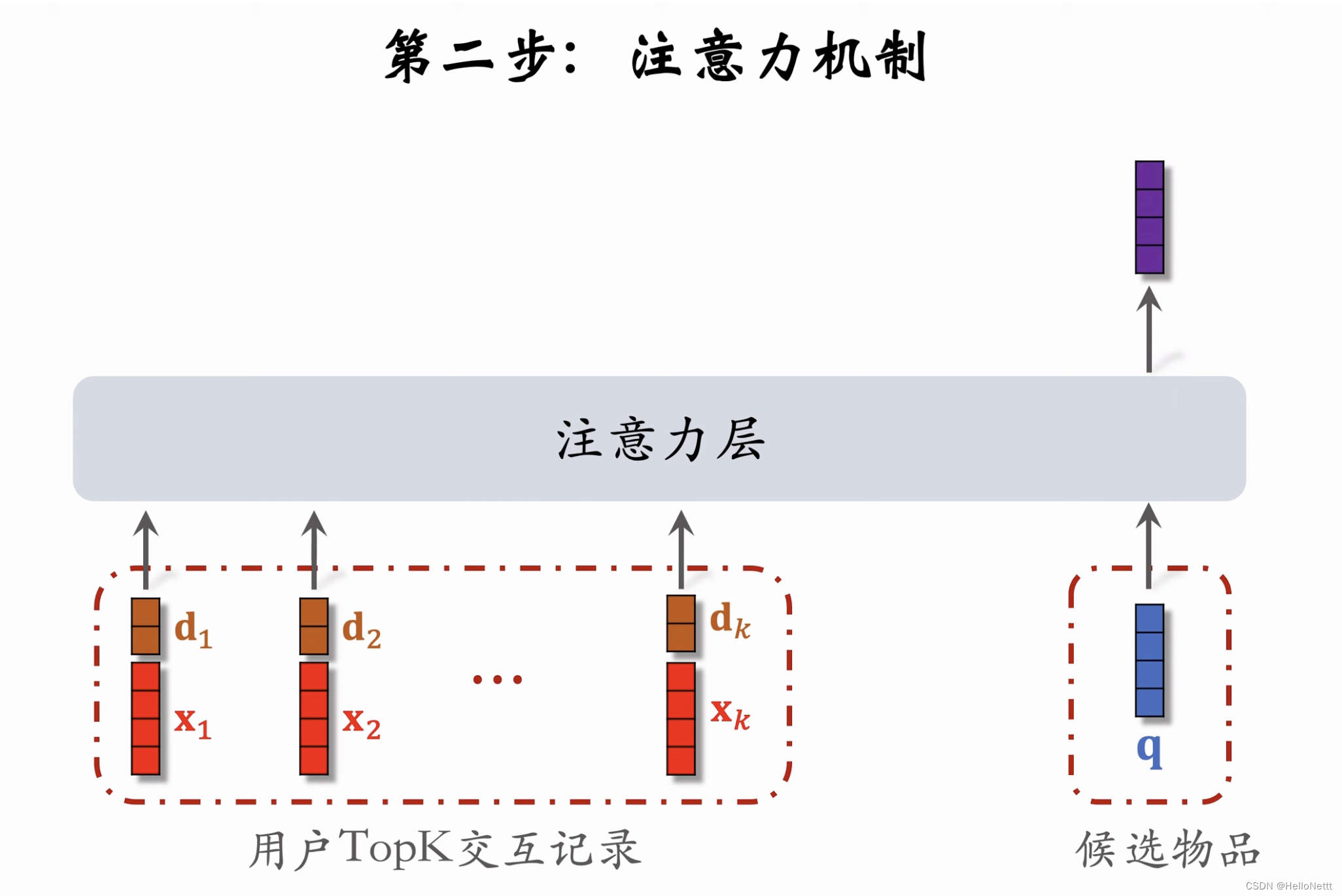
对比DIN,user侧的。被换成了上一步查找到的。
对长期兴趣建模
对比DIN,user侧的LastN交互记录被换成了上一步查找到的TopK交互记录。
王树森推荐系统公开课-SIM模型SIM论文DIN论文
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
企业AI落地别再画饼了!5个真实场景+落地路径全公开,看到就是赚到,建议收藏!!
AI Agent时代来临:2025年普通人如何把握智能体红利,从小白到专家的成长之路!
AI大模型面试题解析之LangChain&LlamaIndex面试高频考点,含核心概念与实战技巧!
扫一扫分享内容





 2
2 0
0


 已为社区贡献3条内容
2 0
已为社区贡献3条内容
已为社区贡献3条内容
2 0
已为社区贡献3条内容

所有评论(0)