分离音频的人声和背景音/音轨----spleeter
这是一个基于python 语言编写的一个工具类小项目,运用了spleeter 库,分割音频中的人声和背景音,目前测试效果还是比较好,主要是免费的就是香。如果你做自媒体,或者AIGC相关音频项目,相信这是个对你很大帮助的小工具。
·
介绍
这是一个基于python 语言编写的一个工具类小项目,运用了spleeter 库,分割音频中的人声和背景音,目前测试效果还是比较好,主要是免费的就是香。如果你做自媒体,或者AIGC相关音频项目,相信这是个对你很大帮助的小工具。
开搞
环境:
python >=3.9 linux ubantu20.04,其他系统请自行灵活应变
1:安装必要组件
apt install ffmpeg
pip install spleeter
2:创建spleeter项目环境
1:在你自己喜欢的目录下创建spleeter文件夹
mkdir spleeter && cd spleeter
2:在spleeter下创建raw文件夹以备用,创建pretrained_models 模型文件夹
mkdir raw
mkdir pretrained_models
3:下载模型到spleeter下的 pretrained_models 文件夹内
wget -P pretrained_models https://github.com/deezer/spleeter/releases/download/v1.4.0/2stems.tar.gz
4:把模型解压到 pretrained_models 文件夹下的 2stems 文件夹内
mkdir -p pretrained_models/2stems
tar -zxvf pretrained_models/2stems.tar.gz -C pretrained_models/2stems/
完事儿后的目录为 这样:
3:测试人声分离
步骤:
①:下载或者上传一段音频到 spleeter 项目文件夹下,例如为 audio_example.mp3
②:在项目根目录下运行脚本命令:
spleeter separate -p spleeter:2stems -o output audio_example.mp3
③:运行后,会在spleeter目录下生成 output 文件夹,并在 output 文件夹下生成以音频名称为名的文件夹,伴奏和人声放在此目录下,如下图
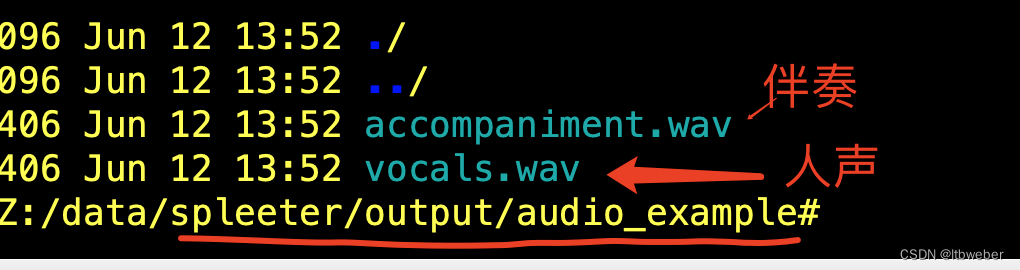
到此,音频文件的人声和伴奏就分离完成了,可以试听下效果。这个小工具可以当做你项目中的一个分离服务,通过改编成接口的形式,提供给你的项目使用。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)