CNN经典模型(1)---letnet
LeNet是一种经典的卷积神经网络架构,于1998年由Yann LeCun等人提出,被广泛应用于手写数字识别任务。它是深度学习中的里程碑之一,为后来的卷积神经网络的发展奠定了基础。LeNet的设计灵感来自于人类视觉系统的结构。它由一系列的卷积层、池化层和全连接层组成,用于从输入图像中提取特征并进行分类。其中最为典型的就是。
·
一、介绍
LeNet是一种经典的卷积神经网络架构,于1998年由Yann LeCun等人提出,被广泛应用于手写数字识别任务。它是深度学习中的里程碑之一,为后来的卷积神经网络的发展奠定了基础。
LeNet的设计灵感来自于人类视觉系统的结构。它由一系列的卷积层、池化层和全连接层组成,用于从输入图像中提取特征并进行分类。
其中最为典型的就是letnet5
二、网络结构
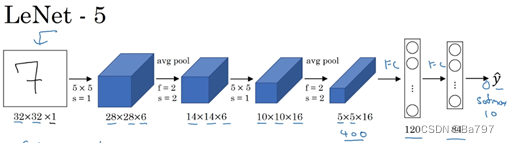
LeNet的结构如下:
输入层:接收输入图像的像素值。
第一层:卷积层。使用多个卷积核对输入图像进行卷积操作,提取局部特征。通常采用Sigmoid或Tanh作为激活函数。
第二层:池化层。对卷积层的输出进行下采样操作,减少特征图的尺寸,并保持重要特征的不变性。通常使用平均池化或最大池化。
第三层:卷积层。类似于第一层,进一步提取更高级的特征。
第四层:池化层。类似于第二层,进一步减小特征图的尺寸。
第五层:全连接层。将池化层的输出展平为向量,并连接到一个或多个全连接层,用于进行分类。
输出层:最后一层全连接层用于将特征映射到目标类别的概率分布上,通常使用Softmax激活函数。
三、手写数字识别任务代码
1、下载MNIST数据集
import torchvision
# 下载训练集
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True)
# 下载测试集
testset = torchvision.datasets.MNIST(root='./data', train=False, download=True)2、模型训练以及可视化
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
# 定义LeNet模型
class LeNet(nn.Module):
def __init__(self, num_classes=10):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(1, 6, kernel_size=5)
self.relu1 = nn.ReLU()
self.maxpool1 = nn.MaxPool2d(kernel_size=2)
self.conv2 = nn.Conv2d(6, 16, kernel_size=5)
self.relu2 = nn.ReLU()
self.maxpool2 = nn.MaxPool2d(kernel_size=2)
self.fc1 = nn.Linear(16*4*4, 120)
self.relu3 = nn.ReLU()
self.fc2 = nn.Linear(120, 84)
self.relu4 = nn.ReLU()
self.fc3 = nn.Linear(84, num_classes)
def forward(self, x):
out = self.conv1(x)
out = self.relu1(out)
out = self.maxpool1(out)
out = self.conv2(out)
out = self.relu2(out)
out = self.maxpool2(out)
out = out.view(out.size(0), -1)
out = self.fc1(out)
out = self.relu3(out)
out = self.fc2(out)
out = self.relu4(out)
out = self.fc3(out)
return out
# 定义训练函数
def train(net, trainloader, criterion, optimizer, num_epochs):
net.train()
train_loss_history = []
train_acc_history = []
for epoch in range(num_epochs):
running_loss = 0.0
correct = 0
total = 0
for i, (inputs, labels) in enumerate(trainloader):
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
epoch_loss = running_loss / len(trainloader)
epoch_acc = correct / total
train_loss_history.append(epoch_loss)
train_acc_history.append(epoch_acc)
print('Epoch [{}/{}], Loss: {:.4f}, Accuracy: {:.2f}%'
.format(epoch+1, num_epochs, epoch_loss, epoch_acc*100))
return train_loss_history, train_acc_history
# 定义测试函数
def test(net, testloader):
net.eval()
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
images = images.to(device)
labels = labels.to(device)
outputs = net(images)
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
test_acc = correct / total
print('Test Accuracy: {:.2f}%'.format(test_acc*100))
# 设置随机种子
torch.manual_seed(1234)
# 定义设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 数据预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# 加载训练集和测试集
trainset = torchvision.datasets.MNIST(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128,
shuffle=True, num_workers=2)
testset = torchvision.datasets.MNIST(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=128,
shuffle=False, num_workers=2)
# 创建LeNet模型
model = LeNet().to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
num_epochs = 10
train_loss_history, train_acc_history = train(model, trainloader, criterion, optimizer, num_epochs)
# 在测试集上评估模型
test(model, testloader)
# 可视化训练过程下面是使用Matplotlib可视化训练过程的代码:
# 可视化训练过程
plt.figure(figsize=(10, 4))
plt.subplot(1, 2, 1)
plt.plot(range(1, num_epochs+1), train_loss_history)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss')
plt.subplot(1, 2, 2)
plt.plot(range(1, num_epochs+1), train_acc_history)
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.title('Training Accuracy')
# 保存训练好的模型
torch.save(model.state_dict(), 'model.pth')
plt.tight_layout()
plt.show() 
3、进行预测
import torch
import torchvision.transforms as transforms
from PIL import Image
# 加载已经训练好的模型
model = LeNet()
model.load_state_dict(torch.load('model.pth')) # 替换'model.pth'为你保存的模型文件路径
model.eval()
# 数据预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# 加载要进行预测的图像
image_path = 'test_image.png' # 替换为你要预测的图像路径
image = Image.open(image_path).convert('L') # 转为灰度图像
image = transform(image).unsqueeze(0) # 添加批处理维度并进行预处理
image = image.to(device)
# 使用模型进行预测
with torch.no_grad():
output = model(image)
# 获取预测结果
_, predicted = torch.max(output.data, 1)
prediction = predicted.item()
# 打印预测结果
print('预测结果:', prediction)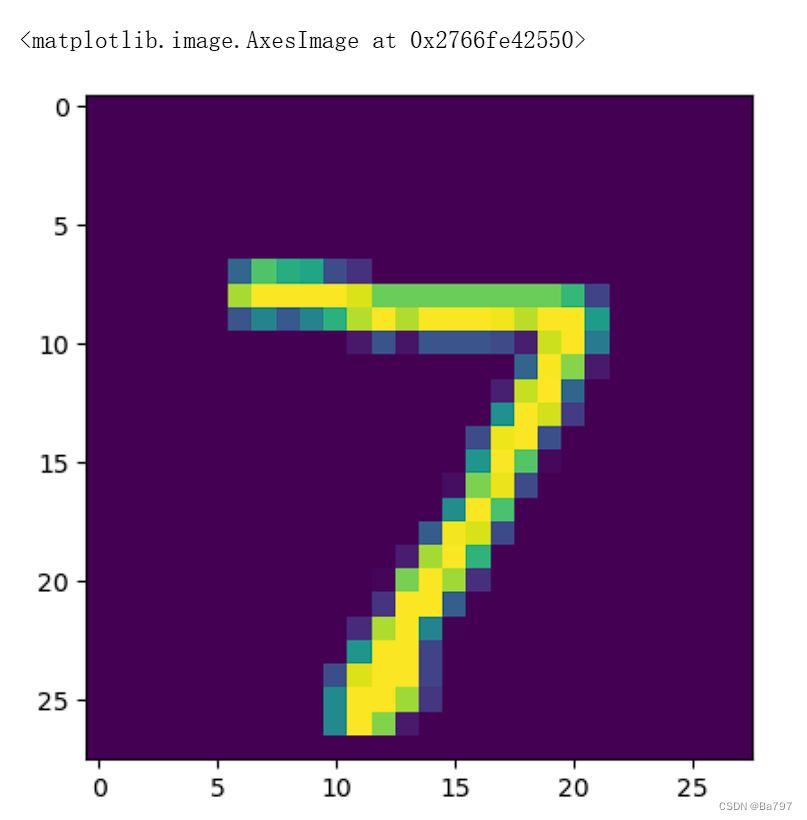

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 5
5 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)