flash attention1和2
虽然non-matmul FLOPs仅占总FLOPs的一小部分,但它们的执行时间较长,这是因为GPU有专用的矩阵乘法计算单元,其吞吐量高达非矩阵乘法吞吐量的16倍。这个过程使用更多的flop,由于减少HBM访问,重新计算也加快了反向传播的速度。,为了减少对HBM的读写,FlashAttention将参与计算的矩阵进行分块送进SRAM,减少了HBM访存,来提高整体读写速度。,将QK划分成块后,只能计
文章目录
欢迎关注微信公众号InfiniReach,这里有更多AI大模型的前沿算法与工程优化方法分享

FlashAttention 笔记(施工中) - HPC小菜鸟的文章 - 知乎
https://zhuanlan.zhihu.com/p/708867810
https://github.com/66RING/tiny-flash-attention/blob/main/flash_attention_cutlass/csrc/flash_attention.cu
attention

注意为了防止溢出,一般会softmax一般过程如下:
m = r o w m a x ( S ) m=rowmax(S) m=rowmax(S), P = e x p ( S − m ) P=exp(S-m) P=exp(S−m), l = r o w s u m ( P ) l=rowsum(P) l=rowsum(P), P = P / l P=P / l P=P/l
(1)(2)设计矩阵乘法,计算复杂度都是 O ( d N 2 ) O(dN^2) O(dN2)(仅乘法),复杂度随序列长度的增长呈二次方增长
GPU的显存即HBM带宽为1.5-2.0TB/s;片上SRAM的带宽约为19TB/s。在attention计算中涉及大量访存事务:
- 读QK,写S
- 读S,写P
- 读PV,写O
访存复杂度 O ( 2 d N + N 2 + N 2 + N 2 + N 2 + d N + d N ) = O ( d N + N 2 ) O(2dN + N^2 + N^2+N^2+N^2+dN+dN) =O(dN+N^2) O(2dN+N2+N2+N2+N2+dN+dN)=O(dN+N2)
flash attention 1
原理
FlashAttention将优化重点放在了降低存储访问开销,为了减少对HBM的读写,FlashAttention将参与计算的矩阵进行分块送进SRAM,减少了HBM访存,来提高整体读写速度。
分块如下:
由于softmax时涉及计算每行元素最大值 m = r o w m a x ( S ) m=rowmax(S) m=rowmax(S),以及 P = e x p ( S − m ) P=exp(S-m) P=exp(S−m), l = r o w s u m ( P ) l=rowsum(P) l=rowsum(P),将QK划分成块后,只能计算局部最大值,每次计算完局部后,更新这俩全局向量,消掉原来的局部max。
如上图所示,计算流程如下
- 外层循环KV,内层循环QOml,将分块后的这些参数从global mem中读取到shared mem,
- 然后计算计算局部的S、P、m、l、并更新ml,计算O,
- 最后将Oml写回global mem

在更新时,首先 m i n e w = m a x ( m i , m ^ i , j ) m^{new}_i = max(m_i, \hat m_{i,j}) minew=max(mi,m^i,j),
然后 l i n e w l^{new}_i linew等于旧的加新的,对于旧的 l i = r o w s u m ( e x p ( S i , j − 1 − m i ) ) l_i=rowsum(exp(S_{i,j-1}-m_i)) li=rowsum(exp(Si,j−1−mi)),由于 m i m_i mi更新了,所以需要更新为 e m i − m i n e w l i e^{m_i-m^{new}_i}l_i emi−minewli,然后更新本块刚计算的 l ^ i j \hat l_{ij} l^ij,因为它只用到了 m ^ i , j \hat m_{i,j} m^i,j,没有用到累积量,所以需要更新为 e m ^ i , j − m i n e w l ^ i j e^{\hat m_{i,j}-m^{new}_i}\hat l_{ij} em^i,j−minewl^ij,因此 l i n e w = e m i − m i n e w l i + e m ^ i , j − m i n e w l ^ i j l^{new}_i=e^{m_i-m^{new}_i}l_i + e^{\hat m_{i,j}-m^{new}_i}\hat l_{ij} linew=emi−minewli+em^i,j−minewl^ij
最后需要更新 O i O_i Oi,原理同 l i n e w l^{new}_i linew, O i O_i Oi也是分成旧的和新的部分,对于新的部分,需要像上面一样更新P,就是 e m ^ i , j − m i n e w P ^ i j / l i n e w ∗ V j e^{\hat m_{i,j}-m^{new}_i}\hat P_{ij}/ l^{new}_i * V_j em^i,j−minewP^ij/linew∗Vj,对于旧的部分,需要先把旧的分母乘回来并除以新分母,然后分子也要像上面一样更新,即 O i ∗ l i / l i n e w ∗ e m i − m i n e w O_i*l_i/l^{new}_i*e^{m_i-m^{new}_i} Oi∗li/linew∗emi−minew,二者合并就是下面第12行的公式了
计算内层访存复杂度,内存循环一次访存Nd,外层循环 N B c = 4 d N M \frac{N}{B_c}=\frac{4dN}{M} BcN=M4dN,共计 O ( N 2 d B − 1 ) = O ( N 2 d 2 M − 1 ) O(N^2dB^{-1})=O(N^2d^2M^{-1}) O(N2dB−1)=O(N2d2M−1)。 M(100KB)通常远远大于 d(数K),所以FlashAttention的MAC远小于标准的Transformer O ( d N + N 2 ) O(dN+N^2) O(dN+N2)。
FlashAttention 的 向后传递需要SP矩阵来计算 Q,K,V 的梯度。然而由于空间复杂度是 O(N^2) ,没有显式存储。使用输出 O 和 softmax 归一化统计 (m,ℓ),利用SRAM中的 Q,K,V 重新计算 S 和 P 矩阵。这个过程使用更多的flop,由于减少HBM访问,重新计算也加快了反向传播的速度。
FlashAttention 的速度优化原理是怎样的? - Civ的回答 - 知乎
https://www.zhihu.com/question/611236756/answer/3132304304
并行策略
QKV的维度都是 [ b a t c h s i z e , s e q l e n , n h e a d , n d i m ] [batchsize, seqlen, nhead, ndim] [batchsize,seqlen,nhead,ndim], Q K T QK^T QKT是 [ b a t c h s i z e , n h e a d , s e q l e n , n d i m ] [batchsize, nhead, seqlen, ndim] [batchsize,nhead,seqlen,ndim]与 [ b a t c h s i z e , n h e a d , n d i m , s e q l e n ] [batchsize, nhead, ndim,seqlen] [batchsize,nhead,ndim,seqlen]相乘,结果维度为 [ b a t c h s i z e , n h e a d , s e q l e n , s e q l e n ] [batchsize, nhead, seqlen, seqlen] [batchsize,nhead,seqlen,seqlen],很自然的,FlashAttention v1的并行在两个维度同时进行:batch和attention head。
-
使用一个thread block去处理一个nhead。每个thread block实际在SM运行,而A100一共有108个SM。如果当总的nhead的并行数足够大时(同时考虑到batch size和nhead数量),就会有更多的SM在同时计算,整体的吞吐量自然也就会比较高。
-
但是随着LLM的上下文窗口长度越来越长,单卡上的batch size通常变得非常小,因此实际可以并行的nhead数量可能远远少于SM数量,导致系统整体吞吐量较低。
计算分片(Work Partitioning)
每一个thread block负责某个分块的一个attention head的计算。在每个thread block中,threads又会被组织为多个warps,每个warp中的threads可以协同完成矩阵乘法计算。Work Partitioning主要针对的是对warp的组织优化。
可以充分利用多个warps的计算能力来对矩阵进行分块处理,从而加快整体计算速度。FlashAttention v1将thread block中的threads分为4个warps,并将 K T K^T KT和 V V V 划分为4个分块,与每个warp对应;对 Q 不进行分块。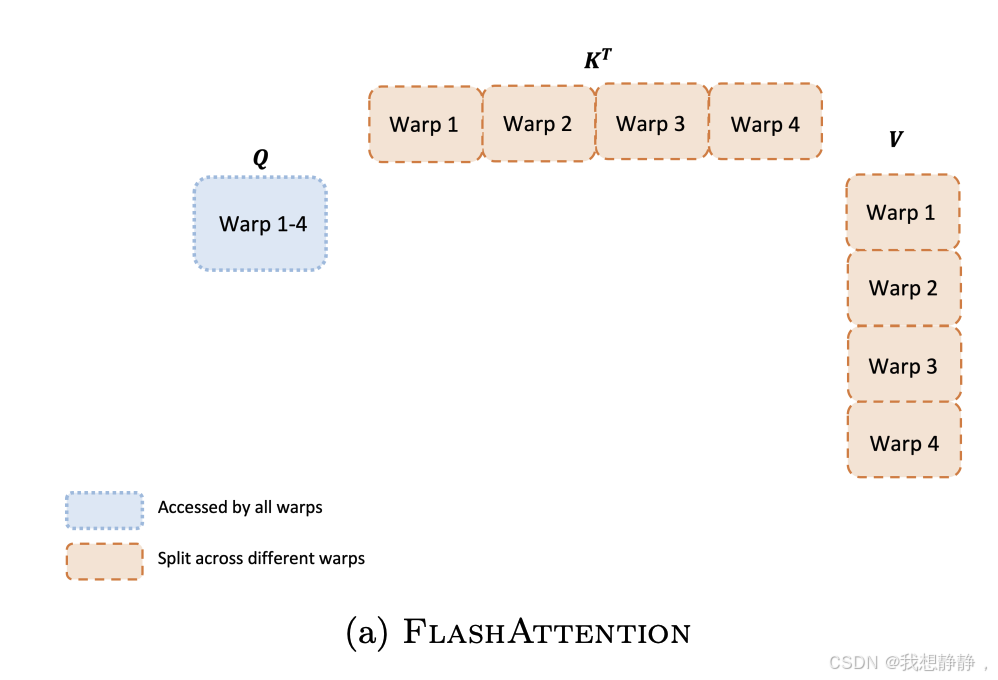
每个warp都从shared memory上读取相同的Q块以及自己所负责计算的KV块。在V1中,每个warp只是计算出了列方向上的结果,这些列方向上的结果必须汇总起来,才能得到最终O矩阵行方向上的对应结果。所以每个warp需要把自己算出来的中间结果写到shared memory上,再由一个warp(例如warp1)进行统一的整合。所以各个warp间需要通讯、需要写中间结果,这就影响了计算效率。
flash attention 2
- 减少了non-matmul FLOPs的数量(消除了原先频繁rescale)。虽然non-matmul FLOPs仅占总FLOPs的一小部分,但它们的执行时间较长,这是因为GPU有专用的矩阵乘法计算单元,其吞吐量高达非矩阵乘法吞吐量的16倍。因此,减少non-matmul FLOPs并尽可能多地执行matmul FLOPs非常重要。(因为在循环时不计算分母,所以少算了很多除法乘法exp)
- 在一个attention计算块内,将工作分配在一个thread block的不同warp上,以减少通信和共享内存读/写。
- 原版外层循环是KV,内存循环是QO,O需要刷新外层循环的次数;所以把QO设为外层循环,KV设为内层循环。将FlashAttention的Q共享,KV切4个warp,改进为Q切4个warp,共享kv,warp之间不再需要通信,减少了share memory读写,带来了性能提升
https://zhuanlan.zhihu.com/p/645376942

原版设置长为N的全局 m a x ( S ) max(S) max(S)和全局 r o w s u m ( e x p ( S − m ) ) rowsum(exp(S-m)) rowsum(exp(S−m)),需要每次更新这俩。新版里先不计算分母,即softmax没分母,等最后再除以分母 l i l_i li即可,因此global mem中不再设置这里长度为N的向量,仅在smem中设置二者的局部 m i j , l i j m^j_i, l^j_i mij,lij
v1版本是在内层循环QO,导致外层循环几次,内层的QO 就要读写几次,为了避免重复读写,将Q放在外层循环,O直接在smem生成并只需要最后写入global mem,并且在累积O时无需考虑分母,最后算完了直接除以分母l即可
流程如下:
- 外层循环Q,将分块后的Qi参数从global mem中读取到shared mem,在smem中初始化Olm
- 然后计算计算局部的S、m、P、l、O,
- 内存循环完成后,Oi仅需要除以分母即可
- 最后将O L写回global mem
注意 m i j m^j_i mij是指前j块block的rowmax,因此对应求出来的 P ^ i j \hat P^j_i P^ij是相对于j正确的,所以更新 l i j l^j_i lij时,只需要更新旧的,不需要更新P
本算法的P没有除分母,所以 O = e S − m V O=e^{S-m}V O=eS−mV,因此仅需更新旧的 O i j − 1 O^{j-1}_i Oij−1即可,把因为m更新的影响消除掉
假设我们要计算从1到10的平均值,但每次只能算两个数。那么原来的FlashAttention v1的计算方法类似于:
第一次算出前两个数的平均值,并记录下当前已经计算过的数字数量N
第二次算出前三个数的平均值,需要使用之前的N(N=2)来更新
换言之,这种方法每一步计算出的都是前N个数精确的平均值,当有新的值来了后,我们再更新至新的全局平均值。
FlashAttention v2的方法类似于:
第一次算出前两个数的和,并记录下当前已经计算过的数字数量N: , N = 2。
第二次算出前三个数的和,并记录下当前已经计算过的数字数量N: , N = 3。
计算完毕后,只需要将当前的总和除以N即可。FlashAttention v2的优势在于少了原来每一步的乘法和除法。
并行策略
FlashAttention v1的并行策略在LLM上下文窗口较长时会因batch size较小而导致整体可并行的nhead数远少于streaming multiprocessors数量。
FlashAttention v2实际上在FlashAttention v1的并行策略基础上,增加了外循环的并行,即在序列长度这一维度上( Q i , O i Q_i, O_i Qi,Oi)进行并行化,显著提升了计算速度。此外,当batch size和head数量较小时,在序列长度上增加并行性有助于提高GPU占用率。
计算分片(Work Partitioning)

每个warp都从shared memory上读取相同的KV块以及自己所负责计算的Q块。在V2中,行方向上的计算是完全独立的,即每个warp把自己计算出的结果写到O的对应位置即可,warp间不需要再做通讯,通过这种方式提升了计算效率。不过这种warp并行方式在V2的BWD过程中就有缺陷了:由于bwd中dK和dV是在行方向上的AllReduce,所以这种切分方式会导致warp间需要通讯。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 2
2 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)