简单树匹配算法STM-理论篇
内容来自论文@article{何昕2007基于简单树匹配算法的,title={基于简单树匹配算法的Web页面结构相似性度量},author={何昕 and 谢志鹏},journal={计算机研究与发展},number={z3},pages={1--6},year={2007}}简单树匹配算法SimPle Tree Matching 最初在软件工程上用于比较两个计算机程序,后引入网页结构相似度计算。
内容来自论文
@article{何昕2007基于简单树匹配算法的,
title={基于简单树匹配算法的Web页面结构相似性度量},
author={何昕 and 谢志鹏},
journal={计算机研究与发展},
number={z3},
pages={1--6},
year={2007}
}
简单树匹配算法SimPle Tree Matching 最初在软件工程上用于比较两个计算机程序,后引入网页结构相似度计算。主要考虑页面的结构信息,假设含有相似信息的页面也具有相似的结构。
将HTML网页表示成树结构
原始的HTML文档可以通过深度优先遍历树重构出来
文档 1 和 2 对应的网页表示:
文档 1 和 2 对应的html表示:
文档 1 和 2 对应的网页结构树表示: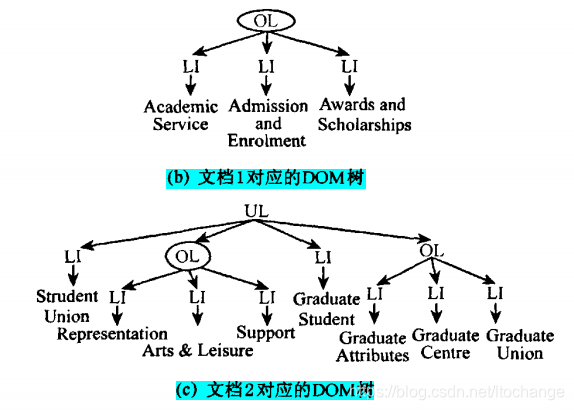
简单树匹配不允许结点的替换和跨层匹配,从而大大提高了算法的运行效率。
简单树匹配算法
两棵树的匹配定义为:
对于映射MMM,任意的结点对(i,j)(i,j)(i,j),(i,j)∈M(i, j) \in M(i,j)∈M (i,ji, ji,j 是非根结点),(parent(i),parent(j))∈M(parent(i), parent(j)) \in M(parent(i),parent(j))∈M成立,则结点对(i,j)(i,j)(i,j)匹配.
最大匹配是指匹配到的结点对数目最多的匹配.
算法流程
令AAA 和BBB为两棵树, iii 和 jjj 分别为AAA和BBB上的结点.
A=(RA,A1,⋯ ,Am)B=(RB,B1,⋯ ,Bn)A=\left(R_{\mathrm{A}}, A_{1}, \cdots, A_{m}\right) \\ B=\left(R_{\mathrm{B}}, B_{1}, \cdots,B_{n}\right)A=(RA,A1,⋯,Am)B=(RB,B1,⋯,Bn)
其中,RAR_{\mathrm{A}}RA 和RBR_{\mathrm{B}}RB是AAA和BBB的根结点,AiA_{i}Ai 和BjB_{j}Bj分别是AAA和BBB的第iii个和第jjj个第1层子树.
(1)当RAR_{A}RA和RBR_{B}RB的标记相同时, AAA和BBB的最大匹配为MA,B+1M_{{A}, {B}}+1MA,B+1, 其中MA,BM_{{A}, {B}}MA,B 是⟨A1,A2,⋯ ,Am⟩\left\langle A_{1}, A_{2}, \cdots, A_{m}\right\rangle⟨A1,A2,⋯,Am⟩ 和 ⟨B1,B2,⋯ ,Bn⟩\left\langle B_{1},B_{2}, \cdots, B_{n}\right\rangle⟨B1,B2,⋯,Bn⟩ 的最大匹配。MA,BM_{\mathrm{A}, \mathrm{B}}MA,B 可以通过动态规划算法得到。
(2)当RAR_{A}RA和RBR_{B}RB的标记不相同时,返回0

计算网页结构相似度
给定两个HTML文档,它们对应的结构树为 T1T_{1}T1,T2T_{2}T2。T1T_{1}T1 和 T2T_{2}T2 中每一个结点标记对应HTML文件中一个标签.
定义T1T_{1}T1 与 T2T_{2}T2 的相似度为:
Similarity (T1,T2)= Simple TreeMatching (T1,T2)(∣T1∣+∣T2∣)/2 \text { Similarity }\left(T_{1}, T_{2}\right)=\frac{\text { Simple TreeMatching }\left(T_{1}, T_{2}\right)}{\left(\left|T_{1}\right|+\left|T_{2}\right|\right) / 2} Similarity (T1,T2)=(∣T1∣+∣T2∣)/2 Simple TreeMatching (T1,T2)
其中,∣T1∣\left|T_{1}\right|∣T1∣,∣T2∣\left|T_{2}\right|∣T2∣ 分别表示两棵树中结点数目,SimpleTreeMatching(T1,T2)\left(T_{1}, T_{2}\right)(T1,T2) 表示这两棵树的最大匹配结点数.
两棵树的最大匹配结点数越多,则两颗树越相似,它们所代表的 HTML文档也就越相似。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 1
1 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)