使用Python进行帧提取及指定帧插入实现文本隐写(CTF杂项出题方向)
关键帧是视频中特定时间点上的帧,这些帧是完整保存的图像。视频的分辨率影响图像的清晰度。将文本插入到视频帧中的位置通常选择在图像的较为平坦或者复杂的区域,以减小插入内容对整体图像的影响,提高隐蔽性。视频是由一系列连续的图像帧组成的,每一帧都是视频的静止画面。将文本放置在视频帧的角落,可以选择左上、右上、左下或右下,这样的位置相对不引人注意。,尤其是高速运动的区域,可以选择在这些区域插入文本,运动模糊
视频是由一系列连续的图像帧组成的,每一帧都是视频的静止画面。这些帧以一定的速率播放,就形成了运动的视频。以下是视频帧的一些基本概念:
-
帧率(Frame Rate): 帧率表示每秒播放的图像帧数量。通常以“帧/秒”(fps)为单位。常见的视频帧率包括 24fps、30fps、60fps 等。较高的帧率可以提供更加流畅的动画效果。
-
分辨率(Resolution): 分辨率表示图像的宽度和高度。通常以像素为单位,例如,1920x1080 表示宽度为1920像素,高度为1080像素。视频的分辨率影响图像的清晰度。
-
关键帧(Key Frame): 关键帧是视频中特定时间点上的帧,这些帧是完整保存的图像。其他帧可能只存储与前一帧的差异(运动信息),以减小文件大小。关键帧通常出现在视频中的场景变化或运动明显的地方。
-
帧间压缩(Interframe Compression): 为了减小视频文件的大小,视频编码器通常使用帧间压缩技术。这种技术通过保存连续帧之间的差异来减小存储需求。帧间压缩包括预测运动、差分编码等技术。
-
播放速度(Playback Speed): 播放速度决定了视频的播放速率。较慢的播放速度会使视频变慢,而较快的播放速度会加速视频。这与帧率有关,但也可以通过调整帧率以外的参数来实现。
-
时长(Duration): 时长表示视频的总播放时间,通常以秒为单位。
首先附上一个可以提取出视频所有的帧的脚本
其中需要指定两个参数:video_path, output_folder
即原视频的位置路径和提取出来的帧输出的位置
import cv2
import os
def extract_frames(video_path, output_folder):
# 确保输出文件夹存在
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 打开视频文件
cap = cv2.VideoCapture(video_path)
# 获取视频的帧率和总帧数
fps = cap.get(cv2.CAP_PROP_FPS)
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
# 循环读取并保存每一帧
for frame_number in range(total_frames):
ret, frame = cap.read()
# 如果成功读取帧,则保存
if ret:
frame_path = os.path.join(output_folder, f"frame_{frame_number:04d}.jpg")
cv2.imwrite(frame_path, frame)
else:
break
# 关闭视频流
cap.release()
# 使用示例
video_path = 'D:/test/myon.mp4'
output_folder = 'D:/test/zhen'
extract_frames(video_path, output_folder)
我们演示一下使用上述代码进行帧提取
这是一个7秒的视频,我们一个提取出了217帧
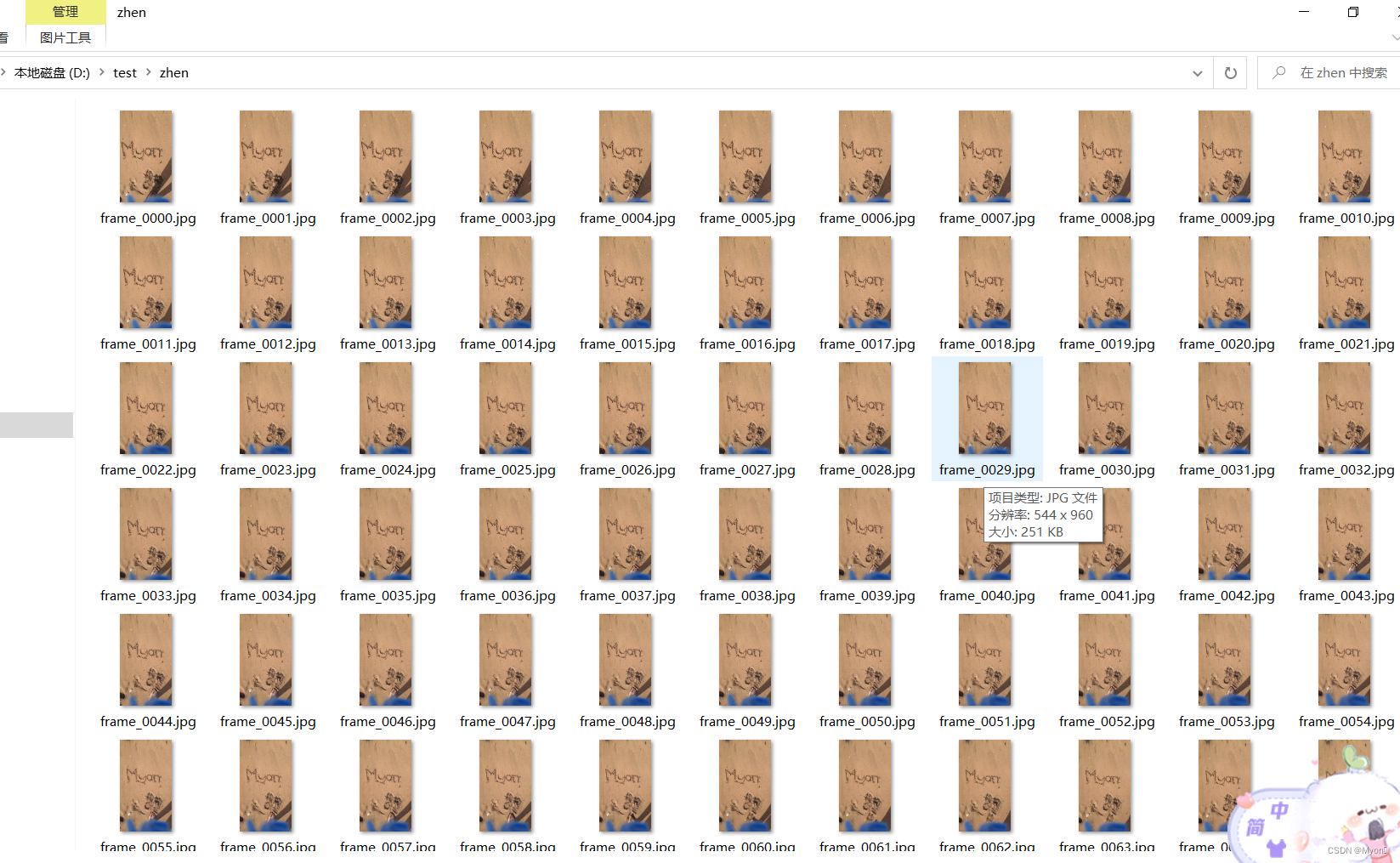
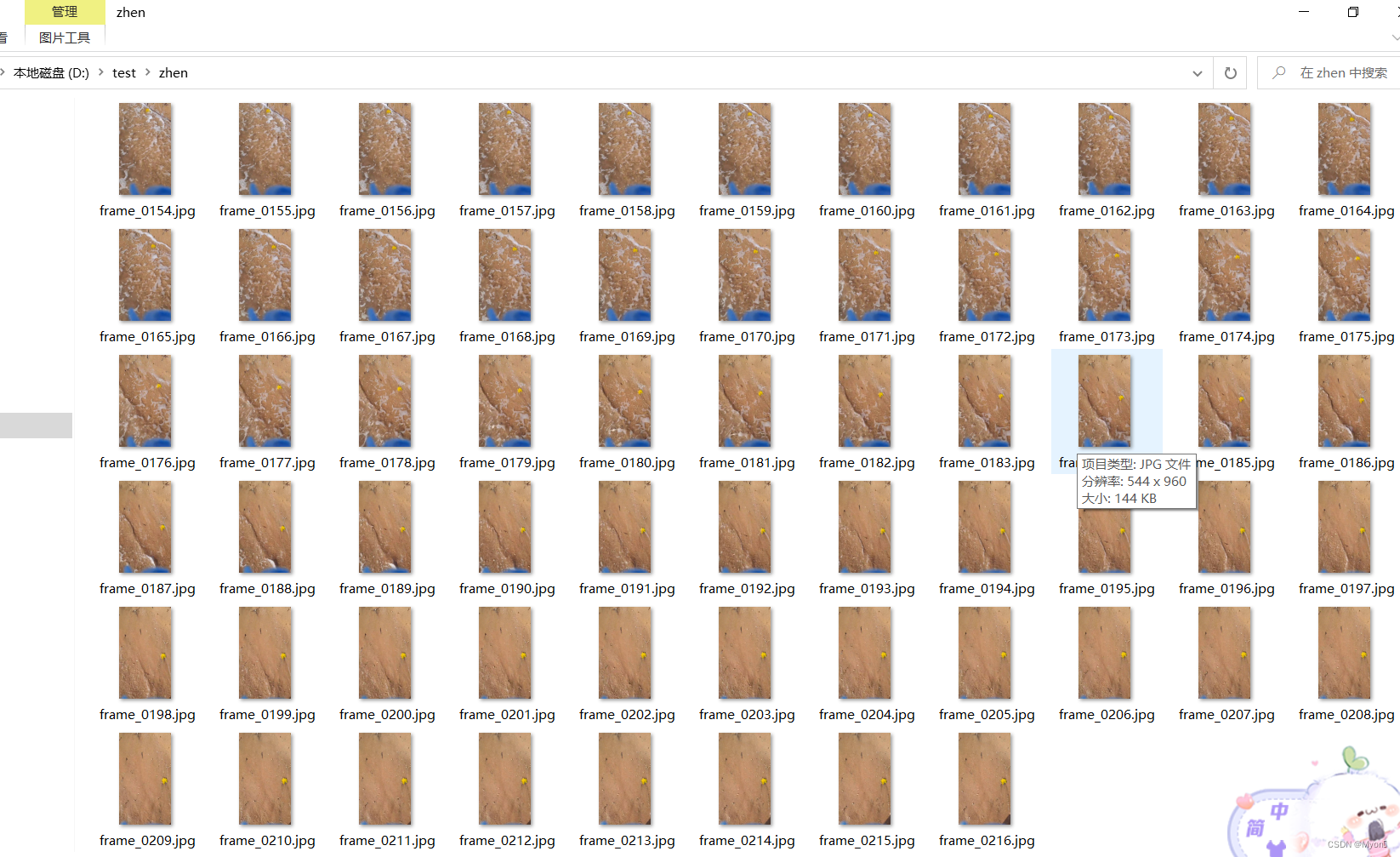
接下来我们尝试在指定某个帧的位置进行文本内容插入
代码如下:
import cv2
def insert_text_to_specific_frame(video_path, output_path, target_frame_number, text, font=cv2.FONT_HERSHEY_SIMPLEX, font_scale=2, color=(0, 0, 255), thickness=3):
cap = cv2.VideoCapture(video_path)
# 获取视频的基本信息
fps = cap.get(cv2.CAP_PROP_FPS)
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
# 确保目标帧数在有效范围内
if target_frame_number < 0 or target_frame_number >= total_frames:
print("Error: Target frame number is out of range.")
cap.release()
return
# 创建 VideoWriter 对象,用于保存插入文本后的视频
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
output = cv2.VideoWriter(output_path, fourcc, fps, (width, height))
# 逐帧读取视频,插入文本,并写入输出视频
for frame_number in range(total_frames):
ret, frame = cap.read()
# 如果帧读取成功
if ret:
# 如果是目标帧,插入文本
if frame_number == target_frame_number:
text_size = cv2.getTextSize(text, font, font_scale, thickness)[0]
text_position = ((width - text_size[0]) // 2, (height + text_size[1]) // 2)
cv2.putText(frame, text, text_position, font, font_scale, color, thickness)
# 写入输出视频
output.write(frame)
else:
print(f"Error: Unable to read frame {frame_number} from input video.")
break
# 释放资源
cap.release()
output.release()
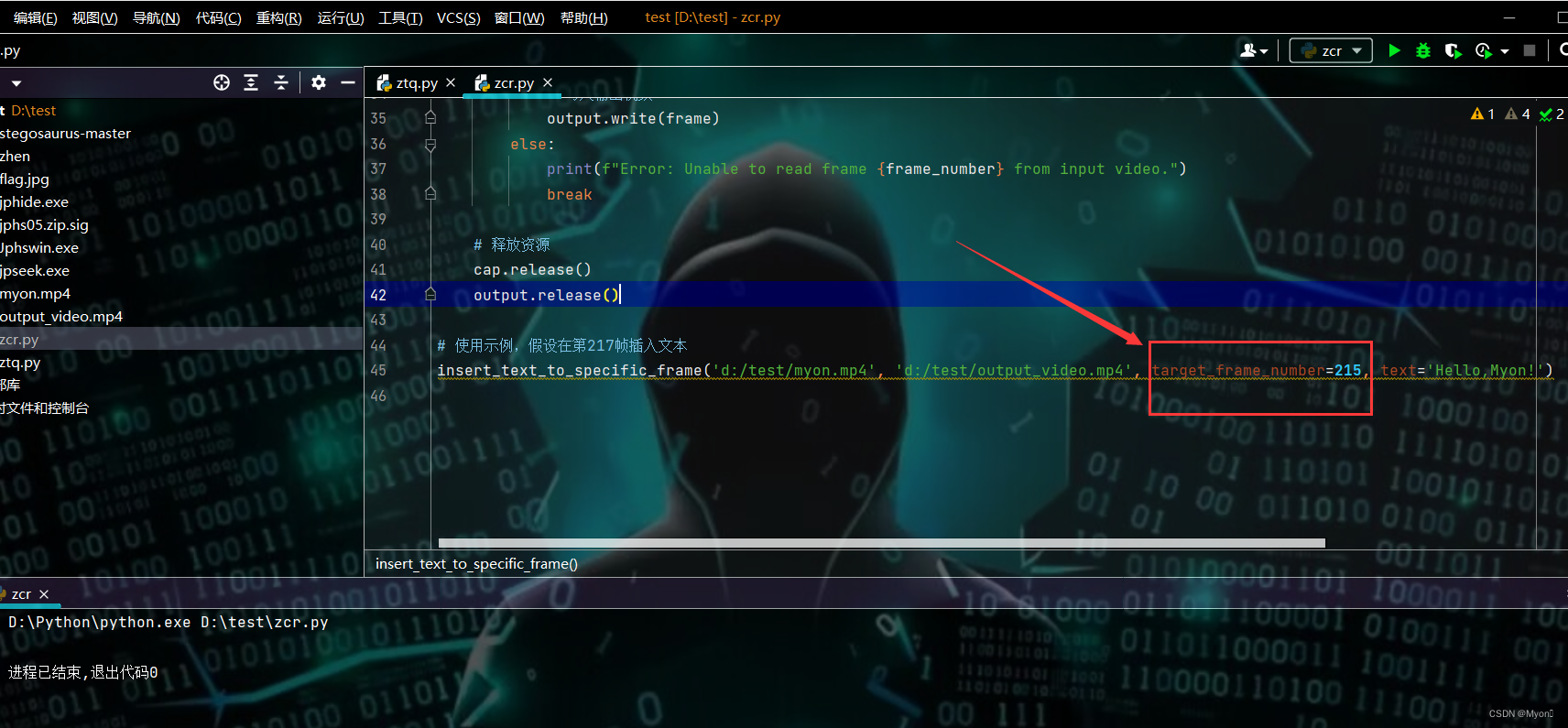
# 使用示例,假设在第50帧插入文本
insert_text_to_specific_frame('d:/test/myon.mp4', 'd:/test/output_video.mp4', target_frame_number=49, text='Hello, CTF!')
注意:需要对 video_path, output_path, target_frame_number 进行替换;
第一个参数为原视频路径,第二个参数为视频输出的路径,第三个参数指定插入位置;
从0开始计为第一帧,假设我们插入到第50帧则对应的number为49。
对插入文本内容后的视频进行帧提取得到结果如下图:
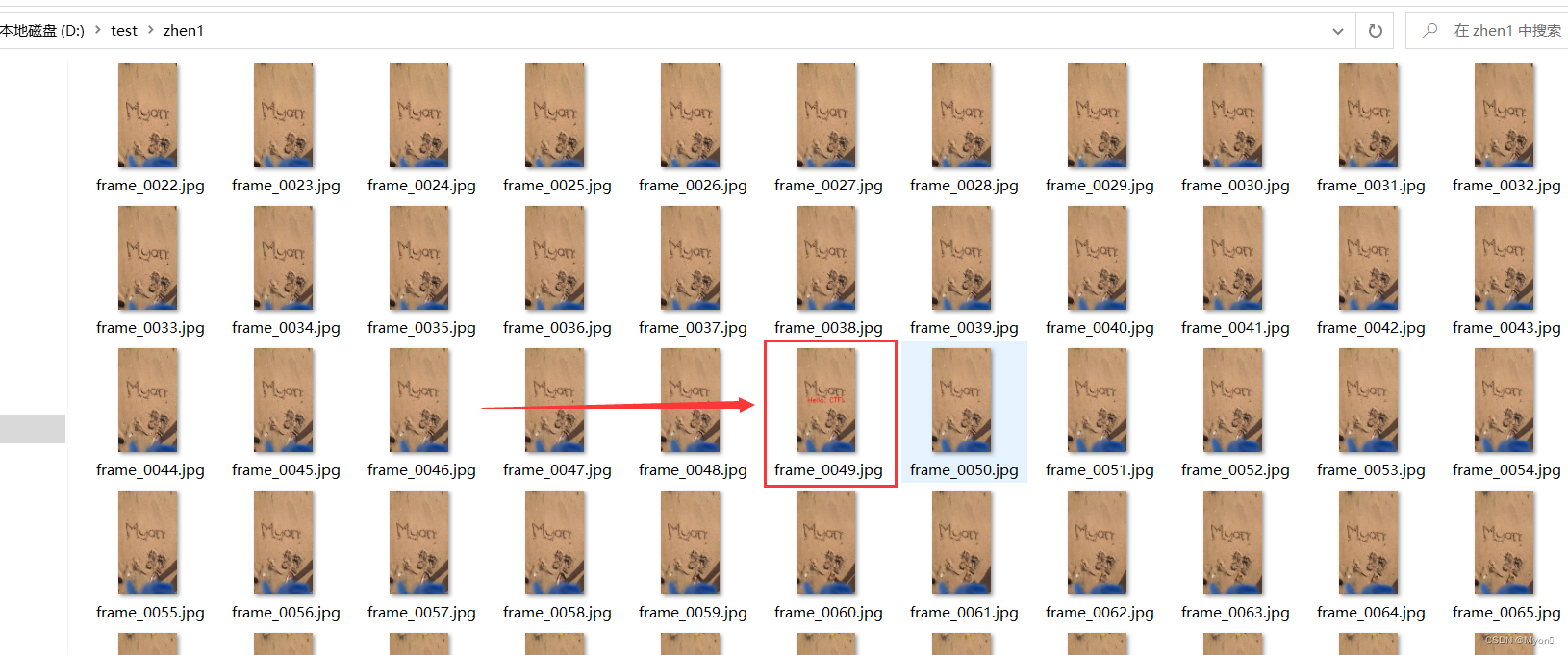
其实单独看这个视频,也是可以发现插入的内容的:(因为我这里刻意做得很明显)
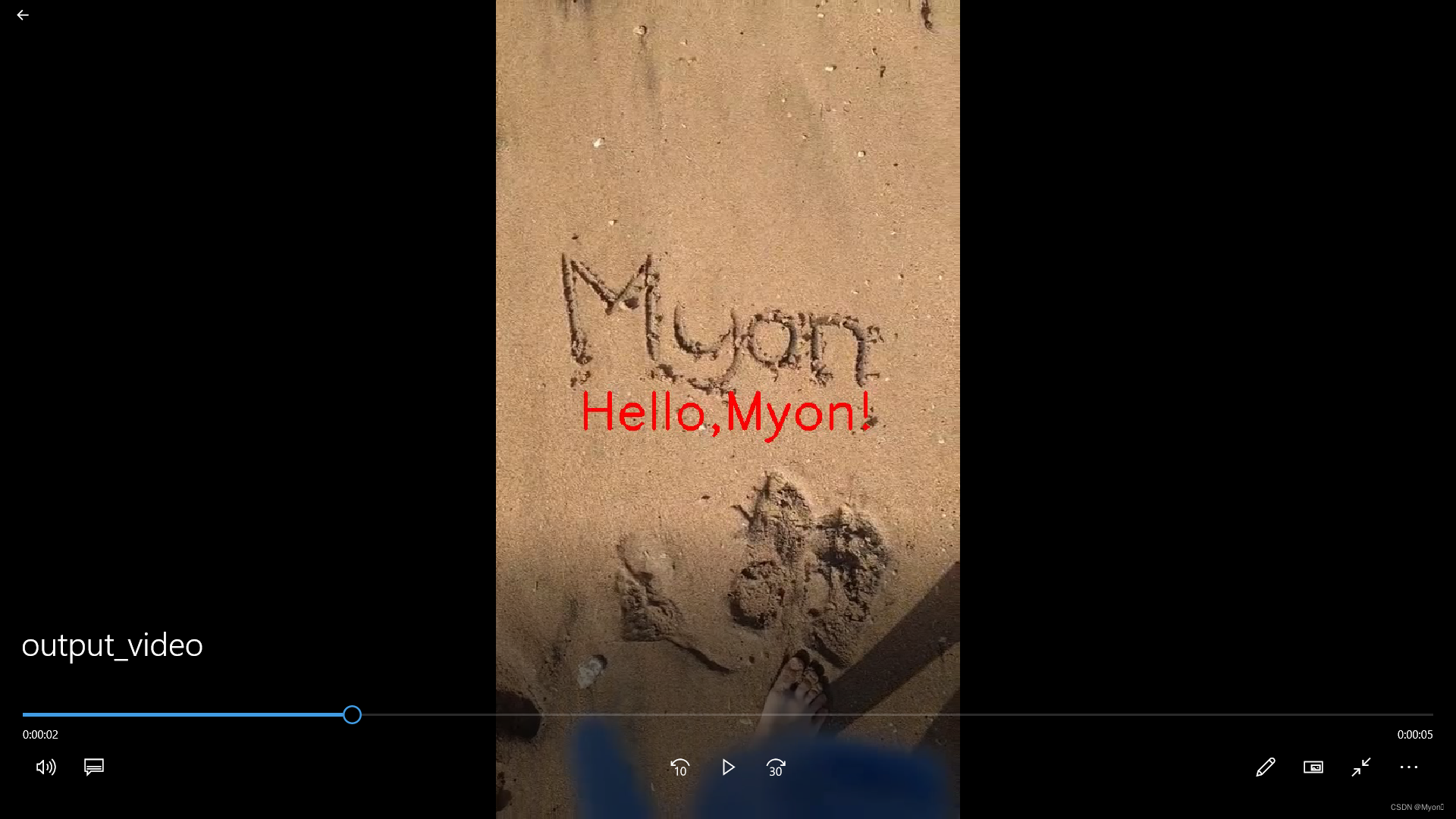
这个插入文本内容的位置及字体大小颜色我们是可以进行设置的
将文本插入到视频帧中的位置通常选择在图像的较为平坦或者复杂的区域,以减小插入内容对整体图像的影响,提高隐蔽性。以下是一些可能的插入位置:
-
底部边缘: 在视频帧的底部边缘添加文本,这是比较常见的位置。
-
角落: 将文本放置在视频帧的角落,可以选择左上、右上、左下或右下,这样的位置相对不引人注意。
-
运动模糊区域: 在视频中存在运动的部分,尤其是高速运动的区域,可以选择在这些区域插入文本,运动模糊可以帮助隐藏文本的存在。
-
复杂纹理区域: 选择视频帧上的复杂纹理区域,比如树叶、花纹等,可以使插入的文本相对不容易被察觉。
-
颜色变化不显著的区域: 选择颜色变化不太显著的区域,例如天空、墙壁等,可以减小插入内容对整体图像的影响。
-
对比度低的区域: 在对比度较低的区域插入文本,可以减小文本与周围图像的差异,提高隐蔽性。
顺便说一下:有些播放器存在缺陷,会自动删减掉最后几帧,导致我们无法观察到隐写的东西,因此我们也常将一些关键信息藏在视频结尾。
上述视频一个有217帧,比如我将文本内容插到第216帧,对应数字215:
如下图,尽管我开了0.5倍半速播放,但是视频结尾的内容依旧被省略了
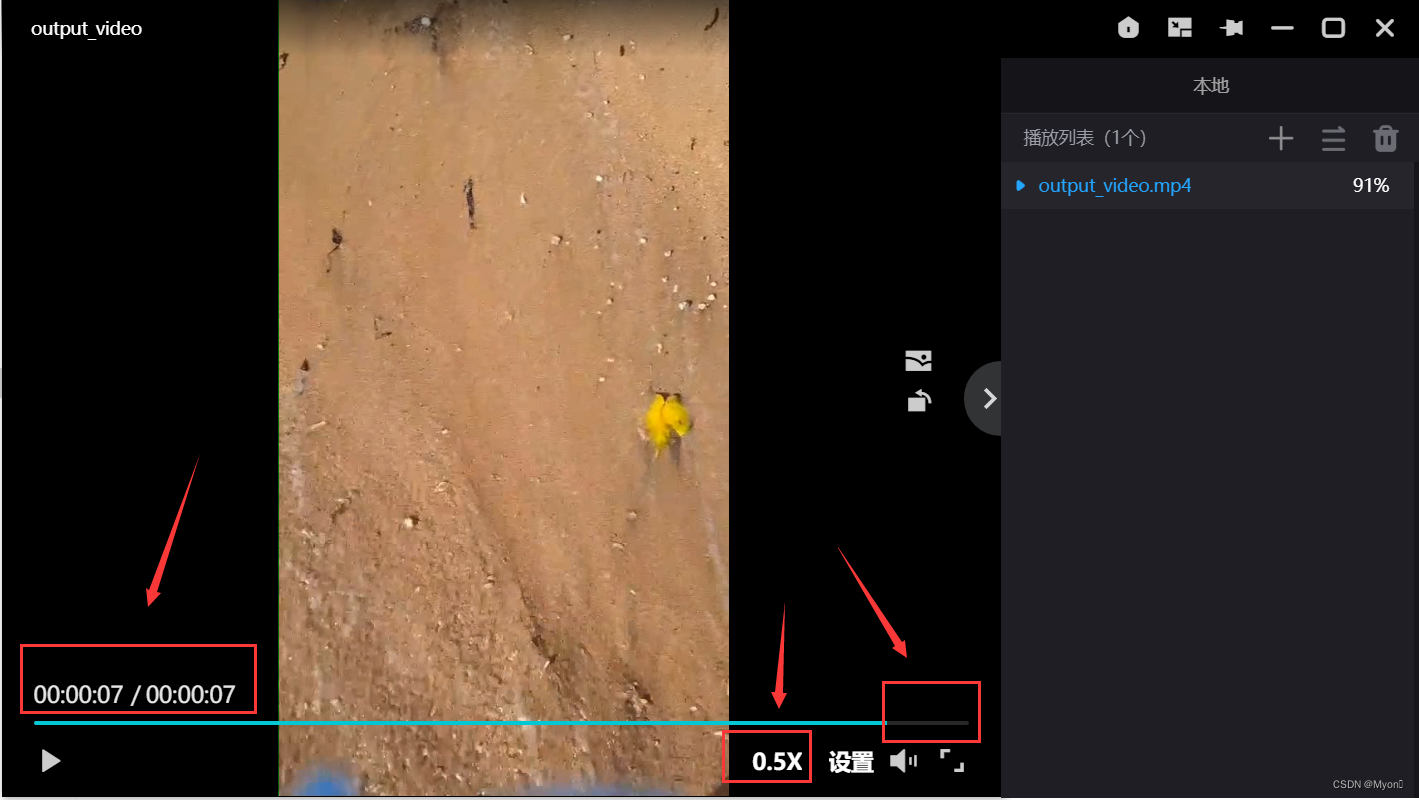
有些肉眼无法识别到的东西只有通过提取视频的帧来获取
可能这个东西很简单吧但这确实可以作为CTF出题的方向
我也遇到过这类题,如下图

所以这里分享给大家也了解一下~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 53
53 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)