【python机器学习】Day18 聚类后簇的含义
作业:参考示例代码对心脏病数据集采取类似操作,并且评估特征工程后模型效果有无提升。
·
聚类后的分析:推断簇的类型
知识点:
- 推断簇含义的2个思路:(1)先选特征(2)后选特征
- 可视化图形后,借助ai定义簇的含义
- 科研逻辑闭环:通过精度,判断特征工程价值(跑一遍监督学习)
# 如何分析聚类簇的含义?
1.将聚类特征簇作为标签,进行模型训练(预测)
2.使用shap库分析哪些特征对聚类的簇贡献最大
3.交给AI分析图表,总结簇的含义
作业:参考示例代码对心脏病数据集采取类似操作,并且评估特征工程后模型效果有无提升。
(1)前期准备
import pandas as pd #用于数据处理和分析,可处理表格数据。
import numpy as np #用于数值计算,提供了高效的数组操作。
import matplotlib.pyplot as plt #用于绘制各种类型的图表
import seaborn as sns #基于matplotlib的高级绘图库,能绘制更美观的统计图形。
import warnings
warnings.filterwarnings("ignore")
# 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系统常用黑体字体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
data = pd.read_csv(r'E:\cjx\2.【打卡】python训练营\python60-days-challenge-master\heart.csv') #读取数据
data.head()
# 获取数值型变量列、也是连续特征列
continuous_features = data.select_dtypes(include=['int64', 'float64']).columns.tolist()
from sklearn.model_selection import train_test_split
X = data.drop(['target'], axis=1) # 特征,axis=1表示按列删除
y = data['target'] # 标签
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans, DBSCAN, AgglomerativeClustering
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import seaborn as sns
# 标准化数据(聚类前通常需要标准化)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X) # X是划分数据集的特征集(2)KMeans聚类
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
import matplotlib.pyplot as plt
import seaborn as sns
# 评估不同 k 值下的指标
k_range = range(2, 11) # 测试 k 从 2 到 10
inertia_values = []
silhouette_scores = []
ch_scores = []
db_scores = []
for k in k_range:
kmeans = KMeans(n_clusters=k, random_state=42)
kmeans_labels = kmeans.fit_predict(X_scaled)
inertia_values.append(kmeans.inertia_) # 惯性(肘部法则)
silhouette = silhouette_score(X_scaled, kmeans_labels) # 轮廓系数
silhouette_scores.append(silhouette)
ch = calinski_harabasz_score(X_scaled, kmeans_labels) # CH 指数
ch_scores.append(ch)
db = davies_bouldin_score(X_scaled, kmeans_labels) # DB 指数
db_scores.append(db)
print(f"k={k}, 惯性: {kmeans.inertia_:.2f}, 轮廓系数: {silhouette:.3f}, CH 指数: {ch:.2f}, DB 指数: {db:.3f}")
# 绘制评估指标图
plt.figure(figsize=(15, 10))
# 肘部法则图(Inertia)
plt.subplot(2, 2, 1)
plt.plot(k_range, inertia_values, marker='o')
plt.title('肘部法则确定最优聚类数 k(惯性,越小越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('惯性')
plt.grid(True)
# 轮廓系数图
plt.subplot(2, 2, 2)
plt.plot(k_range, silhouette_scores, marker='o', color='orange')
plt.title('轮廓系数确定最优聚类数 k(越大越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('轮廓系数')
plt.grid(True)
# CH 指数图
plt.subplot(2, 2, 3)
plt.plot(k_range, ch_scores, marker='o', color='green')
plt.title('Calinski-Harabasz 指数确定最优聚类数 k(越大越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('CH 指数')
plt.grid(True)
# DB 指数图
plt.subplot(2, 2, 4)
plt.plot(k_range, db_scores, marker='o', color='red')
plt.title('Davies-Bouldin 指数确定最优聚类数 k(越小越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('DB 指数')
plt.grid(True)
plt.tight_layout()
plt.show()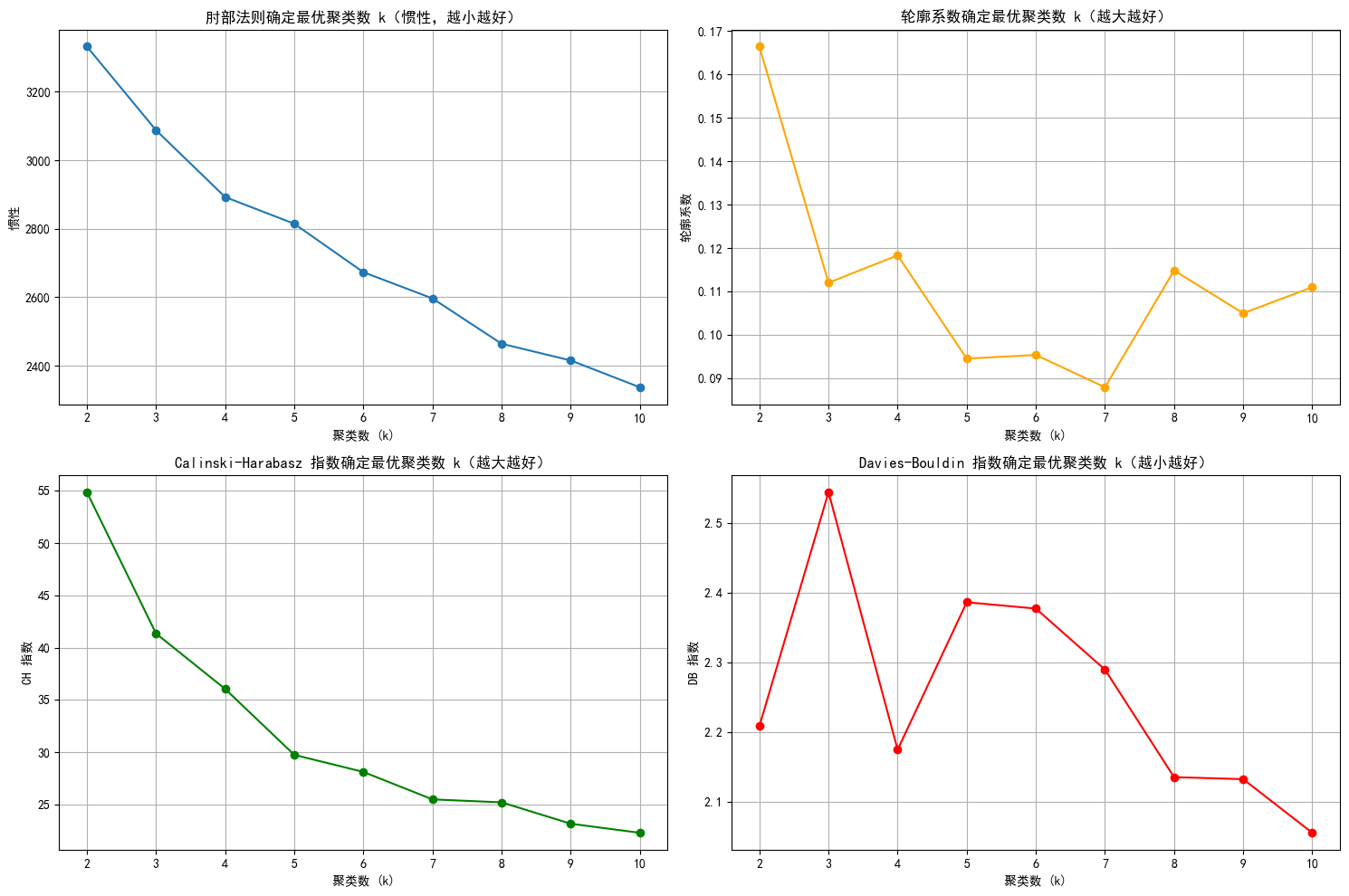
根据图表,选取k值
# 根据图表,选择 k 值
selected_k = 4
# 使用选择的 k 值进行 KMeans 聚类
kmeans = KMeans(n_clusters=selected_k, random_state=42)
kmeans_labels = kmeans.fit_predict(X_scaled)
X['KMeans_Cluster'] = kmeans_labels
# 使用 PCA 降维到 2D 进行可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
# KMeans 聚类结果可视化
plt.figure(figsize=(6, 5))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=kmeans_labels, palette='viridis')
plt.title(f'KMeans Clustering with k={selected_k} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()
# 打印 KMeans 聚类标签的前几行
print(f"KMeans Cluster labels (k={selected_k}) added to X:")
print(X[['KMeans_Cluster']].value_counts())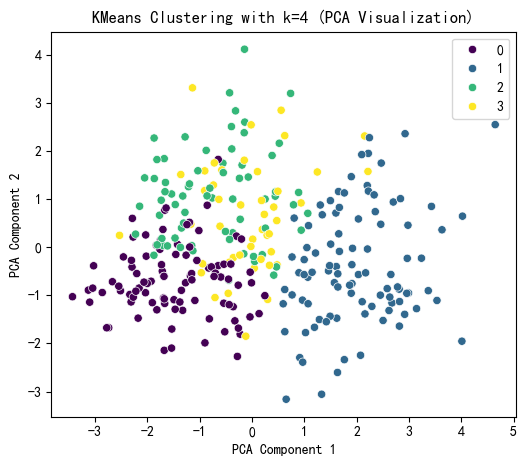
(3)shap库分析
# 加入聚类特征,进行模型训练,分析哪些特征对聚类的簇贡献最大
x1= X.drop('KMeans_Cluster',axis=1) # 删除聚类标签列
y1 = X['KMeans_Cluster']
# 构建随机森林,用shap重要性来筛选重要性
import shap
import numpy as np
from sklearn.ensemble import RandomForestClassifier # 随机森林分类器
model = RandomForestClassifier(n_estimators=100, random_state=42) # 随机森林模型
model.fit(x1, y1) # 训练模型,此时无需在意准确率 直接全部数据用来训练了
shap.initjs()
# 初始化 SHAP 解释器
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(x1) # 这个计算耗时
shap_values.shape # 第一维是样本数,第二维是特征数,第三维是类别数
# --- 1. SHAP 特征重要性条形图 (Summary Plot - Bar) ---
print("--- 1. SHAP 特征重要性条形图 ---")
shap.summary_plot(shap_values[:, :, 0], x1, plot_type="bar",show=False) # 这里show=False表示不直接显示图形,这样用plt来修改元素,不然就直接输出了
plt.title("SHAP Feature Importance (Bar Plot)")
plt.show()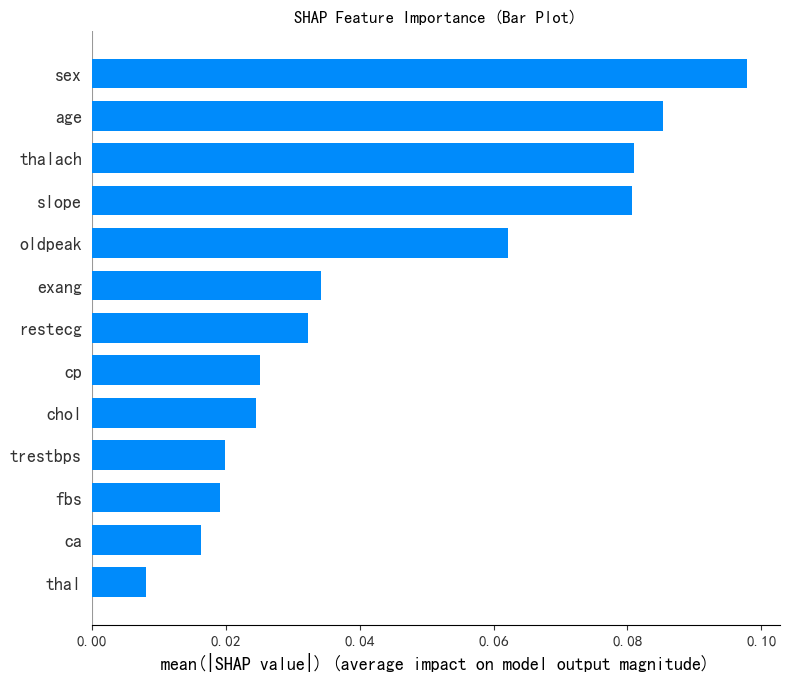
# 此时判断一下这几个特征是离散型还是连续型,这里通过数值的数量判断
# 连续型变量通常有很多唯一值,而离散型变量的唯一值较少
import pandas as pd
selected_features = [ 'sex','age',
'thalach','slope']
for feature in selected_features:
unique_count = X[feature].nunique() # 唯一值指的是在某一列或某个特征中,不重复出现的值
print(f'{feature} 的唯一值数量: {unique_count}')
if unique_count < 10: # 这里 10 是一个经验阈值,可以根据实际情况调整
print(f'{feature} 可能是离散型变量')
else:
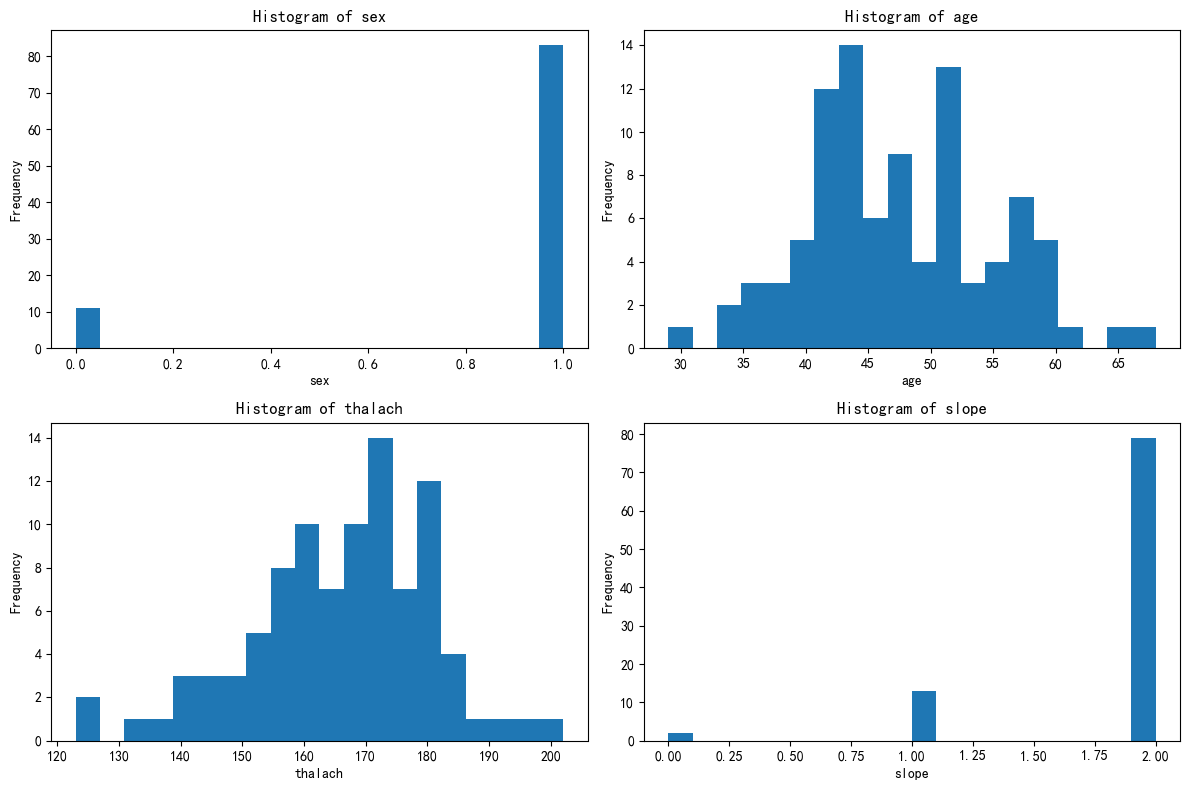
print(f'{feature} 可能是连续型变量')# 总样本中的前四个重要性的特征分布图
import matplotlib.pyplot as plt
# 总样本中的前四个重要性的特征分布图
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
axes = axes.flatten()
for i, feature in enumerate(selected_features):
axes[i].hist(X[feature], bins=20)
axes[i].set_title(f'Histogram of {feature}')
axes[i].set_xlabel(feature)
axes[i].set_ylabel('Frequency')
plt.tight_layout()
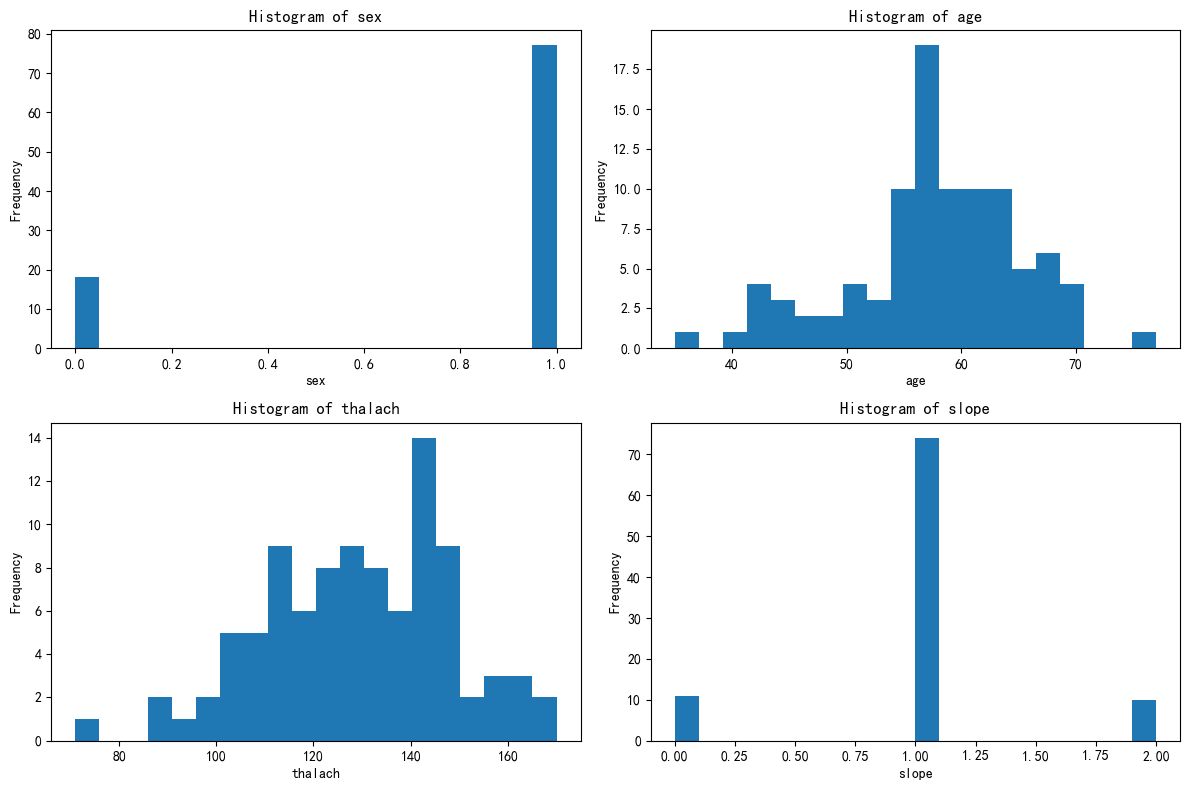
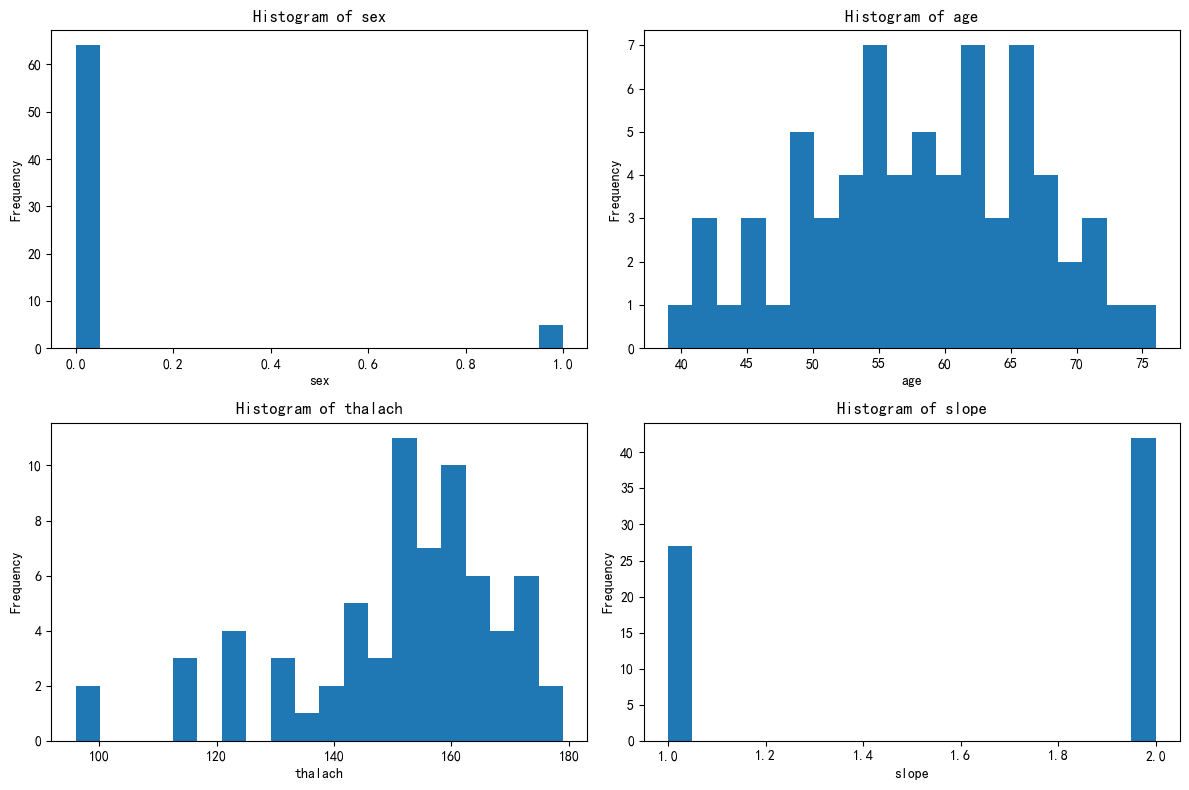
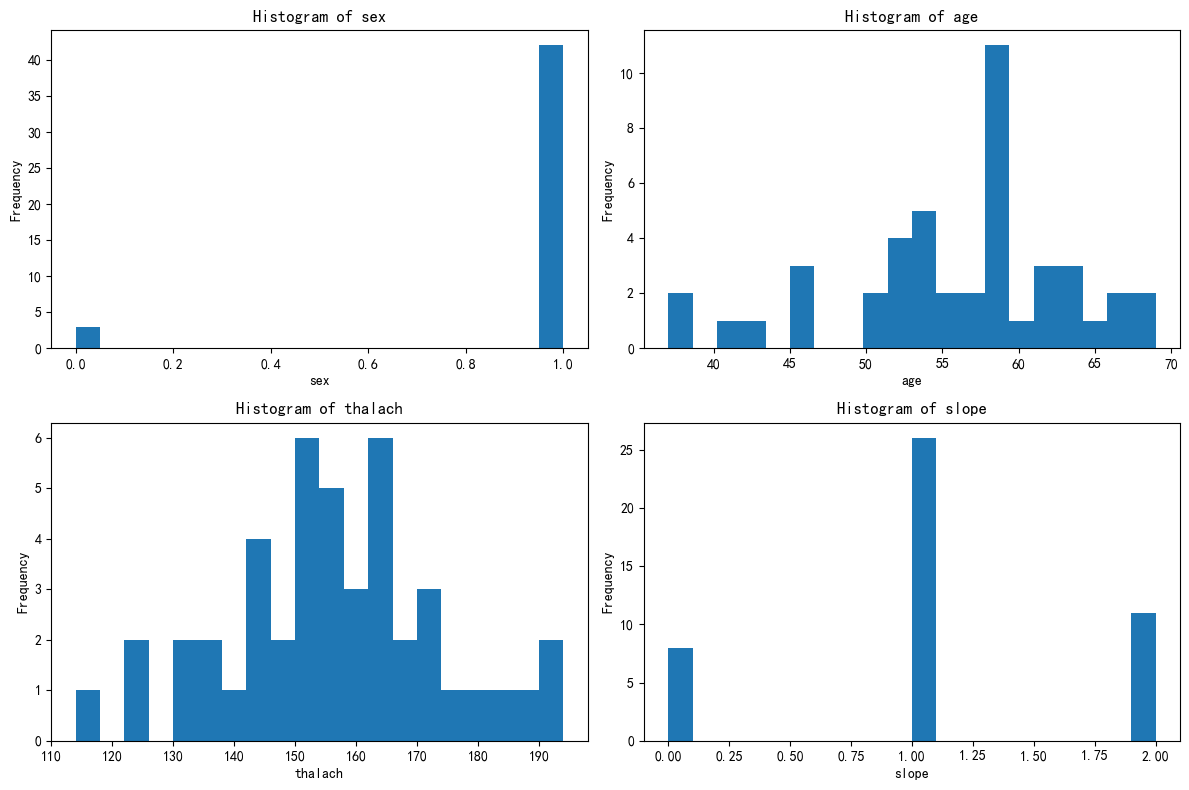
plt.show()# 绘制出每个簇对应的这四个特征的分布图
# 绘制出每个簇对应的这四个特征的分布图
X[['KMeans_Cluster']].value_counts()
# 先绘制簇0的分布图
import matplotlib.pyplot as plt
# 总样本中的前四个重要性的特征分布图
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
axes = axes.flatten()
for i, feature in enumerate(selected_features):
axes[i].hist(X_cluster0[feature], bins=20) # 选取簇0,更改123
axes[i].set_title(f'Histogram of {feature}')
axes[i].set_xlabel(feature)
axes[i].set_ylabel('Frequency')
plt.tight_layout()
plt.show()

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)