CBAM注意力
CBAM注意力
·
本文旨在分享一种将通道注意力与空间注意力结合的方法。
首先解释一下空间注意力(通道注意力的解释可参考笔者的SE注意力)
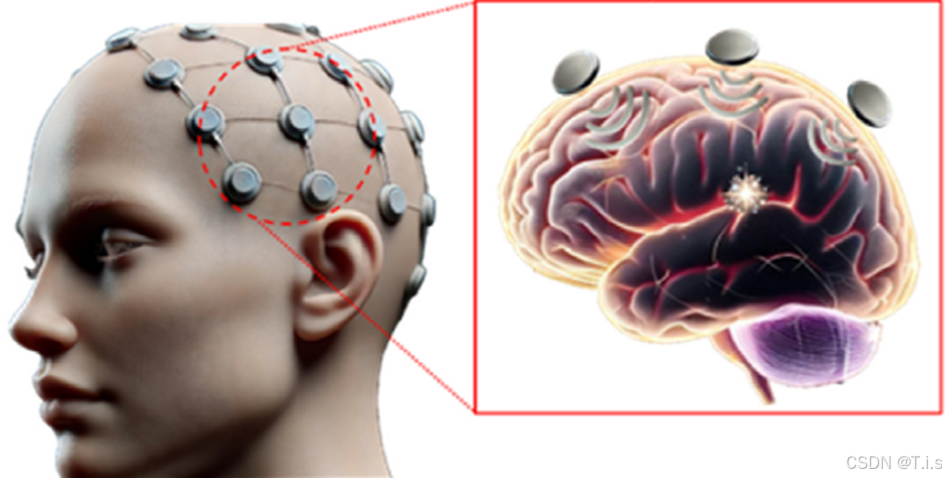
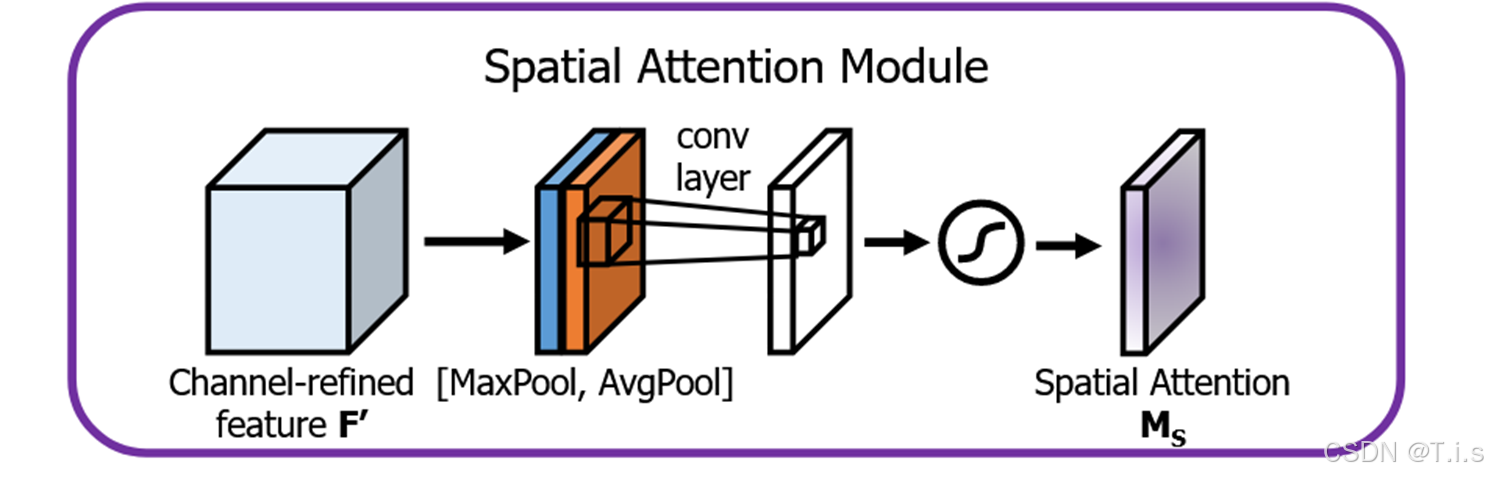
空间注意力(Spatial Attention)是一种用于提升深度学习模型对输入特征图中重要空间位置关注能力的机制。它通过为特征图中的每个空间位置分配一个权重,帮助模型聚焦于关键区域,从而增强重要特征并抑制不重要的特征。
在图片中每个像素(即空间位置)代表图片的一个局部区域。空间注意力根据这些像素的重要性赋予不同的权重,帮助模型更集中于有用的信息。在生理信号处理时,空间注意力的作用是帮助模型识别哪些传感器位置更重要。不同的生理信号和任务对不同位置的依赖可能会不一样。

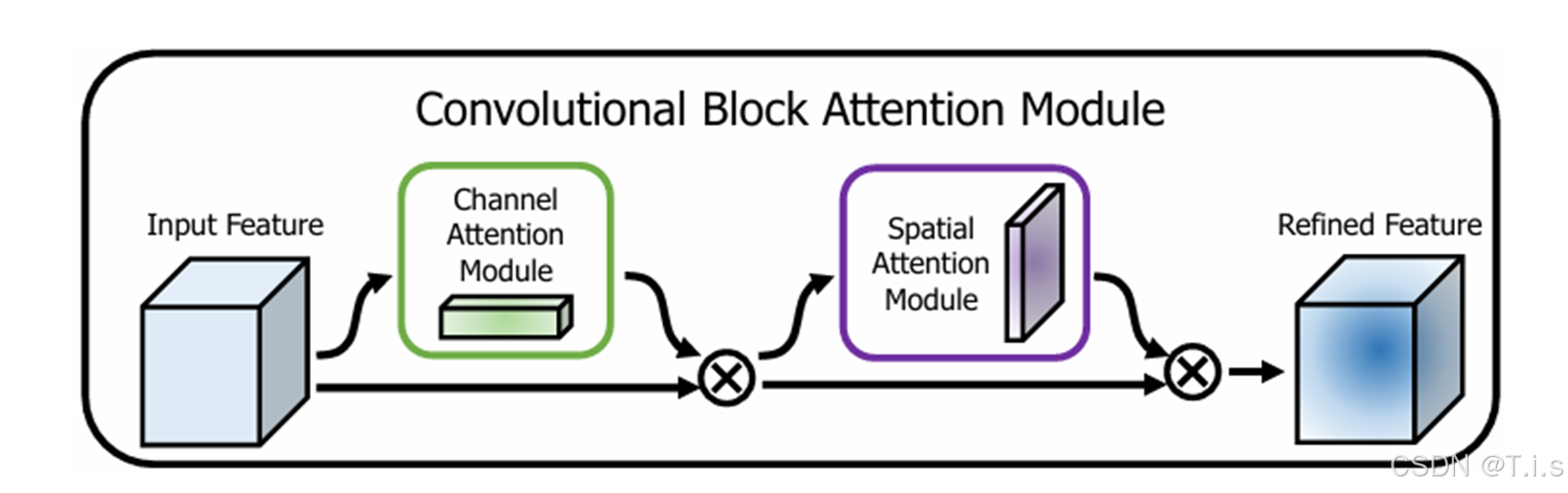
具体解释CBAM注意力:
参考文献:Woo, Sanghyun , et al. "CBAM: Convolutional Block Attention Module." Springer, Cham (2018).
CBAM 模块通过通道注意力和空间注意力结合的方式,增强了网络对重要特征的关注能力。相比于单一的注意力机制,CBAM 能够同时捕捉通道维度和空间维度的重要性,从而提升模型的整体表现。
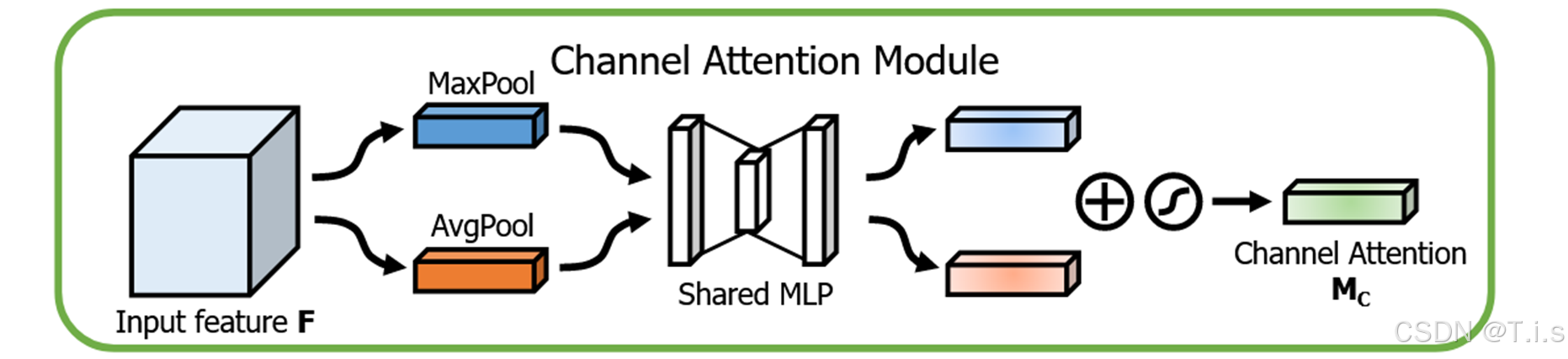
其中通道注意力为:
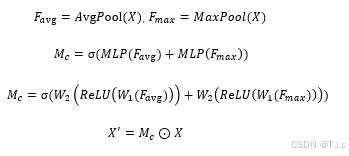
空间注意力为:
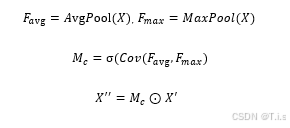
import torch
import torch.nn as nn
import torch.nn.functional as F
class ChannelAttention(nn.Module):
def __init__(self, in_channels, reduction=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc = nn.Sequential(
nn.Linear(in_channels, in_channels // reduction, bias=False),
nn.ReLU(),
nn.Linear(in_channels // reduction, in_channels, bias=False)
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
b, c, _, _ = x.size()
avg_out = self.fc(self.avg_pool(x).view(b, c))
max_out = self.fc(self.max_pool(x).view(b, c))
out = avg_out + max_out
out = self.sigmoid(out).view(b, c, 1, 1)
return x * out
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
self.conv = nn.Conv2d(2, 1, kernel_size=kernel_size, padding=kernel_size // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
out = torch.cat([avg_out, max_out], dim=1)
out = self.sigmoid(self.conv(out))
return x * out
class CBAM(nn.Module):
def __init__(self, in_channels, reduction=16, kernel_size=7):
super(CBAM, self).__init__()
self.channel_attention = ChannelAttention(in_channels, reduction)
self.spatial_attention = SpatialAttention(kernel_size)
def forward(self, x):
x = self.channel_attention(x)
x = self.spatial_attention(x)
return x

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 5
5 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)