何恺明和LeCun新作:Transformer没有归一化层行吗?
就在刚刚,Transformer架构迎来突破!何恺明、LeCun、刘壮联手,用9行代码砍掉了Transformer「标配」归一化层,创造了性能不减反增的奇迹
人工智能(AI)在现代社会中的作用日益增强,从自然语言处理、计算机视觉到自动驾驶和生物医学研究,AI 技术的突破正在改变各个行业的发展模式。随着 AI 规模的不断扩大,对计算效率和模型性能的要求也在提高,而在这一趋势下,作为 AI 关键技术之一的 Transfermer 受到了越来越多的关注。
Transfermer 是对 Transformer 结构的一种优化,它在提升计算效率的同时,保留了 Transformer 处理长序列依赖的优势,使其在 NLP、CV 以及多模态任务中的表现更加突出。它采用了改进的注意力机制、更高效的内存管理以及优化的位置编码,减少了计算复杂度,使大规模模型训练变得更加可行。因此,Transfermer 被认为是下一代 AI 发展中的核心架构之一。
Normalization Layers(归一化层) 在深度学习中起着关键作用,它们的主要目的是对输入数据或隐藏层的激活值进行标准化,以减少分布的偏移,提高模型训练的稳定性。在深度神经网络中,数据的分布在不同层之间会发生变化,这种变化被称为 内部协变量偏移(Internal Covariate Shift)。如果不加以控制,训练时梯度可能会出现震荡,导致收敛变慢,甚至可能出现梯度消失或梯度爆炸的问题。
归一化层的引入能够有效缓解这些问题。例如,批量归一化(Batch Normalization, BN) 通过在每个 mini-batch 内标准化数据分布,减少了参数对初始权重的敏感性,使训练更快收敛。而在像 Transfermer 这样的 Transformer 结构中,层归一化(Layer Normalization, LN) 更为常见,它针对单个样本的特征进行标准化,适用于序列建模任务,可以避免因批量大小变化导致的不稳定性。此外,实例归一化(Instance Normalization, IN) 和 组归一化(Group Normalization, GN) 也被广泛应用于计算机视觉和其他任务,以适应不同的数据特点。
但是在最近的一篇工作中,MIT的何恺明,图灵奖得主杨立昆(Yann LeCun)以及Meta的刘壮联手对transformer中归一化层的作用和必要性提出了质疑。他们发现,即使不使用归一化层的Transformer模型,也就能达到相同甚至更好的性能!
该论文一作 Jiachen Zhu 为纽约大学四年级博士生、二作陈鑫磊(Xinlei Chen)为 FAIR 研究科学家,项目负责人为刘壮。

什么是归一化层?
过去十年,归一化层已经巩固了其作为现代神经网络最基本组件之一的地位。这一切可以追溯到 2015 年批归一化(batch normalization)的发明,它使视觉识别模型的收敛速度变得更快、更好,并在随后几年中获得迅速发展。从那时起,研究人员针对不同的网络架构或领域提出了许多归一化层的变体。
如今,几乎所有现代网络都在使用归一化层,其中层归一化(Layer Norm,LN)是最受欢迎之一,特别是在占主导地位的 Transformer 架构中。
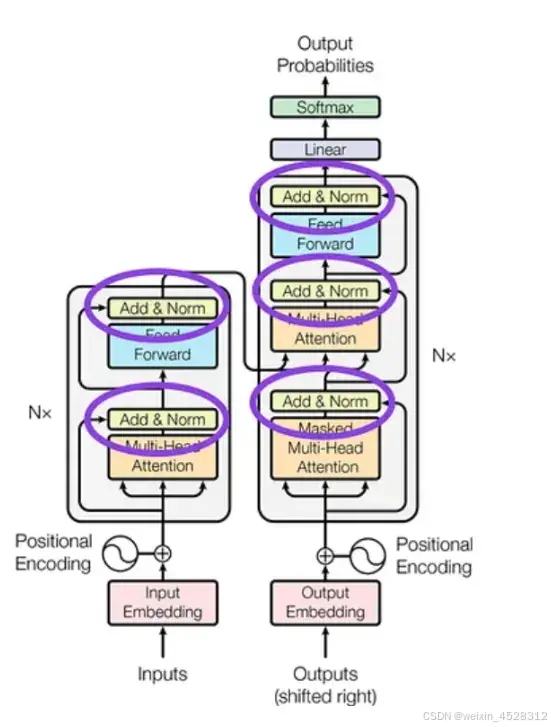
图1. 经典的transformer结构图示,其中蓝线圈上的部分为归一化层。
归一化层的广泛应用很大程度上得益于它们在优化方面的实证优势。除了实现更好的结果之外,归一化层还有助于加速和稳定收敛。随着神经网络变得越来越宽、越来越深,归一化层的必要性变得越来越重要。因此,研究人员普遍认为归一化层对于有效训练深度网络至关重要,甚至是必不可少的。这一观点事实上得到了微妙证明:近年来,新架构经常寻求取代注意力层或卷积层,但几乎总是保留归一化层。
本文中,研究者提出了 Transformer 中归一化层的一种简单平替。他们的探索始于以下观察:LN 层使用类 tanh 的 S 形曲线将其输入映射到输出,同时缩放输入激活并压缩极值。
受此启发,研究者提出了一种元素级运算,称为 Dynamic Tanh(DyT),定义为:DyT (x) = tanh (αx),其中 α 是一个可学习参数。此运算旨在通过 α 学习适当的缩放因子并通过有界 tanh 函数压缩极值来模拟 LN 的行为。值得注意的是,与归一化层不同,DyT 可以实现这两种效果,而无需计算激活数据。
DyT 使用起来非常简单,如下图 2 所示,研究者直接用 DyT 替换视觉和语言 Transformer 等架构中的现有归一化层。实证结果表明,使用 DyT 的模型可以在各种设置中稳定训练并获得较高的最终性能。同时,DyT 通常不需要在原始架构上调整训练超参数。
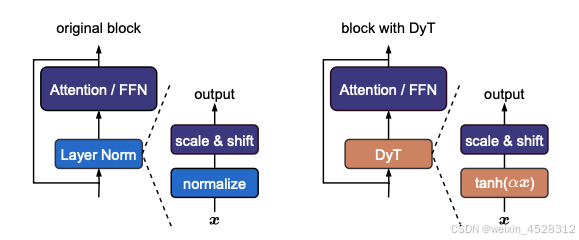
图2. 左:原始transformer模块。右:作者提议的动态Tanh(DyT)层块。
DyT 模块可以通过短短 9 行 PyTorch 代码就可以实现:
class DyT(nn.Module):
def __init__(self, num_features, alpha_init_value=0.5):
super().__init__()
self.alpha = nn.Parameter(torch.ones(1) * alpha_init_value)
self.weight = nn.Parameter(torch.ones(num_features))
self.bias = nn.Parameter(torch.zeros(num_features))
def forward(self, x):
x = torch.tanh(self.alpha * x)
return x * self.weight + self.bias
该工作挑战了「归一化层对训练现代神经网络必不可少」这一观念,并提供了有关归一化层属性的实证见解。此外,初步结果表明,DyT 可以提升训练和推理速度,从而成为以效率为导向的网络设计的候选方案。
归一化层有什么作用?
要去掉 Transformer 中的归一化层,首先要做的当然是了解归一化层有什么用。
该团队通过实证研究对此进行了分析。为此,他们使用了三个不同的经过训练的 Transformer 模型:一个 Vision Transformer(ViT-B)、一个 wav2vec 2.0 Large Transformer 和一个 Diffusion Transformer(DiT-XL)。
他们使用这三个模型采样了一小批样本,并让其前向通过整个网络。然后,他们监测了其中归一化层的输入和输出,即归一化操作前后的张量。
由于 LN 会保留输入张量的维度,因此可以在输入和输出张量元素之间建立一一对应关系,从而可以直接可视化它们的关系。这个映射关系见下图。
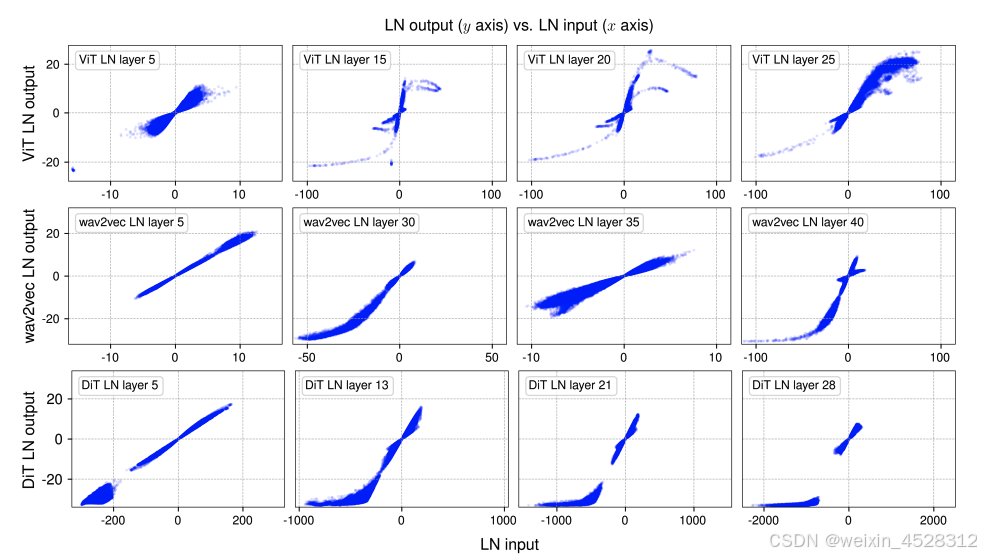
图 3. 选定层归一化(LN)层的输出与输入对比,涉及的模型包括视觉 Transformer(ViT)、用于语音的 Transformer 模型 wav2vec 2.0以及扩散 Transformer(DiT)。
具有层归一化的类 tanh 映射。对于这三个模型,该团队发现,它们的早期 LN 层的输入 - 输出关系基本上是线性的。但是,更深的 LN 层却有更有趣的表现。
可以观察到,这些曲线的形状大多与 tanh 函数表示的完整或部分 S 形曲线非常相似。
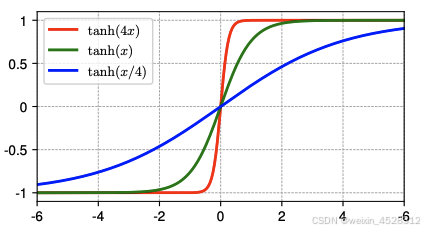
图 4. 不同 α 值下的 tanh(αx) 函数曲线。
人们可能预期 LN 层会对输入张量进行线性变换,因为减去平均值和除以标准差都是线性运算。LN 以每个 token 的方式进行归一化,仅对每个 token 的激活进行线性变换。
由于 token 具有不同的平均值和标准差,因此这种线性并不对输入张量的所有激活都成立。尽管如此,该团队表示依然很惊讶:实际的非线性变换竟然与某个经过缩放的 tanh 函数高度相似!
对于这样一个 S 型曲线,可以看到其中心部分(x 值接近零的部分)仍然主要呈线性形状。大多数点(约 99%)都属于这个线性范围。但是,仍有许多点明显超出此范围,这些点被认为具有「极端」值,例如 ViT 模型中 x 大于 50 或小于 -50 的点。
归一化层对这些值的主要作用是将它们压缩为不太极端的值,从而与大多数点更加一致。这是归一化层无法通过简单的仿射变换层近似的地方。
该团队假设,这种对极端值的非线性和不成比例的压缩效应正是归一化层的关键之处。
前段时间的一篇论文《On the Nonlinearity of Layer Normalization》同样重点指出了 LN 层引入的强非线性,并且表明这种非线性可以增强模型的表征能力 (https://arxiv.org/abs/2406.01255)。
此外,这种压缩行为还反映了生物神经元对大输入的饱和(saturation)特性,这种现象大约一个世纪前就已经被观察到。
token 和通道的归一化。LN 层如何对每个 token 执行线性变换,同时以这种非线性方式压缩极端值呢?
为了理解这一点,该团队分别按 token 和通道对这些点进行可视化。图 5 给出了 ViT 的第二和第三个子图的情况,但为了更清晰,图中使用了采样的点子集。
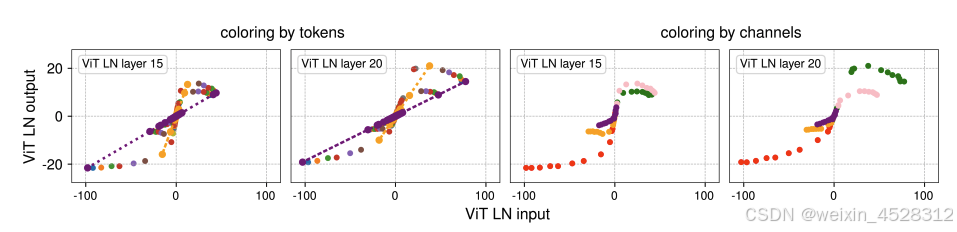
图 5. 两个层归一化(LN)层的输出与输入对比,张量元素通过颜色标注以区分不同的通道和标记(token)维度。
在图 5 左边两个小图中,使用了同一颜色标记每个 token 的激活。可以观察到,任何单个 token 的所有点确实都会形成一条直线。但是,由于每个 token 都有不同的方差,因此斜率也不同。输入 x 范围较小的 token 往往具有较小的方差,并且归一化层将使用较小的标准偏差来除它们的激活,从而让直线有较大的斜率。
总的来说,它们形成了一条类似于 tanh 函数的 S 形曲线。在右侧的两个小图中,同样使用相同的颜色标记各个通道的激活。可以看到,不同通道的输入范围往往存在巨大差异,只有少数通道(例如红色、绿色和粉色)会表现出较大的极端值 —— 而这些通道正是被归一化层压缩得最厉害的。
动态函数: Dynamic Tanh(DyT)
洞悉本质,方能创新。鉴于归一化层与扩展版 tanh 函数在机制上的相似性,研究团队提出了 Dynamic Tanh(DyT),并证明其可作为归一化层的直接替代方案。
给定一个输入张量 x,DyT 层的定义如下:
![]()
其中 α 是一个可学习的标量参数,允许根据输入的范围以不同的方式缩放输入,并会考虑不同的 x 尺度。也因此,他们将整个操作命名为「动态」tanh。γ 和 β 是可学习的每通道向量参数,与所有归一化层中使用的参数相同 —— 它们允许输出缩放到任何尺度。这有时被视为单独的仿射层;这里,该团队将它们视为 DyT 层的一部分,就像归一化层也包括它们一样。算法 1 给出了用类 PyTorch 的伪代码实现的 DyT。

要想将 DyT 层集成到现有架构中,方法很简单:直接用一个 DyT 层替换一个归一化层(见上图)。这适用于注意力块、FFN 块和最终归一化层内的归一化层。
尽管 DyT 可能看起来像或可被视为激活函数,但本研究仅使用它来替换归一化层,而不会改变原始架构中激活函数的任何部分,例如 GELU 或 ReLU。网络的其他部分也保持不变。该团队还观察到,几乎不需要调整原始架构使用的超参数即可使 DyT 表现良好。
尽管 DyT 可能看起来像或可被视为激活函数,但本研究仅使用它来替换归一化层,而不会改变原始架构中激活函数的任何部分,例如 GELU 或 ReLU。网络的其他部分也保持不变。该团队还观察到,几乎不需要调整原始架构使用的超参数即可使 DyT 表现良好。
关于缩放参数。在这里,总是简单地将 γ 初始化为全一向量,将 β 初始化为全零向量,后接归一化层。对于 scaler 参数 α,除了 LLM 训练外,默认初始化为 0.5 通常就足够了。除非另有明确说明,否则在后续的实验中,α 均被初始化为 0.5。
说明。DyT 并非一种新型的归一化层,因为它在前向传递过程中会独立地对张量中的每个输入元素进行操作,而无需计算统计数据或其他类型的聚合。但它确实保留了归一化层的效果,即以非线性方式压缩极端值,同时对输入的中心部分执行近乎线性的变换。
DyT 在实验中的表现
为了验证 DyT 的效果,研究团队在不同任务和领域中测试了 Transformer 及其他架构,将原始架构中的 LN 或 RMSNorm 替换为 DyT 层,并按照官方开源方案进行训练和测试。
1. 视觉监督学习
研究团队在 ImageNet-1K 分类任务上训练了 Base 和 Large 两种规模的 Vision Transformer(ViT)和 ConvNeXt 模型。
选择 ViT 和 ConvNeXt 是因为它们既具代表性,又分别采用不同机制:ViT 基于注意力机制,ConvNeXt 基于卷积操作。从表 1 的 Top-1 分类准确率来看,DyT 在两种架构和不同规模模型上均优于 LN。
表 1. ImageNet-1K 上的监督分类准确率。DyT 在不同架构和模型规模下均表现出优于或与 LN 相当的性能。
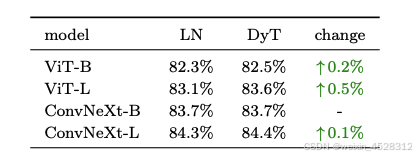
图 6 中展示的 ViT-B 和 ConvNeXt-B 的训练损失曲线。
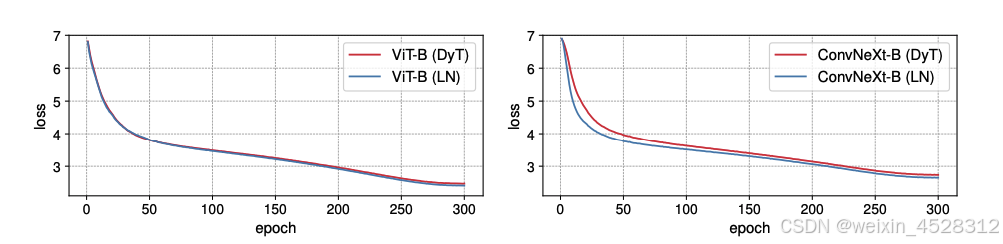 图 6 ViT-B 和 ConvNeXt-B 模型的训练损失曲线。两种模型在使用 LN 和 DyT 时的损失曲线表现出相似的模式,这表明 LN 和 DyT 可能具有相似的学习动态。
图 6 ViT-B 和 ConvNeXt-B 模型的训练损失曲线。两种模型在使用 LN 和 DyT 时的损失曲线表现出相似的模式,这表明 LN 和 DyT 可能具有相似的学习动态。
2. 视觉自监督学习
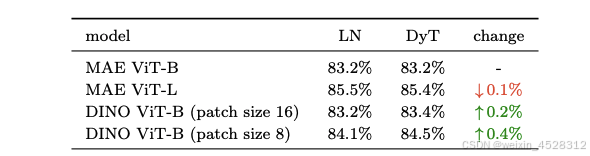
研究团队测试了两种流行的视觉自监督学习方法:何恺明的 MAE 和 DINO。
这两种方法都默认使用 Vision Transformer 作为骨干网络,但训练目标不同。MAE 使用重建损失进行训练,而 DINO 则使用联合嵌入损失。研究团队先在 ImageNet-1K 数据集上进行无标签预训练,然后添加分类层并用标签数据微调来测试预训练模型。表 2 展示了微调的结果。在自监督学习任务中,DyT 和 LN 的表现基本持平。
表 2. ImageNet-1K 上的自监督学习准确率。在自监督学习任务中,DyT 在不同的预训练方法和模型规模下与 LN 表现相当。
3. 扩散模型
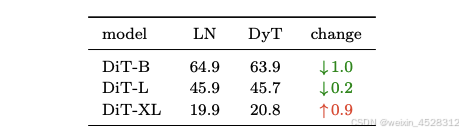
研究者在 ImageNet-1K 上训练了三个尺寸分别为 B、L 和 XL 的 DiT 模型。需要注意的是,在 DiT 中,LN 层的仿射参数用于类调节,DyT 实验中也保留了这一参数,只是用 tanh (αx) 函数替换了归一化迁移。训练结束,如表 3 所示,与 LN 相比,DyT 的 FID 值相当或有所提高。
表 3. ImageNet 上的图像生成质量(FID,数值越低越好)。DyT 在不同规模的 DiT 模型中实现了与 LN 相当或更优的 FID 分数。
4. 大语言模型 LLM
这些模型是按照 LLaMA 中概述的原始配方在带有 200B tokens 的 The Pile 数据集上进行训练的。在带有 DyT 的 LLaMA 中,研究者在初始嵌入层之后添加了一个可学习的标量参数,并调整了 α 的初始值(第 7 节)。下表 4 报告了训练后的损失值,并按照 OpenLLaMA 的方法,在 lm-eval 的 15 个零样本任务上对模型进行了基准测试。如表 4 所示,在所有四种规模的模型中,DyT 的表现与 RMSNorm 相当。
表 4. 语言模型在 15 个零样本 lm-eval 任务中的训练损失和平均表现。DyT 在零样本任务表现和训练损失方面与 RMSNorm 相当。
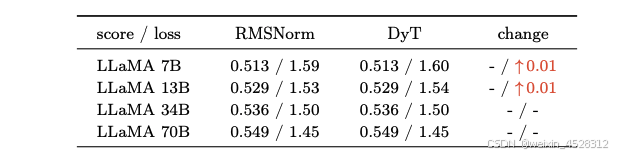
图 7 展示了损失曲线,显示了所有模型大小的相似趋势,训练损失在整个训练过程中都非常接近。
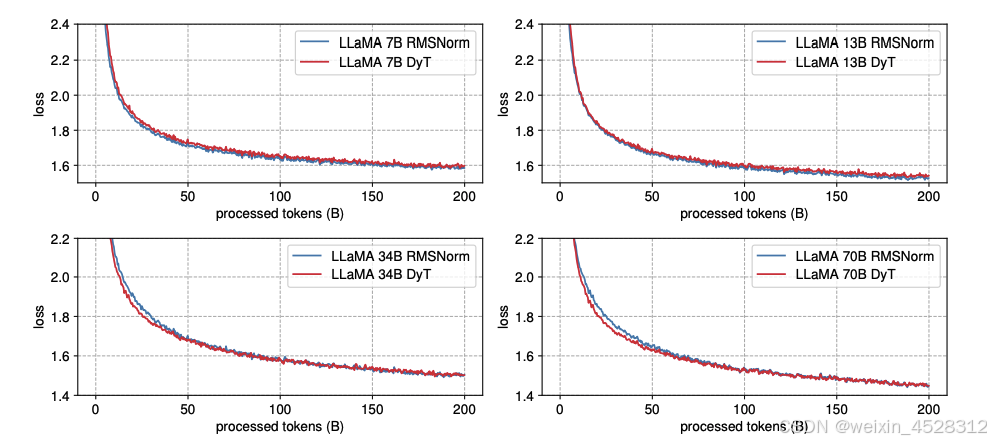
图 7. LLaMA 预训练损失。DyT 和 RMSNorm 模型在不同规模下的损失曲线高度一致。
5. 语音自监督学习
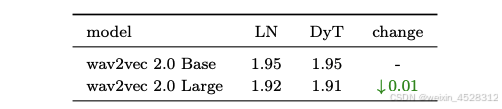
研究者在 LibriSpeech 数据集上预训练了两个 wav2vec 2.0 Transformer 模型。表 5 报告了最终的验证损失。在两种模型规模下,DyT 的表现都与 LN 相当。
表 5. LibriSpeech 语音预训练的验证损失。DyT 在 wav2vec 2.0 模型中的表现与 LN 相当。
6. DNA 序列建模
在长程 DNA 序列建模任务中,研究者对 HyenaDNA 模型和 Caduceus 模型进行了预训练。结果如表 6,在这项任务中,DyT 保持了与 LN 相当的性能。
表 6. GenomicBenchmarks 上的 DNA 分类准确率,结果为各数据集的平均值。DyT 在性能上与 LN 相当。
对 α 进行初始化
作者发现,对参数 α(记作 α₀)的初始化进行调优通常不会显著提升模型性能。唯一的例外是大型语言模型(LLM)训练,在这种情况下,对 α₀ 进行精细调整能够带来明显的性能提升。
1. 非 LLM 模型的 α 初始化
非 LLM 模型对 α₀ 相对不敏感。下图展示了在不同任务中改变 α₀ 对验证性能的影响。
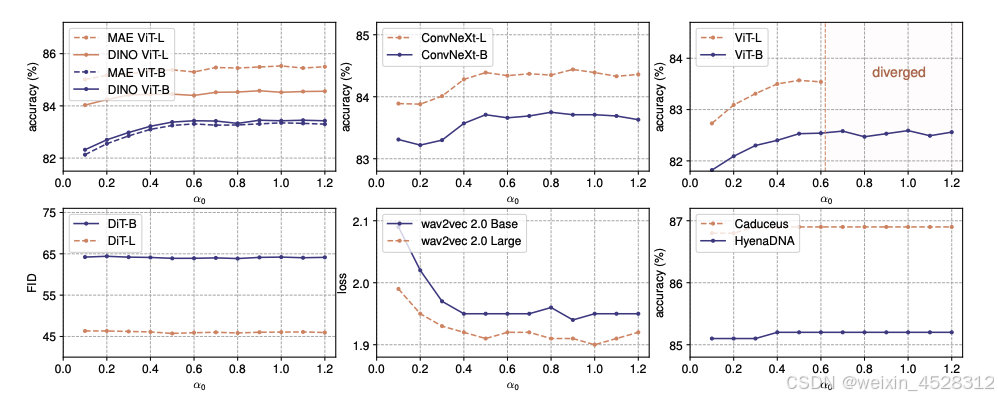
图 8. 不同 α₀ 值下各任务的性能表现。
α₀ 越小,训练越稳定。下图展示了使用 ImageNet-1K 数据集对有监督 ViT 训练稳定性的消减。
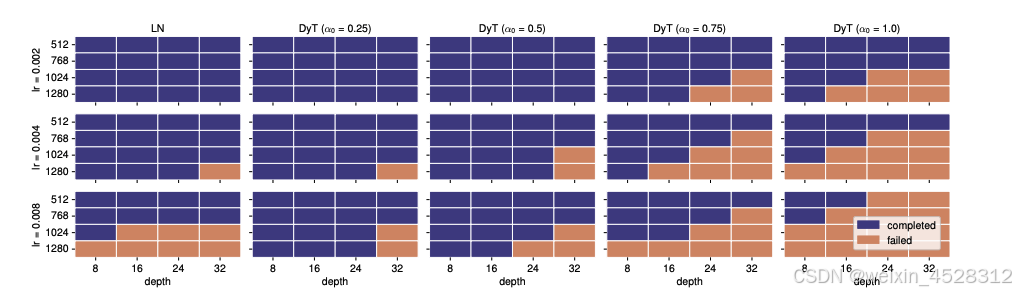 图 9. 在不同 α₀ 值、学习率和模型规模下的稳定性表现。
图 9. 在不同 α₀ 值、学习率和模型规模下的稳定性表现。
将 α₀ = 0.5 设为默认值。根据研究结果,研究者将 α₀ = 0.5 设置为所有非 LLM 模型的默认值。这种设置既能提供与 LN 相当的训练稳定性,又能保持强大的性能。
2. LLM 模型的 α 初始化
调整 α₀ 可以提高 LLM 性能。如前所述,默认设置 α₀ = 0.5 在大多数任务中表现良好。然而,研究者发现调整 α₀ 可以大幅提高 LLM 性能。他们对每个 LLaMA 模型都进行了 30B tokens 的预训练,并比较了它们的训练损失,从而调整了它们的 α₀。
表 7. 不同 LLaMA 模型的最优 α₀ 值。
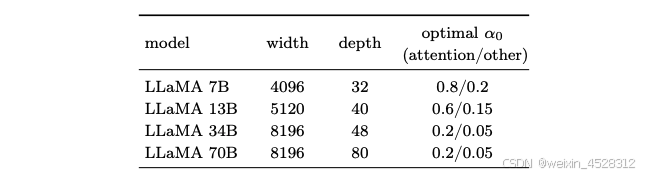
表 7 总结了每个模型的调整后 α₀ 值,其中有两个重要发现:
1. 较大的模型需要较小的 α₀ 值。一旦确定了较小模型的最佳 α₀ 值,就可以相应地缩小较大模型的搜索空间;
2. 注意力块的 α₀ 值越高,性能越好。对注意力块中的 DyT 层初始化较高的 α 值,而对其他位置(即 FFN 区块内或最终线性投影之前)的 DyT 层初始化较低的 α 值,可以提高性能。
为了进一步说明 α₀ 调整的影响,图 10 展示了两个 LLaMA 模型损失值的热图。这两个模型都受益于注意力块中较高的 α₀,从而减少了训练损失。
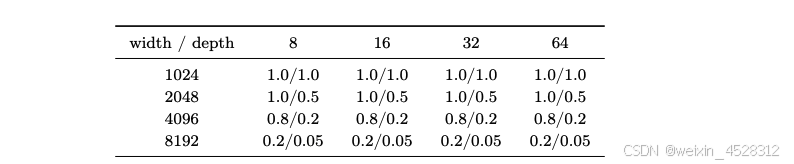
模型宽度主要决定了 α₀ 的选择。我们还研究了模型宽度和深度对最优 α₀ 的影响。研究者发现,模型宽度对确定最优 α₀ 至关重要,而模型深度的影响则微乎其微。表 8 显示了不同宽度和深度下的最佳 α₀ 值,表明较宽的网络可以从较小的 α₀ 值中获益,从而获得最佳性能。另一方面,模型深度对 α₀ 的选择影响微乎其微。
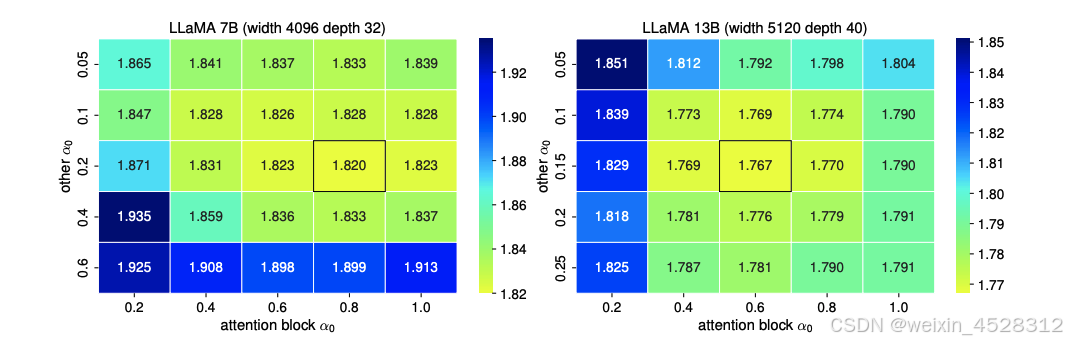
图 10. 不同 α₀ 设置下,在 300 亿 tokens 训练时的损失值热图。两种 LLaMA 模型在注意力块中受益于较大的 α₀
从表 8 中可以看出,网络越宽,「注意力」和「其他」所需的初始化就越不均衡。研究者假设,LLM 的 α 初始化的敏感度与其他模型相比过大的宽度有关。
表 8. LLaMA 训练中不同模型宽度和深度下的最优 α₀(注意力模块 / 其他模块)。
总结
在本研究中,作者证明了现代神经网络,特别是 Transformer,可以在不使用归一化层的情况下进行训练。他们通过 Dynamic Tanh(DyT) 实现了这一点,这是一种用于替代传统归一化层的简单方法。DyT 通过可学习的缩放因子 α 调整输入激活范围,然后利用 S 形的 tanh 函数抑制极端值。尽管 DyT 采用了更简单的函数形式,但它能够有效捕捉归一化层的作用。在不同实验条件下,采用 DyT 的模型在性能上能够匹敌甚至超越使用归一化层的模型。该研究挑战了关于归一化层在训练现代神经网络中必要性的传统认知,并有助于加深对归一化层机制的理解,作为深度神经网络中最基础的组成部分之一。
尽管如此,作者承认,他们在实验中采用 LN 和 RMSNorm,这两种归一化方法因其在 Transformer 及其他现代架构中的广泛应用而受到关注。初步实验表明,DyT 在经典网络(如 ResNets)中难以直接替代 BN。DyT 是否以及如何适应具有其他类型归一化层的模型仍需进一步研究。
参考文献:
1. Jiachen Zhu, Xinlei Chen, Kaiming He, Yann LeCun, Zhuang Liu. "Transformers without Normalization", arXiv:2503.10622 (2025).

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 30
30 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)