复现实验的心路历程
在命令行参数中指定。
顾名思义,我在复现别人的实验。笑死,一点也不好跑。一堆报错,还有好多的内容不懂。
现在我在这里记录一下我的心路历程。
通过网盘分享的文件:EstraNet-main.zip等2个文件
链接: https://pan.baidu.com/s/1Gt_KHiRWT-q4p0nrVP9KDA 提取码: hmip
--来自百度网盘超级会员v6的分享
关于这篇文献和实验的分析姊妹篇,我先罗列在下面了:
根据复现过实验的学长说的,如果只是要跑通代码,那么只要运行
这里的train_trains就可以了,如果有了错误,再慢慢纠正。
不过不论如何,先看README吧。
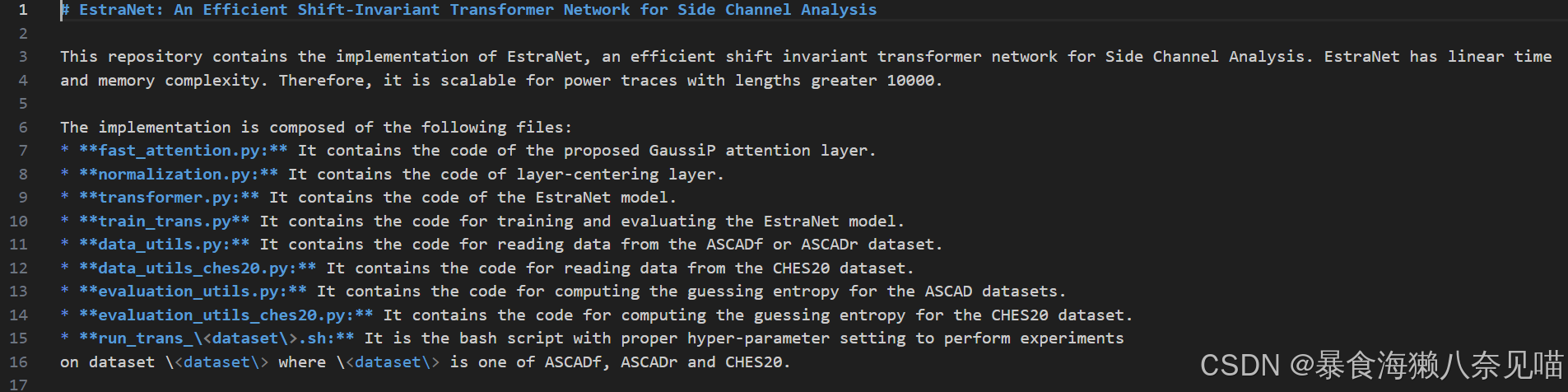
翻译如下:
EstraNet: 一种高效的平移不变变换器网络用于侧信道分析
本代码库包含了EstraNet的实现,这是一种用于侧信道分析的高效平移不变变换器网络。EstraNet具有线性的时间和内存复杂度,因此能够高效处理长度超过10,000的功率轨迹。
实现代码包含以下文件:
-
fast_attention.py: 包含提出的GaussiP注意力层代码
-
normalization.py: 包含层中心化层的实现代码
-
transformer.py: 包含EstraNet模型的完整实现
-
train_trans.py: 包含模型训练和评估的代码
-
data_utils.py: 提供从ASCADf/ASCADr数据集读取数据的工具
-
data_utils_ches20.py: 提供从CHES20数据集读取数据的工具
-
evaluation_utils.py: 包含ASCAD数据集的猜测熵计算模块
-
evaluation_utils_ches20.py: 包含CHES20数据集的猜测熵计算模块
-
run_trans_<数据集>.sh: 针对特定数据集(支持ASCADf/ASCADr/CHES20)的实验启动脚本,包含经过调优的超参数配置
(注:第一张工程包含文件中的train_new是我自己为了修改方便自建的,为了不破坏源代码,方便对比)
我用的python版本是3.9,对应的tensorflow什么的,还有各种软件包都是装齐了
那么现在我们来跑一跑这个train_trains吧:
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import os
import math
import time
import random
import pickle
from absl import flags
import absl.logging as _logging # pylint: disable=unused-import
import tensorflow as tf
import data_utils
import data_utils_ches20
from transformer import Transformer
import evaluation_utils
import evaluation_utils_ches20
import pickle
import numpy as np
# GPU config
flags.DEFINE_bool("use_tpu", default=False,
help="Use TPUs rather than plain CPUs.")
# Experiment (data/checkpoint/directory) config
flags.DEFINE_string("data_path", default="",
help="Path to data file")
flags.DEFINE_string("dataset", default="ASCAD",
help="Name of the dataset (ASCAD, CHES20, AES_RD, DPAv42)")
flags.DEFINE_string("checkpoint_dir", default=None,
help="directory for saving checkpoint.")
flags.DEFINE_integer("checkpoint_idx", default=0,
help="checkpoints index to restore.")
flags.DEFINE_bool("warm_start", default=False,
help="Whether to warm start training from checkpoint.")
flags.DEFINE_string("result_path", default="",
help="Path for eval results")
flags.DEFINE_bool("do_train", default=False,
help="Whether to perform training or evaluation")
# Optimization config
flags.DEFINE_float("learning_rate", default=2.5e-4,
help="Maximum learning rate.")
flags.DEFINE_float("clip", default=0.25,
help="Gradient clipping value.")
# for cosine decay
flags.DEFINE_float("min_lr_ratio", default=0.004,
help="Minimum ratio learning rate.")
flags.DEFINE_integer("warmup_steps", default=0,
help="Number of steps for linear lr warmup.")
flags.DEFINE_integer("input_length", default=700,
help="The input length for TN model")
flags.DEFINE_integer("data_desync", default=0,
help="Max trace desync for data augmentation")
# Training config
flags.DEFINE_integer("train_batch_size", default=256,
help="Size of train batch.")
flags.DEFINE_integer("eval_batch_size", default=32,
help="Size of valid batch.")
flags.DEFINE_integer("train_steps", default=100000,
help="Total number of training steps.")
flags.DEFINE_integer("iterations", default=500,
help="Number of iterations per repeat loop.")
flags.DEFINE_integer("save_steps", default=10000,
help="number of steps for model checkpointing.")
# Model config
flags.DEFINE_integer("n_layer", default=6,
help="Number of layers.")
flags.DEFINE_integer("d_model", default=128,
help="Dimension of the model (d).")
flags.DEFINE_integer("d_head", default=32,
help="Dimension of each head (d_v).")
flags.DEFINE_integer("n_head", default=4,
help="Number of attention heads (H).")
flags.DEFINE_integer("d_inner", default=256,
help="Dimension of inner hidden size in positionwise feed-forward.")
flags.DEFINE_integer("n_head_softmax", default=4,
help="Number of attention heads in softmax attention")
flags.DEFINE_integer("d_head_softmax", default=32,
help="Dimension of each head in softmax attention")
flags.DEFINE_integer("d_kernel_map", default=128,
help="Dimension of the kernel feature map (d_e).")
flags.DEFINE_integer("beta_hat_2", default=100,
help="Distance based scaling in the kernel of self-attention")
flags.DEFINE_float("dropout", default=0.1,
help="Dropout rate.")
flags.DEFINE_integer("conv_kernel_size", default=3,
help="Kernel size of all but the first convolution layers")
flags.DEFINE_integer("n_conv_layer", default=1,
help="Number of convolutional blocks")
flags.DEFINE_integer("pool_size", default=2,
help="Pooling size of the average pooling layers")
flags.DEFINE_string("model_normalization", default='preLC',
help="Normalization type used to normalize layer, can be in ['preLC', 'postLC', 'none']")
flags.DEFINE_string("head_initialization", default='forward',
help="Type of the initialization of the positional attention heads, can be in ['forward', 'backward', 'symmetric']")
flags.DEFINE_bool("softmax_attn", default='True',
help="Whether to use softmax attention instead of global pooling")
# Evaluation config
flags.DEFINE_integer("max_eval_batch", default=-1,
help="Set -1 to turn off.")
flags.DEFINE_bool("output_attn", default=False,
help="output attention probabilities")
FLAGS = flags.FLAGS
class LRSchedule(tf.keras.optimizers.schedules.LearningRateSchedule):
def __init__(self, max_lr, tr_steps, wu_steps=0, min_lr_ratio=0.0):
self.max_lr=max_lr
self.tr_steps=tr_steps
self.wu_steps=wu_steps
self.min_lr_ratio=min_lr_ratio
def __call__(self, step):
step_float = tf.cast(step, tf.float32)
wu_steps_float = tf.cast(self.wu_steps, tf.float32)
tr_steps_float = tf.cast(self.tr_steps, tf.float32)
max_lr_float =tf.cast(self.max_lr, tf.float32)
min_lr_ratio_float = tf.cast(self.min_lr_ratio, tf.float32)
# warmup learning rate using linear schedule
wu_lr = (step_float/wu_steps_float) * max_lr_float
# decay the learning rate using the cosine schedule
global_step = tf.math.minimum(step_float-wu_steps_float, tr_steps_float-wu_steps_float)
decay_steps = tr_steps_float-wu_steps_float
pi = tf.constant(math.pi)
cosine_decay = .5 * (1. + tf.math.cos(pi * global_step / decay_steps))
decayed = (1.-min_lr_ratio_float) * cosine_decay + min_lr_ratio_float
decay_lr = max_lr_float * decayed
return tf.cond(step < self.wu_steps, lambda: wu_lr, lambda: decay_lr)
def create_model(n_classes):
model = Transformer(
n_layer = FLAGS.n_layer,
d_model = FLAGS.d_model,
d_head = FLAGS.d_head,
n_head = FLAGS.n_head,
d_inner = FLAGS.d_inner,
n_head_softmax = FLAGS.n_head_softmax,
d_head_softmax = FLAGS.d_head_softmax,
dropout = FLAGS.dropout,
n_classes = n_classes,
conv_kernel_size = FLAGS.conv_kernel_size,
n_conv_layer = FLAGS.n_conv_layer,
pool_size = FLAGS.pool_size,
d_kernel_map = FLAGS.d_kernel_map,
beta_hat_2 = FLAGS.beta_hat_2,
model_normalization = FLAGS.model_normalization,
head_initialization = FLAGS.head_initialization,
softmax_attn = FLAGS.softmax_attn,
output_attn = FLAGS.output_attn
)
return model
def train(train_dataset, eval_dataset, num_train_batch, num_eval_batch, strategy, chk_name):
# Ensure that the batch sizes are divisible by number of replicas in sync
assert(FLAGS.train_batch_size % strategy.num_replicas_in_sync == 0)
assert(FLAGS.eval_batch_size % strategy.num_replicas_in_sync == 0)
##### Create computational graph for train dataset
train_dist_dataset = strategy.experimental_distribute_dataset(train_dataset)
##### Create computational graph for eval dataset
eval_dist_dataset = strategy.experimental_distribute_dataset(eval_dataset)
if FLAGS.save_steps <= 0:
FLAGS.save_steps = None
else:
# Set the FLAGS.save_steps to a value multiple of FLAGS.iterations
if FLAGS.save_steps < FLAGS.iterations:
FLAGS.save_steps = FLAGS.iterations
else:
FLAGS.save_steps = (FLAGS.save_steps // FLAGS.iterations) * \
FLAGS.iterations
##### Instantiate learning rate scheduler object
lr_sch = LRSchedule(
FLAGS.learning_rate, FLAGS.train_steps, \
FLAGS.warmup_steps, FLAGS.min_lr_ratio
)
loss_dic_file = os.path.join(FLAGS.checkpoint_dir, 'loss.pkl')
##### Create computational graph for model
with strategy.scope():
if FLAGS.dataset == 'CHES20':
model = create_model(4)
else:
model = create_model(256)
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_sch)
checkpoint = tf.train.Checkpoint(optimizer=optimizer, model=model)
train_loss = tf.keras.metrics.Mean('train_loss', dtype=tf.float32)
eval_loss = tf.keras.metrics.Mean('eval_loss', dtype=tf.float32)
grad_norm = tf.keras.metrics.Mean('grad_norms', dtype=tf.float32)
new_start = True
if FLAGS.warm_start:
options = tf.train.CheckpointOptions(experimental_io_device="/job:localhost")
chk_path = tf.train.latest_checkpoint(FLAGS.checkpoint_dir)
if chk_path is None:
tf.compat.v1.logging.info("Could not find any checkpoint, starting training from beginning")
else:
tf.compat.v1.logging.info("Found checkpoint: {}".format(chk_path))
try:
checkpoint.restore(chk_path, options=options)
tf.compat.v1.logging.info("Restored checkpoint: {}".format(chk_path))
new_start = False
except:
tf.compat.v1.logging.info("Could not restore checkpoint, starting training from beginning")
if new_start == True:
# Save the initial model
chk_path = os.path.join(FLAGS.checkpoint_dir, chk_name)
options = tf.train.CheckpointOptions(experimental_io_device="/job:localhost")
save_path = checkpoint.save(chk_path, options=options)
tf.compat.v1.logging.info("Model saved in path: {}".format(save_path))
loss_dic = {}
pickle.dump(loss_dic, open(loss_dic_file, 'wb'))
else:
loss_dic = pickle.load(open(loss_dic_file, 'rb'))
@tf.function
def train_steps(iterator, steps, bsz, global_step):
###### Reset the states of the update variables
train_loss.reset_states()
grad_norm.reset_states()
###### The step function for one training step
def step_fn(inps, lbls, global_step):
lbls = tf.squeeze(lbls)
with tf.GradientTape() as tape:
softmax_attn_smoothing = 1. #tf.minimum(float(global_step)/FLAGS.train_steps, 1.)
logits = model(inps, softmax_attn_smoothing, training=True)[0]
if FLAGS.dataset == 'CHES20':
per_example_loss = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(lbls, logits),
axis = 1
)
else:
per_example_loss = tf.nn.sparse_softmax_cross_entropy_with_logits(lbls, logits)
avg_loss = tf.nn.compute_average_loss(per_example_loss, \
global_batch_size=bsz)
variables = tape.watched_variables()
gradients = tape.gradient(avg_loss, variables)
clipped, gnorm = tf.clip_by_global_norm(gradients, FLAGS.clip)
optimizer.apply_gradients(list(zip(clipped, variables)))
train_loss.update_state(avg_loss * strategy.num_replicas_in_sync)
grad_norm.update_state(gnorm)
for _ in range(steps):
global_step += 1
inps, lbls = next(iterator)
strategy.run(step_fn, args=(inps, lbls, global_step))
@tf.function
def eval_steps(iterator, steps, bsz):
###### The step function for one evaluation step
def step_fn(inps, lbls):
lbls = tf.squeeze(lbls)
logits = model(inps)[0]
if FLAGS.dataset == 'CHES20':
per_example_loss = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(lbls, logits),
axis = 1
)
else:
per_example_loss = tf.nn.sparse_softmax_cross_entropy_with_logits(lbls, logits)
avg_loss = tf.nn.compute_average_loss(per_example_loss, \
global_batch_size=bsz)
eval_loss.update_state(avg_loss * strategy.num_replicas_in_sync)
for _ in range(steps):
inps, lbls = next(iterator)
strategy.run(step_fn, args=(inps, lbls,))
tf.compat.v1.logging.info('Starting training ... ')
train_iter = iter(train_dist_dataset)
cur_step = optimizer.iterations.numpy()
while cur_step < FLAGS.train_steps:
train_steps(train_iter, tf.convert_to_tensor(FLAGS.iterations), \
FLAGS.train_batch_size, cur_step)
cur_step = optimizer.iterations.numpy()
cur_loss = train_loss.result()
gnorm = grad_norm.result()
lr_rate = lr_sch(cur_step)
dic = {}
tf.compat.v1.logging.info("[{:6d}] | gnorm {:5.2f} lr {:9.6f} "
"| loss {:>5.2f}".format(cur_step, gnorm, lr_rate, cur_loss))
dic['gnorm'] = gnorm.numpy()
dic['running_train_loss'] = cur_loss.numpy()
if FLAGS.max_eval_batch <= 0:
num_eval_iters = num_eval_batch
else:
num_eval_iters = min(FLAGS.max_eval_batch, num_eval_batch)
eval_tr_iter = iter(train_dist_dataset)
eval_loss.reset_states()
eval_steps(eval_tr_iter, tf.convert_to_tensor(num_eval_iters), \
FLAGS.train_batch_size)
cur_eval_loss = eval_loss.result()
tf.compat.v1.logging.info("Train batches[{:5d}] |"
" loss {:>5.2f}".format(num_eval_iters, cur_eval_loss))
dic['train_loss'] = cur_eval_loss.numpy()
eval_va_iter = iter(eval_dist_dataset)
eval_loss.reset_states()
eval_steps(eval_va_iter, tf.convert_to_tensor(num_eval_iters), \
FLAGS.eval_batch_size)
cur_eval_loss = eval_loss.result()
tf.compat.v1.logging.info("Eval batches[{:5d}] |"
" loss {:>5.2f}".format(num_eval_iters, cur_eval_loss))
dic['test_loss'] = cur_eval_loss.numpy()
loss_dic[cur_step] = dic
if FLAGS.save_steps is not None and (cur_step) % FLAGS.save_steps == 0:
chk_path = os.path.join(FLAGS.checkpoint_dir, chk_name)
options = tf.train.CheckpointOptions(experimental_io_device="/job:localhost")
save_path = checkpoint.save(chk_path, options=options)
tf.compat.v1.logging.info("Model saved in path: {}".format(save_path))
pickle.dump(loss_dic, open(loss_dic_file, 'wb'))
if FLAGS.save_steps is not None and (cur_step) % FLAGS.save_steps != 0:
chk_path = os.path.join(FLAGS.checkpoint_dir, chk_name)
options = tf.train.CheckpointOptions(experimental_io_device="/job:localhost")
save_path = checkpoint.save(chk_path, options=options)
tf.compat.v1.logging.info("Model saved in path: {}".format(save_path))
pickle.dump(loss_dic, open(loss_dic_file, 'wb'))
def evaluate(data, strategy, chk_name):
# Ensure that the batch size is divisible by number of replicas in sync
assert(FLAGS.eval_batch_size % strategy.num_replicas_in_sync == 0)
##### Create computational graph for model
with strategy.scope():
if FLAGS.dataset == 'CHES20':
model = create_model(4)
else:
model = create_model(256)
optimizer = tf.keras.optimizers.Adam(learning_rate=FLAGS.learning_rate)
checkpoint = tf.train.Checkpoint(optimizer=optimizer, model=model)
options = tf.train.CheckpointOptions(experimental_io_device="/job:localhost")
if FLAGS.checkpoint_idx <= 0:
chk_path = tf.train.latest_checkpoint(FLAGS.checkpoint_dir)
if chk_path is None:
tf.compat.v1.logging.info("Could not find any checkpoint")
return None
else:
chk_path = os.path.join(FLAGS.checkpoint_dir, '%s-%s'%(chk_name, FLAGS.checkpoint_idx))
tf.compat.v1.logging.info("Restoring checkpoint: {}".format(chk_path))
try:
checkpoint.read(chk_path, options=options).expect_partial()
tf.compat.v1.logging.info("Restored checkpoint: {}".format(chk_path))
except:
tf.compat.v1.logging.info("Could not restore checkpoint")
return None
if FLAGS.output_attn:
output = model.predict(data, steps=FLAGS.max_eval_batch)
else:
output = model.predict(data)
return output
def print_hyperparams():
tf.compat.v1.logging.info("")
tf.compat.v1.logging.info("")
tf.compat.v1.logging.info("use_tpu : %s" % (FLAGS.use_tpu))
tf.compat.v1.logging.info("data_path : %s" % (FLAGS.data_path))
tf.compat.v1.logging.info("dataset : %s" % (FLAGS.dataset))
tf.compat.v1.logging.info("checkpoint_dir : %s" % (FLAGS.checkpoint_dir))
tf.compat.v1.logging.info("checkpoint_idx : %s" % (FLAGS.checkpoint_idx))
tf.compat.v1.logging.info("warm_start : %s" % (FLAGS.warm_start))
tf.compat.v1.logging.info("result_path : %s" % (FLAGS.result_path))
tf.compat.v1.logging.info("do_train : %s" % (FLAGS.do_train))
tf.compat.v1.logging.info("learning_rate : %s" % (FLAGS.learning_rate))
tf.compat.v1.logging.info("clip : %s" % (FLAGS.clip))
tf.compat.v1.logging.info("min_lr_ratio : %s" % (FLAGS.min_lr_ratio))
tf.compat.v1.logging.info("warmup_steps : %s" % (FLAGS.warmup_steps))
tf.compat.v1.logging.info("input_length : %s" % (FLAGS.input_length))
tf.compat.v1.logging.info("data_desync : %s" % (FLAGS.data_desync))
tf.compat.v1.logging.info("train_batch_size : %s" % (FLAGS.train_batch_size))
tf.compat.v1.logging.info("eval_batch_size : %s" % (FLAGS.eval_batch_size))
tf.compat.v1.logging.info("train_steps : %s" % (FLAGS.train_steps))
tf.compat.v1.logging.info("iterations : %s" % (FLAGS.iterations))
tf.compat.v1.logging.info("save_steps : %s" % (FLAGS.save_steps))
tf.compat.v1.logging.info("n_layer : %s" % (FLAGS.n_layer))
tf.compat.v1.logging.info("d_model : %s" % (FLAGS.d_model))
tf.compat.v1.logging.info("d_head : %s" % (FLAGS.d_head))
tf.compat.v1.logging.info("n_head : %s" % (FLAGS.n_head))
tf.compat.v1.logging.info("d_inner : %s" % (FLAGS.d_inner))
tf.compat.v1.logging.info("n_head_softmax : %s" % (FLAGS.n_head_softmax))
tf.compat.v1.logging.info("d_head_softmax : %s" % (FLAGS.d_head_softmax))
tf.compat.v1.logging.info("dropout : %s" % (FLAGS.dropout))
tf.compat.v1.logging.info("conv_kernel_size : %s" % (FLAGS.conv_kernel_size))
tf.compat.v1.logging.info("n_conv_layer : %s" % (FLAGS.n_conv_layer))
tf.compat.v1.logging.info("pool_size : %s" % (FLAGS.pool_size))
tf.compat.v1.logging.info("d_kernel_map : %s" % (FLAGS.d_kernel_map))
tf.compat.v1.logging.info("beta_hat_2 : %s" % (FLAGS.beta_hat_2))
tf.compat.v1.logging.info("model_normalization : %s" % (FLAGS.model_normalization))
tf.compat.v1.logging.info("head_initialization : %s" % (FLAGS.head_initialization))
tf.compat.v1.logging.info("softmax_attn : %s" % (FLAGS.softmax_attn))
tf.compat.v1.logging.info("max_eval_batch : %s" % (FLAGS.max_eval_batch))
tf.compat.v1.logging.info("output_attn : %s" % (FLAGS.output_attn))
tf.compat.v1.logging.info("")
tf.compat.v1.logging.info("")
def main(unused_argv):
del unused_argv # Unused
print_hyperparams()
tf.compat.v1.logging.set_verbosity(tf.compat.v1.logging.INFO)
if FLAGS.dataset == 'ASCAD':
train_data = data_utils.Dataset(data_path=FLAGS.data_path, split="train",
input_length=FLAGS.input_length, data_desync=FLAGS.data_desync)
test_data = data_utils.Dataset(data_path=FLAGS.data_path, split="test",
input_length=FLAGS.input_length, data_desync=FLAGS.data_desync)
elif FLAGS.dataset == 'CHES20':
if FLAGS.do_train:
data_path = FLAGS.data_path + '.npz'
train_data = data_utils_ches20.Dataset(data_path=data_path, split="train",
input_length=FLAGS.input_length, data_desync=FLAGS.data_desync)
data_path = FLAGS.data_path + '_valid.npz'
test_data = data_utils_ches20.Dataset(data_path=data_path, split="test",
input_length=FLAGS.input_length, data_desync=FLAGS.data_desync)
else:
data_path = FLAGS.data_path + '.npz'
test_data = data_utils_ches20.Dataset(data_path=data_path, split="test",
input_length=FLAGS.input_length, data_desync=FLAGS.data_desync)
else:
assert False
if FLAGS.use_tpu:
resolver = tf.distribute.cluster_resolver.TPUClusterResolver(tpu='grpc://' + os.environ['COLAB_TPU_ADDR'])
tf.config.experimental_connect_to_cluster(resolver)
tf.tpu.experimental.initialize_tpu_system(resolver)
strategy = tf.distribute.experimental.TPUStrategy(resolver)
else:
strategy = tf.distribute.get_strategy()
tf.compat.v1.logging.info("Number of accelerators: %s" % strategy.num_replicas_in_sync)
if FLAGS.dataset == 'ASCAD':
chk_name = 'trans_long'
elif FLAGS.dataset == 'CHES20':
chk_name = 'trans_long'
else:
assert False
if FLAGS.do_train:
num_train_batch = train_data.num_samples // FLAGS.train_batch_size
num_test_batch = test_data.num_samples // FLAGS.eval_batch_size
tf.compat.v1.logging.info("num of train batches {}".format(num_train_batch))
tf.compat.v1.logging.info("num of test batches {}".format(num_test_batch))
train(train_data.GetTFRecords(FLAGS.train_batch_size, training=True), \
test_data.GetTFRecords(FLAGS.eval_batch_size, training=True), \
num_train_batch, num_test_batch, strategy, chk_name)
else:
num_test_batch = test_data.num_samples // FLAGS.eval_batch_size
tf.compat.v1.logging.info("num of test batches {}".format(num_test_batch))
output = evaluate(test_data.GetTFRecords(FLAGS.eval_batch_size, training=False),
strategy, chk_name)
test_scores = output[0]
attn_outputs = output[1:]
if test_scores is None:
return
if FLAGS.output_attn and not FLAGS.do_train:
nsamples = FLAGS.max_eval_batch*FLAGS.eval_batch_size
else:
nsamples = test_data.num_samples
if FLAGS.dataset == 'ASCAD':
plaintexts = test_data.plaintexts[:nsamples]
keys = test_data.keys[:nsamples]
elif FLAGS.dataset == 'CHES20':
nonces = test_data.nonces[:nsamples]
keys = test_data.umsk_keys
key_rank_list = []
for i in range(100):
if FLAGS.dataset == 'ASCAD':
key_ranks = evaluation_utils.compute_key_rank(test_scores, plaintexts, keys)
elif FLAGS.dataset == 'CHES20':
key_ranks = evaluation_utils_ches20.compute_key_rank(test_scores, nonces, keys)
key_rank_list.append(key_ranks)
key_ranks = np.stack(key_rank_list, axis=0)
with open(FLAGS.result_path+'.txt', 'w') as fout:
for i in range(key_ranks.shape[0]):
for r in key_ranks[i]:
fout.write(str(r)+'\t')
fout.write('\n')
mean_ranks = np.mean(key_ranks, axis=0)
for r in mean_ranks:
fout.write(str(r)+'\t')
fout.write('\n')
tf.compat.v1.logging.info("written results in {}".format(FLAGS.result_path))
if FLAGS.output_attn:
pickle.dump(attn_outputs, open(FLAGS.result_path+'.pkl', 'wb'))
if __name__ == "__main__":
tf.compat.v1.app.run()
我们第一次运行
我们发现,问题很长:
D:\anaconda3\envs\torch\python.exe C:\Users\早早早\Desktop\reproducing_experiments\TCHES2024\EstraNet-main\EstraNet-main\train_trans.py
INFO:tensorflow:
I0324 10:35:49.431368 26372 train_trans.py:382]
INFO:tensorflow:
I0324 10:35:49.431368 26372 train_trans.py:383]
INFO:tensorflow:use_tpu : False
I0324 10:35:49.431368 26372 train_trans.py:384] use_tpu : False
INFO:tensorflow:data_path :
I0324 10:35:49.431368 26372 train_trans.py:385] data_path :
INFO:tensorflow:dataset : ASCAD
I0324 10:35:49.431368 26372 train_trans.py:386] dataset : ASCAD
INFO:tensorflow:checkpoint_dir : None
I0324 10:35:49.431368 26372 train_trans.py:387] checkpoint_dir : None
INFO:tensorflow:checkpoint_idx : 0
I0324 10:35:49.431368 26372 train_trans.py:388] checkpoint_idx : 0
INFO:tensorflow:warm_start : False
I0324 10:35:49.431368 26372 train_trans.py:389] warm_start : False
INFO:tensorflow:result_path :
I0324 10:35:49.431368 26372 train_trans.py:390] result_path :
INFO:tensorflow:do_train : False
I0324 10:35:49.431368 26372 train_trans.py:391] do_train : False
INFO:tensorflow:learning_rate : 0.00025
I0324 10:35:49.431368 26372 train_trans.py:392] learning_rate : 0.00025
INFO:tensorflow:clip : 0.25
I0324 10:35:49.431368 26372 train_trans.py:393] clip : 0.25
INFO:tensorflow:min_lr_ratio : 0.004
I0324 10:35:49.431368 26372 train_trans.py:394] min_lr_ratio : 0.004
INFO:tensorflow:warmup_steps : 0
I0324 10:35:49.431368 26372 train_trans.py:395] warmup_steps : 0
INFO:tensorflow:input_length : 700
I0324 10:35:49.431368 26372 train_trans.py:396] input_length : 700
INFO:tensorflow:data_desync : 0
I0324 10:35:49.431368 26372 train_trans.py:397] data_desync : 0
INFO:tensorflow:train_batch_size : 256
I0324 10:35:49.431368 26372 train_trans.py:398] train_batch_size : 256
INFO:tensorflow:eval_batch_size : 32
I0324 10:35:49.431368 26372 train_trans.py:399] eval_batch_size : 32
INFO:tensorflow:train_steps : 100000
I0324 10:35:49.431368 26372 train_trans.py:400] train_steps : 100000
INFO:tensorflow:iterations : 500
I0324 10:35:49.431368 26372 train_trans.py:401] iterations : 500
INFO:tensorflow:save_steps : 10000
I0324 10:35:49.431368 26372 train_trans.py:402] save_steps : 10000
INFO:tensorflow:n_layer : 6
I0324 10:35:49.431368 26372 train_trans.py:403] n_layer : 6
INFO:tensorflow:d_model : 128
I0324 10:35:49.431368 26372 train_trans.py:404] d_model : 128
INFO:tensorflow:d_head : 32
I0324 10:35:49.431368 26372 train_trans.py:405] d_head : 32
INFO:tensorflow:n_head : 4
I0324 10:35:49.431368 26372 train_trans.py:406] n_head : 4
INFO:tensorflow:d_inner : 256
I0324 10:35:49.431368 26372 train_trans.py:407] d_inner : 256
INFO:tensorflow:n_head_softmax : 4
I0324 10:35:49.431368 26372 train_trans.py:408] n_head_softmax : 4
INFO:tensorflow:d_head_softmax : 32
I0324 10:35:49.431368 26372 train_trans.py:409] d_head_softmax : 32
INFO:tensorflow:dropout : 0.1
I0324 10:35:49.431368 26372 train_trans.py:410] dropout : 0.1
INFO:tensorflow:conv_kernel_size : 3
I0324 10:35:49.431368 26372 train_trans.py:411] conv_kernel_size : 3
INFO:tensorflow:n_conv_layer : 1
I0324 10:35:49.431368 26372 train_trans.py:412] n_conv_layer : 1
INFO:tensorflow:pool_size : 2
I0324 10:35:49.431368 26372 train_trans.py:413] pool_size : 2
INFO:tensorflow:d_kernel_map : 128
I0324 10:35:49.431368 26372 train_trans.py:414] d_kernel_map : 128
INFO:tensorflow:beta_hat_2 : 100
I0324 10:35:49.432368 26372 train_trans.py:415] beta_hat_2 : 100
INFO:tensorflow:model_normalization : preLC
I0324 10:35:49.432368 26372 train_trans.py:416] model_normalization : preLC
INFO:tensorflow:head_initialization : forward
I0324 10:35:49.436376 26372 train_trans.py:417] head_initialization : forward
INFO:tensorflow:softmax_attn : True
I0324 10:35:49.437368 26372 train_trans.py:418] softmax_attn : True
INFO:tensorflow:max_eval_batch : -1
I0324 10:35:49.437368 26372 train_trans.py:419] max_eval_batch : -1
INFO:tensorflow:output_attn : False
I0324 10:35:49.437368 26372 train_trans.py:420] output_attn : False
INFO:tensorflow:
I0324 10:35:49.437368 26372 train_trans.py:421]
INFO:tensorflow:
I0324 10:35:49.437368 26372 train_trans.py:422]
INFO:tensorflow:Number of accelerators: 1
I0324 10:35:56.138029 26372 train_trans.py:462] Number of accelerators: 1
INFO:tensorflow:num of test batches 312
I0324 10:35:56.138029 26372 train_trans.py:484] num of test batches 312
2025-03-24 10:35:56.144793: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: SSE SSE2 SSE3 SSE4.1 SSE4.2 AVX AVX2 AVX_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
C:\Users\早早早\AppData\Roaming\Python\Python39\site-packages\keras\src\initializers\initializers.py:120: UserWarning: The initializer RandomUniform is unseeded and being called multiple times, which will return identical values each time (even if the initializer is unseeded). Please update your code to provide a seed to the initializer, or avoid using the same initializer instance more than once.
warnings.warn(
Traceback (most recent call last):
File "C:\Users\早早早\Desktop\reproducing_experiments\TCHES2024\EstraNet-main\EstraNet-main\train_trans.py", line 530, in <module>
tf.compat.v1.app.run()
File "C:\Users\早早早\AppData\Roaming\Python\Python39\site-packages\tensorflow\python\platform\app.py", line 36, in run
_run(main=main, argv=argv, flags_parser=_parse_flags_tolerate_undef)
File "C:\Users\早早早\AppData\Roaming\Python\Python39\site-packages\absl\app.py", line 316, in run
_run_main(main, args)
File "C:\Users\早早早\AppData\Roaming\Python\Python39\site-packages\absl\app.py", line 261, in _run_main
sys.exit(main(argv))
File "C:\Users\早早早\Desktop\reproducing_experiments\TCHES2024\EstraNet-main\EstraNet-main\train_trans.py", line 486, in main
output = evaluate(test_data.GetTFRecords(FLAGS.eval_batch_size, training=False),
File "C:\Users\早早早\Desktop\reproducing_experiments\TCHES2024\EstraNet-main\EstraNet-main\train_trans.py", line 360, in evaluate
chk_path = tf.train.latest_checkpoint(FLAGS.checkpoint_dir)
File "C:\Users\早早早\AppData\Roaming\Python\Python39\site-packages\tensorflow\python\checkpoint\checkpoint_management.py", line 350, in latest_checkpoint
ckpt = get_checkpoint_state(checkpoint_dir, latest_filename)
File "C:\Users\早早早\AppData\Roaming\Python\Python39\site-packages\tensorflow\python\checkpoint\checkpoint_management.py", line 270, in get_checkpoint_state
coord_checkpoint_filename = _GetCheckpointFilename(checkpoint_dir,
File "C:\Users\早早早\AppData\Roaming\Python\Python39\site-packages\tensorflow\python\checkpoint\checkpoint_management.py", line 59, in _GetCheckpointFilename
return os.path.join(save_dir, latest_filename)
File "D:\anaconda3\envs\torch\lib\ntpath.py", line 78, in join
path = os.fspath(path)
TypeError: expected str, bytes or os.PathLike object, not NoneType进程已结束,退出代码为 1
可以发现,运行了一次之后打印出来了一堆看不懂的东西。
以上内容都是红字,但其实真的存在问题的,是这一部分
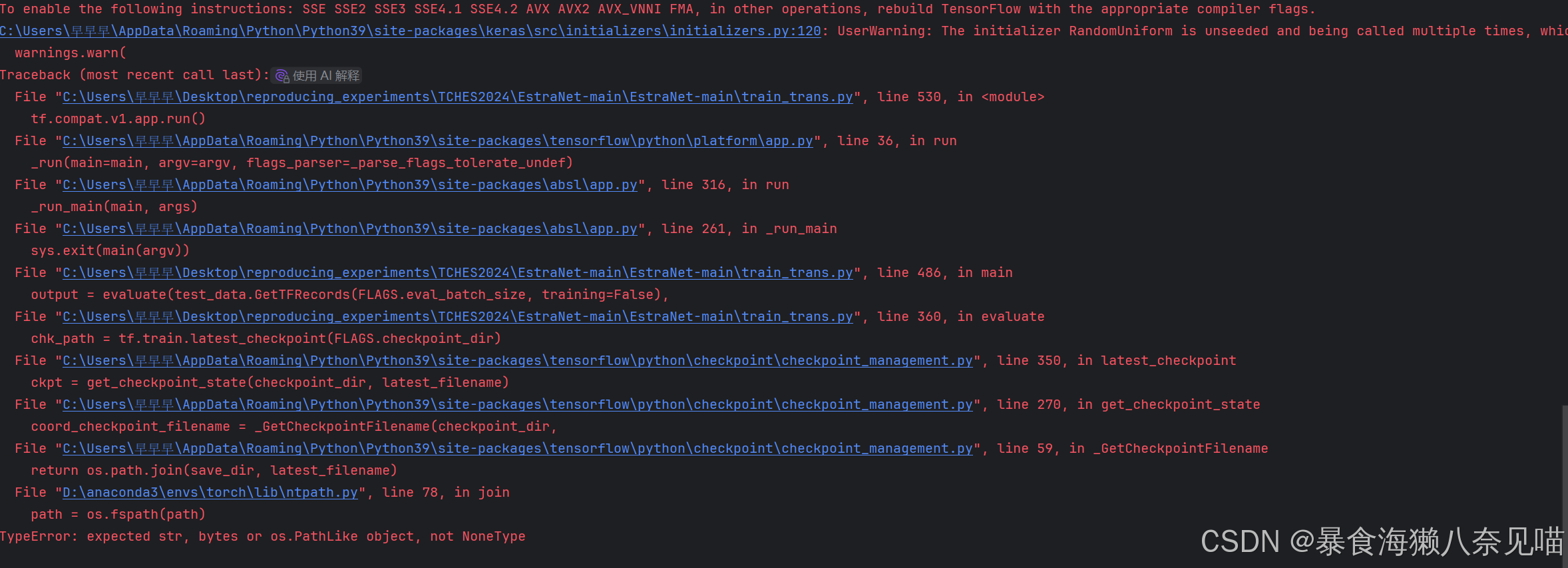
C:\Users\早早早\AppData\Roaming\Python\Python39\site-packages\keras\src\initializers\initializers.py:120: UserWarning: The initializer RandomUniform is unseeded and being called multiple times, which will return identical values each time (even if the initializer is unseeded). Please update your code to provide a seed to the initializer, or avoid using the same initializer instance more than once.
warnings.warn(
Traceback (most recent call last):
File "C:\Users\早早早\Desktop\reproducing_experiments\TCHES2024\EstraNet-main\EstraNet-main\train_trans.py", line 530, in <module>
tf.compat.v1.app.run()
File "C:\Users\早早早\AppData\Roaming\Python\Python39\site-packages\tensorflow\python\platform\app.py", line 36, in run
_run(main=main, argv=argv, flags_parser=_parse_flags_tolerate_undef)
File "C:\Users\早早早\AppData\Roaming\Python\Python39\site-packages\absl\app.py", line 316, in run
_run_main(main, args)
File "C:\Users\早早早\AppData\Roaming\Python\Python39\site-packages\absl\app.py", line 261, in _run_main
sys.exit(main(argv))
File "C:\Users\早早早\Desktop\reproducing_experiments\TCHES2024\EstraNet-main\EstraNet-main\train_trans.py", line 486, in main
output = evaluate(test_data.GetTFRecords(FLAGS.eval_batch_size, training=False),
File "C:\Users\早早早\Desktop\reproducing_experiments\TCHES2024\EstraNet-main\EstraNet-main\train_trans.py", line 360, in evaluate
chk_path = tf.train.latest_checkpoint(FLAGS.checkpoint_dir)
File "C:\Users\早早早\AppData\Roaming\Python\Python39\site-packages\tensorflow\python\checkpoint\checkpoint_management.py", line 350, in latest_checkpoint
ckpt = get_checkpoint_state(checkpoint_dir, latest_filename)
File "C:\Users\早早早\AppData\Roaming\Python\Python39\site-packages\tensorflow\python\checkpoint\checkpoint_management.py", line 270, in get_checkpoint_state
coord_checkpoint_filename = _GetCheckpointFilename(checkpoint_dir,
File "C:\Users\早早早\AppData\Roaming\Python\Python39\site-packages\tensorflow\python\checkpoint\checkpoint_management.py", line 59, in _GetCheckpointFilename
return os.path.join(save_dir, latest_filename)
File "D:\anaconda3\envs\torch\lib\ntpath.py", line 78, in join
path = os.fspath(path)
TypeError: expected str, bytes or os.PathLike object, not NoneType进程已结束,退出代码为 1
这部分问题之前的打印出来的红字
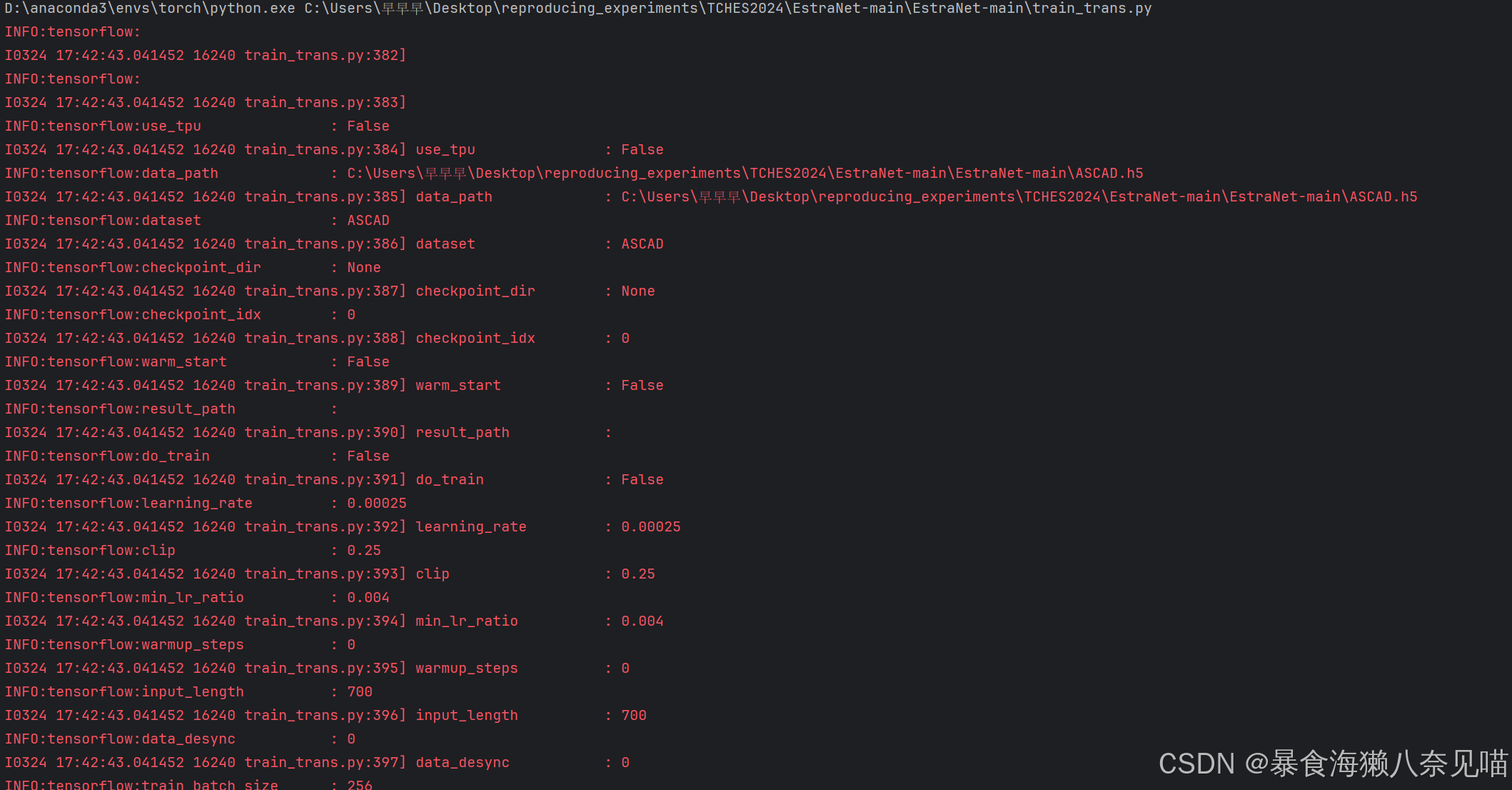
是在回应这些代码:
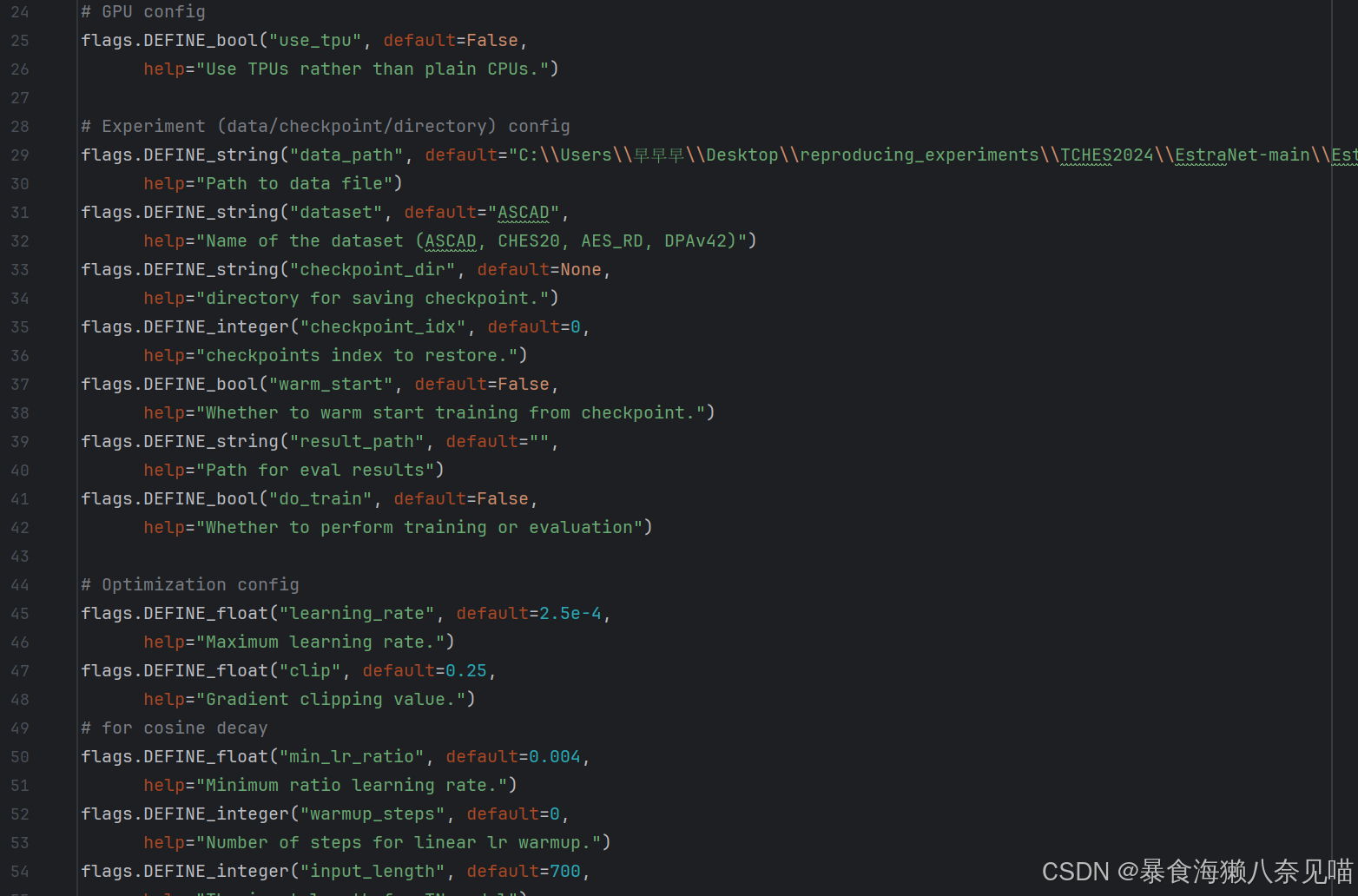
所以不用管。
那么真正存在的这些问题怎么处理呢?
吧错误喂给deepseek,我们得知
于是就加上check_point和result两个文件夹,作为路径
接下来我们第二次运行
代码出现了这样的报错:
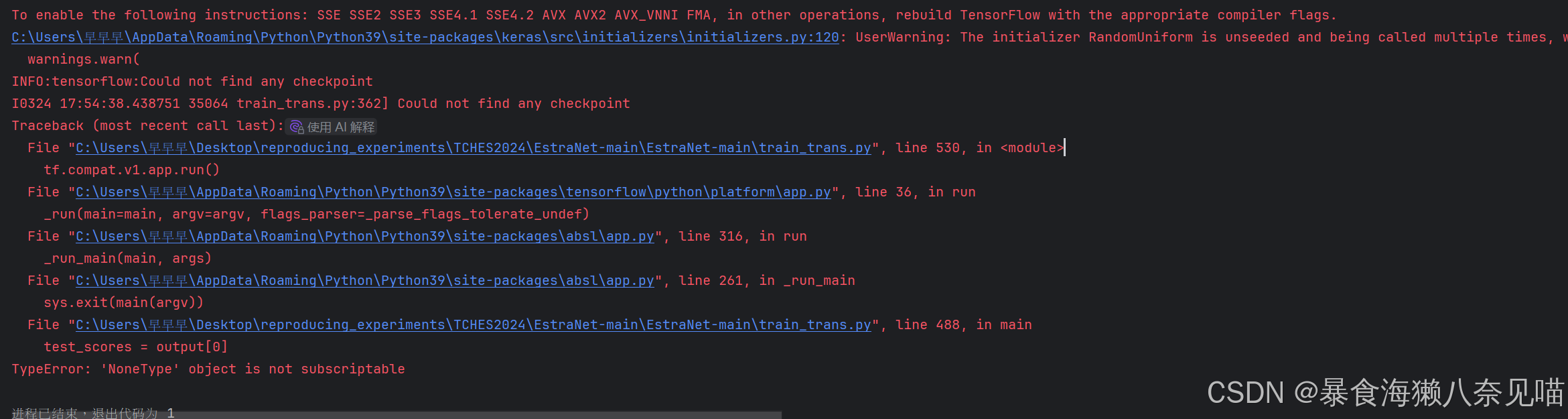
To enable the following instructions: SSE SSE2 SSE3 SSE4.1 SSE4.2 AVX AVX2 AVX_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
C:\Users\早早早\AppData\Roaming\Python\Python39\site-packages\keras\src\initializers\initializers.py:120: UserWarning: The initializer RandomUniform is unseeded and being called multiple times, which will return identical values each time (even if the initializer is unseeded). Please update your code to provide a seed to the initializer, or avoid using the same initializer instance more than once.
warnings.warn(
INFO:tensorflow:Could not find any checkpoint
I0324 17:54:38.438751 35064 train_trans.py:362] Could not find any checkpoint
Traceback (most recent call last):
File "C:\Users\早早早\Desktop\reproducing_experiments\TCHES2024\EstraNet-main\EstraNet-main\train_trans.py", line 530, in <module>
tf.compat.v1.app.run()
File "C:\Users\早早早\AppData\Roaming\Python\Python39\site-packages\tensorflow\python\platform\app.py", line 36, in run
_run(main=main, argv=argv, flags_parser=_parse_flags_tolerate_undef)
File "C:\Users\早早早\AppData\Roaming\Python\Python39\site-packages\absl\app.py", line 316, in run
_run_main(main, args)
File "C:\Users\早早早\AppData\Roaming\Python\Python39\site-packages\absl\app.py", line 261, in _run_main
sys.exit(main(argv))
File "C:\Users\早早早\Desktop\reproducing_experiments\TCHES2024\EstraNet-main\EstraNet-main\train_trans.py", line 488, in main
test_scores = output[0]
TypeError: 'NoneType' object is not subscriptable
deepseek说问题的根源在:
错误:'NoneType' object is not subscriptable
原因分析:
evaluate()函数返回了None- 检查点未正确加载导致模型未初始化
- 评估代码未处理空返回值
File "C:\Users\早早早\Desktop\reproducing_experiments\TCHES2024\EstraNet-main\EstraNet-main\train_trans.py", line 488, in main
test_scores = output[0]
TypeError: 'NoneType' object is not subscriptable
这个错误对应到代码中是这个:
output = evaluate(test_data.GetTFRecords(FLAGS.eval_batch_size, training=False),
strategy, chk_name)
test_scores = output[0]也就是说,我们的evaluate()函数返回的数据不对
继续回溯,我们发现evaluate()函数是作者自己定义的:
def evaluate(data, strategy, chk_name):
# Ensure that the batch size is divisible by number of replicas in sync
assert(FLAGS.eval_batch_size % strategy.num_replicas_in_sync == 0)
##### Create computational graph for model
with strategy.scope():
if FLAGS.dataset == 'CHES20':
model = create_model(4)
else:
model = create_model(256)
optimizer = tf.keras.optimizers.Adam(learning_rate=FLAGS.learning_rate)
checkpoint = tf.train.Checkpoint(optimizer=optimizer, model=model)
options = tf.train.CheckpointOptions(experimental_io_device="/job:localhost")
if FLAGS.checkpoint_idx <= 0:
chk_path = tf.train.latest_checkpoint(FLAGS.checkpoint_dir)
if chk_path is None:
tf.compat.v1.logging.info("Could not find any checkpoint")
return None
else:
chk_path = os.path.join(FLAGS.checkpoint_dir, '%s-%s'%(chk_name, FLAGS.checkpoint_idx))
tf.compat.v1.logging.info("Restoring checkpoint: {}".format(chk_path))
try:
checkpoint.read(chk_path, options=options).expect_partial()
tf.compat.v1.logging.info("Restored checkpoint: {}".format(chk_path))
except:
tf.compat.v1.logging.info("Could not restore checkpoint")
return None
if FLAGS.output_attn:
output = model.predict(data, steps=FLAGS.max_eval_batch)
else:
output = model.predict(data)
return output然后我先得说,deepseek直接帮我改了代码,但是问题没有变化,它改的代码也没有体现出什么不同来,我于是决定自查一下:
既然是output有问题我们就看看这个output。我在evaluate中加了这么一段内容,发现输入的data和strategy没见过这样的形式,那么这是正确的吗?
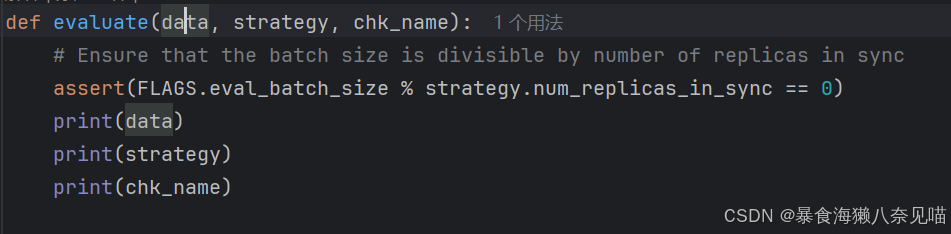

然后是在main函数中的一点变化我们加了一个对test_data的print:
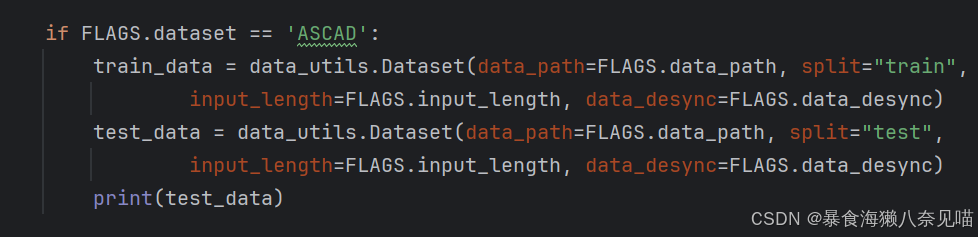

我们发现,这个形式依旧不像我们传统印象当中的test_data,要么这是一个压缩文件的文件名,但是这不太可能,所以这应该是一个错误,或者这就是一种数据集。所以我觉得我应该去看看我们的这个数据是怎么处理的。这涉及到我们的数据集处理函数data_utils.Dataset()。
我们直接来看我们的数据集处理的python文件

import numpy as np
import tensorflow as tf
import h5py
import os, sys
class Dataset:
def __init__(self, data_path, split, input_length, data_desync=0):
self.data_path = data_path
self.split = split
self.input_length = input_length
self.data_desync = data_desync
#data_path
corpus = h5py.File("C:\\Users\\早早早\\Desktop\\reproducing_experiments\\TCHES2024\\EstraNet-main\\EstraNet-main\\ASCAD.h5", 'r')#C:\Users\早早早\Desktop\reproducing_experiments\TCHES2024\EstraNet-main\EstraNet-main\ASCAD.h5
if split == 'train':
split_key = 'Profiling_traces'
elif split == 'test':
split_key = 'Attack_traces'
self.traces = corpus[split_key]['traces'][:, :(self.input_length+self.data_desync)]
self.labels = np.reshape(corpus[split_key]['labels'][()], [-1, 1])
self.labels = self.labels.astype(np.int64)
self.num_samples = self.traces.shape[0]
#assert (self.input_length + self.data_desync) <= self.traces.shape[1]
#self.traces = self.traces[:, :(self.input_length+self.data_desync)]
max_split_size = 2000000000//self.input_length
split_idx = list(range(max_split_size, self.num_samples, max_split_size))
self.traces = np.split(self.traces, split_idx, axis=0)
self.labels = np.split(self.labels, split_idx, axis=0)
#self.traces = self.traces.astype(np.float32)
self.plaintexts = self.GetPlaintexts(corpus[split_key]['metadata'])
self.masks = self.GetMasks(corpus[split_key]['metadata'])
self.keys = self.GetKeys(corpus[split_key]['metadata'])
def GetPlaintexts(self, metadata):
plaintexts = []
for i in range(len(metadata)):
plaintexts.append(metadata[i]['plaintext'][2])
return np.array(plaintexts)
def GetKeys(self, metadata):
keys = []
for i in range(len(metadata)):
keys.append(metadata[i]['key'][2])
return np.array(keys)
def GetMasks(self, metadata):
masks = []
for i in range(len(metadata)):
masks.append(np.array(metadata[i]['masks']))
masks = np.stack(masks, axis=0)
return masks
def GetTFRecords(self, batch_size, training=False):
dataset = tf.data.Dataset.from_tensor_slices((self.traces[0], self.labels[0]))
for traces, labels in zip(self.traces[1:], self.labels[1:]):
temp_dataset = tf.data.Dataset.from_tensor_slices((traces, labels))
dataset.concatenate(temp_dataset)
def shift(x, max_desync):
ds = tf.random.uniform([1], 0, max_desync+1, tf.dtypes.int32)
ds = tf.concat([[0], ds], 0)
x = tf.slice(x, ds, [-1, self.input_length])
return x
if training == True:
if self.input_length < self.traces[0].shape[1]:
return dataset.repeat() \
.shuffle(self.num_samples) \
.batch(batch_size//2) \
.map(lambda x, y: (shift(x, self.data_desync), y)) \
.unbatch() \
.batch(batch_size, drop_remainder=True) \
.map(lambda x, y: (tf.cast(x, tf.float32), y)) \
.prefetch(10)
else:
return dataset.repeat() \
.shuffle(self.num_samples) \
.batch(batch_size, drop_remainder=True) \
.map(lambda x, y: (tf.cast(x, tf.float32), y)) \
.prefetch(10)
else:
if self.input_length < self.traces[0].shape[1]:
return dataset.batch(batch_size, drop_remainder=True) \
.map(lambda x, y: (shift(x, 0), y)) \
.map(lambda x, y: (tf.cast(x, tf.float32), y)) \
.prefetch(10)
else:
return dataset.batch(batch_size, drop_remainder=True) \
.map(lambda x, y: (tf.cast(x, tf.float32), y)) \
.prefetch(10)
def GetDataset(self):
return self.traces, self.labels
if __name__ == '__main__':
if len(sys.argv) < 4:
print("Error: Missing command-line arguments.")
print("Usage: python data_utils.py <data_path> <batch_size> <split>")
sys.exit(1)
data_path = sys.argv[1]
batch_size = int(sys.argv[2])
split = sys.argv[3]
dataset = Dataset(data_path, split, 5)
print("traces : "+str(dataset.traces.shape))
print("labels : "+str(dataset.labels.shape))
print("plaintext : "+str(dataset.plaintexts.shape))
print("keys : "+str(dataset.keys.shape))
print("traces ty : "+str(dataset.traces.dtype))
print("")
print("")
tfrecords = dataset.GetTFRecords(batch_size, training=True)
iterator = iter(tfrecords)
for i in range(1):
tr, lbl = iterator.get_next()
print(str(tr.shape)+' '+str(lbl.shape))
print(str(tr.dtype)+' '+str(lbl.dtype))
print(str(tr[:, :10]))
print(str(lbl[:, :]))
print("")
我们发现,作者设置了这个代码可以跑着测试的

我们发现,事实上,我们根本没有能够处理数据集。所以我们其实是要先修改数据集的处理部分。
为什么我们的输出是报错的。原因在于这个:if len(sys.argv) < 4
我们sys.argv的长度太短了,已经小于4了。
它长什么样子,它本应该是什么样子的?
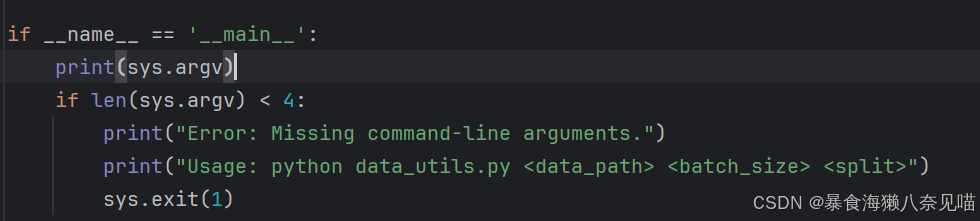
我打印了一下这个东西

结果它只是一个地址?
于是我询问Deep seek这是什么东西,但是它的回答很差,它反复向我强调这一句内容需要运行以下内容才有用:
这样就可以得到
但是我们所有的代码里是没有这个东西的,所以想要把dataset跑出来,得直接给出我们的数据内容。
if __name__ == '__main__':
"""
print(sys.argv)
if len(sys.argv) < 4:
print("Error: Missing command-line arguments.")
print("Usage: python data_utils.py <data_path> <batch_size> <split>")
sys.exit(1)
data_path = sys.argv[1]
batch_size = int(sys.argv[2])
split = sys.argv[3]
"""
data_path = "C:\\Users\\早早早\\Desktop\\reproducing_experiments\\TCHES2024\\EstraNet-main\\EstraNet-main\\ASCAD.h5"
batch_size = 256
split = 'train'
dataset = Dataset(data_path, split, 5)
print("traces : "+str(dataset.traces[0].shape))
#print("traces : " + str(dataset.traces.shape))
print("labels : "+str(dataset.labels[0].shape))
print("plaintext : "+str(dataset.plaintexts.shape))
print("keys : "+str(dataset.keys.shape))
print("traces ty : "+str(dataset.traces))
print("")
print("")
tfrecords = dataset.GetTFRecords(batch_size, training=True)
iterator = iter(tfrecords)
for i in range(1):
tr, lbl = iterator.get_next()
print(str(tr.shape)+' '+str(lbl.shape))
print(str(tr.dtype)+' '+str(lbl.dtype))
print(str(tr[:, :10]))
print(str(lbl[:, :]))
print("")于是我做出了这样的调整,终于看到了使用Dataset类处理的ASCAD数据集的结果了。
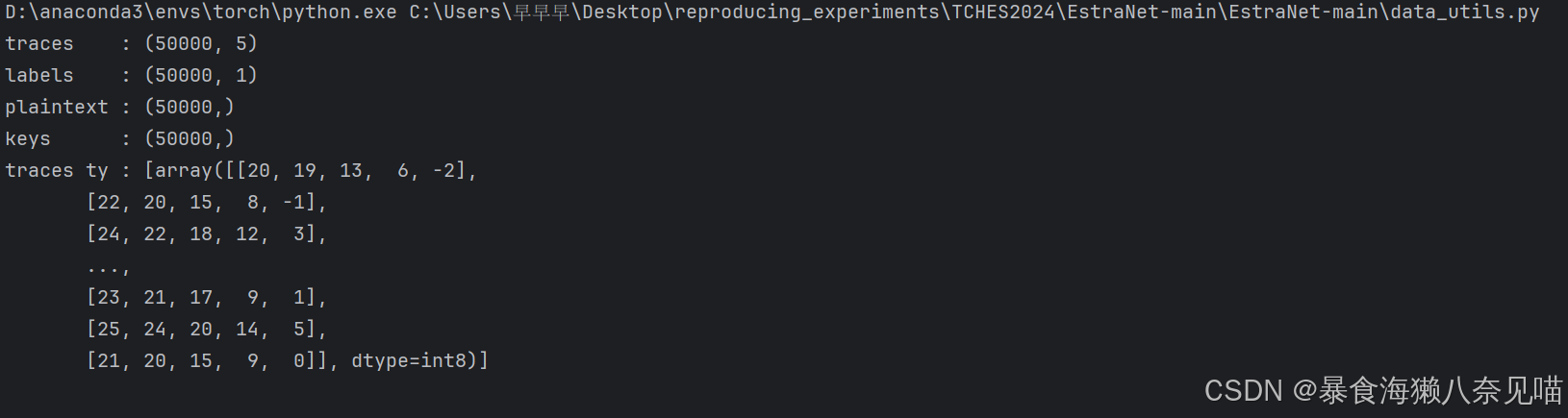
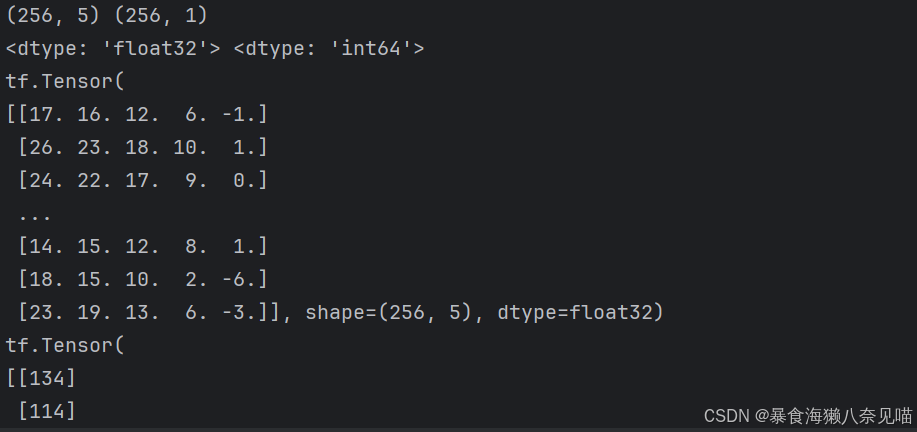
但是这并没有解决前面的问题。问题依然是
output没东西!!!!!
为了找到问题出在哪里,我在output旁边加上了这些代码:
几个print,查看一下数据有没有问题,我发现,test_data的形式和原始数据集一样,是从原始数据集里划分出来的,没有什么问题。
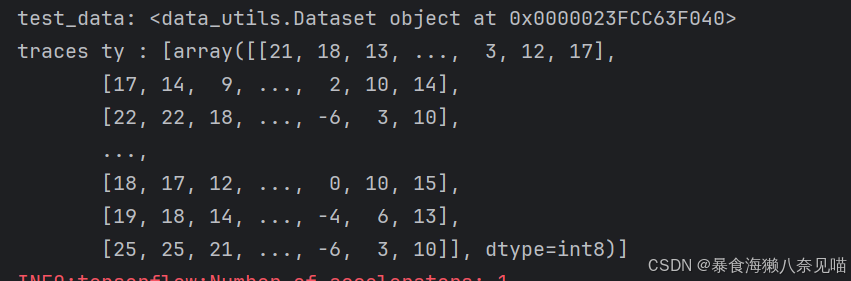
所以到这里,我觉得我们可以把错误范围缩小到evaluate()里面
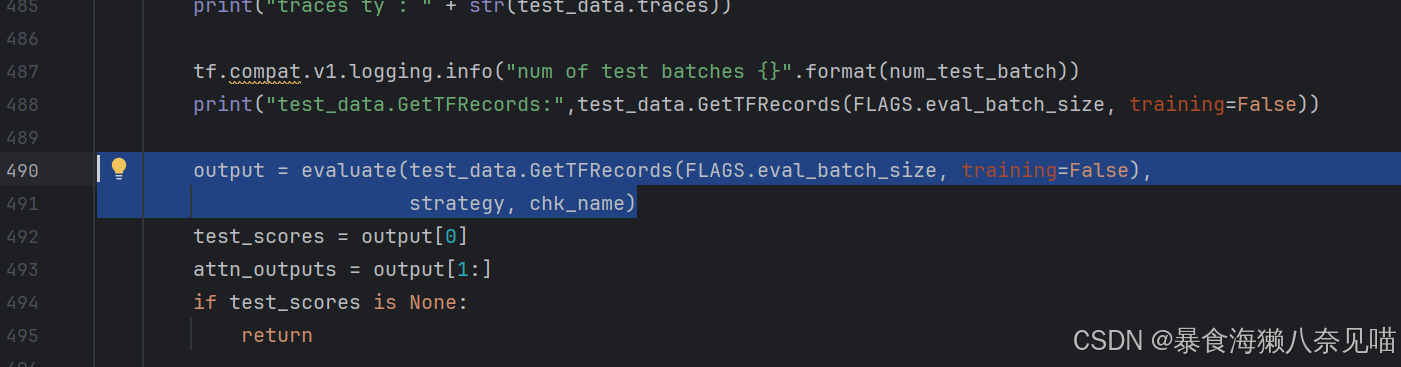
先来看看这个吧
test_data.GetTFRecords(FLAGS.eval_batch_size, training=False)
回到data_utils.py中我们可以看到
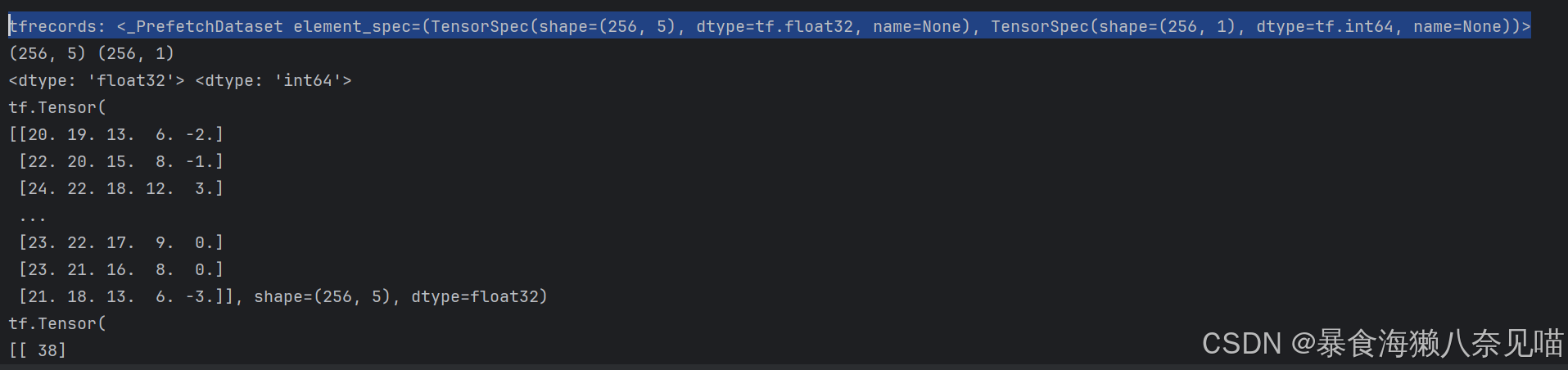

我们发现,除了shape不一样,其他的结构是没什么问题的。所以问题应该出在evaluate()中:
先让我们看看deepseek怎么说吧:
函数定义
def evaluate(data, strategy, chk_name):- 作用:模型评估函数
- 参数:
data:输入数据(通常是tf.data.Dataset)strategy:TensorFlow 分布式策略(如MirroredStrategy或TPUStrategy)chk_name:检查点名称前缀(如trans_long)
1. 批次大小验证
assert FLAGS.eval_batch_size % strategy.num_replicas_in_sync == 0- 作用:确保评估批次大小能被分布式副本数整除,避免数据分配不均。
- 示例:
- 若
strategy.num_replicas_in_sync=8(如使用 8 个 GPU),则eval_batch_size必须是 8 的倍数。
- 若
2. 分布式策略上下文
with strategy.scope():- 作用:在分布式策略范围内创建模型和变量,确保变量同步。
- 典型场景:多 GPU 训练或 TPU 环境。
3. 模型创建
if FLAGS.dataset == 'CHES20':
model = create_model(4) # 4 类输出
else:
model = create_model(256) # 256 类输出- 说明:根据数据集类型初始化模型,输出维度不同。
- 假设:
create_model()返回一个tf.keras.Model实例。
4. 优化器与检查点
optimizer = tf.keras.optimizers.Adam(learning_rate=FLAGS.learning_rate)
checkpoint = tf.train.Checkpoint(optimizer=optimizer, model=model)- 作用:
optimizer:定义优化器(尽管评估阶段可能不需要优化器,但需与训练检查点兼容)。checkpoint:包含模型和优化器的状态,用于恢复参数。
5. 检查点路径处理
options = tf.train.CheckpointOptions(experimental_io_device="/job:localhost")- 作用:指定检查点加载的 I/O 设备(
/job:localhost表示从本地加载)。
路径生成逻辑
if FLAGS.checkpoint_idx <= 0:
chk_path = tf.train.latest_checkpoint(FLAGS.checkpoint_dir)
if chk_path is None:
tf.compat.v1.logging.info("Could not find any checkpoint")
return None
else:
chk_path = os.path.join(FLAGS.checkpoint_dir, '%s-%s'%(chk_name, FLAGS.checkpoint_idx))- 逻辑分支:
- 自动查找最新检查点(
checkpoint_idx <= 0):通过tf.train.latest_checkpoint()找到checkpoint_dir中最新的检查点。 - 指定检查点索引(
checkpoint_idx > 0):生成路径如checkpoint_dir/trans_long-100。
- 自动查找最新检查点(
- 潜在问题:未校验手动拼接的检查点路径是否存在。
6. 加载检查点
try:
checkpoint.read(chk_path, options=options).expect_partial()
tf.compat.v1.logging.info("Restored checkpoint: {}".format(chk_path))
except:
tf.compat.v1.logging.info("Could not restore checkpoint")
return None- 关键方法:
.read():从chk_path加载检查点。.expect_partial():允许部分变量恢复(某些变量可能未被保存)。
- 异常处理:捕获所有异常,但未区分错误类型(如文件不存在、变量不匹配等)。
7. 模型预测
if FLAGS.output_attn:
output = model.predict(data, steps=FLAGS.max_eval_batch)
else:
output = model.predict(data)
return output- 作用:运行模型预测。
- 参数差异:
steps=FLAGS.max_eval_batch:限制预测的批次数量(仅在output_attn=True时生效)。- 默认情况下使用完整数据集。
- 潜在问题:若检查点加载失败(返回
None),调用该函数后访问output[0]会触发TypeError。
在evaluate中我先加入了一点print
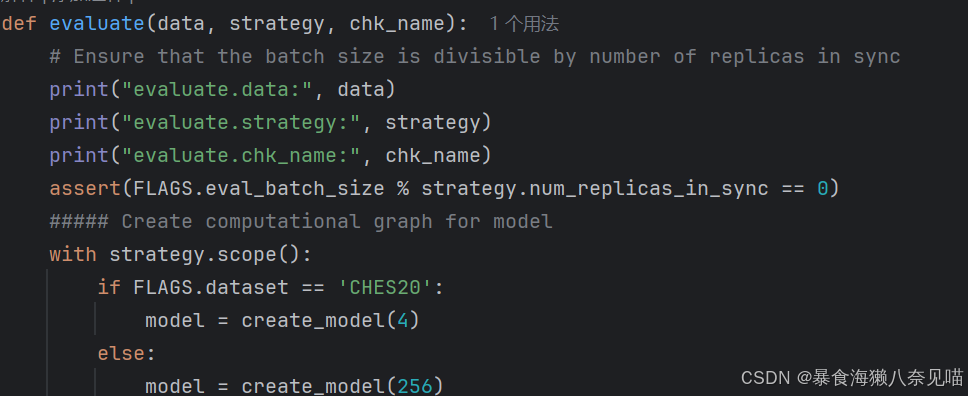

我发现这些内容没有什么问题,strategy和chk_name都是源代码里有的,data和外部的是一样的。
但是我注意到一个东西:
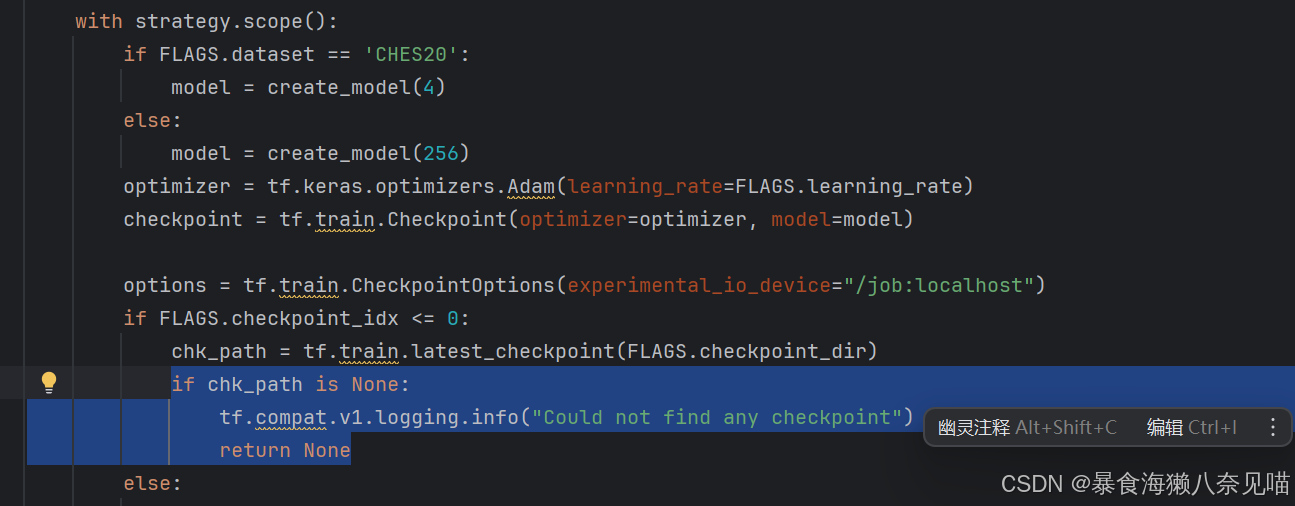
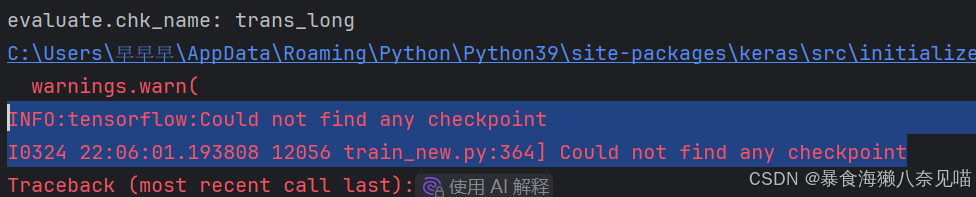
其实代码里是告诉了问题所在的,我们没有chk_path!!!天哪!难道是踏破铁鞋无觅处,得来全不费工夫?之所以前面返回了一个None,原来是这个问题!
我们继续排查:
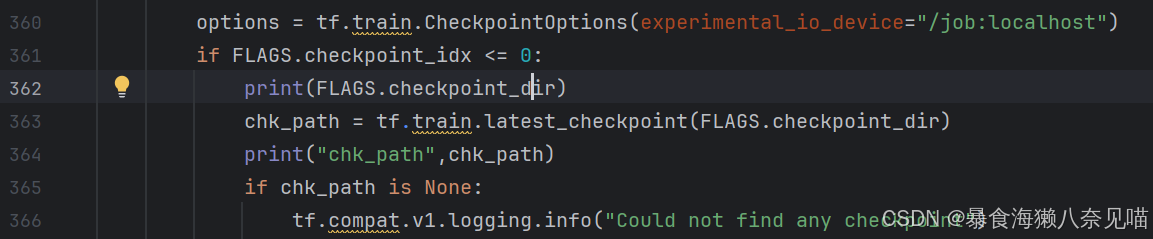

核心问题应该在这里
chk_path = tf.train.latest_checkpoint(FLAGS.checkpoint_dir)
代码块详解:chk_path = tf.train.latest_checkpoint(FLAGS.checkpoint_dir)
1. 代码块分解
| 代码部分 | 数据类型/对象 | 作用 |
|---|---|---|
tf.train.latest_checkpoint |
函数 | 自动查找并返回指定目录中最新的检查点路径。 |
FLAGS.checkpoint_dir |
字符串(命令行参数) | 用户定义的参数,指定检查点文件存储的目录路径。 |
chk_path |
字符串或 None |
返回的检查点路径(如 ./checkpoints/model-1000),若未找到则为 None。 |
2. 核心功能说明
-
作用:
在训练或评估过程中,自动定位最新保存的模型检查点,用于:- 恢复训练(断点续训)
- 加载模型进行推理/评估
- 迁移学习
-
实现原理:
解析checkpoint_dir目录下的checkpoint文件(文本文件),其内容类似:model_checkpoint_path: "model-1000" all_model_checkpoint_paths: "model-900" all_model_checkpoint_paths: "model-1000"函数会读取
model_checkpoint_path对应的最新检查点名称。
3. 完整使用流程
步骤1:定义检查点目录
在命令行参数中指定 checkpoint_dir:
from absl import flags
flags.DEFINE_string(
"checkpoint_dir", "./checkpoints",
"Directory where checkpoints are saved."
)
FLAGS = flags.FLAGS步骤2:保存检查点
在训练代码中定期保存检查点:
import tensorflow as tf
# 创建检查点对象
checkpoint = tf.train.Checkpoint(model=model, optimizer=optimizer)
manager = tf.train.CheckpointManager(
checkpoint,
directory=FLAGS.checkpoint_dir,
max_to_keep=3 # 保留最近3个检查点
)
# 训练循环中保存
for epoch in range(epochs):
# ...训练步骤...
if epoch % 100 == 0:
manager.save(checkpoint_number=epoch) # 保存为 model-0, model-100, 等步骤3:加载最新检查点
在评估或恢复训练时调用:
# 获取最新检查点路径
chk_path = tf.train.latest_checkpoint(FLAGS.checkpoint_dir)
# 校验路径有效性
if chk_path is None:
raise FileNotFoundError(f"No checkpoint found in {FLAGS.checkpoint_dir}")
# 恢复模型状态
checkpoint.restore(chk_path)
print(f"成功加载检查点:{chk_path}")4. 关键参数与返回值
| 参数/返回值 | 说明 |
|---|---|
**checkpoint_dir** |
必须存在的目录路径,否则返回 None。建议通过 os.makedirs 提前创建目录。 |
返回值 chk_path |
完整检查点路径(如 ./checkpoints/model-1000),可直接用于 checkpoint.restore()。 |
5. 错误处理与调试
场景1:目录不存在
# 错误示例
FLAGS.checkpoint_dir = "./nonexistent_dir"
chk_path = tf.train.latest_checkpoint(FLAGS.checkpoint_dir) # 返回 None
# 解决方案
import os
os.makedirs(FLAGS.checkpoint_dir, exist_ok=True)场景2:目录无检查点
# 错误现象
print(chk_path) # 输出 None
# 调试方法
files = os.listdir(FLAGS.checkpoint_dir)
print("目录内容:", files) # 应包含 checkpoint, model-1000.index 等文件根据这些信息,我认为,我们可以这样下结论:我们的路径里没有任何检查点!!!!!!
为什么!Look in my eyes! why! Baby , tell me why!
我明天好好排查一下,我觉得有希望了。
根据deepseek我们看到:
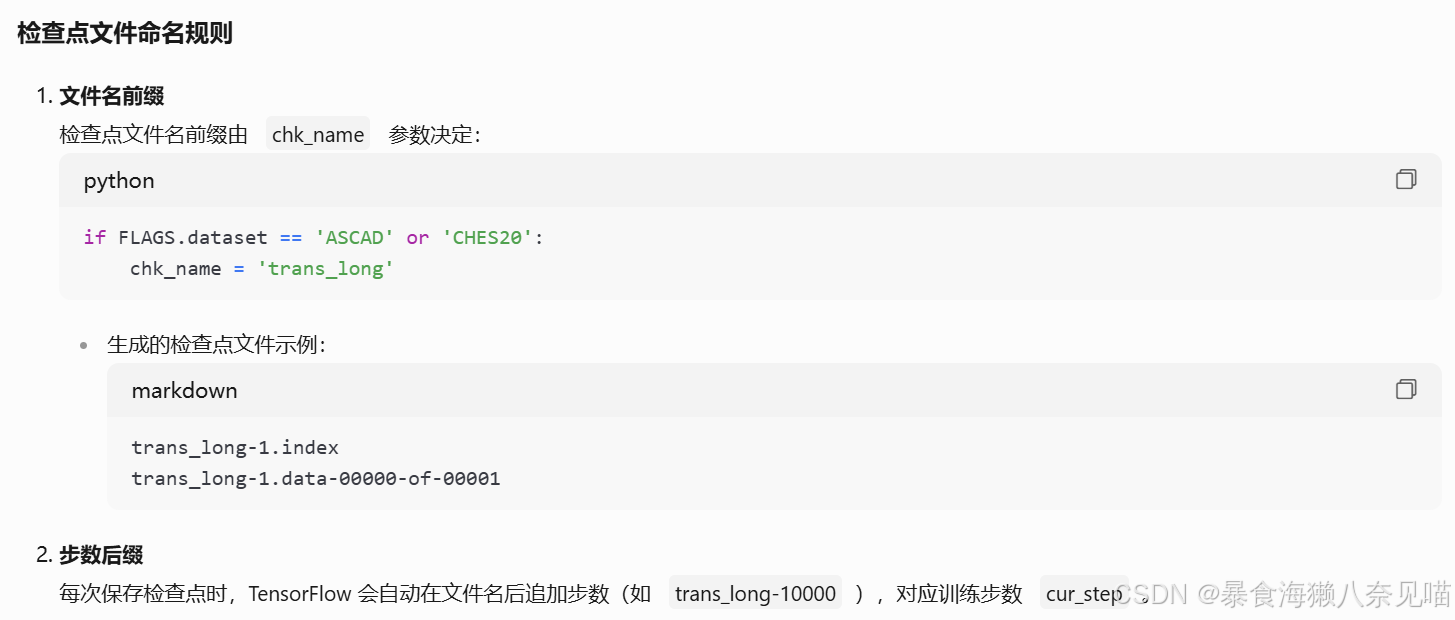
关键代码逻辑
**(1) 检查点保存逻辑**
在 train() 函数中,检查点保存通过以下代码实现:
# 初始保存
chk_path = os.path.join(FLAGS.checkpoint_dir, chk_name)
save_path = checkpoint.save(chk_path, options=options)
# 周期性保存(每 FLAGS.save_steps 步)
if cur_step % FLAGS.save_steps == 0:
checkpoint.save(os.path.join(FLAGS.checkpoint_dir, chk_name))- 生成文件:
trans_long-1.indextrans_long-1.data-00000-of-00001checkpoint(记录最新检查点路径的元文件)
**(2) 检查点加载逻辑**
在 evaluate() 函数中,检查点路径生成逻辑:
if FLAGS.checkpoint_idx <= 0:
# 自动查找最新检查点
chk_path = tf.train.latest_checkpoint(FLAGS.checkpoint_dir)
else:
# 手动指定索引(如 trans_long-10000)
chk_path = os.path.join(FLAGS.checkpoint_dir,
f"{chk_name}-{FLAGS.checkpoint_idx}")上面的(2) 检查点加载逻辑其实就是我们报错的点,没有检查点。所以问题一定出在(1) 检查点保存逻辑上
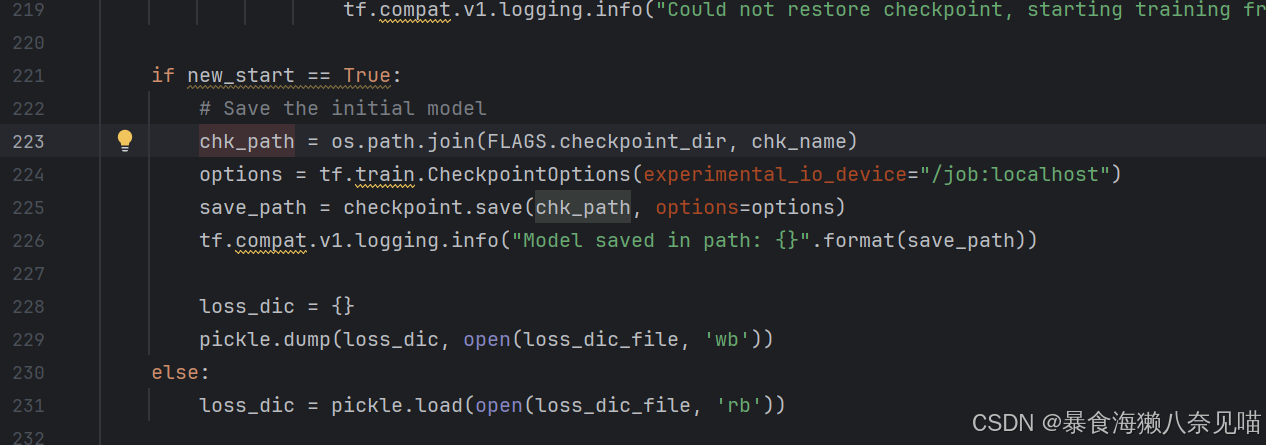
会是这里吗?
显然不是,因为这行代码没有打印出来,所以之前根本没有进入这里!!!!!也就是说,我们根本没有生成任何的文件!!!!
这说明我们代码前面的这个判断没有生效
if new_start == True:
为什么?
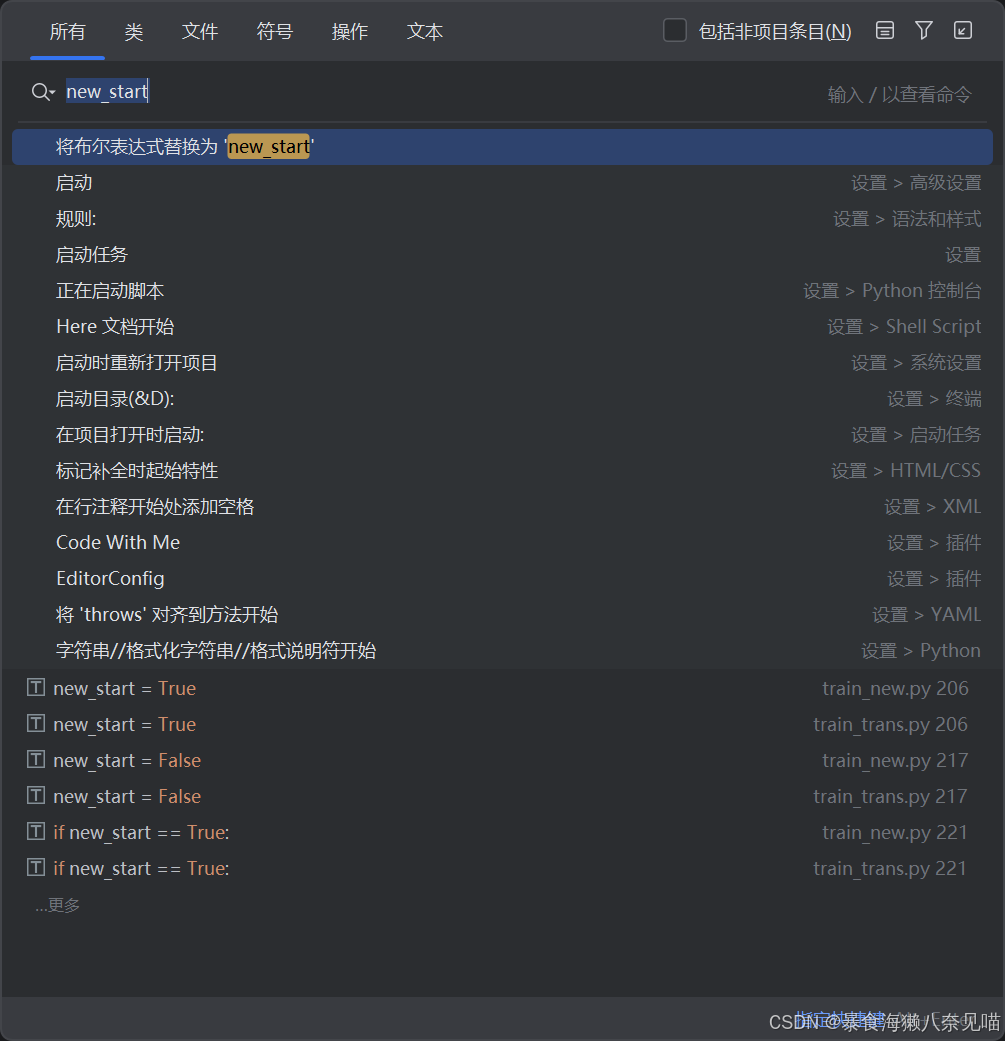
我们发现这个关键变量的正误判断存在一定的问题:会不会这里的new_start没有值?
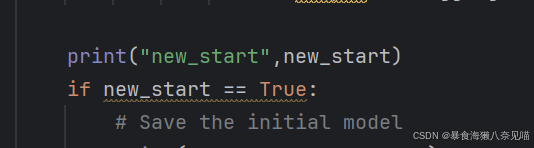
打印出来什么捏?什么也没有!!!
于是我有了一个更加大胆的想法:它会不会根本没有进train里训练!

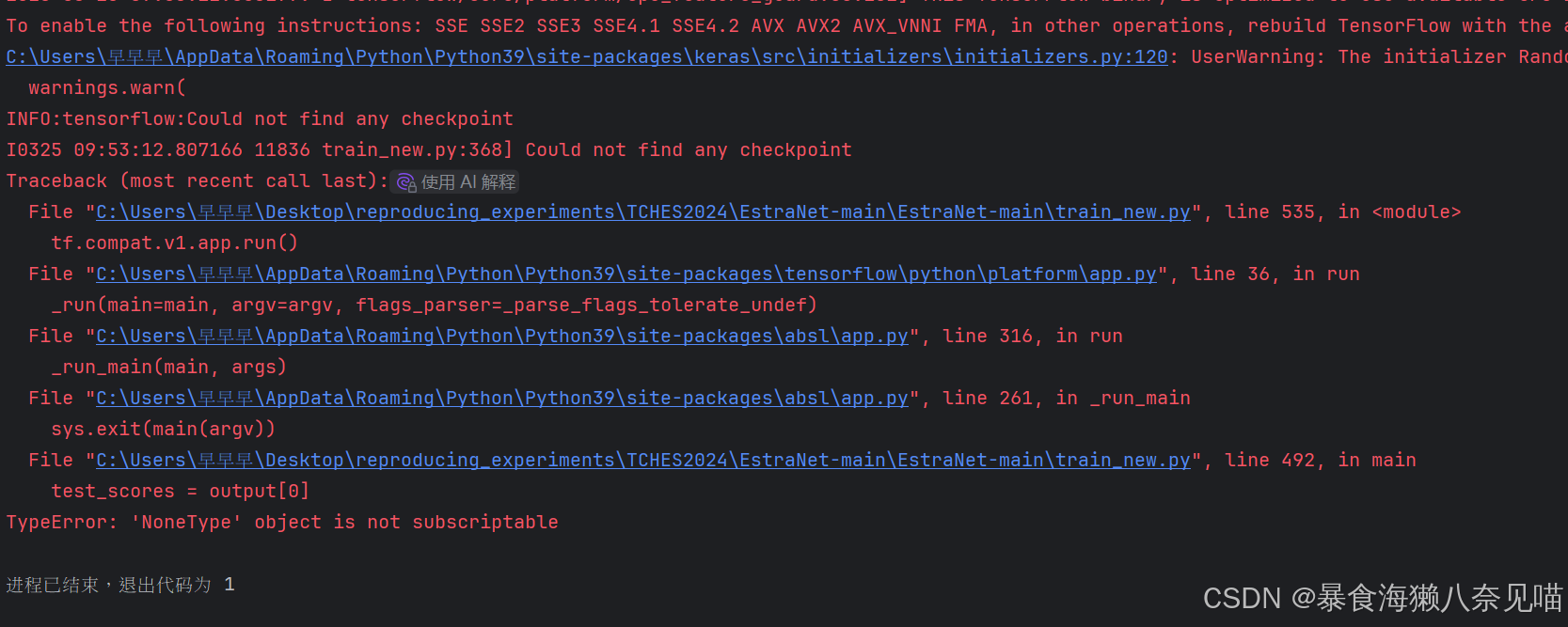
真的没有啊!!!!
这不对的,肯定有问题。或许是作者认为我们作为研究人员都看得懂代码,所以这里没有把train加进去其实是为了方便我们?
那么现在我们要解决如何正确运行代码各个部分的问题了
首先
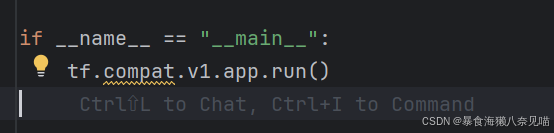
这里的tf.compat.v1.app.run()只是一个main()函数的启动器,直接跑main的。所以我需要重点关注main函数:
def main(unused_argv):
del unused_argv # Unused
print_hyperparams()
tf.compat.v1.logging.set_verbosity(tf.compat.v1.logging.INFO)
if FLAGS.dataset == 'ASCAD':
train_data = data_utils.Dataset(data_path=FLAGS.data_path, split="train",
input_length=FLAGS.input_length, data_desync=FLAGS.data_desync)
test_data = data_utils.Dataset(data_path=FLAGS.data_path, split="test",
input_length=FLAGS.input_length, data_desync=FLAGS.data_desync)
elif FLAGS.dataset == 'CHES20':
if FLAGS.do_train:
data_path = FLAGS.data_path + '.npz'
train_data = data_utils_ches20.Dataset(data_path=data_path, split="train",
input_length=FLAGS.input_length, data_desync=FLAGS.data_desync)
data_path = FLAGS.data_path + '_valid.npz'
test_data = data_utils_ches20.Dataset(data_path=data_path, split="test",
input_length=FLAGS.input_length, data_desync=FLAGS.data_desync)
else:
data_path = FLAGS.data_path + '.npz'
test_data = data_utils_ches20.Dataset(data_path=data_path, split="test",
input_length=FLAGS.input_length, data_desync=FLAGS.data_desync)
else:
assert False
if FLAGS.use_tpu:
resolver = tf.distribute.cluster_resolver.TPUClusterResolver(tpu='grpc://' + os.environ['COLAB_TPU_ADDR'])
tf.config.experimental_connect_to_cluster(resolver)
tf.tpu.experimental.initialize_tpu_system(resolver)
strategy = tf.distribute.experimental.TPUStrategy(resolver)
else:
strategy = tf.distribute.get_strategy()
tf.compat.v1.logging.info("Number of accelerators: %s" % strategy.num_replicas_in_sync)
if FLAGS.dataset == 'ASCAD':
chk_name = 'trans_long'
elif FLAGS.dataset == 'CHES20':
chk_name = 'trans_long'
else:
assert False
if FLAGS.do_train:
num_train_batch = train_data.num_samples // FLAGS.train_batch_size
num_test_batch = test_data.num_samples // FLAGS.eval_batch_size
tf.compat.v1.logging.info("num of train batches {}".format(num_train_batch))
tf.compat.v1.logging.info("num of test batches {}".format(num_test_batch))
train(train_data.GetTFRecords(FLAGS.train_batch_size, training=True), \
test_data.GetTFRecords(FLAGS.eval_batch_size, training=True), \
num_train_batch, num_test_batch, strategy, chk_name)
else:
num_test_batch = test_data.num_samples // FLAGS.eval_batch_size
tf.compat.v1.logging.info("num of test batches {}".format(num_test_batch))
output = evaluate(test_data.GetTFRecords(FLAGS.eval_batch_size, training=False),
strategy, chk_name)
test_scores = output[0]
attn_outputs = output[1:]
if test_scores is None:
return
if FLAGS.output_attn and not FLAGS.do_train:
nsamples = FLAGS.max_eval_batch*FLAGS.eval_batch_size
else:
nsamples = test_data.num_samples
if FLAGS.dataset == 'ASCAD':
plaintexts = test_data.plaintexts[:nsamples]
keys = test_data.keys[:nsamples]
elif FLAGS.dataset == 'CHES20':
nonces = test_data.nonces[:nsamples]
keys = test_data.umsk_keys
key_rank_list = []
for i in range(100):
if FLAGS.dataset == 'ASCAD':
key_ranks = evaluation_utils.compute_key_rank(test_scores, plaintexts, keys)
elif FLAGS.dataset == 'CHES20':
key_ranks = evaluation_utils_ches20.compute_key_rank(test_scores, nonces, keys)
key_rank_list.append(key_ranks)
key_ranks = np.stack(key_rank_list, axis=0)
with open(FLAGS.result_path+'.txt', 'w') as fout:
for i in range(key_ranks.shape[0]):
for r in key_ranks[i]:
fout.write(str(r)+'\t')
fout.write('\n')
mean_ranks = np.mean(key_ranks, axis=0)
for r in mean_ranks:
fout.write(str(r)+'\t')
fout.write('\n')
tf.compat.v1.logging.info("written results in {}".format(FLAGS.result_path))
if FLAGS.output_attn:
pickle.dump(attn_outputs, open(FLAGS.result_path+'.pkl', 'wb'))尤其是main函数里和train相关的部分:
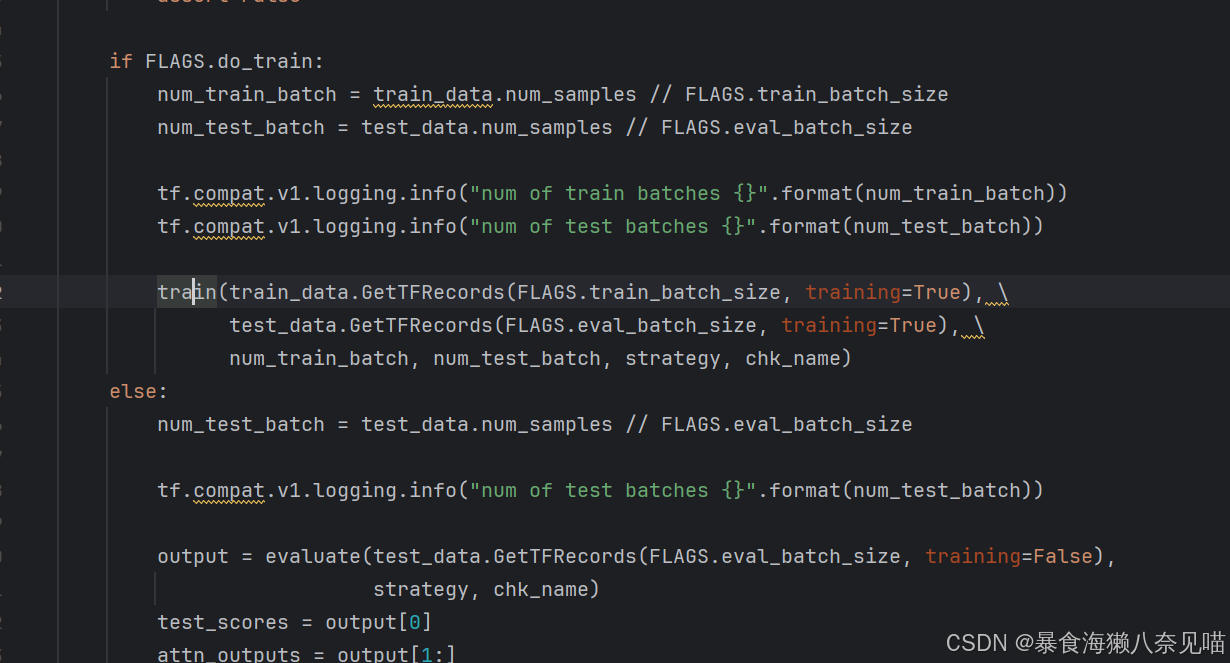
我们发现train只在这里有,而下面就是我们的问题所在:我们的output。现在我们重新看这里,我们发现,在代码中train和evaluate,是完全分开的。所以我们没有文件,其实是之前根本没有训练的过程,直接评估了,很乐,确实是我这样的科研小白加菜鸡干的出来的事情。那我们改一下这边的do_train试试吧。
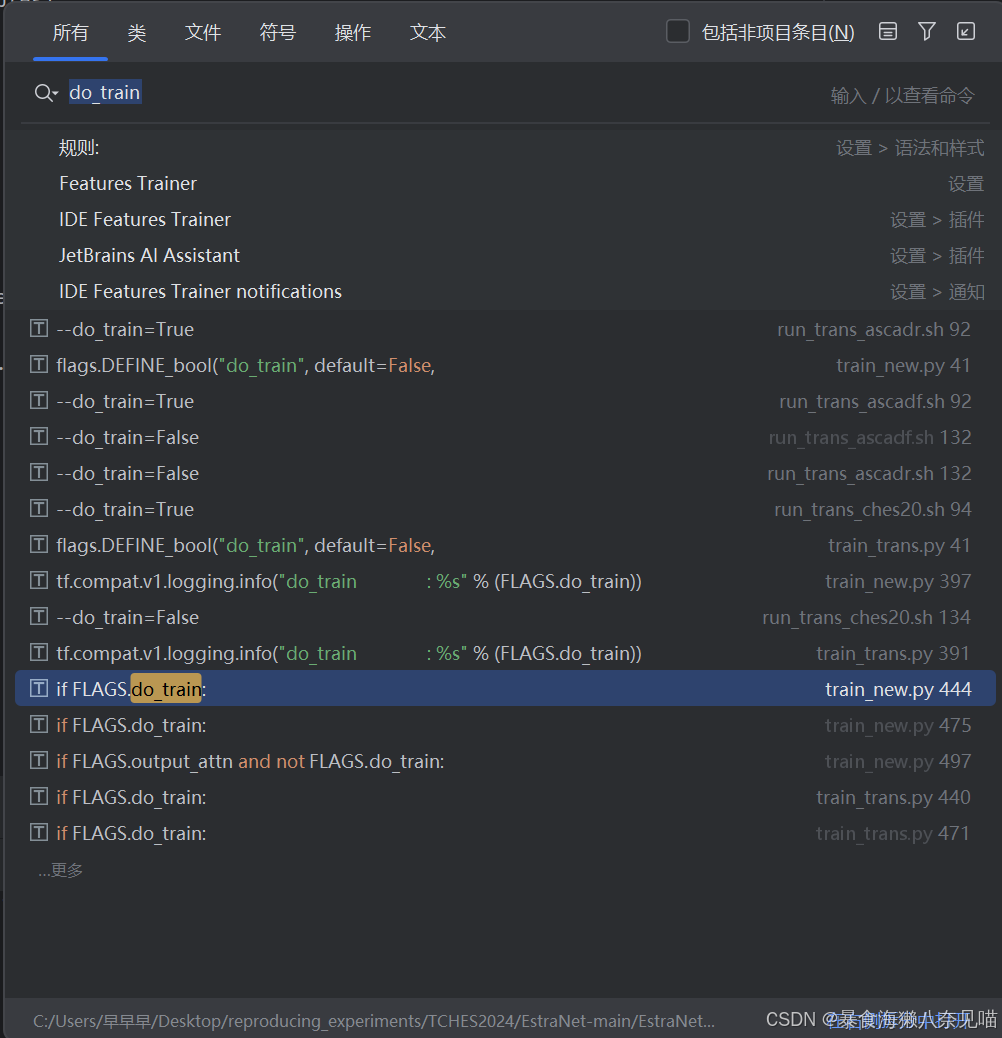
我们发现do_train除了一个默认是False以外没有任何的赋值点。
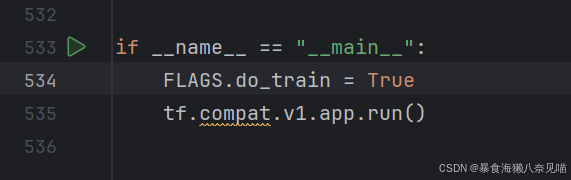
结果呢?

好消息,开始训练了!坏消息,还是报错!
它说我的checkpoints不是一个有效的目录!
下午再搞一下
隔了挺久的,再更新一下,找了好久为什么不成功,结果我绷不住了,因为我的路径里带了中文
D:\reproducing_experiments\TCHES2024\EstraNet-main\EstraNet-main
我现在把路径换到没有中文路径的D盘,就可以跑了,不过我问了跑过代码的学长,学长说整个代码跑下来要30多个小时。
我就放到实验室的电脑上去跑了,等我跑完再更新。
乐,实验室台式机4070跑了41个小时了,还没跑完
这是刚刚开始跑:

这是目前跑出的直观内容:
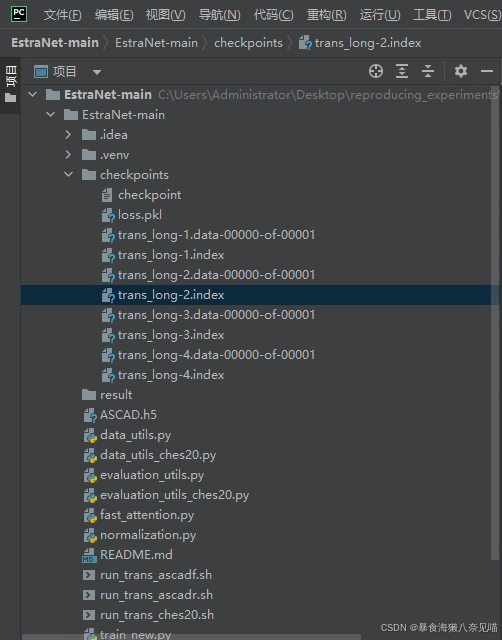
不知道什么时候跑完,让它清明慢慢跑吧
跑完了,之前跑到4.index花了41个小时,我们这个总共11个index的训练过程怕不是要花上120个小时,整个清明都在跑这个代码了。这还只是训练过程,现在Ciallo~(∠・ω< )⌒★要进入验证(评估)环节啦!
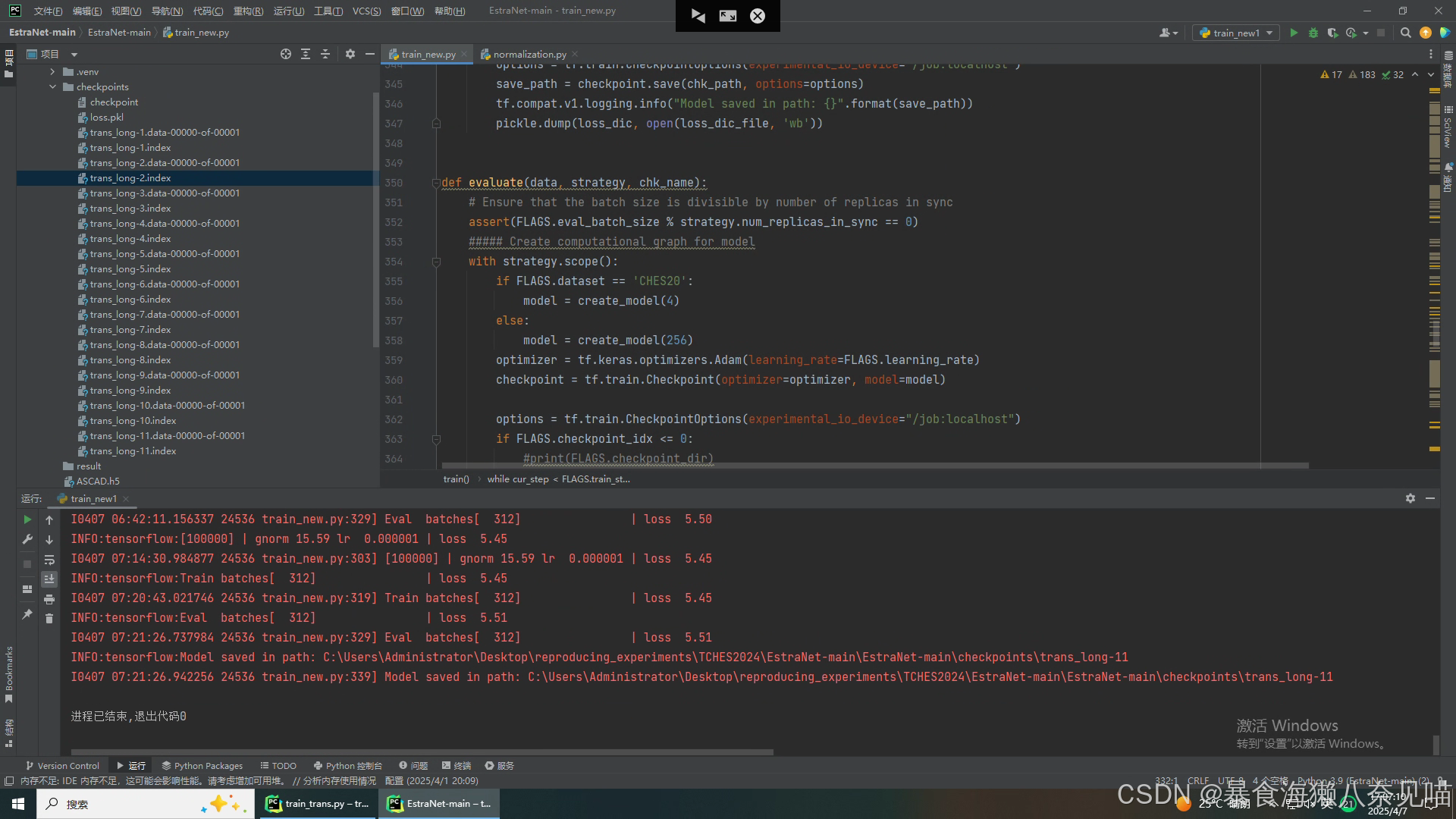
进入验证(评估|evaluate)环节!!!!!
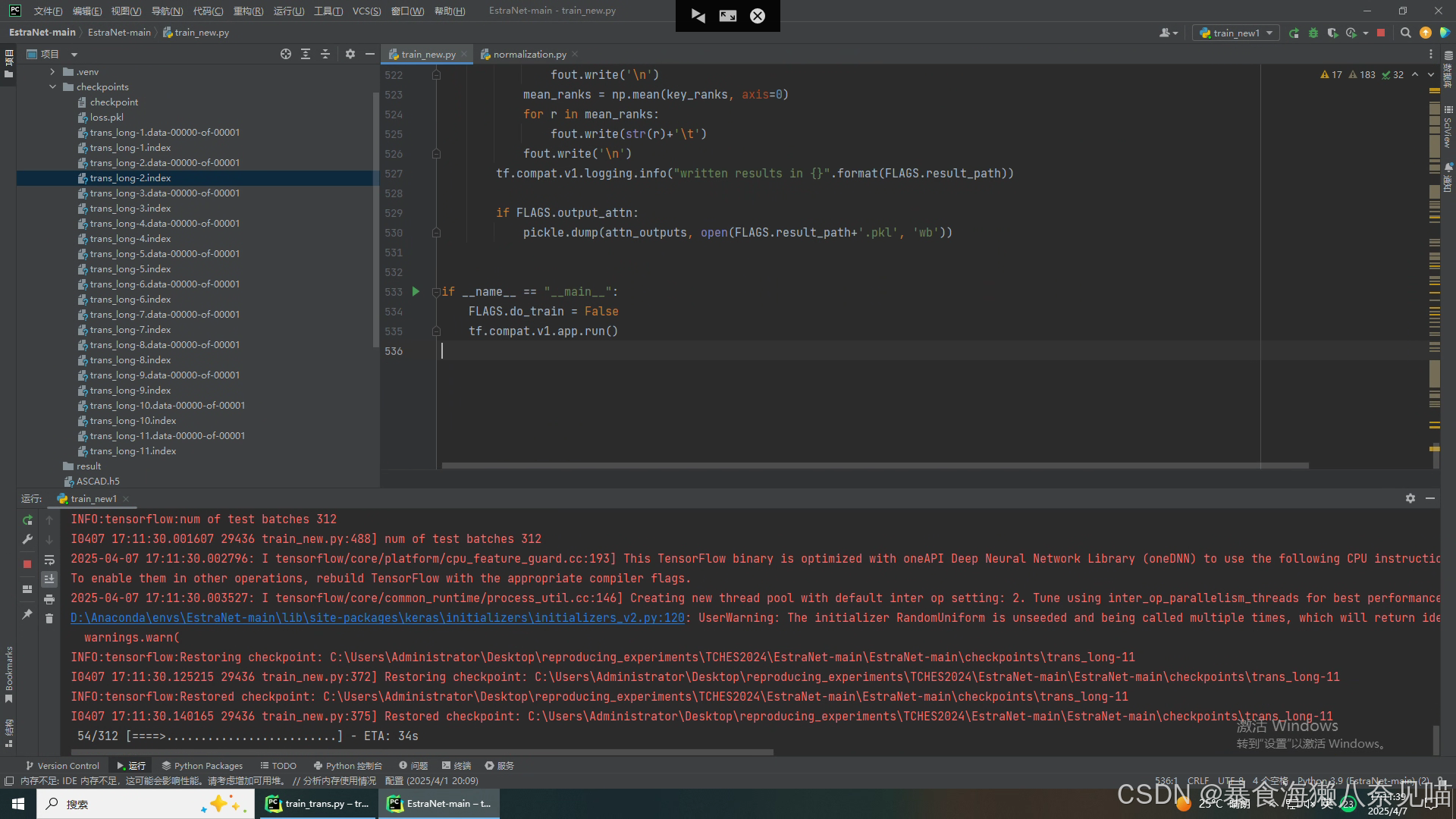
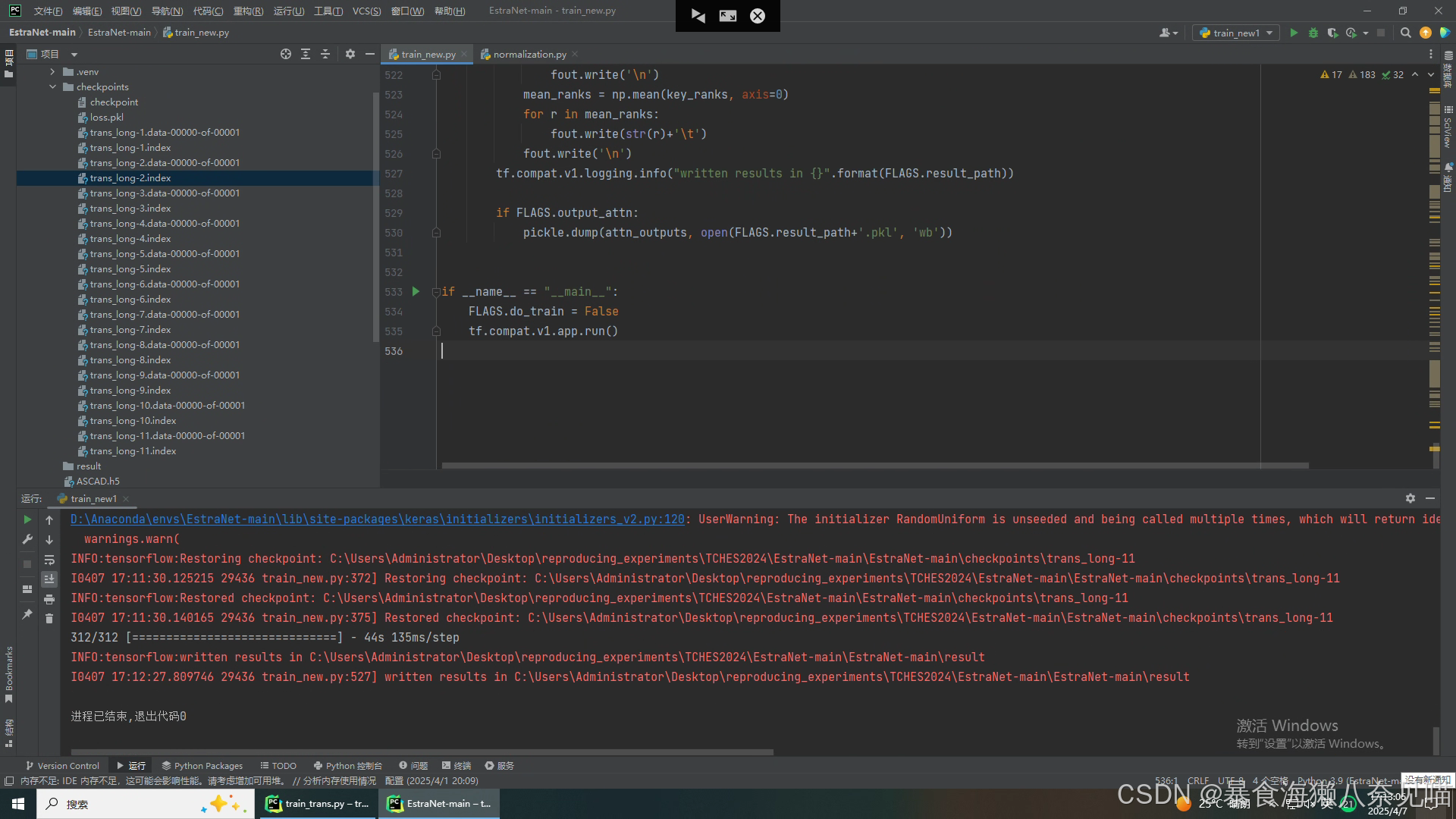
几秒钟,验证(评估)就结束了!?
这result里面明明是空的呀!
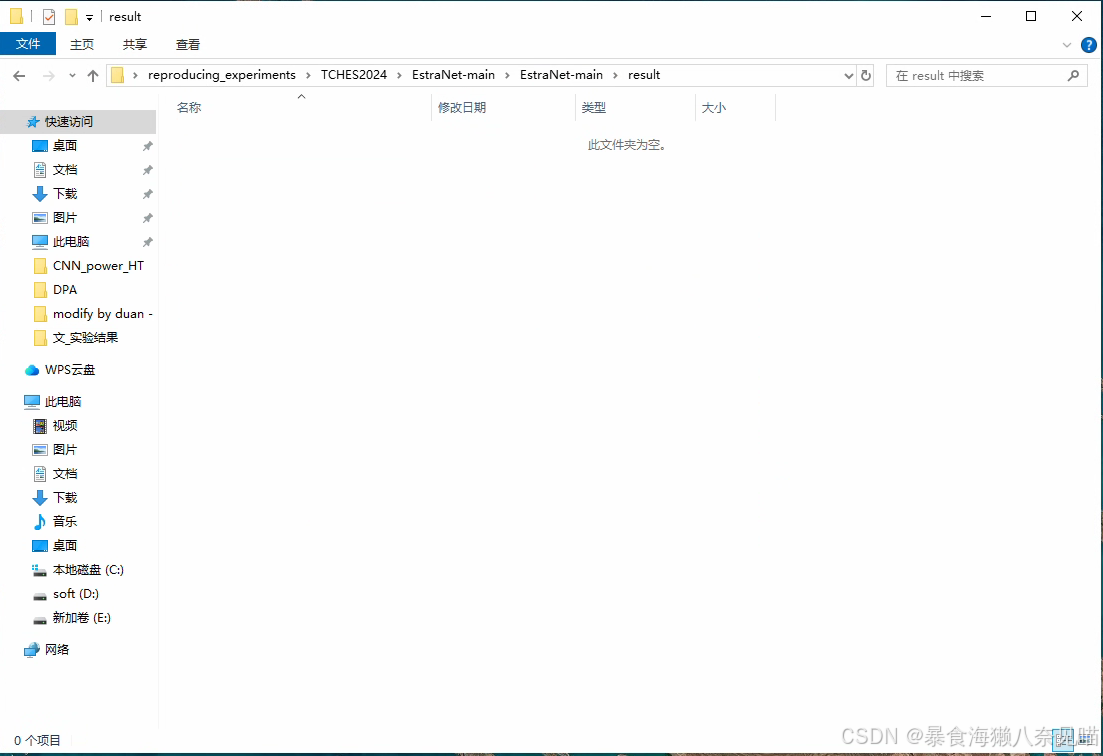
应该又是什么环节出来问题,我再看看吧(〒︿〒)
初步破案了,不是没result,而是result.txt没放在result文件夹里,可是这个result我也看不懂啊。得请教一下了。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)