NLPCDA —— 基于SimBERT的相似文本生成
·
NLPCDA —— 基于SimBERT的相似文本生成
感谢苏神开源的SimBERT,笔者先前简单尝试了SimBERT在相似文本生成的应用。同时结合nlpcda作者开源的代码,所以才有了博客中的demo:NLPCDA——中文数据增强工具。估计是标题不够高大上,或者大家不知道NLPCDA这个工具,阅读量不大。
最近,苏神又开源了RoFormer-Sim模型(SimBERT的升级版,简称SimBERTv2),链接:SimBERTv2来了!融合检索和生成的RoFormer-Sim模型。
1. SimBERT与SimBERTv2的核心区别
- A. 训练细节
SimBERT = BERT + UniLM + 对比学习
SimBERTv2 = RoFormer + UniLM + 对比学习 + BART + 蒸馏- B. 更大的batch_size和maxlen:SimBERTv2模型代码
- C. 训练语料构建
SimBERT:疑问类型相似句
SimBERTv2:疑问类型相似句 + 通用类型相似句
- D. 生成能力
SimBERT:无BART
SimBERTv2:基于BART的思想,“输入带噪声的句子,输出原句子的一个相似句“- E. 蒸馏
蒸馏的目的:在SimBERTv2训练完之后,进一步通过蒸馏的方式把SimBERT的检索效果转移到SimBERTv2上去,从而使得SimBERTv2的检索效果基本持平甚至优于SimBERT。2. SimBERTv2的相似文本生成demo
代码其实还是和上篇博客中一样,只是模型不一样,并且需要更新bert4keras的版本,以及修改源码中的generator函数。一步一步说吧。
(1)python的demo
from nlpcda import Simbert
from time import time
def test_sing(simbert, N):
"""
功能: 单元测试
:param simbert:
:return:
"""
while True:
text = input("\n输入: ")
ss = time()
synonyms = simbert.replace(sent=text, create_num=N)
for line in synonyms:
print(line)
print("总耗时{0}ms".format(round(1000 * (time() - ss), 3)))
if __name__ == "__main__":
# SimBERT模型: Simbert/chinese_simbert_L-12_H-768_A-12
# SimBERTv2模型: Simbert/chinese_roformer-sim-char_L-12_H-768_A-12
config = {
'model_path': 'Simbert/chinese_roformer-sim-char_L-12_H-768_A-12',
'device': 'cuda',
'max_len': 32,
'seed': 1
}
sim_bert = Simbert(config=config)
test_sing(simbert=sim_bert, N=10) # 单元测试说明:chinese_roformer-sim-char_L-12_H-768_A-12模型下载链接,苏神是提供了的。
- chinese_roformer-sim-char_L-12_H-768_A-12.zip(提取码:2cgz)
- chinese_roformer-sim-char_L-6_H-384_A-6.zip(提取码:h68q)
(2)包版本更新
pip install bert4keras==0.10.6(3)generator.py文件修改
改后的代码应该是
# -*- coding: utf-8 -*-
import os
import numpy as np
from bert4keras.backend import keras
from bert4keras.models import build_transformer_model
from bert4keras.tokenizers import Tokenizer
from bert4keras.snippets import sequence_padding, AutoRegressiveDecoder
def setup_seed(seed):
try:
import random
import numpy as np
np.random.seed(seed)
random.seed(seed)
except Exception as e:
pass
class SynonymsGenerator(AutoRegressiveDecoder):
"""seq2seq解码器
"""
def __init__(self, model_path, max_len=32, seed=1):
# super().__init__()
setup_seed(seed)
self.config_path = os.path.join(model_path, "bert_config.json")
self.checkpoint_path = os.path.join(model_path, "bert_model.ckpt")
self.dict_path = os.path.join(model_path, "vocab.txt")
self.max_len = max_len
self.tokenizer = Tokenizer(self.dict_path, do_lower_case=True)
self.bert = build_transformer_model(
self.config_path,
self.checkpoint_path,
# model='roformer', # SimBERTv2模型加载, SimBERT模型加载时, 注释该行
with_pool='linear',
application='unilm',
return_keras_model=False,
)
self.encoder = keras.models.Model(self.bert.model.inputs,
self.bert.model.outputs[0])
self.seq2seq = keras.models.Model(self.bert.model.inputs,
self.bert.model.outputs[1])
super().__init__(start_id=None, end_id=self.tokenizer._token_end_id,
maxlen=self.max_len)
# @AutoRegressiveDecoder.set_rtype('probas') # bert4keras==0.7.7
@AutoRegressiveDecoder.wraps(default_rtype='probas') # bert4keras==0.10.6
def predict(self, inputs, output_ids, states):
token_ids, segment_ids = inputs
token_ids = np.concatenate([token_ids, output_ids], 1)
segment_ids = np.concatenate(
[segment_ids, np.ones_like(output_ids)], 1)
return self.seq2seq.predict([token_ids, segment_ids])[:, -1]
def generate(self, text, n=1, topk=5):
# bert4keras==0.7.7
# token_ids, segment_ids = self.tokenizer.encode(
# text, max_length=self.max_len)
# bert4keras==0.10.6
token_ids, segment_ids = self.tokenizer.encode(
text, maxlen=self.max_len)
output_ids = self.random_sample([token_ids, segment_ids], n, topk)
return [self.tokenizer.decode(ids) for ids in output_ids]
def gen_synonyms(self, text, n=100, k=20, threhold=0.75):
""""含义: 产生sent的n个相似句,然后返回最相似的k个。
做法:用seq2seq生成,并用encoder算相似度并排序。
"""
r = self.generate(text, n)
r = [i for i in set(r) if i != text]
r = [text] + r
X, S = [], []
for t in r:
x, s = self.tokenizer.encode(t)
X.append(x)
S.append(s)
X = sequence_padding(X)
S = sequence_padding(S)
Z = self.encoder.predict([X, S])
Z /= (Z ** 2).sum(axis=1, keepdims=True) ** 0.5
scores = np.dot(Z[1:], Z[0])
argsort = scores.argsort()
scores = scores.tolist()
# print(scores.shape)
# return [(r[i + 1], scores[i]) for i in argsort[::-1][:k] if scores[i] > threhold]
return [(r[i + 1], scores[i]) for i in argsort[::-1][:k]]
最后,我们再来运行下SimBERTv2模型的生成结果。
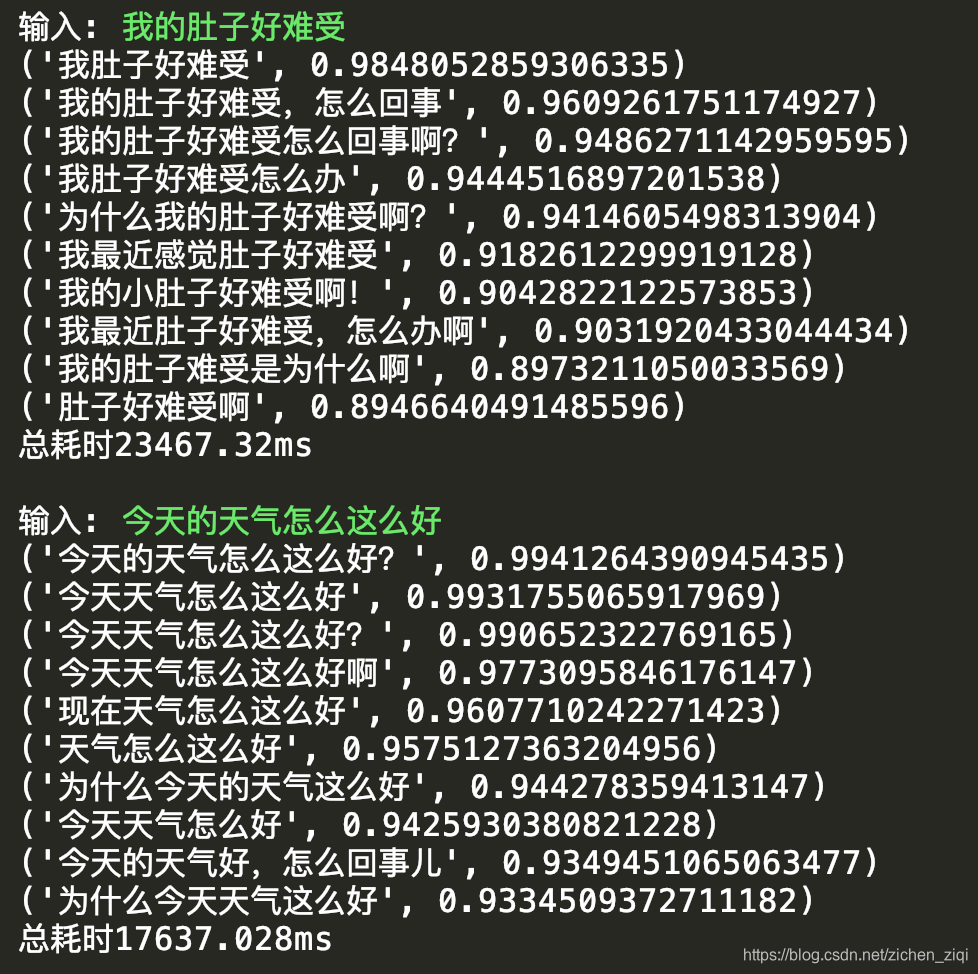
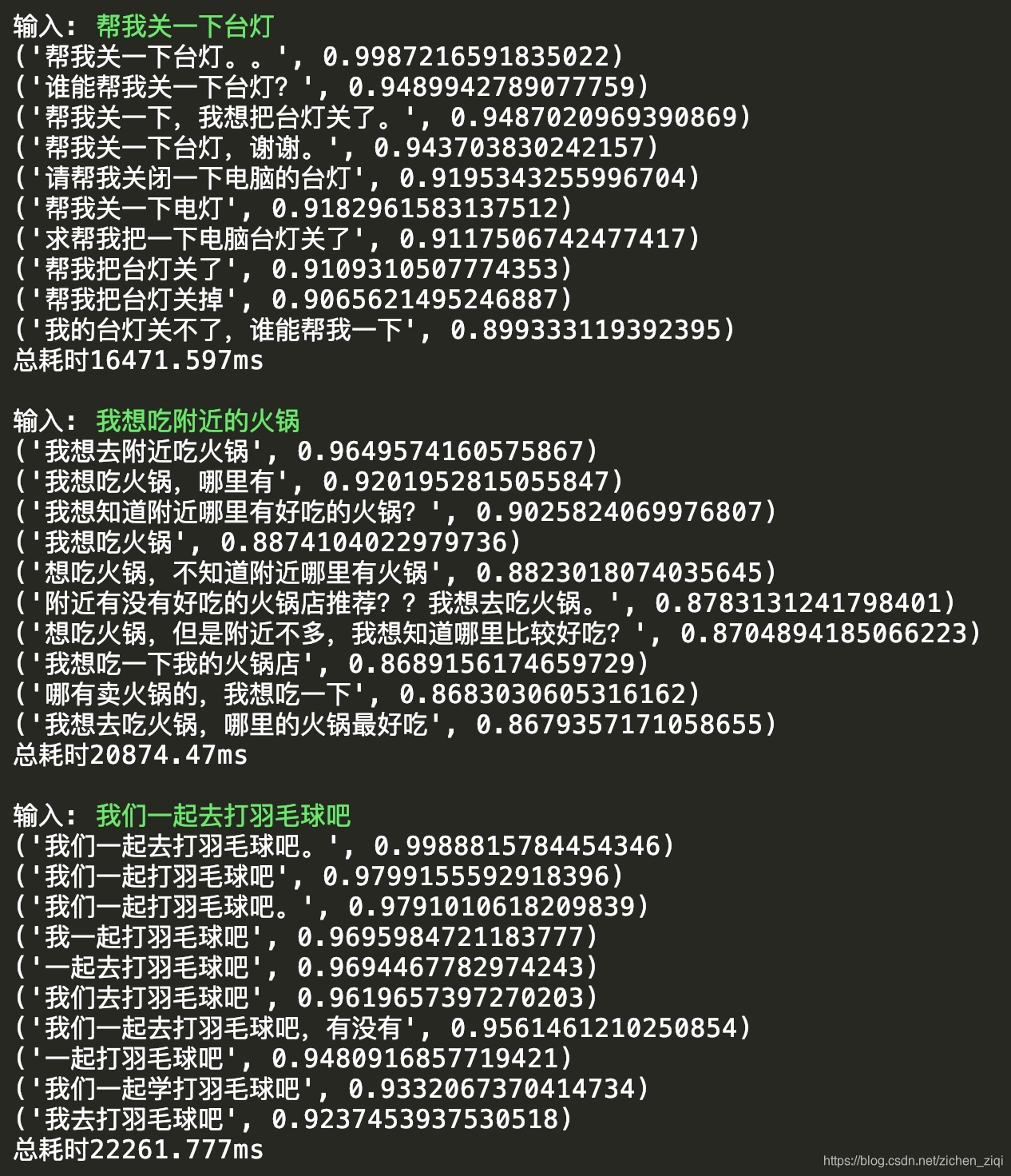
为了对比出SimBERTv2的优势,笔者试了3条一般问句在SimBERT和SimBERTv2的结果。
帮我关一下台灯
我想吃附近的火锅
我们一起去打羽毛球吧- SimBERTv2模型的相似文本生成结果
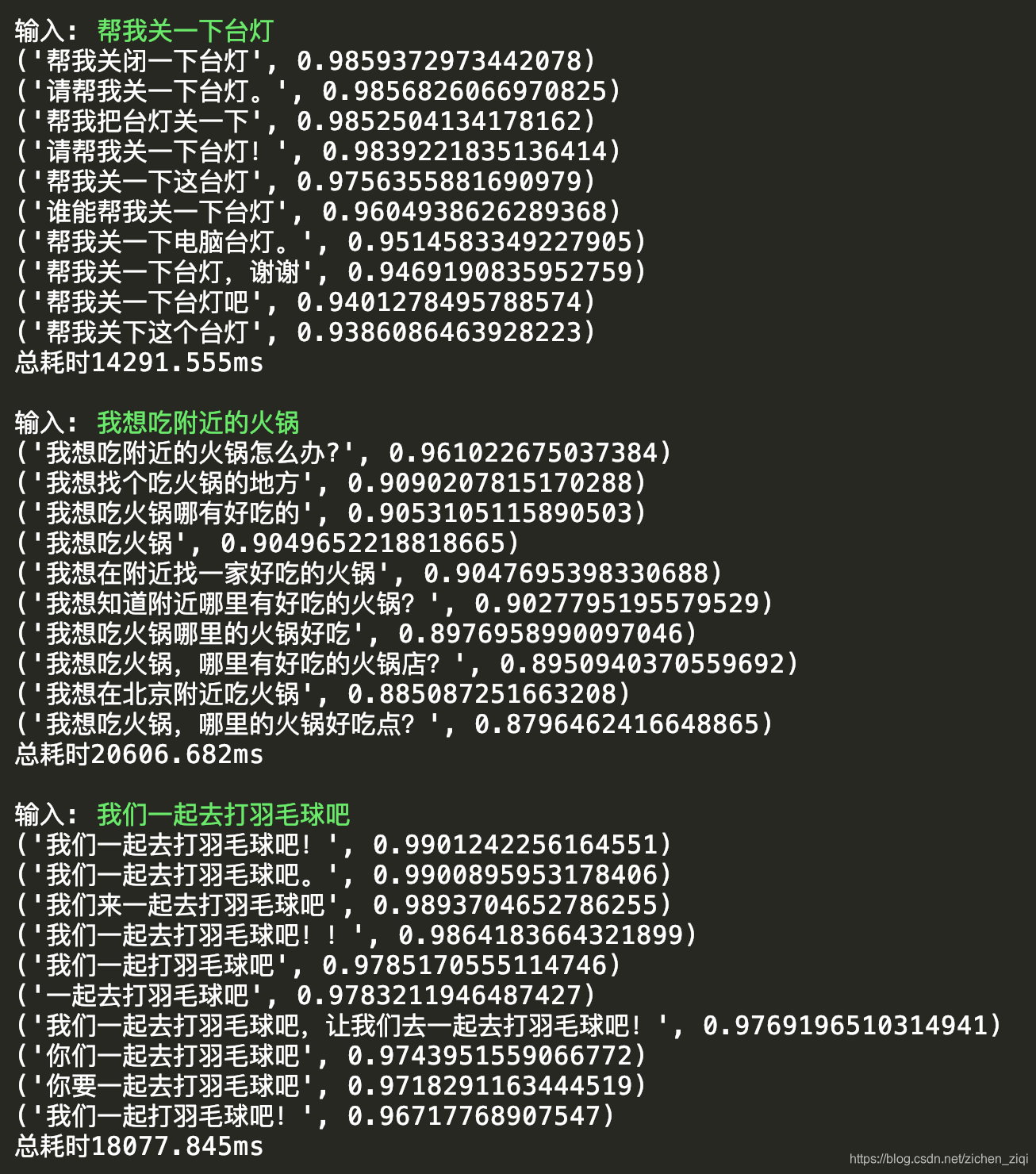
- SimBERT模型的相似文本生成结果

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 6
6 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)