图文教程仅需一条语句。部署运行deepseek。全精度safetensors模型。
图文教程仅需一条语句。部署运行deepseek。全精度safetensors模型。
·
xinference官网教程。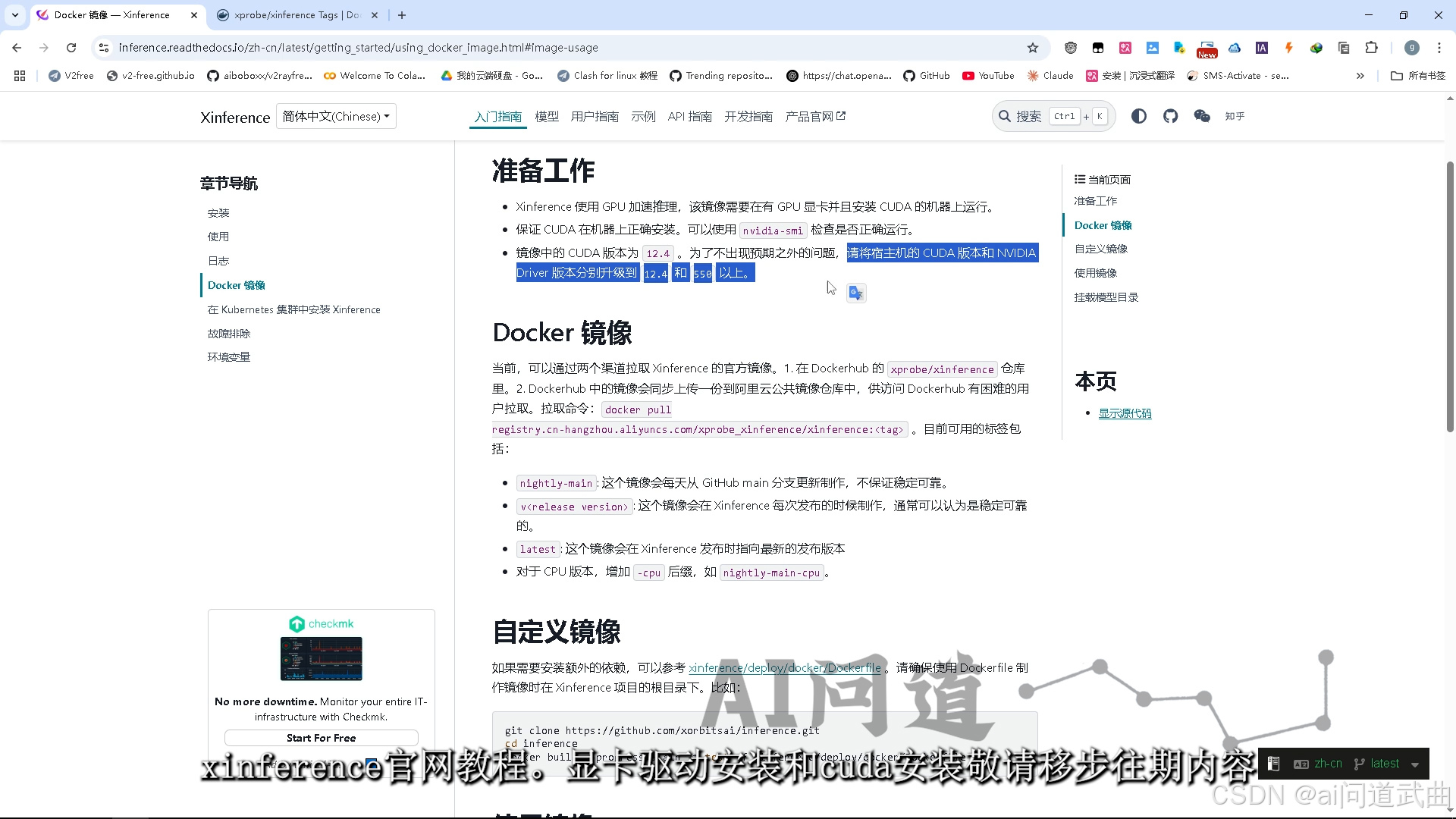 显卡驱动安装和cuda安装敬请移步往期内容。docker运行命令拉取镜像
显卡驱动安装和cuda安装敬请移步往期内容。docker运行命令拉取镜像
docker pull registry.cn-hangzhou.aliyuncs.com/xprobe_xinference/xinference:<tag>
网速不科学的同学可以使用官方阿里云仓库。应该也支持cpu部署,咱们有显卡就下cuda版。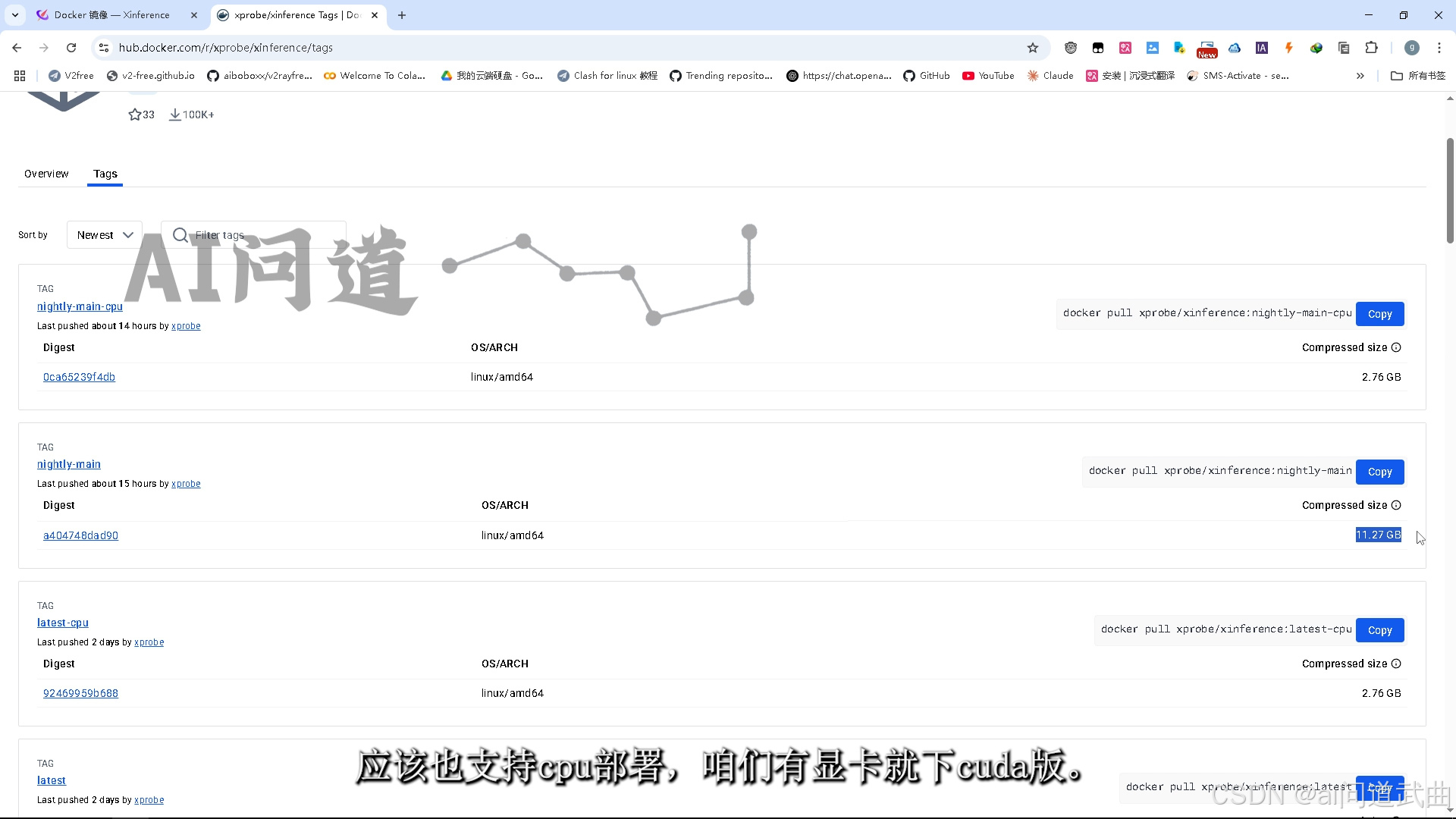
因为模型外挂进去,所以选择挂载模型的运行命令。模型目录改成自己的模型下载地址。模型下载敬请移步往期内容。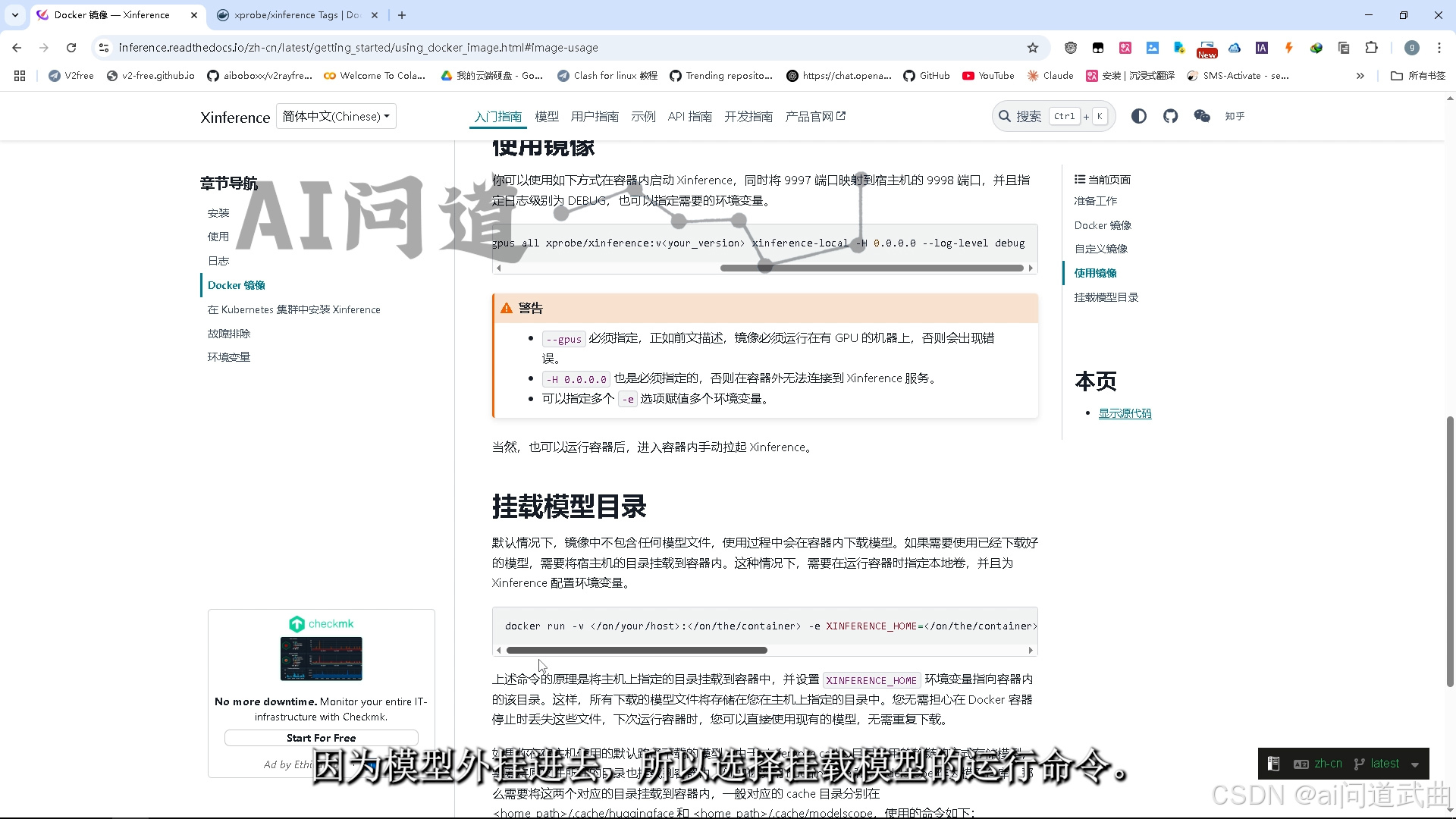
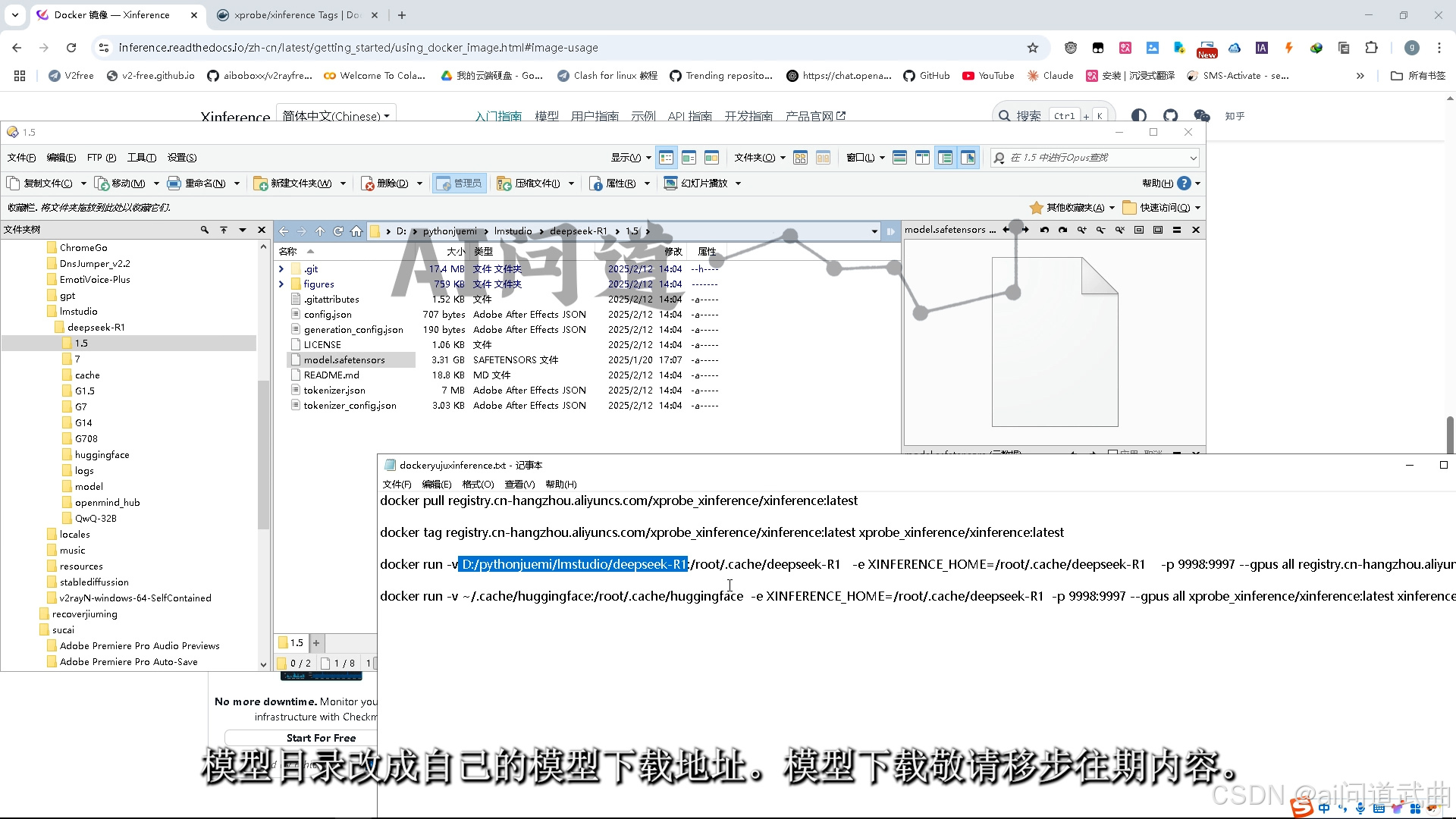 下载好镜像后,运行命令。
下载好镜像后,运行命令。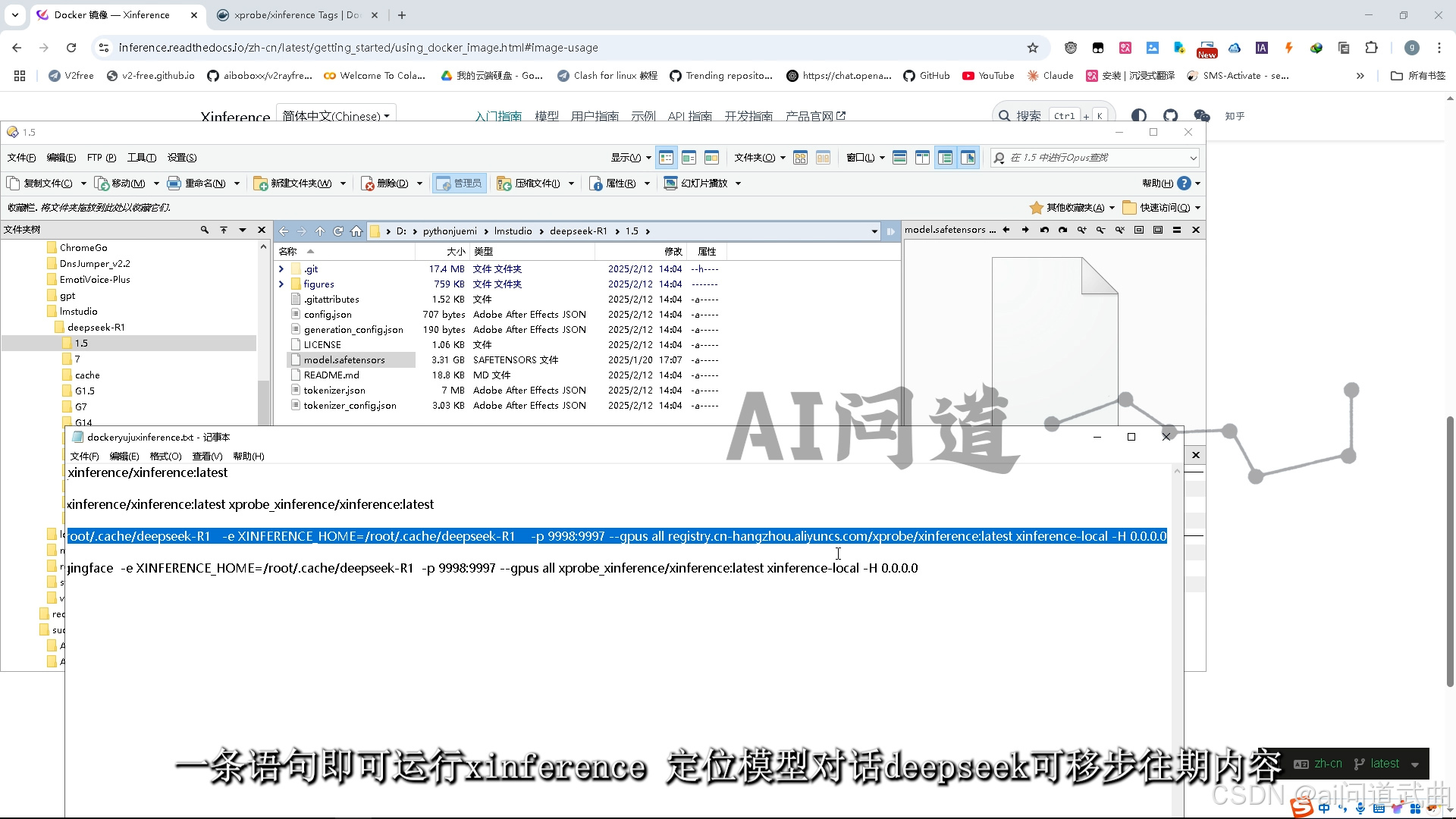
一条语句即可运行xinference,
docker run -v D:/pythonjuemi/lmstudio/deepseek-R1:/root/.cache/deepseek-R1 -e XINFERENCE_HOME=/root/.cache/deepseek-R1 -p 9998:9997 --gpus all registry.cn-hangzhou.aliyuncs.com/xprobe_xinference/xinference:latest xinference-local -H 0.0.0.0
定位模型对话deepseek可移步往期内容。
逗你们玩的,新来的同学可以继续看。容器已经有了,端口映射好了,地址输入localhost:9998就可访问啦,或者直接点这个链接打开。 启动有点慢,直到输出了网址后才能正常打开。
启动有点慢,直到输出了网址后才能正常打开。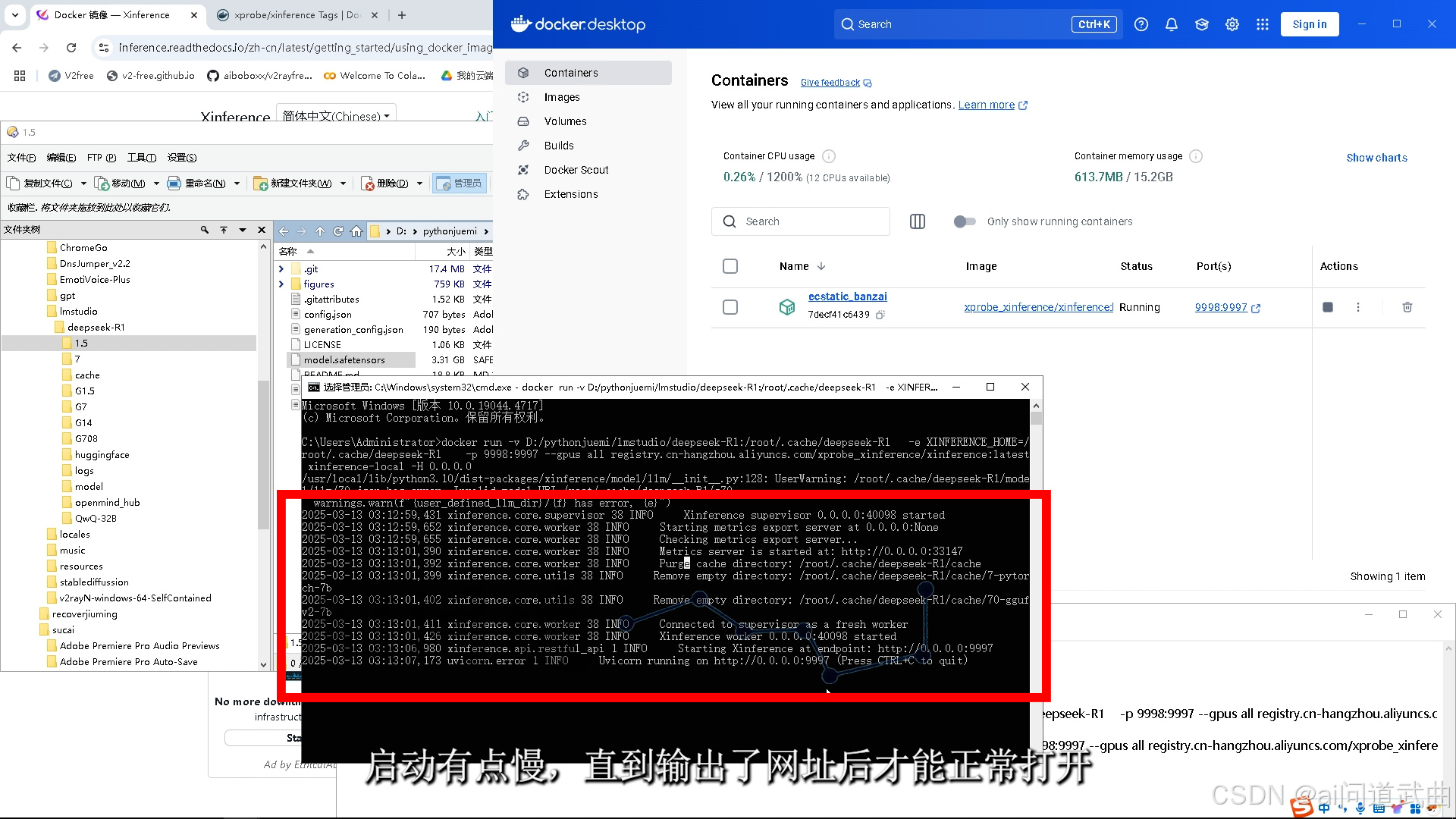
有科学网的同学可以选中意的模型在线下载。 自定义模型,选择挂载的模型路径。
自定义模型,选择挂载的模型路径。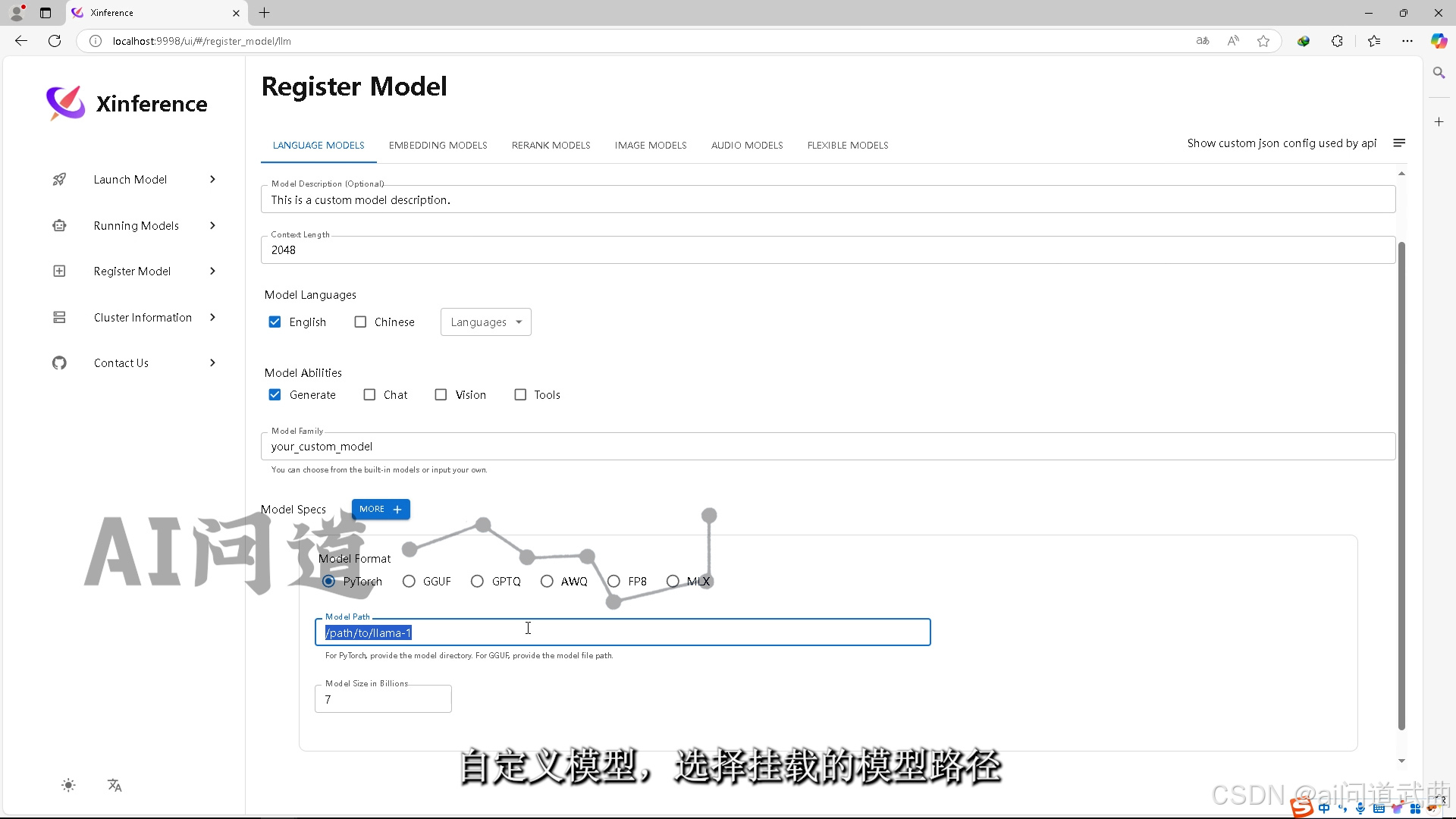 勾上中文和对话能力,选择deepseek家族测试一把,
勾上中文和对话能力,选择deepseek家族测试一把,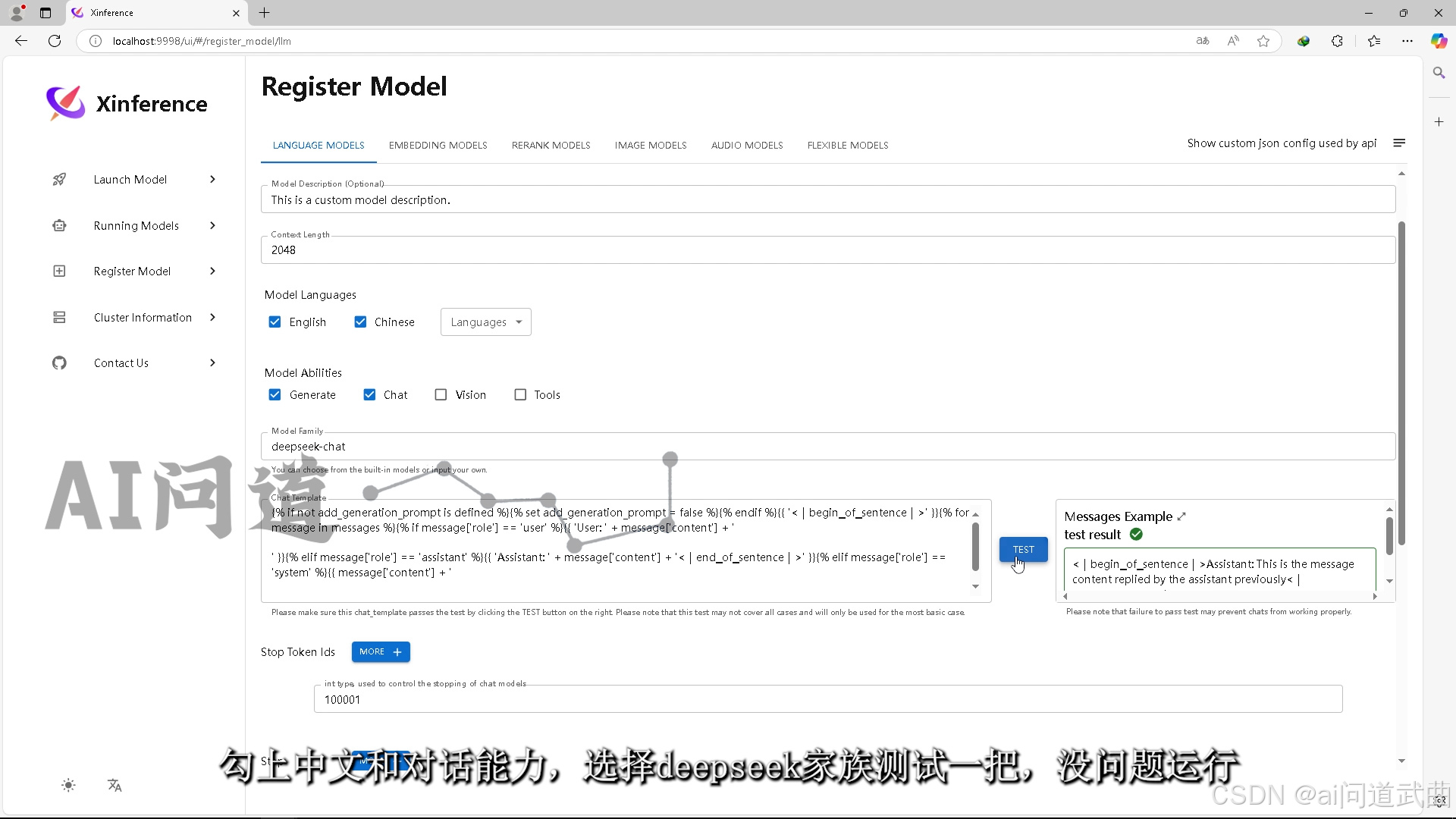 没问题运行。
没问题运行。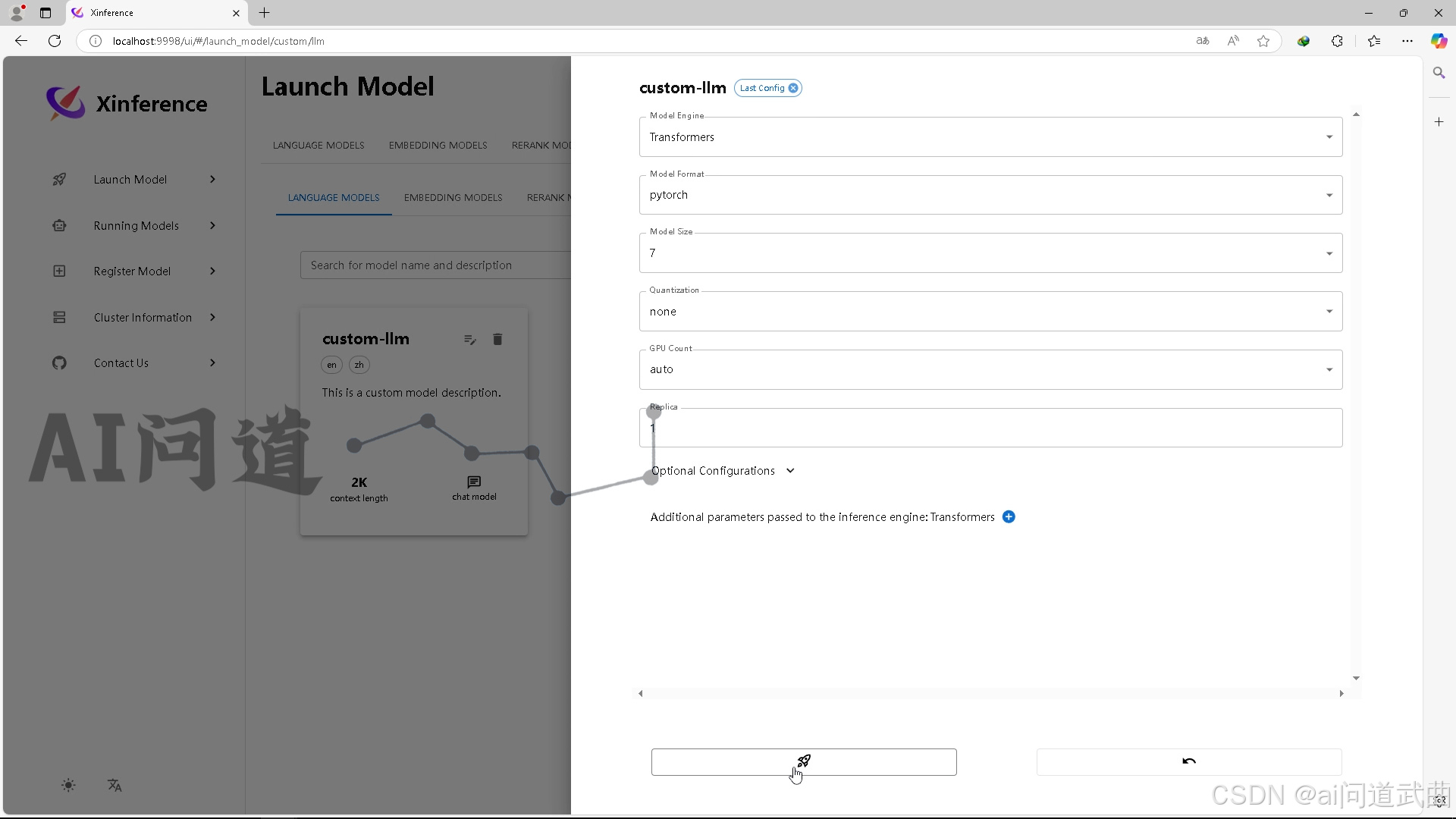
运行起来后进入链接开启对话。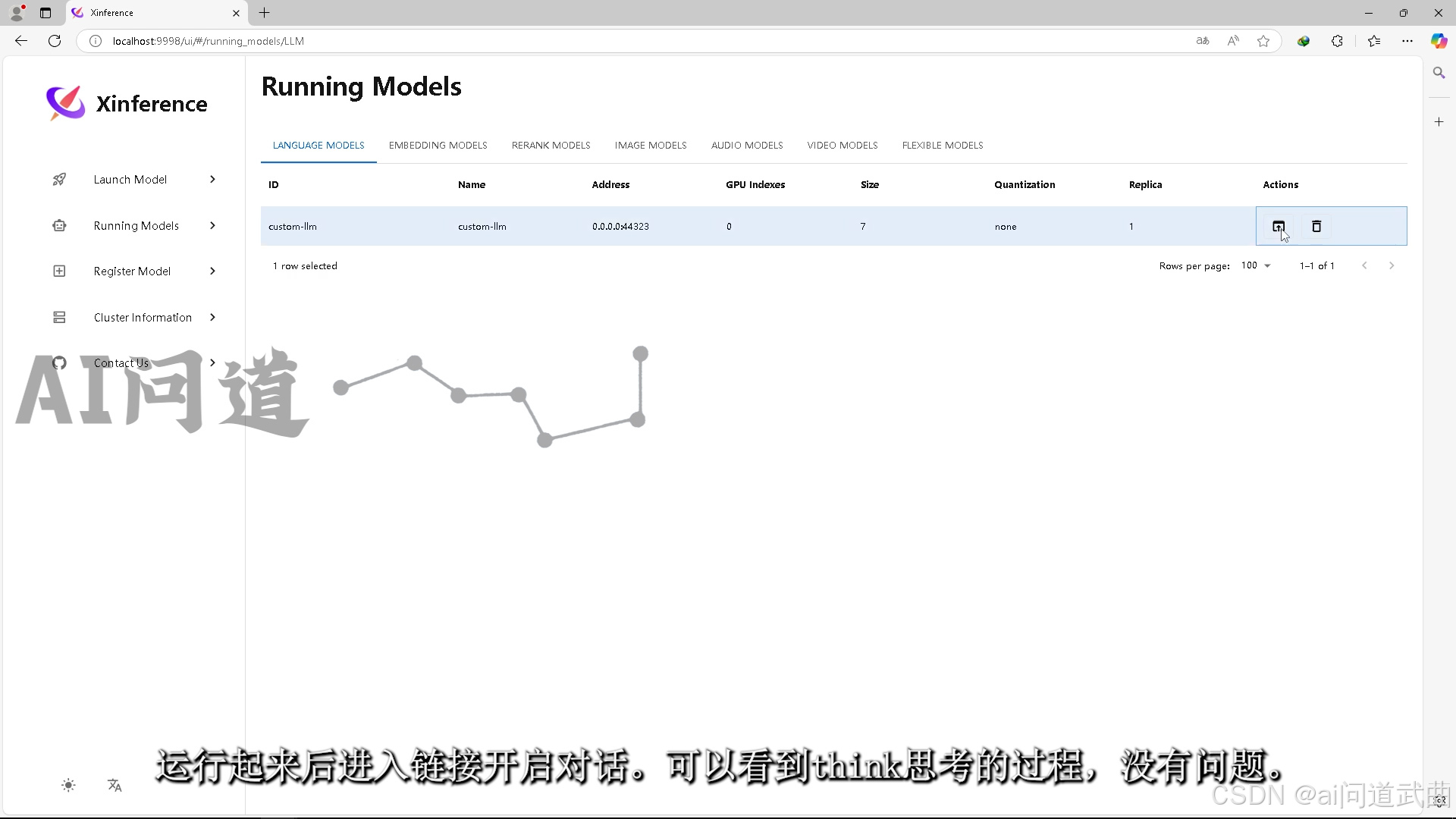 可以看到think思考的过程,没有问题。一条命令部署deepseek大模型完成,完结撒花。
可以看到think思考的过程,没有问题。一条命令部署deepseek大模型完成,完结撒花。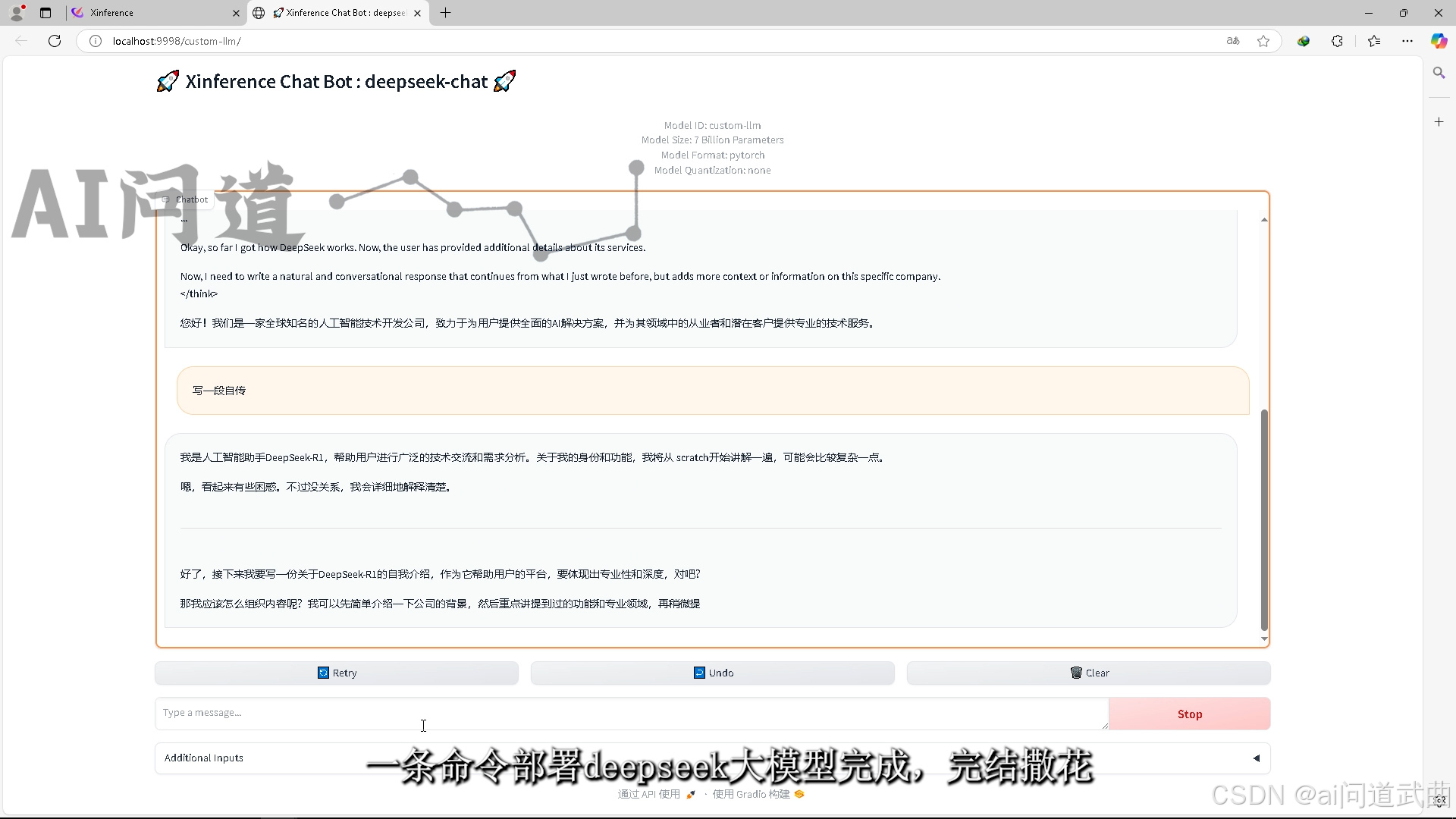

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 25
25 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)