kaggle--猫狗数据集分类
首先需要下载相关的数据集,可从kaggle官网进行下载下载的数据集分为train和test两部分,而train数据集中的图像并非都是连续的,所以若要截取部分图像进行训练,则应注意首先创建属于自己的数据集,此次学习并没有用到所以的数据,而只有2000张训练图像,1000张测试图像和1000张验证图像import os,shutil#原始训练数据存放位置,在当前目录下的dog-and-...
·
首先需要下载相关的数据集,可从kaggle官网进行下载
下载的数据集分为train和test两部分,而train数据集中的图像并非都是连续的,所以若要截取部分图像进行训练,则应注意
首先创建属于自己的数据集,此次学习并没有用到所以的数据,而只有2000张训练图像,1000张测试图像和1000张验证图像
import os,shutil
#原始训练数据存放位置,在当前目录下的dog-and-cat-original/train中
original_dataset_dir = './dog-and-cat-original/train'
#创建更小的数据集的目录
base_dir = './dog-and-cat-smalldata1'
os.mkdir(base_dir)
#分别创建关于训练,验证和测试的数据集目录
train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir, 'validation')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)
train_cats_dir = os.path.join(train_dir, 'cats')
os.mkdir(train_cats_dir)
train_dogs_dir = os.path.join(train_dir, 'dogs')
os.mkdir(train_dogs_dir)
validation_cats_dir = os.path.join(validation_dir, 'cats')
os.mkdir(validation_cats_dir)
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
os.mkdir(validation_dogs_dir)
test_cats_dir = os.path.join(test_dir, 'cats')
os.mkdir(test_cats_dir)
test_dogs_dir = os.path.join(test_dir, 'dogs')
os.mkdir(test_dogs_dir)
#将相关的图像copy到对应目录
fnames = ['cat.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_cats_dir, fname)
shutil.copyfile(src, dst)
fnames = ['cat.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_cats_dir, fname)
shutil.copyfile(src, dst)
fnames = ['cat.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_cats_dir, fname)
shutil.copyfile(src, dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(10000,11000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_dogs_dir, fname)
shutil.copyfile(src, dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(11000, 11500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_dogs_dir, fname)
shutil.copyfile(src, dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(11500, 12000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_dogs_dir, fname)
shutil.copyfile(src, dst)
构建网络
from keras import layers
from keras import models
model = models.Sequential()
#网络中特征图的深度逐渐增大,从32增加到128,然后不变,而特征图的尺寸从150x150减小大7x7,这种模式
#在卷积神经网络中相当常见
#32,64,128为输出的维度,(3,3)为卷积步长
model.add(layers.Conv2D(32,(3,3),activation = 'relu',input_shape = (150,150,3)))
#MaxPooling2D为最大池化层,(2,2)使图片两个维度均减少为原来的一半
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64,(3,3),activation = 'relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128,(3,3),activation = 'relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128,(3,3),activation = 'relu'))
model.add(layers.MaxPooling2D((2,2)))
#把3D向量展平为1D向量
model.add(layers.Flatten())
#输出维度为512
model.add(layers.Dense(512,activation = 'relu'))
model.add(layers.Dense(1,activation = 'sigmoid'))编译
from keras import optimizers
#二分类问题使用二元交叉熵,lr为大于等于0的浮点数,为学习率
model.compile(loss='binary_crossentropy',optimizer = optimizers.RMSprop(lr = 1e-4),metrics=['acc'])处理图像数据
#数据预处理
#步骤1.读取图像文件2.将jpeg文件解码为RGB像素网格3.将这些像素网格转换为浮点数张量4.将像素值(0-255范围内)缩放到[0,1]区间
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale=1/255)
test_datagen = ImageDataGenerator(rescale=1/255)
#将所有的图像代销调整为(150,150),因为使用了binary_crossentropy损失,所以需要用二进制标签
#color_mode: 颜色模式,为"grayscale","rgb"之一,默认为"rgb".代表这些图片是否会被转换为单通道或三通道的图片
train_generator = train_datagen.flow_from_directory(train_dir,target_size=(150,150),batch_size=20,class_mode='binary')
validation_generator = test_datagen.flow_from_directory(validation_dir,target_size=(150,150),batch_size=20,class_mode
='binary')
#生成器输出,每个批量包含20个样本,一个样本生成了150x150的RGB图像
for data_batch,labels_batch in train_generator:
print("data batch shape:",data_batch.shape)
print("labels batch shape:",labels_batch.shape)
break
#生成器输出为data batch shape: (20, 150, 150, 3)
# labels batch shape: (20,)
#使用fit_generator进行训练,由于每轮需要从生成器中抽取20个样本,所以全部抽取完毕需要100个批量,当抽取完100个批量后就会进入到下一轮次的训练,epochs=30表示训练30轮,validation_steps=50表示从验证生成器抽取50个批次进行训练
history = model.fit_generator(train_generator,steps_per_epoch=100,epochs=30,
validation_data=validation_generator,validation_steps=50)
#然后可以保存模型
model.save('cats_and_dogs_small_1.h5')最后绘制图形
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()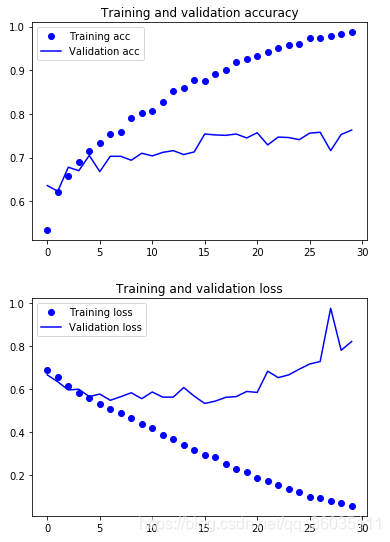
可以发现随着时间的增加,训练精度也在上升,直到接近100%,训练损失也在下降,直到接近0。但是验证精度大约在72%-78%之间,验证损失大约在第15轮到达最小值,由于训练数据较少,所以产生了过拟合。那么就要降低过拟合,除了之间的dropout和L2正则化。在图像处理方面常会用到数据增强。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)