InfoMasker :新型反窃听系统,保护语音隐私
本文提出了一种高效且鲁棒的反窃听系统Infomasker,可以在干扰麦克风的同时保留授权录音。该系统利用信息掩蔽的思想,设计了一种基于音素的噪声,可以干扰机器和人类的理解,并且难以被降噪技术去除。此外,该系统还优化了噪声传输策略,并实现了硬件原型。
随着智能手机、智能音箱等设备的普及,人们越来越担心自己的谈话内容被窃听。由于这些设备通常是黑盒的,攻击者可能利用、篡改或配置这些设备进行窃听。借助自动语音识别 (ASR) 系统,攻击者可以从窃听的录音中提取受害者的个人信息,从而侵犯其隐私。许多新闻报道了设备如Siri、Alexa、Google Assistant或小度等始终存在被窃听的风险,特别是一些报道还显示了窃听造成的严重后果:2021年,一段泄露的录音显示伊朗革命卫队推翻了许多政府决策,使得录音中的说话者、伊朗外交部长陷入了特别的争议。2020年,乌克兰总理因一段泄露的录音而提交了辞呈,这段录音表明他批评了总统。2018年,英国国防大臣在下议院声明时被语音助手打断,因为Siri一直在监听以寻找唤醒词,这可以被视为一种新型的窃听。语音隐私的严峻状况显示了反窃听技术的必要性。
然而,现有的解决方案远远不能满足需求,存在一些局限性:
- 简单形式的噪声: 许多解决方案使用简单形式的噪声,如白噪声和随机频率噪声,主要依靠高能量进行干扰。这会导致能耗高,且容易被降噪技术去除。
- 不支持授权录音: 大多数解决方案不支持授权录音,限制了其应用场景。
- 安全性问题: 一些解决方案使用电磁干扰 (EMI) 来干扰麦克风,但 EMI 可能会影响附近的设备,例如心脏起搏器,造成意外后果。
为了克服上述局限性,本文提出了一种高效且鲁棒的反窃听系统Infomasker,可以在干扰麦克风的同时保留授权录音。该系统利用信息掩蔽的思想,设计了一种基于音素的噪声,可以干扰机器和人类的理解,并且难以被降噪技术去除。此外,该系统还优化了噪声传输策略,并实现了硬件原型。
项目地址:https://github.com/desperado1999/InfoMasker
1 关键概念
1.1 麦克风中的非线性效应
麦克风是一种将声波信号转换为电信号的传感器。研究表明,大多数麦克风的预放大器都涉及非线性操作,这会导致输出信号出现互调失真。例如,当输入信号为两个单一频率的音调时,输出信号不仅包含这两个频率的成分,还包含它们的所有可能的线性组合,例如和频、差频等。这种非线性特性可以用来将可听信号隐藏在超声波中,从而实现对麦克风的无声干扰。
1.2 信息掩蔽
信息掩蔽是指当目标声音嵌入到具有相似特征的干扰声中时,人脑对声音的检测阈值下降的现象。与信息掩蔽相对应的是能量掩蔽,它发生在干扰声与目标声音同时存在于相同的频率范围内。能量掩蔽主要取决于干扰声与目标声音在每个频率带的相对能量,而信息掩蔽主要取决于干扰声与目标声音之间的相似性。两者通常共同影响听觉检测阈值。
1.3 人耳听觉系统和语音识别系统
人耳听觉系统和语音识别系统的主要任务都是从语音信号中提取语义信息。为了提高语音可懂度,两者都需要先去除信号中的噪声,然后提取音素序列,最后将音素序列解码成有意义的内容。
- 人耳听觉系统: 人耳听觉系统具有强大的噪声抑制能力,称为“鸡尾酒会效应”。它允许听众从其他声源中区分信号,并消除不感兴趣噪声的影响,从而实现降噪。噪声抑制的有效性主要取决于目标信号与噪声在基频、时间特性和空间分布方面的差异。
- 语音识别系统: 语音识别系统的工作原理与人类听觉系统类似。它首先从音频片段中提取语音特征,例如梅尔频率倒谱系数 (MFCC),然后使用声学模型识别音素序列。最后,借助发音模型和语言模型,将音素序列解码成普通文本。为了提高识别准确率,通常会在识别之前应用语音增强方法,例如降噪和噪声分离。
2 系统设计
2.1 设计目标
infoMasker的设计目标如下:
2.1.1 防窃听有效性
- 干扰语音识别系统 (ASR): 系统生成的噪声应能够有效干扰 ASR 系统对录音内容的理解,使其无法准确识别语音内容。
- 干扰人耳听觉: 系统生成的噪声应能够干扰人耳对语音内容的理解,使人无法清晰地听到录音内容。
- 支持多种 ASR 系统: 系统的噪声应能够有效地干扰不同类型的 ASR 系统,包括商业 ASR 系统和开源 ASR 系统。
- 支持多种语言: 系统的噪声应能够有效地干扰不同语言的语音内容,包括英语、普通话、葡萄牙语和日语等。
2.1.2 噪声鲁棒性
- 抵抗语音增强技术: 系统生成的噪声应能够抵抗各种语音增强技术,包括噪声抑制、语音分离和盲源分离等,使其无法被有效地消除。
- 抵抗特定攻击: 系统的噪声应能够抵抗针对该系统的特定攻击,例如攻击者知道噪声生成方法的细节并训练定制 ASR 系统或语音增强模型进行攻击。
2.1.3 低干扰性
- 不可听性: 系统生成的噪声应具有不可听性,不会对人类造成听觉上的干扰。
- 无害性: 系统生成的噪声应对人体无害,不会对人体健康造成任何负面影响。
2.1.4 控制录音权限
- 授权录音: 系统应支持授权用户对录音内容的恢复,使其能够清晰地听到录音内容。
- 安全恢复: 系统应能够安全地恢复录音内容,防止录音内容被未授权用户获取。
2.2 核心思想
本文的主要目标是通过传输噪声来干扰环境中的麦克风,使录音对于人类和自动语音识别(ASR)系统都难以识别。干扰ASR系统的成功主要依赖于噪声对语音增强方法的鲁棒性,而干扰人类听觉系统的成功则主要依赖于两种掩蔽效应:信息掩蔽和能量掩蔽。能量掩蔽的有效性主要取决于噪声相对于目标信号的能量,而对于后者,它主要取决于噪声的内容。现有工作专注于利用能量掩蔽,这导致对能量的高需求,并不适合于超声波传输场景。本文的关键洞见是利用信息掩蔽效应形成噪声。
- 语音信号的基本频率(F0)和语速对信息掩蔽的效果有显著影响。
- 为了最大限度地干扰语义理解,噪声应与目标语音信号具有相似的F0和语速。
2.3 系统模型
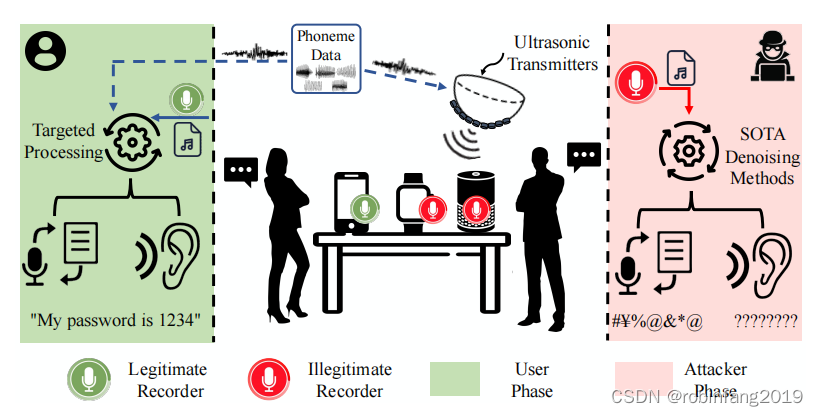
本文考虑的场景是用户在室内环境(如办公室或会议室)中进行对话。用户可能需要记录对话,同时希望防止可能的未知对手窃听。如下图所示,系统涉及四个实体:
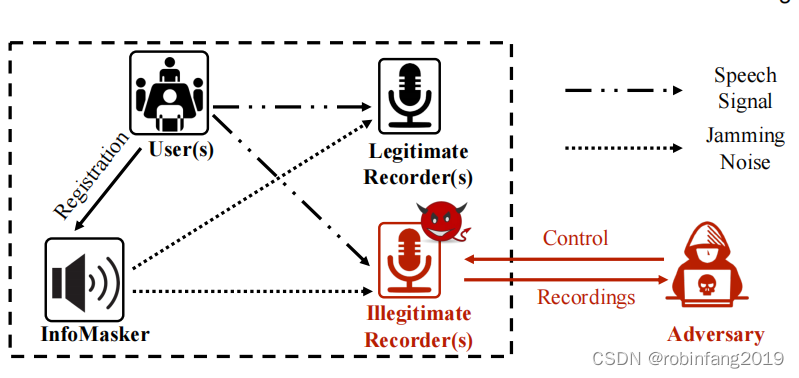
- 用户(User(s)):正在进行对话的人。为了保护他们的隐私,他们部署了InfoMasker来防止他们的声音被窃听。
- InfoMasker:一个用户控制的干扰设备,可以根据用户的注册信息生成并发射干扰噪声,以防止可能的窃听。请注意,我们不涵盖语音通话场景,因为环境中的所有麦克风都会被干扰。
- 合法录音设备(Legitimate Recorder(s)):用户放置的设备,用于记录正在进行的对话。由于InfoMasker的存在,录制的音频也将受到影响,并将包含对话和干扰噪声。对话结束后,用户将尝试从嘈杂的录音中恢复内容。
- 非法录音设备(Illegitimate Recorder(s)):指环境中所有其他配备麦克风的设备,如智能手机和智能手表。由于大多数电子产品的"黑箱"特性,它们不受用户完全控制,可能会秘密窃听用户。用户不太可能将它们放置在视线之外的区域,因此不考虑非视距场景。
2.4 威胁模型
我们考虑的对手可以控制环境中的录音设备(例如,智能家居设备的制造商)。为了窃听对话内容,对手将记录语音信号,使用各种方法提高录音的可懂度,然后提取语义信息。在这项工作中,我们假设对手在每个窃听步骤中具有以下能力:
- 音频录制(Audio Recording):假设对手可以控制环境中的一个或多个录音设备,以记录单声道或多声道音频信号。
- 语音增强(Speech Enhancement):假设对手可以使用不同的语音增强方法提高录制语音信号的可懂度,包括降噪、语音分离和盲信号分离(BSS)。
- 语义信息提取(Semantic Information Extraction):对手可以联合使用不同的ASR以及人耳从增强后的录音中提取语义信息,人类可以准确识别录音,而ASR可以高效地解释语音内容。我们还考虑了一个强大的对手,他了解我们噪声生成方法的细节,并且可以针对我们的噪声训练定制的ASR系统。
2.5 噪声设计
本文基于音素的噪声由三个音素序列组成:S1、S2和S3,如下图所示:
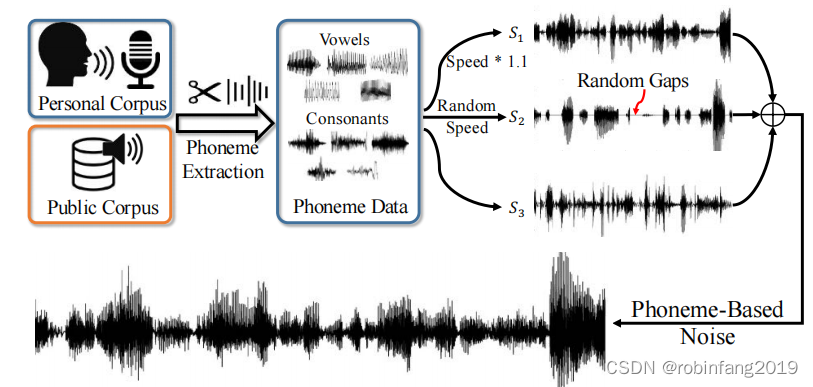
- S1:随机元音序列,加速播放以包含更多元音,并从目标用户的语音数据中提取,以最小化与目标语音的F0差异。
- S2:具有随机语速的元音序列,通过随机选择速度因子来模拟不同的语速,并使噪声更具多样性。
- S3:从公开语音语料库中提取的辅音序列,用于增加噪声的多样性。
- 三个音素序列叠加形成最终的干扰噪声。
2.6 系统工作流程
InfoMasker的系统工作流程包括三个主要阶段:用户注册、实时反监听干扰、内容恢复,如下图所示:
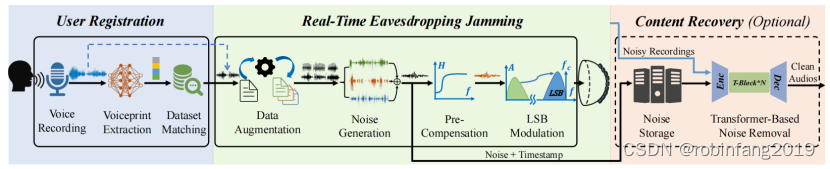
2.6.1 用户注册
InfoMasker 从用户那里收集语音材料并提取他们的语音特征。根据用户数量和时间可用性,采用不同的方法生成足够的音素数据。
2.6.1.1 单用户注册
- 如果用户时间充足,可以录制足够长的语音数据(使用哈佛句子数据集)来生成音素数据。
- 如果用户时间有限,可以录制少量语音数据(约5秒)用于提取语音特征,并从数据集中选择与用户语音特征最相似的语音数据来生成音素数据。
2.6.1.2 多用户注册
- 所有用户录制语音数据,提取语音特征,并计算平均语音特征。
- 根据平均语音特征从数据集中选择最匹配的语音数据来生成音素数据。
2.6.2 实时反监听干扰
InfoMasker 连续生成、补偿、调制并传输干扰噪声,以干扰环境中的麦克风。干扰噪声根据用户注册信息生成,并具有以下特点:
- 数据增强:对音素数据进行数据增强,以增加数据量并防止出现重复片段。
- 噪声生成:根据增强后的音素数据生成干扰噪声。
- 预补偿:对噪声信号进行预补偿,以补偿超声波发射器的频率响应不均匀性。
- 低边带噪声调制:将噪声信号调制到超声波载波上,并通过超声波发射器发射。
2.6.3 内容恢复(可选)
- 网络架构:基于Transformer的降噪网络,包括编码器、掩蔽网络和解码器。
- 训练过程:使用包含干扰噪声和原始语音信号的数据集训练网络,并引入随机时移和随机信道脉冲响应来提高网络的鲁棒性。
- 噪声去除:将干扰噪声和录音输入网络,网络生成掩蔽信号,用于去除录音中的噪声,并恢复原始内容。
2.7 硬件设计
2.7.1 发射器特性分析
现有的超声波发射器具有以下特性:
- 超声波能量随角度迅速衰减,导致有效干扰范围有限。
- 增加发射器数量可以扩展有效干扰距离。
- 载波信号和调制噪声信号的能量衰减特性不同。
2.7.2 发射器阵列设计
为了扩展有效干扰范围,InfoMasker设计了发射器阵列,将多个超声波发射器以六边形形状安装在球形泡沫上。

- 发射器分为两组:一组发送载波信号;另一组发送调制后的噪声信号。
- 球形泡沫的曲率和发射器的分布使得发射器阵列能够覆盖更大的角度和更远的距离。
2.7.3 硬件实现
InfoMasker的硬件实现包括以下组件:一个发射器阵列、两个功率放大器(每组发射器一个)、一个信号发生器(这里使用笔记本电脑,但它可以被其他具有≥80kHz采样率的声卡的开发板替代)。内容恢复在后端服务器上实现(本文中使用的是Intel(R) Xeon(R) Gold 6226R CPU和Nvidia RTX3090 GPU)。如果不包括笔记本电脑和后端服务器,硬件实现的成本约为70美元。

- 发射器阵列:包含多个超声波发射器。
- 功率放大器:两个功率放大器,分别用于两组发射器。
- 信号发生器:用于生成载波信号和调制噪声信号,可以使用笔记本电脑或其他具有音频接口的开发板。
- 内容恢复部分在后台服务器上实现,使用高性能的CPU和GPU。
2.7.4 硬件优势
- 覆盖范围广:发射器阵列可以覆盖更大的角度和更远的距离,有效干扰范围内的麦克风。
- 成本低:硬件实现成本低,易于部署。
- 可扩展性:可以根据需要增加发射器数量,进一步扩展覆盖范围。
3 评估
3.1 实验设置
3.1.1 评估方法
- 有效性评估:使用不同的语音识别系统测试系统在不同信噪比和不同场景下的干扰效果。
- 鲁棒性评估:测试系统对各种语音增强技术的鲁棒性,包括SOTA降噪算法和定制语音识别系统。
- 变量测试:测试系统在不同变量下的表现,例如数据增强概率、录音设备等。
- 案例研究:在真实办公环境中进行测试,验证系统的实际应用效果。
3.1.2 评估数据集
3.1.2.1 LibriSpeech
- 用于基线和其他未提及的部分。
- 包含大量英语语音数据,用于评估系统在不同 ASR 系统和噪声条件下的性能。
- 包含不同说话者的语音数据,用于测试多用户场景下的效果。
3.1.2.2 AISHELL-1
- 用于测试中文语音数据,评估系统在不同语言下的性能。
- 包含大量中文语音数据,用于测试系统在中文语音识别场景下的效果。
3.1.2.3 Multilingual LibriSpeech
- 用于测试葡萄牙语语音数据,评估系统在不同语言下的性能。
- 包含大量葡萄牙语语音数据,用于测试系统在葡萄牙语语音识别场景下的效果。
3.1.2.4 Japanese Versatile Speech
- 用于测试日语语音数据,评估系统在不同语言下的性能。
- 包含大量日语语音数据,用于测试系统在日语语音识别场景下的效果。
3.1.2.5 TIMIT
- 用于测试语音增强网络的效果,评估系统在不同噪声条件下的恢复能力。
- 数据集规模较小,便于机器学习模型快速收敛。
3.1.2.6 Harvard Sentences
- 用于测试人类对噪声语音的可懂度,评估系统在人类听觉系统下的效果。
- 包含短句语音数据,降低人类识别难度。
3.1.3 数据集预处理
在进行噪声生成之前,需要对语音数据进行以下预处理:
3.1.3.1 分词
将语音数据分割成音素,以便进行后续处理。
- 英语数据使用 Prosodylab Aligner 进行分词。
- 中文数据使用 Charsiu 进行分词。
- 葡萄牙语和日语数据使用 Montreal Forced Aligner 进行分词。
- TIMIT 数据集已经提供了音素分割信息。
3.1.3.2 音素分类
根据国际音标 (IPA) 将音素分为元音和辅音两类,以便进行后续处理。
3.2 评估结果

我们的噪声在SNR ≤ 4时的性能明显优于白噪声,随着SNR的降低,两者之间的差距逐渐增大。此外,我们噪声的优势在商业ASR上比在开源ASR上更为明显。我们推测这是因为商业系统已经针对白噪声的干扰进行了增强。
3.2.1 有效性
- 系统可以显著降低SOTA语音识别系统的识别准确率,即使在信噪比为0的情况下,识别准确率也可以降低到50%以下。
- 系统在不同的语言、多用户场景和真实场景下均表现出良好的干扰效果。
- 系统产生的噪声对人耳不可见且无害。
3.2.2 鲁棒性
系统可以抵抗SOTA语音增强技术,包括SOTA降噪算法和定制语音识别系统。
3.2.3 变量测试
- 数据增强概率对干扰效果的影响有限。
- 系统在不同录音设备下均表现出良好的鲁棒性。
3.2.4 与其他方法的比较
- 与基于能量的掩蔽方法和基于语音的噪声相比,InfoMasker具有更高的干扰效果和鲁棒性。
- 与Backdoor和Patronus等方法相比,InfoMasker具有更高的干扰效果和更低的能量要求。
4 实际案例
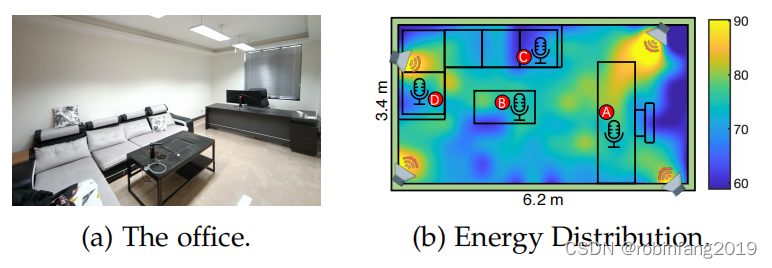
4.1 环境设置
- 场景: 一个常见的办公室,长 6.2 米,宽 3.4 米。
- 设备部署: 在房间四个角落各放置一个发射器阵列,用于发射超声波噪声。
- 能量分布: 使用专业设备测量房间内超声波能量分布,结果显示除距离发射器阵列 10 厘米以内的区域外,其他区域的能量均低于 95 dB SPL,符合 WHO 的建议标准。
4.2 测试设备
- 录音设备: 在房间内放置四台设备作为录音设备,包括两台智能手机(Samsung A51 和 Huawei Mate30Pro)、一台笔记本电脑(Lenovo IdeaPad7)和一台 iPad(iPad8)。
- 位置: 两台智能手机放置在噪声能量相对较高的 A 点和 B 点,笔记本电脑和 iPad 放置在噪声能量相对较低的 C 点和 D 点。
4.3 测试内容
- 识别结果: 使用三款商用 ASR 系统对四台设备的录音进行识别,并选择最低的 WER 作为结果。
- 无噪声情况: 测试功率放大器开启但未发射噪声的情况,以验证噪声对识别结果的影响。
- 盲信号分离: 使用华为 Mate30Pro 的双声道录音进行盲信号分离测试,评估 BSS 算法对噪声的影响。
4.4 结果分析
- 识别结果: 在噪声能量较高的 A 点和 B 点,四台设备的识别准确率均低于 20%,表明 InfoMasker 能够有效干扰 ASR 系统的识别。
- 无噪声情况: 在无噪声情况下,四台设备的识别准确率均超过 90%,验证了噪声对识别结果的影响。
- 盲信号分离: 即使在噪声能量最低的 C 点,BSS 算法(AuxIVA 、ConsistentILRMA 、FastMNMF 、LaplaceFDICA 和 t-ILRMA )也无法有效提高识别准确率,表明 InfoMasker 能够抵抗 BSS 算法的攻击。
4.5 结论
- InfoMasker 在实际办公室环境中能够有效干扰 ASR 系统的识别,并能够抵抗 BSS 算法的攻击。
- InfoMasker 的噪声能量分布符合 WHO 的建议标准,对人体无害。
- InfoMasker 能够在保护用户隐私的同时,允许授权用户进行录音。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)