【机器学习】食物图像分类(CNN)
本文基于李宏毅老师的机器学习课程,在Kaggle平台上构建CNN模型完成食物图像分类
本文基于李宏毅老师的机器学习课程,在Kaggle平台上构建CNN模型完成食物图像分类
1 实验目的
学会并熟练pytorch的安装以及环境搭建,使用pytorch处理数据,实现梯度的计算和神经网络的搭建,并训练模型。通过实验对CNN结构进一步了解,将CNN用于食物图像识别的训练。
2 实验环境
Kaggle
Accelerator GPU T4x2
python
3 实验原理
CNN是用于图像识别的神经网络,使用特殊的卷积操作,将图像分区识别,减少输入参数,比直接的全连接更符合图像的特点,同时还可以加快学习的过程。其实是相当于人类提前帮助机器对图像进行分类学习。
CNN基于图像的三个特点:
- Some patterns are much smaller than the whole image.
- The same patterns appear in different regions.
- Subsampling the pixels will not change the object.
因此CNN的基本架构为:input -> Convolution Layer -> Pooling Layer -> Convolution Layer -> Pooling Layer -> ...-> Flatten -> Fully Connected network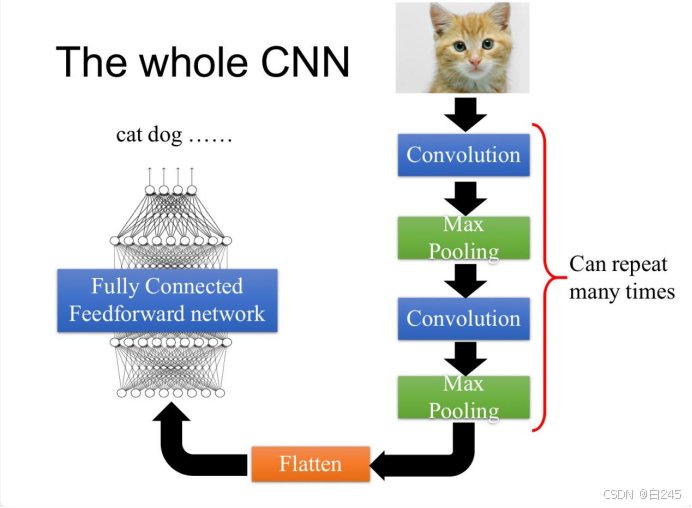
picture1.CNN construction(图片来源李宏毅老师)
3.2 Kaggle平台
因为直接在自己的电脑的CPU上跑整个训练+预测过程会很慢,并且如果没有GPU的话,也没办法直接使用GPU的加速方法。所以,整个实验可以选择在Kaggle网站上完成.

picture2.kaggle
对于中国用户,使用邮箱注册更加方便,QQ邮箱就可以直接完成注册。如果想使用GPU的加速服务,需要验证一下手机号,同样的,中国手机号也可以完成验证。之后只需要在自己的code的setting上找到Accelerator,选中GPU就可以了.
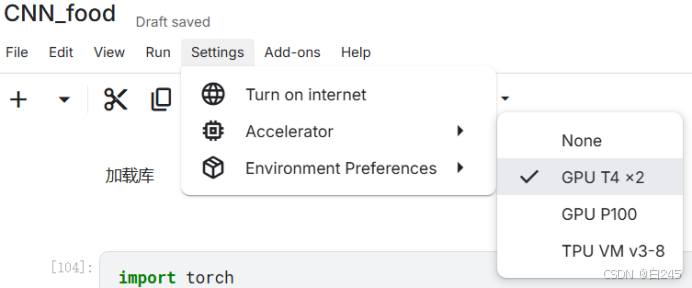
Picture3.setting for code
4 实验过程
加载库
import torch
import torch.nn.functional as F
import os
import cv2
import numpy as np
from torch.utils.data import Dataset, DataLoader
from PIL import Image
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import torch.optim as optim
from tqdm.notebook import tqdm
from torch.utils.data import ConcatDataset
import time读取数据的函数,用于读取数据标签和图像
def readfile(path, label):
# label 是一个bool值,代表是否需要返回便签(因为读取测试集的时候是没有标签的)
image_dir = sorted(os.listdir(path))
# 设置图像大小是256*256*3的大小
x = np.zeros((len(image_dir), 256, 256, 3), dtype=np.uint8)
y = np.zeros((len(image_dir)), dtype=np.uint8)
# 逐个读取
for i, file in enumerate(image_dir):
img = cv2.imread(os.path.join(path, file))
x[i, :, :] = cv2.resize(img,(256, 256))
if label:
# y就是label
y[i] = int(file.split("_")[0])
if label:
return x, y
else:
return x
调用加载数据函数
# 读取数据的总目录
workspace_dir = '/kaggle/input/food11/food11'
print("读取数据中")
# 用readfile函数完成数据的分类和读取
train_x, train_y = readfile(os.path.join(workspace_dir, "training"), True)
print("训练集的大小为 = {}".format(len(train_x)))
val_x, val_y = readfile(os.path.join(workspace_dir, "validation"), True)
print("验证集的大小为 = {}".format(len(val_x)))
# 最终的预测集没有label(这是我们最终需要的目标),索引直接给False
test_x = readfile(os.path.join(workspace_dir, "test"), False)
print("需要预测集的大小为 = {}".format(len(test_x)))
因为之前直接训练的效果太差,用一下数据加强的功能试试
train_transforms = transforms.Compose(
[
# 转换为PIL图像
transforms.ToPILImage(),
# 调整图像大小
transforms.Resize((256, 256)),
# 随机将图片水平翻转
transforms.RandomHorizontalFlip(),
# 随机将图片竖直翻转
transforms.RandomVerticalFlip(),
# 随机旋转图片
transforms.RandomRotation(15),
# 转换成tensor
transforms.ToTensor(),
# 将图片归一化
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5)),
])
test_transforms = transforms.Compose(
[
# 转换为PIL图像
transforms.ToPILImage(),
# 调整图像大小
transforms.Resize((256, 256)),
# 转换成tensor
transforms.ToTensor(),
# 将图片归一化
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5)),
])编写载入food图像的类
其中包含了:
1.初始化函数:定义数据转换模式 添加文件路径(相当于input) 保存图像文件的文件名称(用于后续识别标签label,也就是output)
2.返回数据集长度函数:嗯就是返回长度
3.返回索引下图像的相关数据,有两者情况:1.有label(类别),则返回索引的图像和类别 2.无label(类别),则直接返回索引的图像本身
class dataset_food(Dataset):
def __init__(self, x, y=None, transforms = None):
# 定义数据转换的模式
self.transform = transforms
# 定义x,
self.x = x
# 定义y(其实就是label)
self.y = y
if y is not None:
self.y = torch.LongTensor(y)
# 返回数据集长度
def __len__(self):
return len(self.x)
# 根据索引返回图像以及类别
def __getitem__(self, idx):
X = self.x[idx]
if self.transform is not None:
# 有数据转换要求则进行转换
X = self.transform(X)
if self.y is not None:
# 如果label不为空,则返回
Y = self.y[idx]
return X,Y
else:
return X在主函数中看看能不能正常加载我们的数据集,顺便设定一下类别的文字标签以便后续查看
# 设定类别
class_ = ('Bread', 'Dairy product', 'Dessert', 'Egg', 'Fried food', 'Meat', 'Noodles/Pasta', 'Rice', 'Seafood', 'Soup', 'Vegetable/Fruit')
# 一次迭代中使用的数据样本数量
my_batch_size = 128
# 加载数据集
print("开始加载训练数据集")
train_data = dataset_food(train_x, train_y, transforms = train_transforms)
train_set = DataLoader(train_data, batch_size = my_batch_size, shuffle=True)
validation_data = dataset_food(val_x, val_y, transforms = test_transforms)
validation_set = DataLoader(validation_data, batch_size = my_batch_size, shuffle=True)
test_data = dataset_food(x = test_x, transforms = test_transforms)
test_set = DataLoader(test_data, batch_size = my_batch_size, shuffle=True)
print("加载结束")
接下来进行CNN的基本设置
要做自己模型的设置,其实就是设定要经过几个卷积层,每个卷积层有几个输入,几个输出,卷积核的大小,步长的大小;池化层选择最大池化还是平均池化还是最小池化;激活函数选择哪一种(一般选的是ReLU);全连接层的连接方式
根据查到的资料,一般说是使用3->16->32->64->128这样的递增输入会让图像识别准确度比较高.而且一般来说,层数越深,训练效果越好,所以可以多设置几层.
# 设置CNN
class CNN_food(nn.Module):
def __init__(self):
# 调用父类的初始化方法,确保基础模块nn.Module正确初始化
super().__init__()
# 定义中间的隐藏层
# 组合多个层
self.conv1 = nn.Sequential(
# 图像是2d形式
nn.Conv2d(
# 图像通道个数,在第一层就是3(对于RGB)
in_channels = 3,
# 要得到多少个特征图
out_channels = 16,
# 卷积核大小, 3*3
kernel_size = 3,
# 步长
stride=1,
padding=1,
),
# 保证输出为16大小
nn.BatchNorm2d(16),
# 使用激活函数ReLU
nn.ReLU(),
# 用2*2的最大池化层
nn.MaxPool2d(kernel_size = 2),
)
self.conv2 = nn.Sequential(
nn.Conv2d(16, 32, 3, 1, 1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2),
)
self.conv3 = nn.Sequential(
nn.Conv2d(32, 64, 3, 1, 1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2),
)
self.conv4 = nn.Sequential(
nn.Conv2d(64, 128, 3, 1, 1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2),
)
self.conv5 = nn.Sequential(
nn.Conv2d(128, 128, 3, 1, 1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2),
)
self.conv6 = nn.Sequential(
nn.Conv2d(128, 256, 3, 1, 1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2),
)
self.conv7 = nn.Sequential(
nn.Conv2d(256, 512, 3, 1, 1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2),
)
self.conv8 = nn.Sequential(
nn.Conv2d(512, 512, 3, 1, 1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2),
)
# 全连接层
self.fc = nn.Sequential(
# 输入512*1*1,输出512*1
nn.Linear(512*1*1, 512),
nn.ReLU(),
# 输入512*1,输出256*1
nn.Linear(512, 256),
nn.ReLU(),
# 输入256*1,输出128*1
nn.Linear(256, 128),
nn.ReLU(),
# 输入128*1,输出11*1,即11种食物种类
nn.Linear(128, 11)
)
# 向前传递,定义了数据如何通过CNN得到输出
def forward(self, x):
# 经过8个卷积层
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = self.conv6(x)
x = self.conv7(x)
x = self.conv8(x)
# 张开成为n*1的向量
x = x.view(x.size(0), -1)
# 进入全连接层
x = self.fc(x)
return x因为直接在CPU上跑会太慢,所以采用GPU加速训练过程,下面是测试是否能够使用GPU加速的方式
在Kaggle中可以使用它的云GPU,不过要先验证手机号,之后在notebook的Settings中选择Acclerator中的GPU即可
# 检查CUDA是否可用,并选择对应的设备
if torch.cuda.is_available():
device = torch.device("cuda")
print("Using GPU:", torch.cuda.get_device_name(0))
else:
device = torch.device("cpu")
print("Using CPU")
# 解决内存溢出的问题
CUDA_VISIBLE_DEVICES = 1
把我们设置好的CNN模型移动到GPU上,并进行一些参数初始化设置,设置Loss函数的计算方式(CrossEntropy),参数更新的方式(Adam),以及总训练轮数
# 加载设置的CNN
my_food_CNN = CNN_food().to(device)
# 使用CrossEntropy计算Loss函数
criterion = nn.CrossEntropyLoss()
# 用Adam方法计算梯度下降
optimizer = torch.optim.Adam(my_food_CNN.parameters(), lr=0.001)
# 总训练轮数,每一轮训练都会遍历整个数据集
epochs = 30可以打印模型结果看看,直接print模型就可以
print(my_food_CNN)


为了方便后面调用,还是把训练过程放入一个函数里
#只训练
def my_train(dataset, model, criterion, optimizer, epochs):
# 每一次迭代
for epoch in range(epochs):
# 记录每次迭代开始的时间 准确度 损失函数
epoch_start_time = time.time()
train_acc = 0.0
train_loss = 0.0
# 保证是在训练模式下进行的
model.train()
# 对于每一组data
for i, data in enumerate(dataset):
# 每次开始前都要将梯度参数归零
optimizer.zero_grad()
# 预测训练值
train_pred = model(data[0].cuda())
# 用预测结果跟实际结果计算损失
batch_loss = criterion(train_pred, data[1].cuda())
# 向后传播,计算每个参数的梯度
batch_loss.backward()
# 更新参数值
optimizer.step()
# 计算训练的准确值和损失函数
train_acc += np.sum(np.argmax(train_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
train_loss += batch_loss.item()
# 将结果打印出来
print('[%03d/%03d] %2.2f sec(s) Train Acc: %3.6f Loss: %3.6f' % \
(epoch + 1, epochs, time.time()-epoch_start_time, \
train_acc/dataset.__len__(), train_loss/dataset.__len__()))
print("训练结束")再写一个测试函数看看模型在验证集(validation)上的表现
# 只测试
def my_test(dataset, model, criterion):
# 确保模型不会更新参数
model.eval()
# 数据集大小
total_samples = 0
# 数据批次
num_batches = len(dataset)
# 初始化总loss 和 正确数
total_loss, correct = 0, 0
with torch.no_grad():
for x_inputs, labels in tqdm(dataset, desc="测试过程", unit='batch'):
# 将数据移动到GPU上
x_inputs, labels = x_inputs.to(device), labels.to(device)
# 向前传播得到预测值
pred = model(x_inputs)
# 计算测试集损失
total_loss += criterion(pred, labels)
# 计算预测的标签
_, predicted = torch.max(pred, 1)
# 计算正确数量
correct += (predicted == labels).sum().item()
# 增加数据集数量
total_samples += labels.size(0)
# 计算平均loss
total_loss /= num_batches
# 计算模型准确度
correct /= total_samples
print(f"测试结果: 准确度:{(100*correct):.2f}%, 平均Loss:{total_loss:.4f}")为了方便及时调整设置,将训练和测试函数合并到一个函数里,便于找到效果最好的模型
def train_test(train_dataset, test_dataset, model, criterion, optimizer, epochs):
total_steps = epochs * len(train_dataset)
# 创建一个总进度条
with tqdm(total=total_steps, desc="训练+测试进度", unit='step') as pbar:
# 开始训练网络
for epoch in range(epochs):
# 训练
# 初始化运行损失
running_loss = 0.0
# 将模型切换到训练模式
model.train()
# 遍历数据集
for i, data in enumerate(train_dataset, 0):
# 得到输入,加载好的数据以[x_input, labels]的形式存在
x_inputs, labels = data
# 把数据迁移到设备中
x_inputs = x_inputs.to(device)
labels = labels.to(device)
# 每次反向传播之前,都需要清空之前的梯度
optimizer.zero_grad()
# 向前传递 + 反向传播 + 更新参数
outputs = model(x_inputs)
# 比较输出和标签,得到损失函数值
loss = criterion(outputs, labels)
# 使用向后传播的方法计算参数的梯度
loss.backward()
# 根据梯度更新参数
optimizer.step()
# 统计损失
running_loss += loss.item()
# 更新进度条
pbar.set_postfix(epoch=epoch+1, loss=running_loss/(i+1))
pbar.update(1)
print("第",epoch + 1," epoch的训练集平均损失为 ",loss.item())
# 测试
# 确保模型不会更新参数
model.eval()
# 数据集大小
total_samples = 0
# 数据批次
num_batches = len(test_dataset)
# 初始化总loss 和 正确数
total_loss, correct = 0, 0
with torch.no_grad():
for i, data in enumerate(test_dataset, 0):
# 得到输入,加载好的数据以[x_input, labels]的形式存在
x_inputs, labels = data
# 将数据移动到GPU上
x_inputs, labels = x_inputs.to(device), labels.to(device)
# 向前传播得到预测值
pred = model(x_inputs)
# 计算测试集损失
total_loss += criterion(pred, labels)
# 计算预测的标签
_, predicted = torch.max(pred, 1)
# 计算正确数量
correct += (predicted == labels).sum().item()
# 增加数据集数量
total_samples += labels.size(0)
# 计算平均loss
total_loss /= num_batches
# 计算模型准确度
correct /= total_samples
print(f"第{epoch+1}epoch的测试结果: 准确度:{(100*correct):.2f}%, 平均Loss:{total_loss:.4f}")
print("训练+测试结束")直接调用
train_test(train_set, validation_set, my_food_CNN, criterion, optimizer, epochs)得到结果
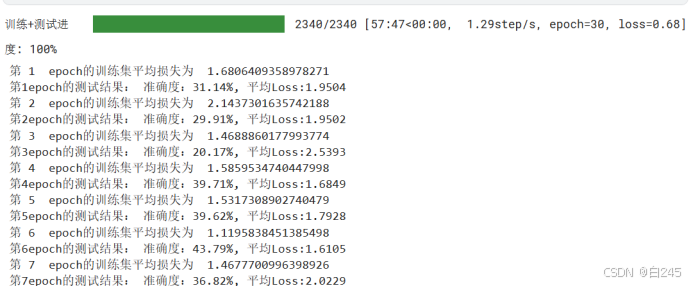


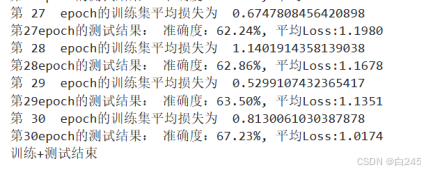
查看结果发现是第30 epoch的时候准确度最高,所以就选择epoch = 30
扩大训练集(把用来检验的数据集也放进去)再得到一组参数
# 根据训练+测试结果选择epoch = 30
epochs = 30
# 合并训练集和测试集
train_val_x = np.concatenate((train_x, val_x), axis=0)
train_val_y = np.concatenate((train_y, val_y), axis=0)
# 放入dataset中
train_val_set = dataset_food(train_val_x, train_val_y, train_transforms)
# 进行DataLoader,其中布尔类型参数shuffle决定是否打乱数据,训练集需要,所以为True
train_val_dataloader = DataLoader(train_val_set, batch_size=my_batch_size, shuffle=True)
# 重新训练得到一组参数
my_train(train_val_dataloader, my_food_CNN, criterion, optimizer, epochs)
# 保存模型
torch.save(my_food_CNN.state_dict(), 'model.pth')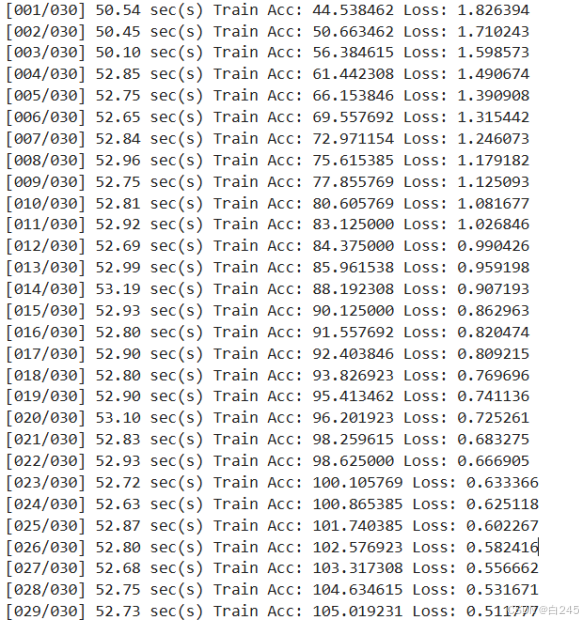
进行预测,得到预测结果
# 创建模型的实例
#model = CNN_food().to(device)
# 加载模型的状态字典
#model.load_state_dict(torch.load('model.pth'))
# 进行预测,将模型放在预测模式避免更新参数
my_food_CNN.eval()
# 保存预测结果
prediction = []
# 不进行梯度下降更新参数
with torch.no_grad():
# 遍历测试集的数据
for i, data in enumerate(test_set):
# 得到预测值
test_pred = my_food_CNN(data.cuda())
test_label = np.argmax(test_pred.cpu().data.numpy(), axis=1)#哪个类别概率最大,就识别哪个类别
for y in test_label:
prediction.append(y)
#将结果按照要求的格式写入csv
with open("predict.csv", 'w') as f:
f.write('Id,Category\n')
for i, y in enumerate(prediction):
f.write('{},{}\n'.format(i, y))
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)