卷积神经网络——学习笔记
通过上述的一系列公式,已经可以判断神经网络与理想模型的偏差,并对其进行量化了,但要对模型进行调整,就要借助梯度下降法了。
目录
从卷积到图像卷积操作再到卷积神经网络
感知机(神经元)
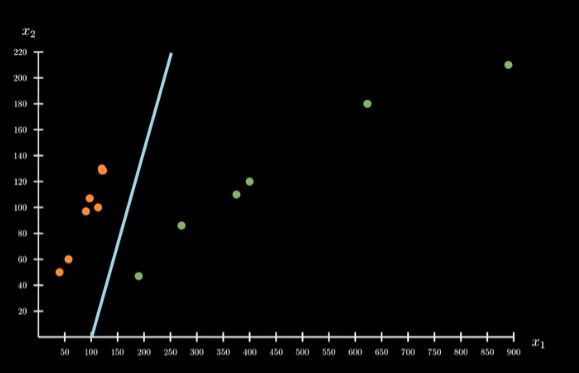
观察上述两张图片,感知机处理的是二分问题,二维上可以看作一条线,三维上可以看作一个面,将元素分成两部分。
数学公式:
线性函数:输入数据通过w(权重),b(偏置)两个变量的计算给出结果。
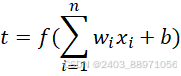
激活函数:决定最后输出的是哪一类(感知机解决二分问题),输出+1或-1
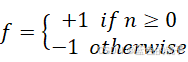
图像: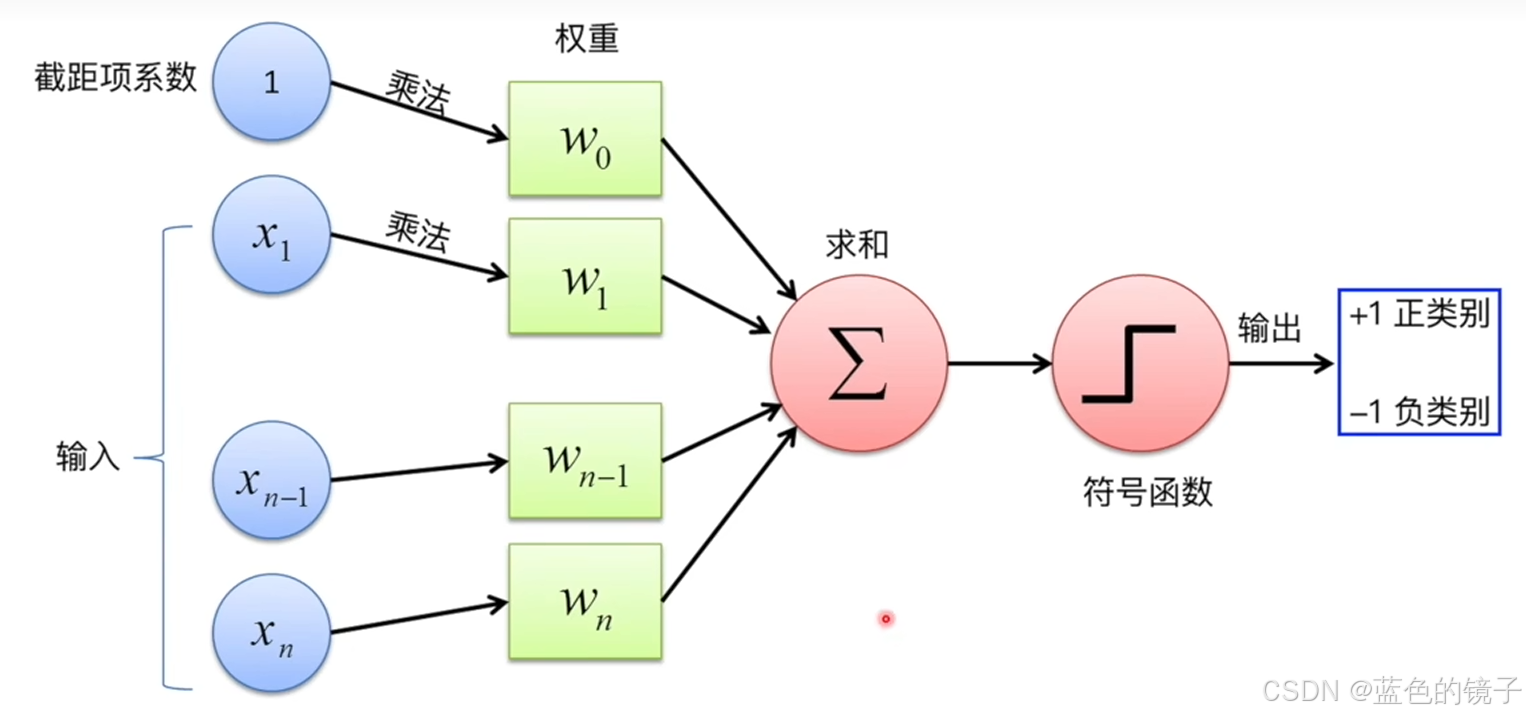
单一感知机只能处理与或非的问题,但通过多个感知机的叠加就可以实现异或的问题。神经网络通过感知机的结合去解决复杂问题。
神经网络是什么?
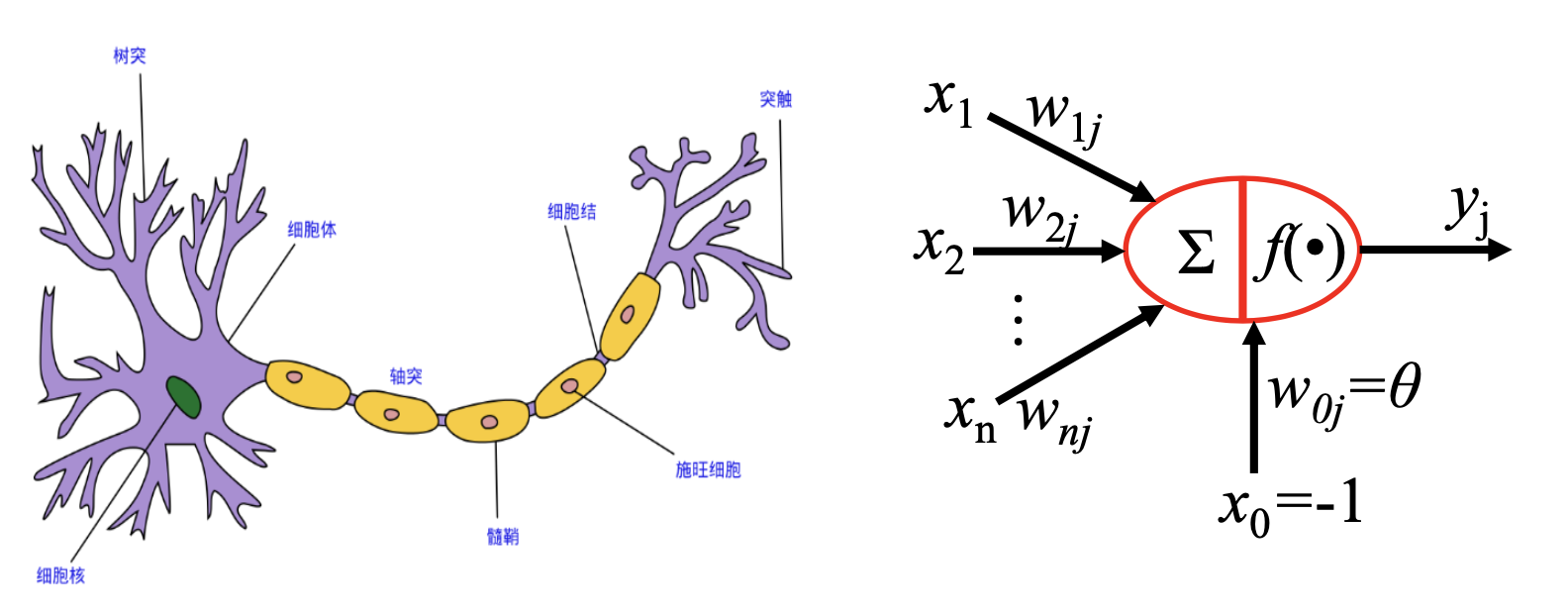
神经网络可以看作通过计算机为工具,利用数学的方式对人的神经的拙劣的模仿。
原理:
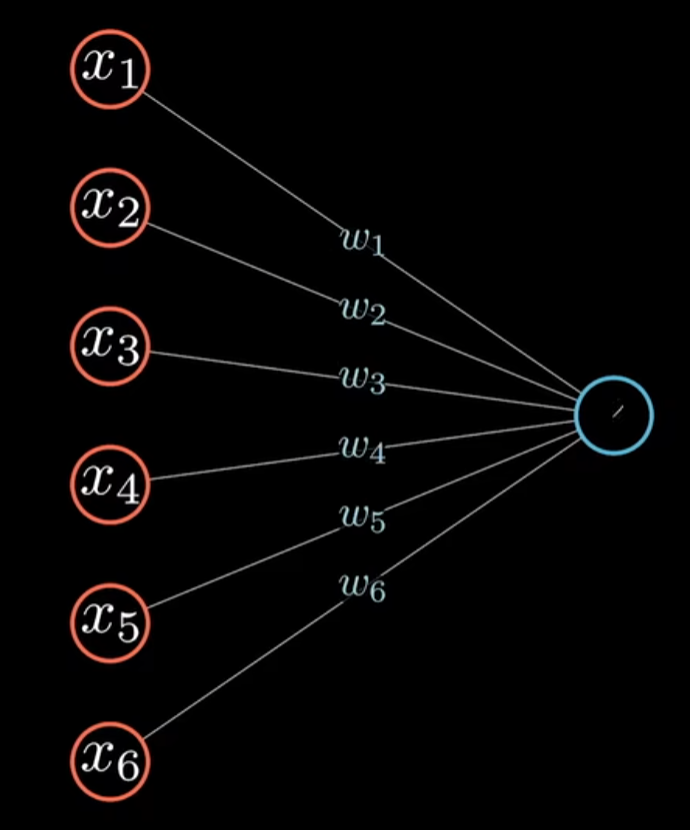
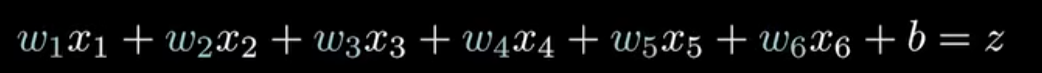
神经网络可以简单地看作是构建一个复杂函数,它的作用是接受输入的数据,通过这个函数进行计算然后输出我们想要的结果。
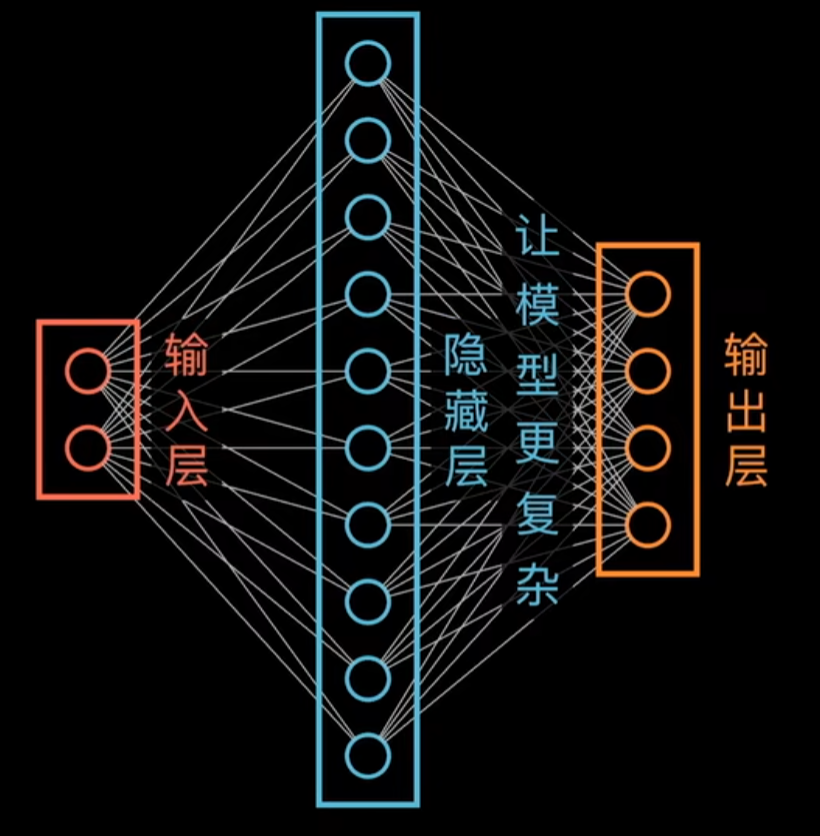
我们可以发现神经网络的神经元越多,层数越多,就越能构建更加高维更加复杂的函数。
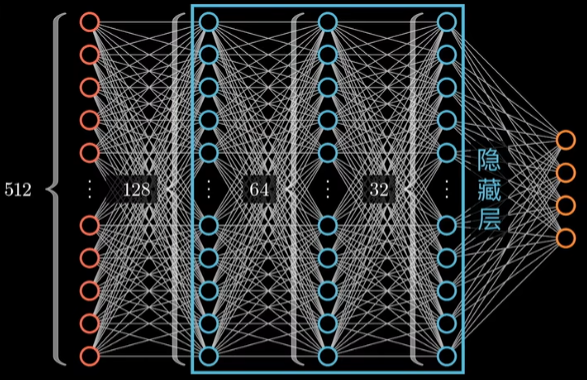
所能分割和识别任务也更加复杂:
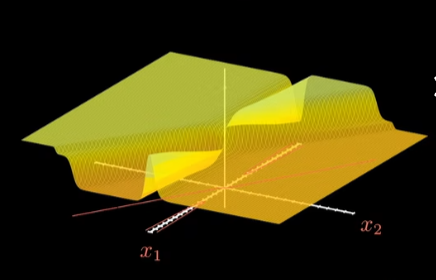
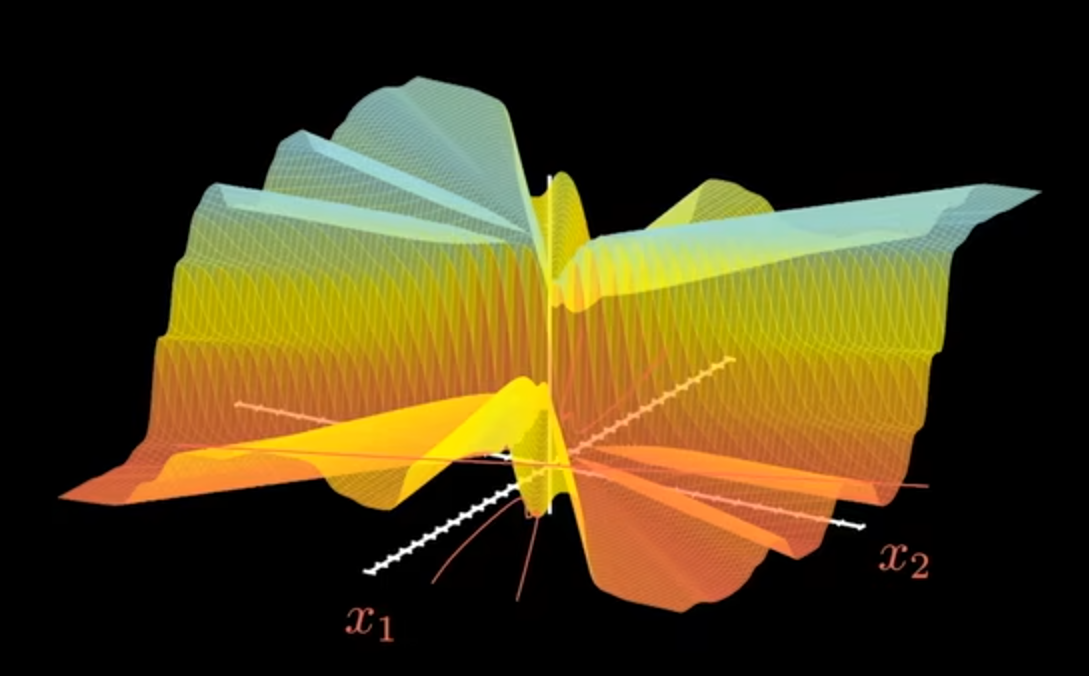
图像应用示例
实际运用到图像问题中可能更加复杂
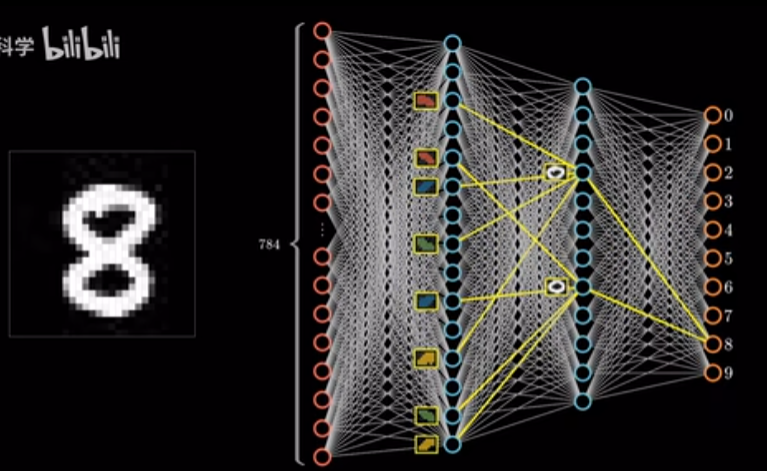
下面是一个经典识别数字的应用示例。
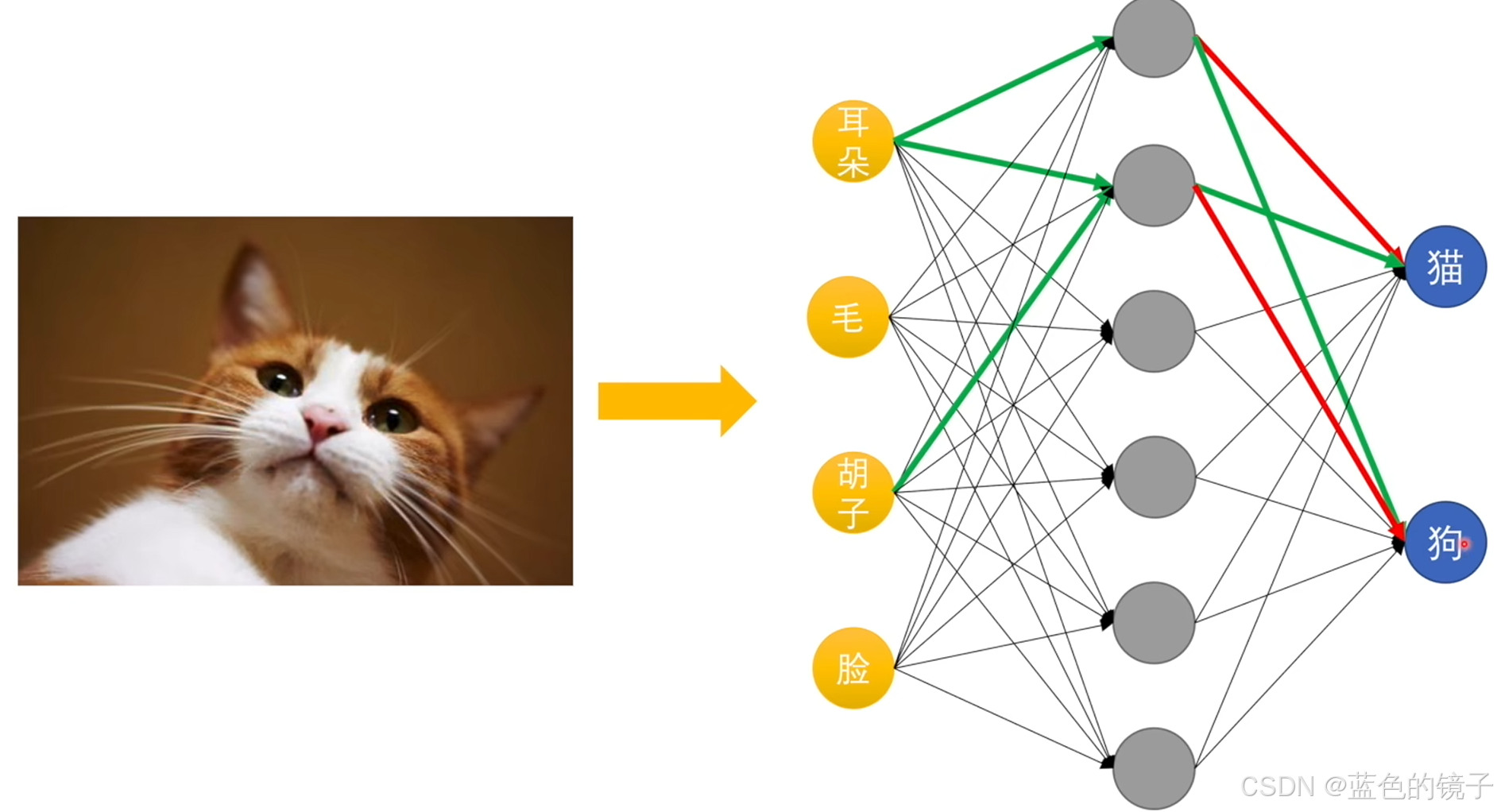
上述图片中展示的就是神经网络工作原理示意,输入层输入一些信息,如耳朵,通过神经网络判断其所属类别(猫或狗),许多特征经过隐藏层(一个个神经元)的判断综合后就可以判断出最终结果。
卷积的数学含义:
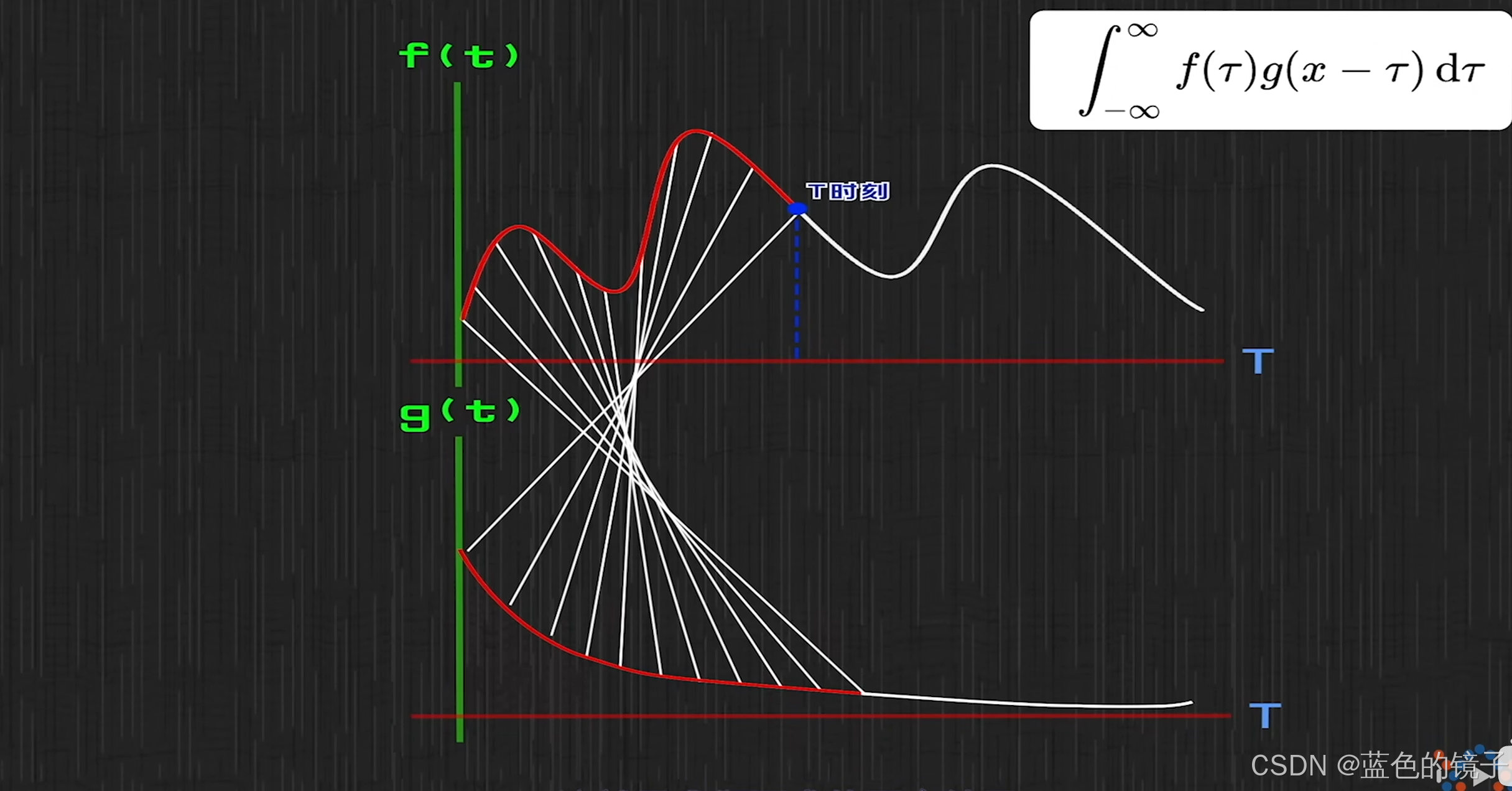
卷积数学公式:
数学上的卷积就是在一个系统输入不稳定,输出稳定的情况下,求系统的存量。
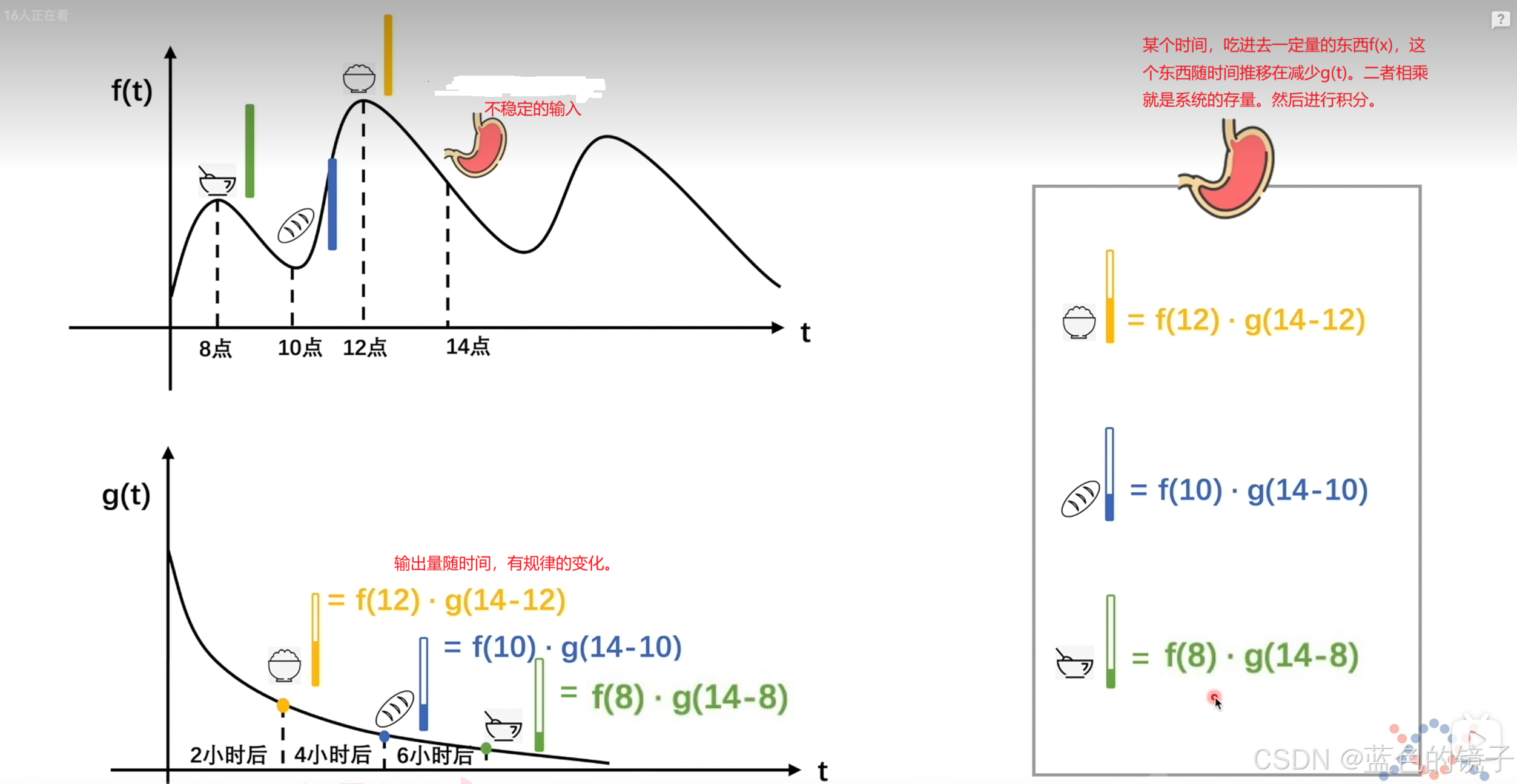
上述为卷积的类比生活中的例子的通俗解释。
数学上的卷积可以抽象的理解为t时刻之前的一切要素对t时刻影响的总和。其中t
之前所有时刻的影响为输入即![]() ,而影响会随时间的推移而发生变化即
,而影响会随时间的推移而发生变化即 。
。
卷积神经网络: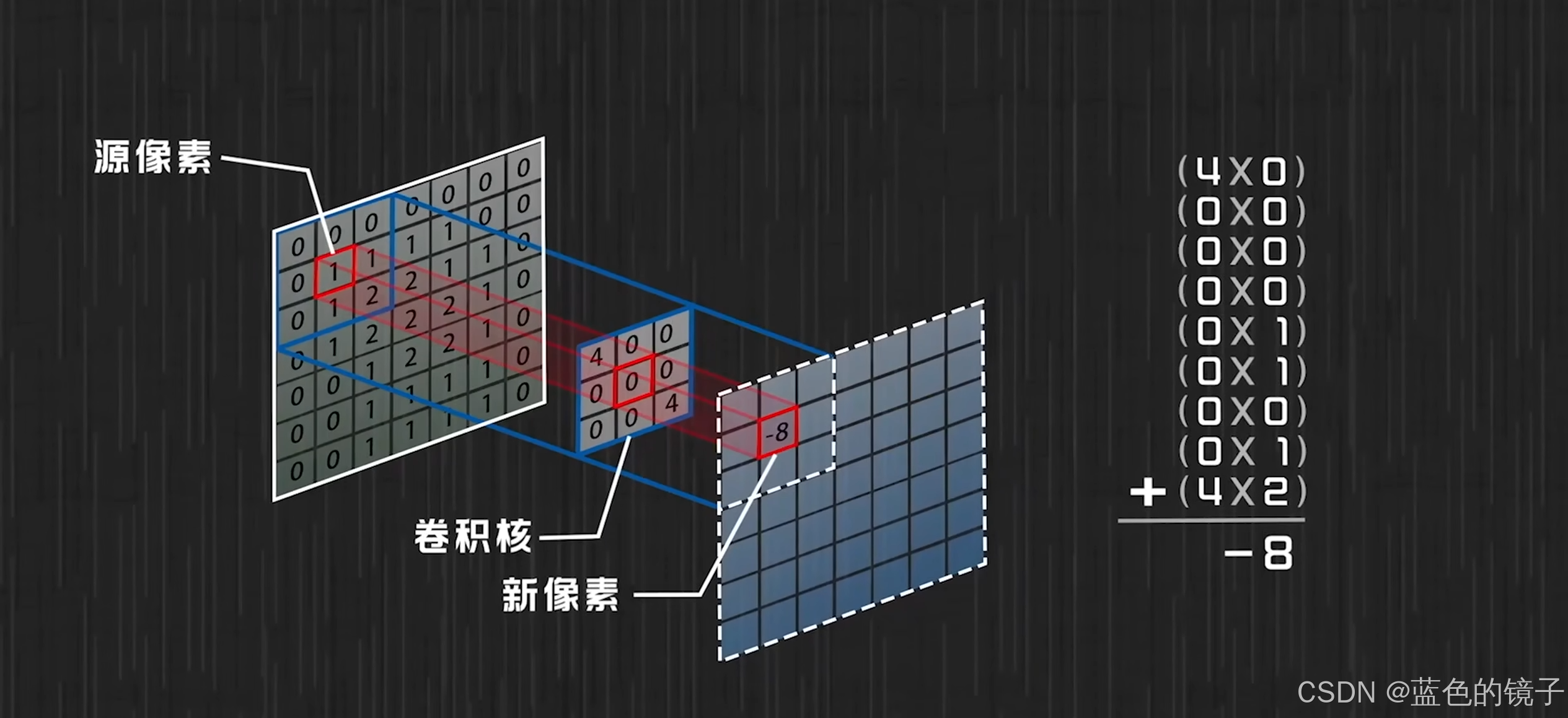
从卷积到卷积神经网络可以理解为求某个像素点周围的像素对其影响的总和。而影响的方式取决于卷积核里的权重,影响的范围取决于卷积核的大小。
比如平滑卷积操作:就是对3*3的卷积核求平均,也就是对一个像素点与周围的八个像素点比较大小,大了就变小,小了就拉大。从而使图像变得更平滑。
卷积核是怎么提取图像的特征的呢?

上述两种不同的卷积核分别把图像的水平特征核垂直特征提取了出来。
通过上述图片的例子可以发现,通过设计不同的卷积核,规定周围像素点对某个像素点影响的方式,从而重点关注一些像素点的影响,忽略一些像素点的影响,从而提取出局部特征。
Sigmoid函数的引用:
之前的感知机是用两侧的数据夹逼出分界线,然后用分界线去进行判断。而在神经网络的训练过程中往往只给了一类的数据,当然也就无法约束。也就不符合之前夹逼的思想。
如图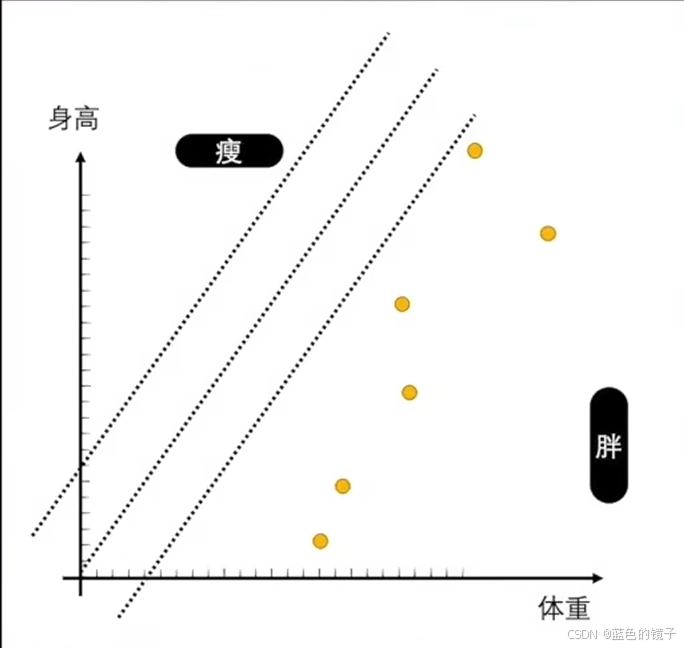
于是sigmoid函数取代了之前感知机的+1,-1的简单二分判断。也就是从是或否转换成了好坏的问题。
如图: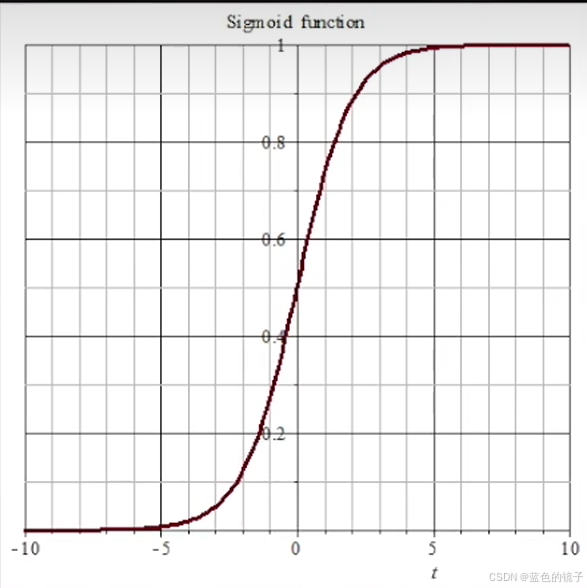
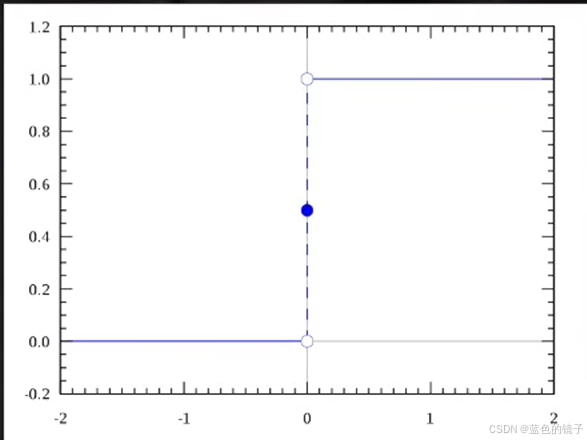
于是模型的训练可以解释为寻找一个理想模型,它可以最近似人脑的判断。比如世界上有以个理想的猫的模型,在它身上可以找到所有猫的投影。而这个模型实际上存在于人脑。输入数据时就是用人脑的理想模型给图片打上标签。然后让神经网络的模型尽可能去近似这个理想模型。
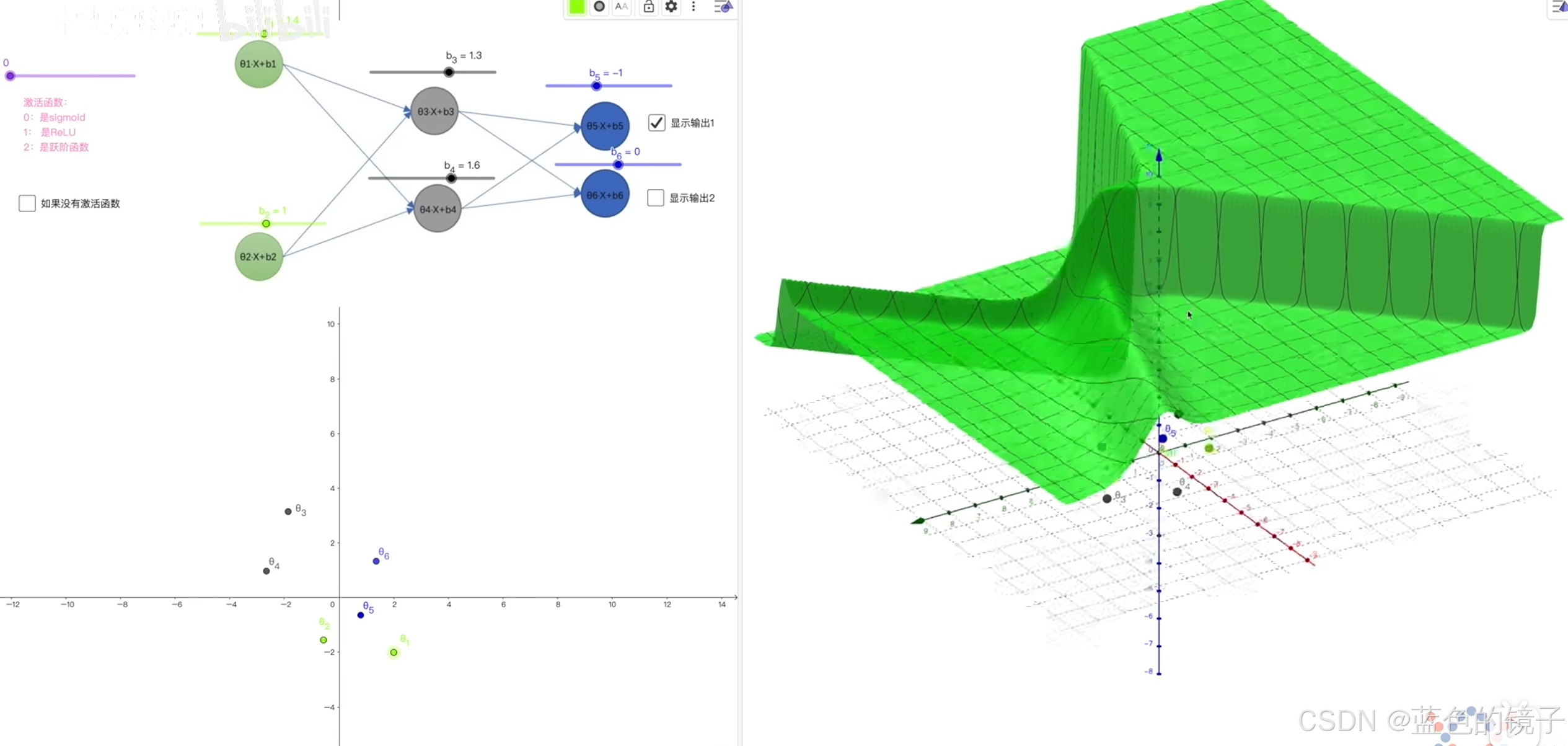
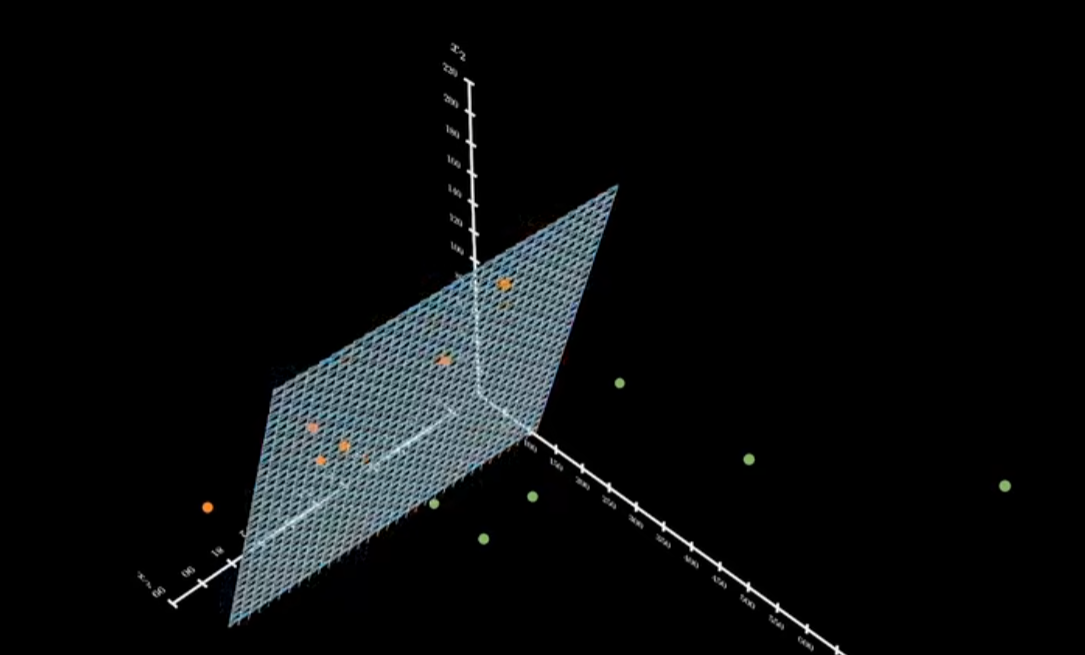
上述图片:是一个简单神经网络模型的可视化。可以看到通过参数的调整可以得到上述绿色分界面,它对不同数据进行了区分和画格子。不同数据被区分到了不同的格子里面。也就区分出了不同的类别。
损失函数是什么?它是如何设计出来的?
损失函数的作用:
神经网络与理想模型之间偏差的定量表达。
最小二乘法
数学公式:=
为理想结果,
为神经网络输出结果。二者的差值可以近似看作理想模型与神经网络之间的偏差。平方的作用是为了令结果为正数,方便处理计算。然后求其最小值。
极大似然估计
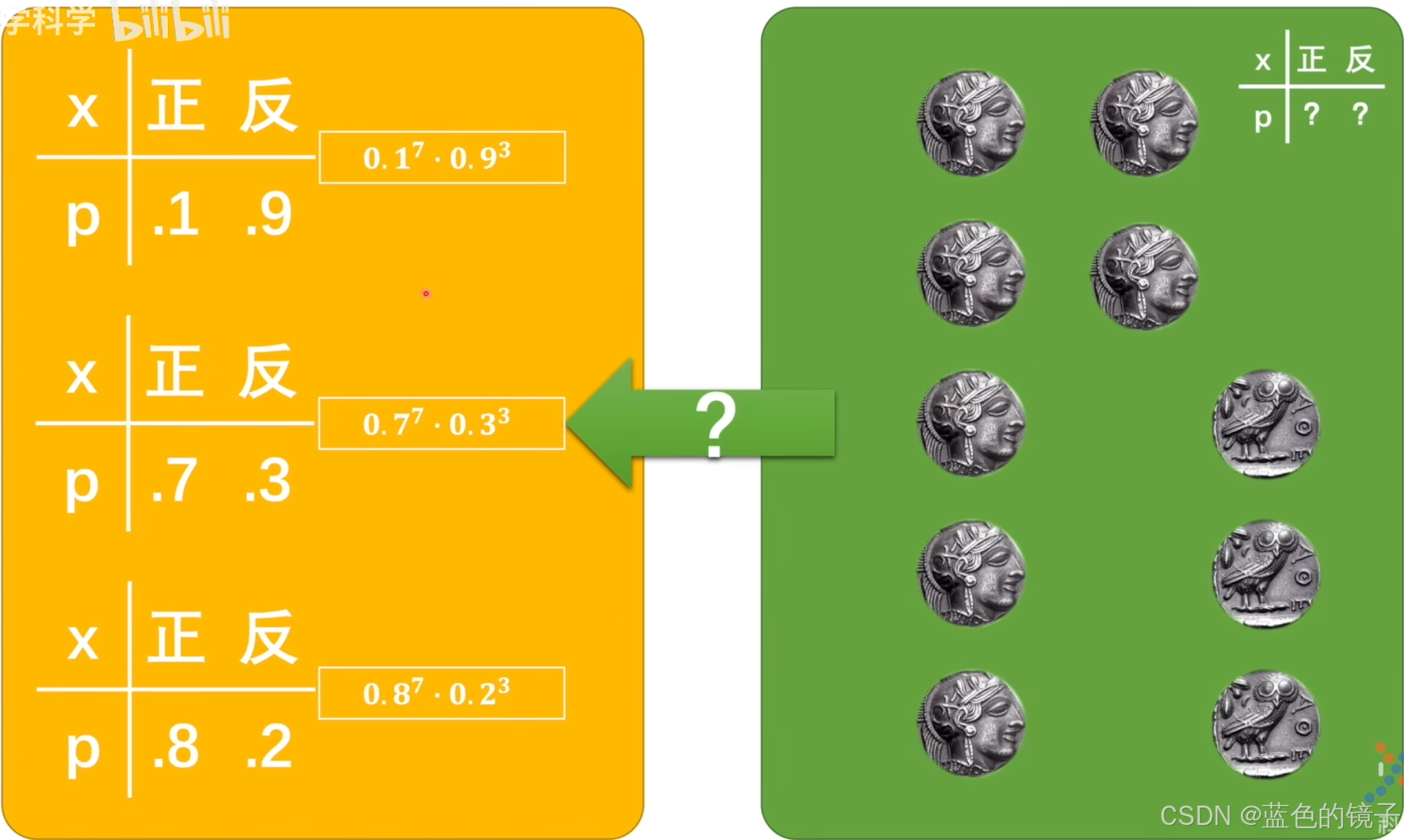
如上图假设的是一个投硬币的模型,假设我们目前还不知道硬币的概率模型是什么样,但通过实验得到上述三种结果。其中以中间的模型为例,根据它的结果得到的正反面概率分别为0.7,0.3。根据它得到的似然值为:![]() ,该模型下表示发生这种情况的可能性。我们需要选择似然值最大的模型,也就是最接近真实情况的模型了。
,该模型下表示发生这种情况的可能性。我们需要选择似然值最大的模型,也就是最接近真实情况的模型了。
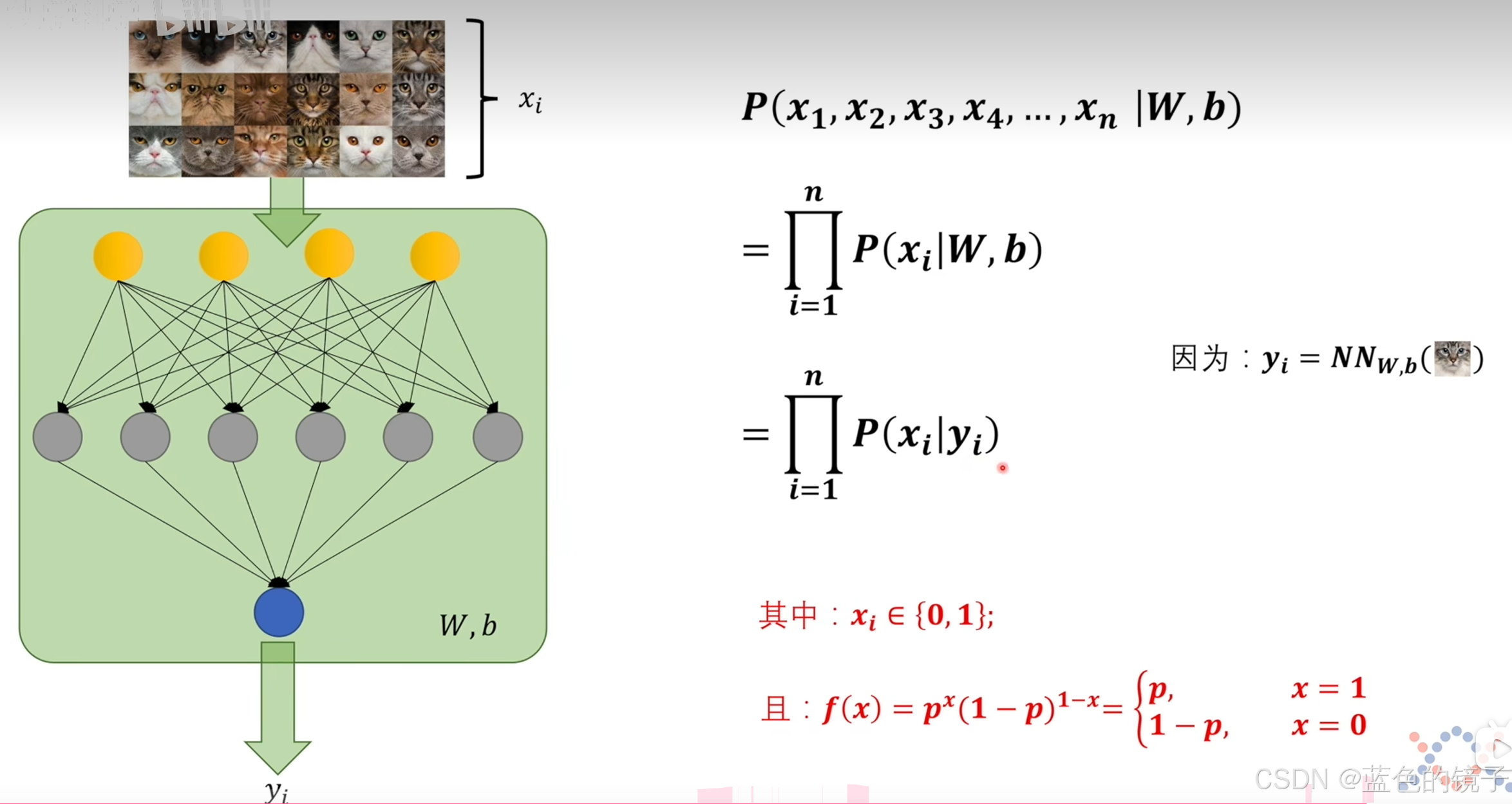
如上图:![]() 是人为输入的标签,也就是:是猫或不是猫。
是人为输入的标签,也就是:是猫或不是猫。 ![]() 是神经网络的输出值。
是神经网络的输出值。
用![]() ,
,![]() 带入极大似然估计法就可以得到:
带入极大似然估计法就可以得到: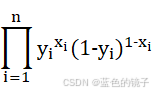 ,
,
为了方便计算和处理就可以将连乘变成连加,在将求最大值变成求最小值。表示为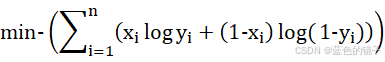
交叉熵损失函数
熵:描述一个模型体系的混乱程度(信息量)
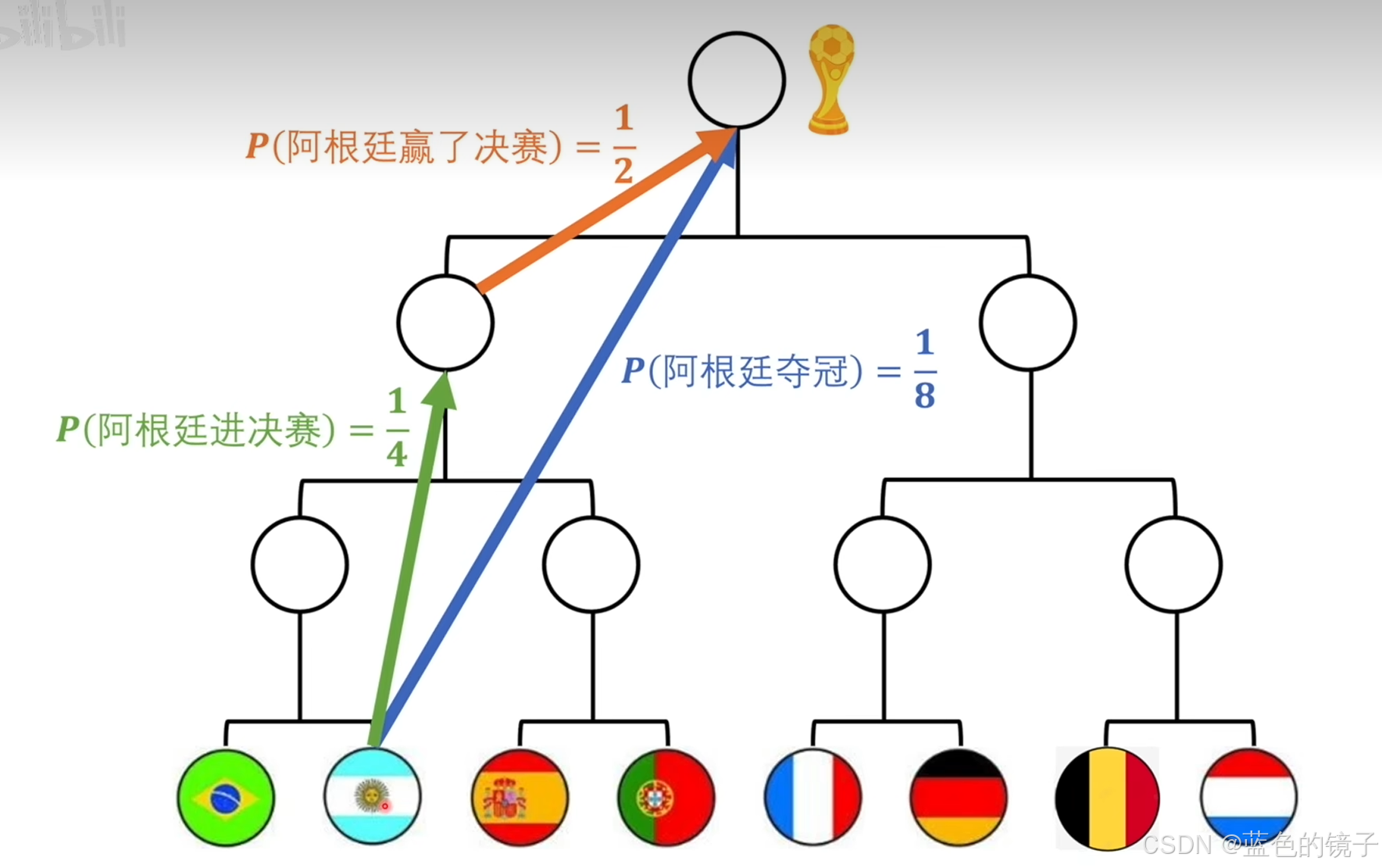
上述图片是一个例子,两种不同颜色的路径都指向了阿根廷球队夺冠,所以两种路径携带的信息量是相同的。表示为数学公式为:
![]()
![]()
![]()
所以![]() 就可以表示为:
就可以表示为:![]()
要使得![]() 这个式子成立,
这个式子成立,
![]() 就可以表示为
就可以表示为![]()
但是上述只是求出了单个事件的信息量,而不是整个系统的熵。要求整个系统的熵需要用每个事件的信息量乘以它的概率。如下图
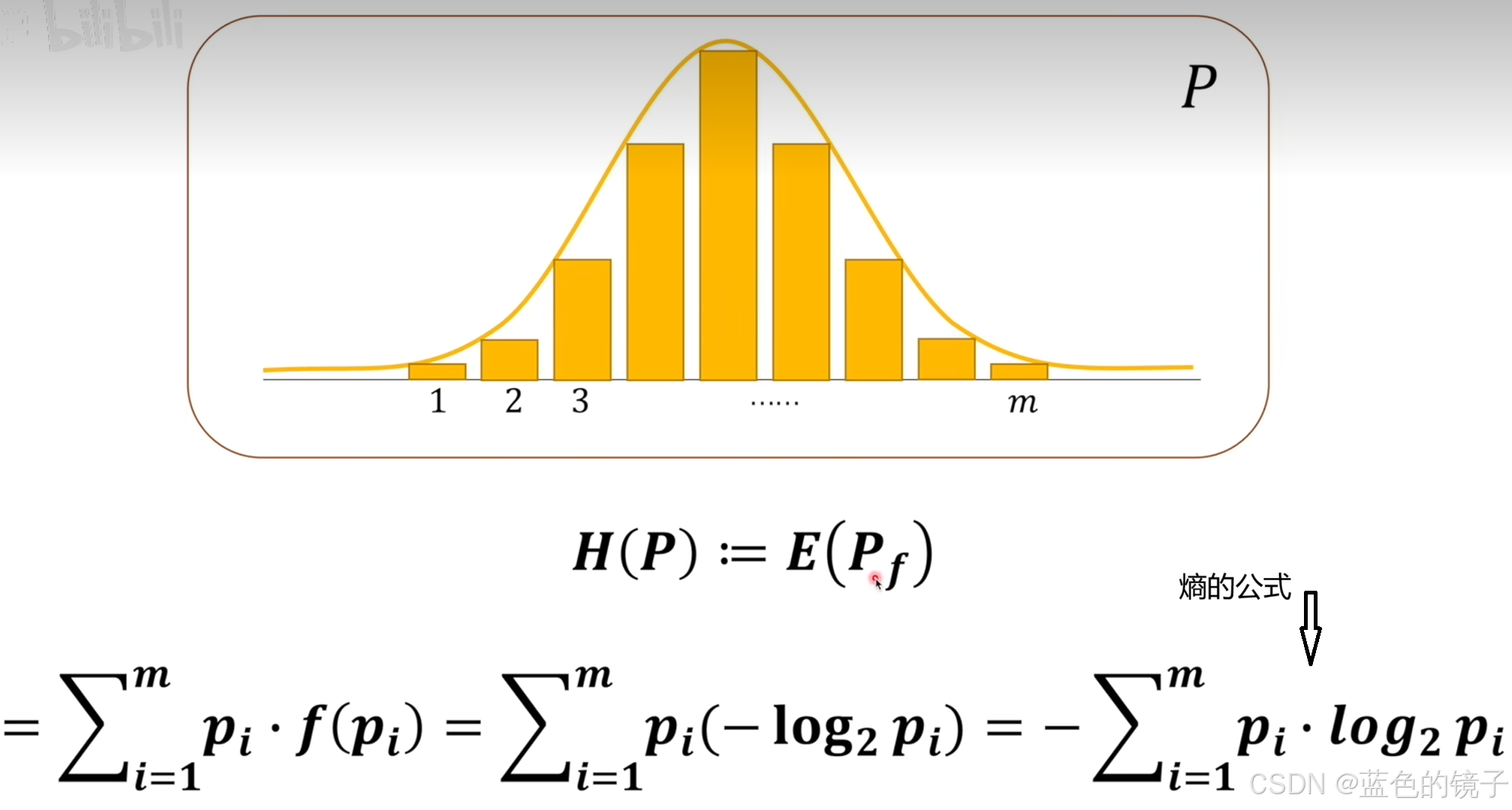
上述图片中,1--m表示1--m个事件,及其概率p。
要比较两个系统的信息量,就可以利用交叉熵,衡量两个系统的偏差。
根据上述熵的定义,可以推导出交叉熵的公式如下:
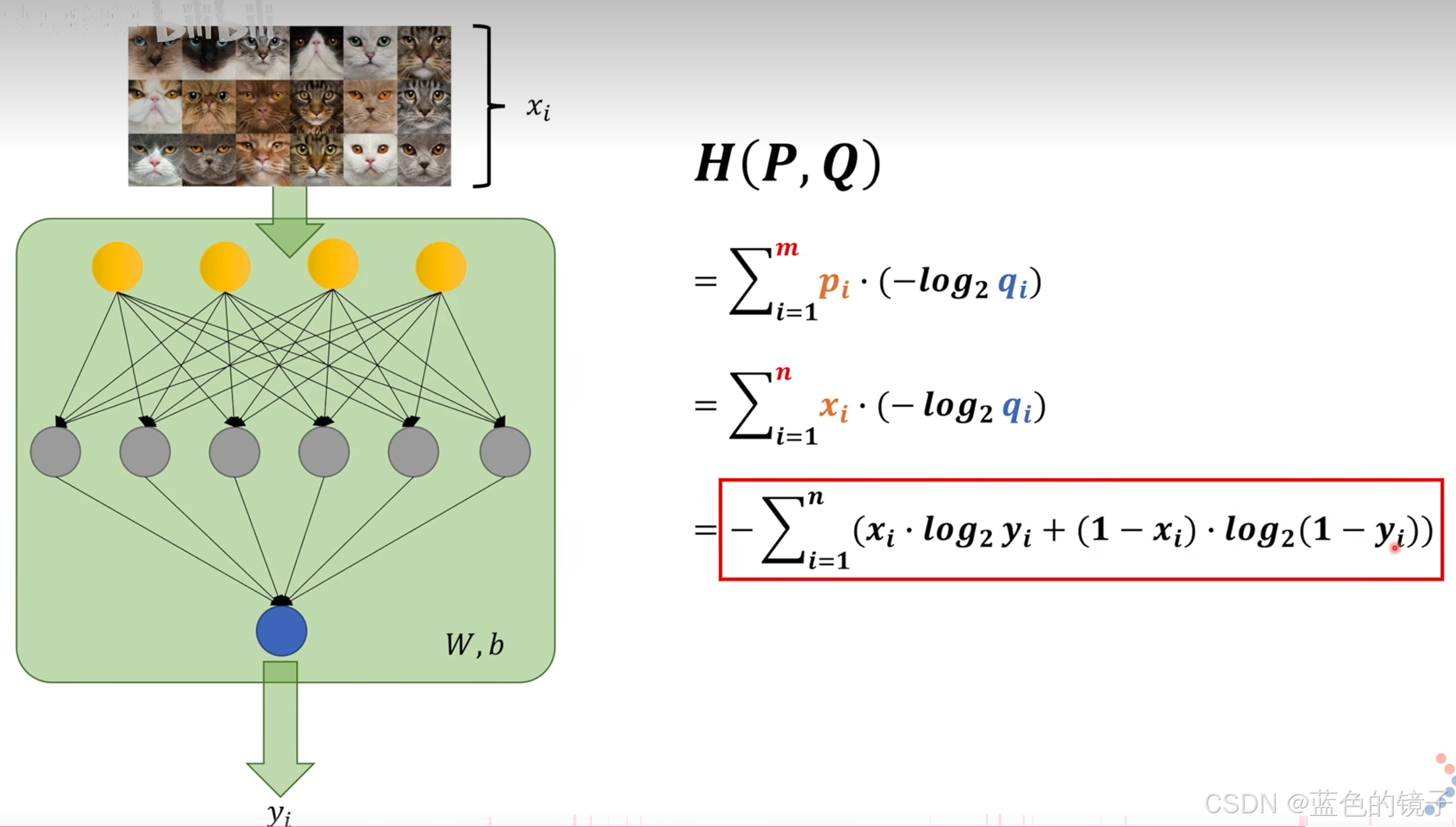
可以看出,交叉熵和极大似然估计推导出的公式是一样的。
理解梯度下降法,什么是反向传播?
通过上述的一系列公式,已经可以判断神经网络与理想模型的偏差,并对其进行量化了,但要对模型进行调整,就要借助梯度下降法了。
梯度
定义:梯度是一个向量,这个向量的方向等于函数分别对x,y(w,b)求偏导的向量的和。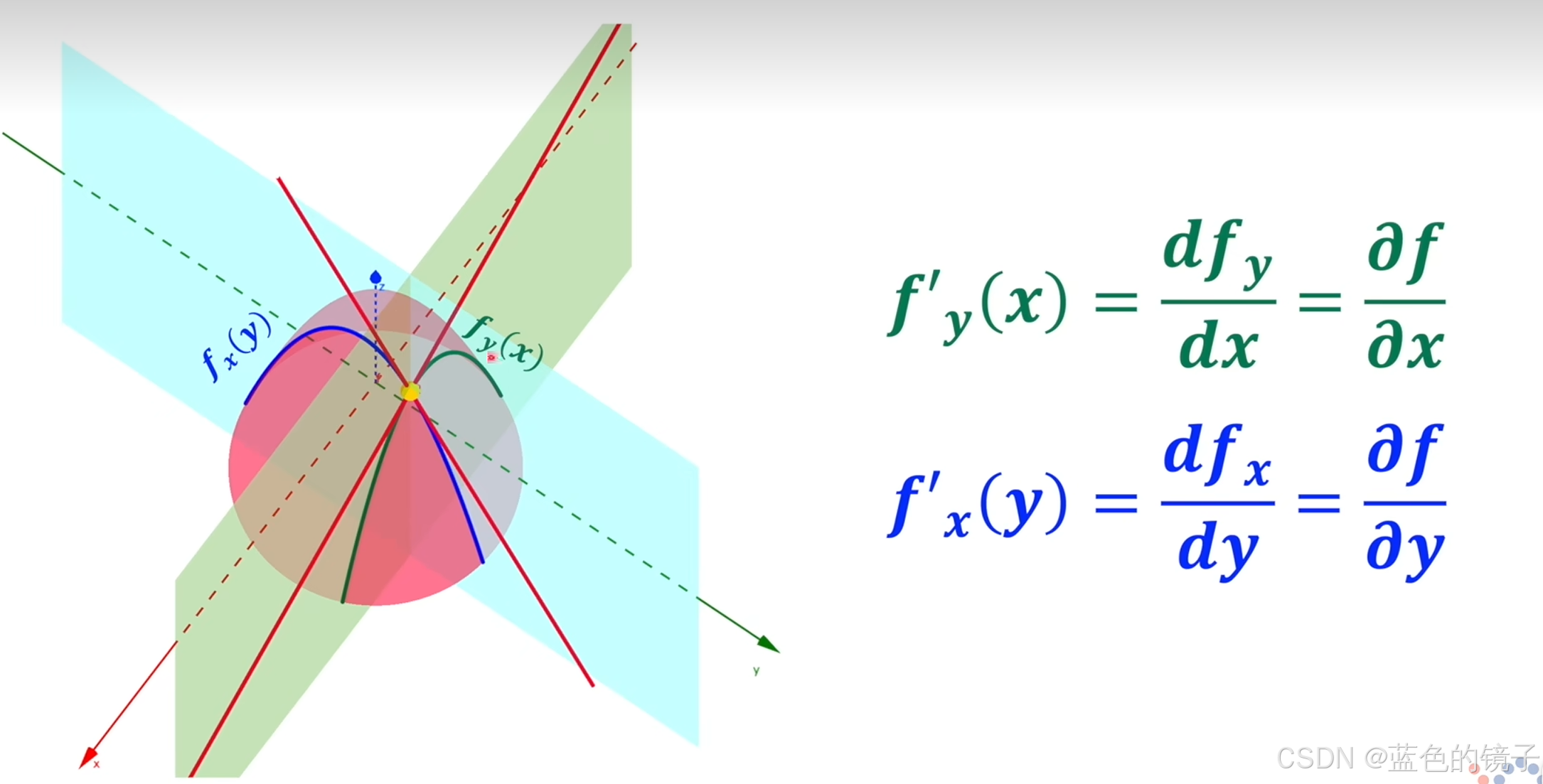
梯度上的变化量,是变化速度最快的变化量。
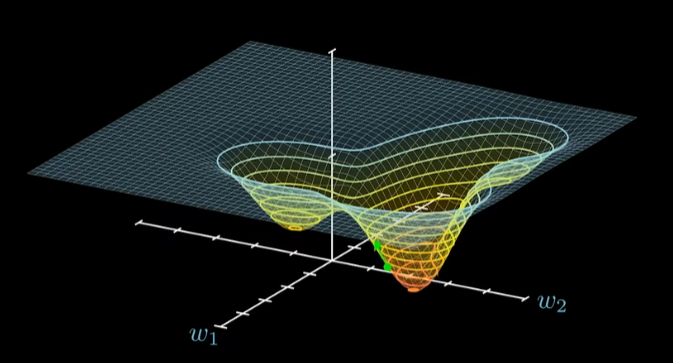
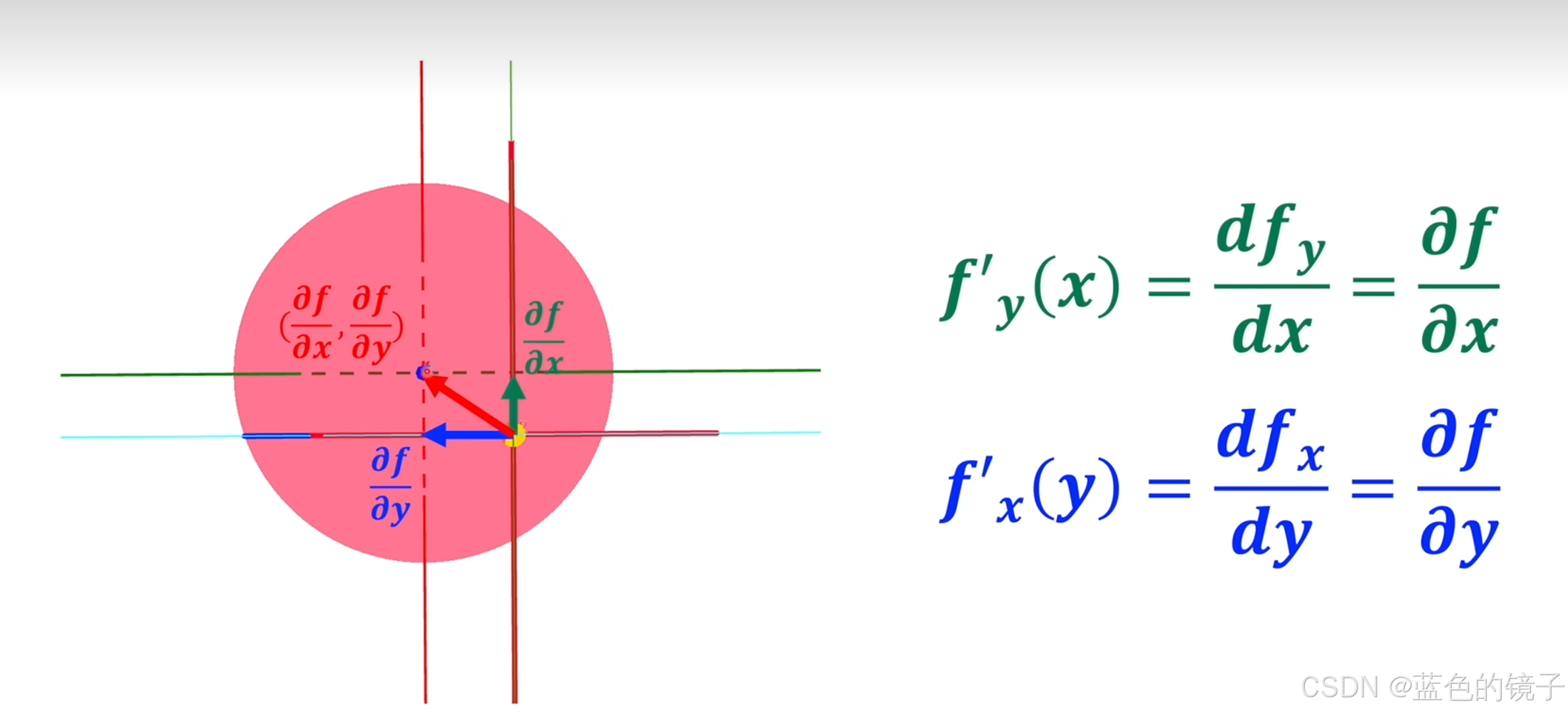
我们实际在训练过程中需要通过梯度来找到到达理想值最短最快捷的路径,当然理想值不一定是最大值,也可能是最小值,这时只需要对梯度进行相应的求反就行。
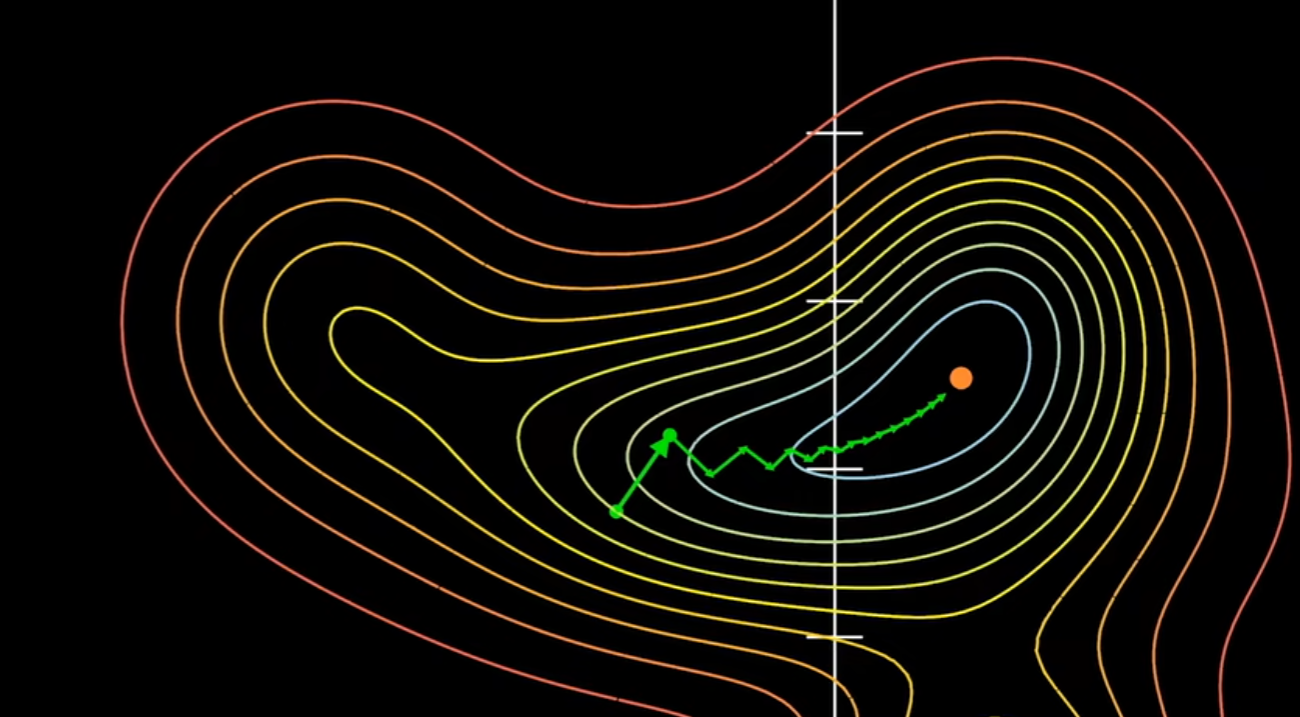
通过梯度指明的方向我们便可以一步一步走向理想值,但具体实现过程中,我们的路径依然不是最短理想的路径,在走的过程中依然会有曲折,这就和学习率有关了。
反向传播
数学过程
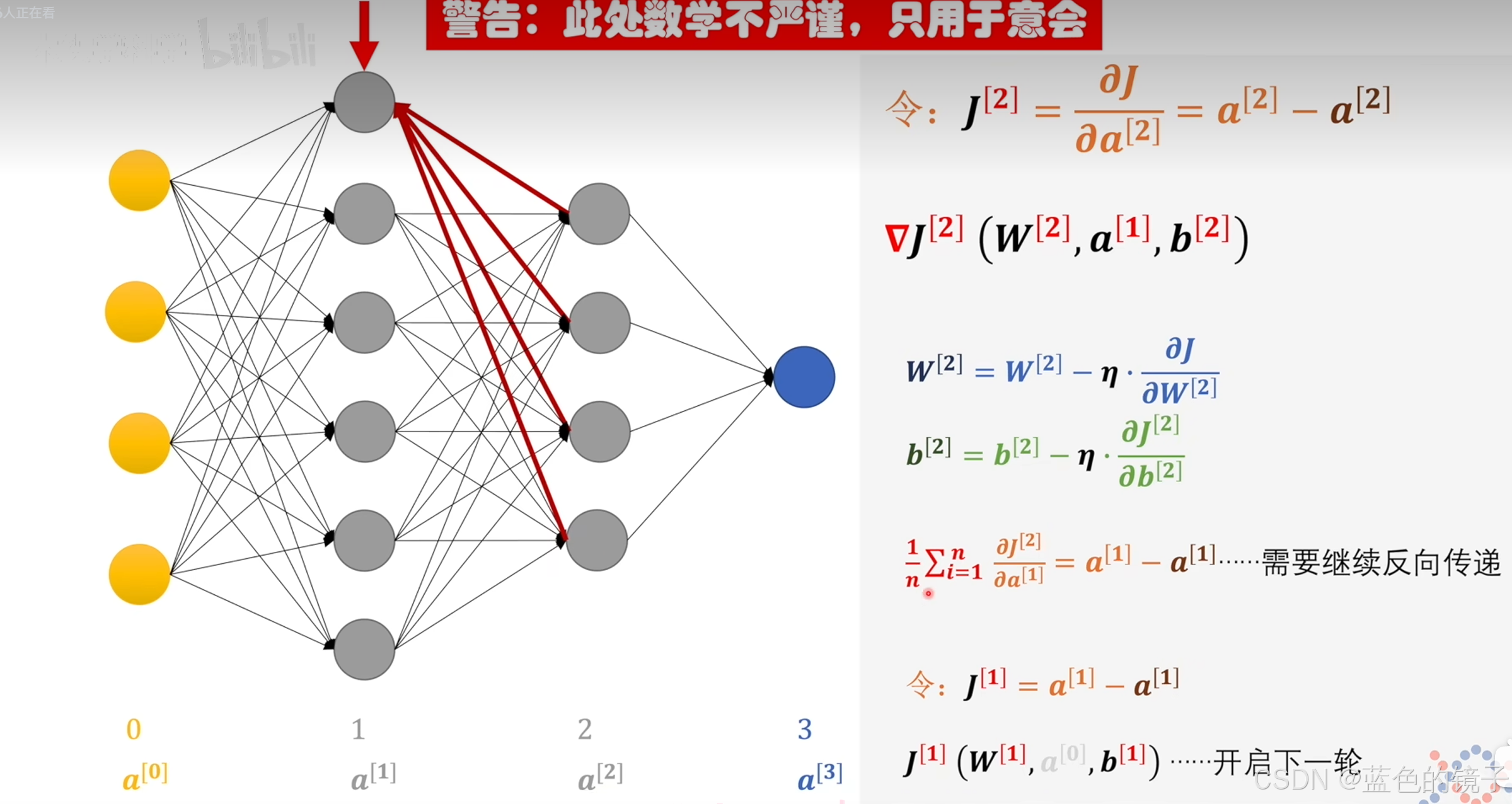
根据上述图片,在神经网络中,反向传播时误差由三个部分造成,分别是w(权重),b(偏置),(上一层神经网络传播过来的值)。分别对其求偏导,就可以得到梯度的变化方向。而
无法直接求偏导,需要继续向下传递。
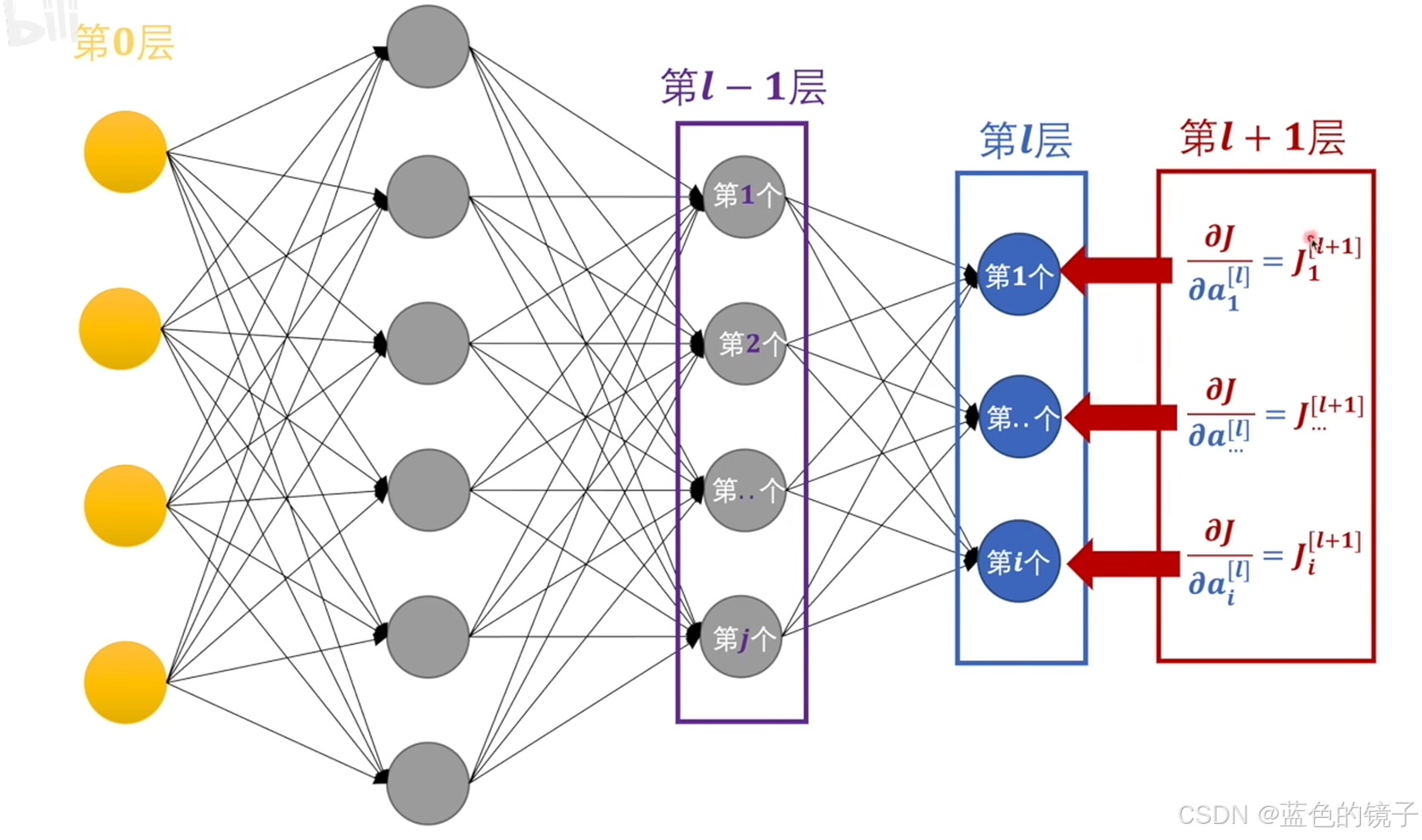
上述图片中,J表示对输出值进行损失函数处理,然后对其求梯度,然后进行反向传播。在这个过程中就需要使用链式求导。
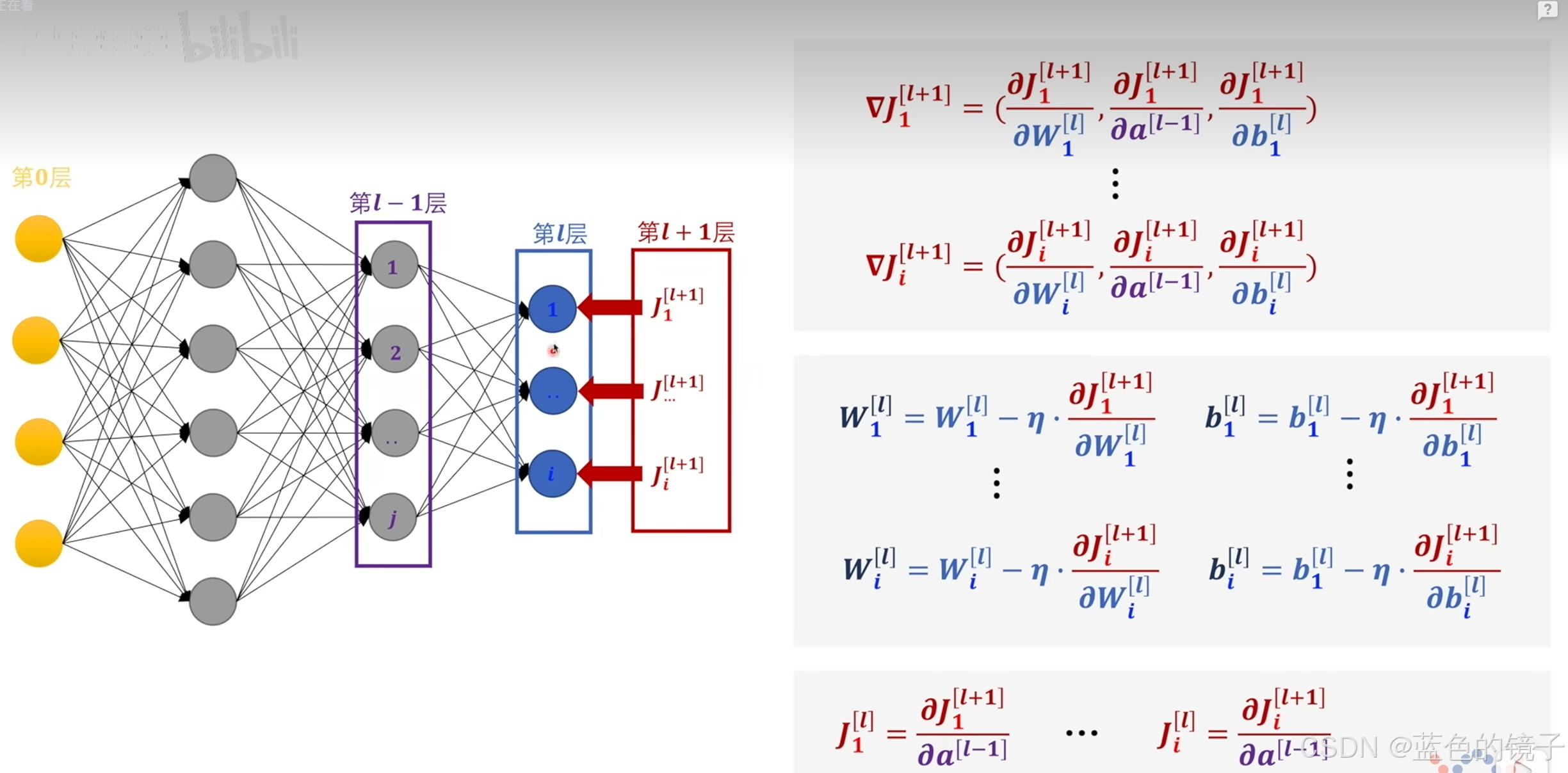
上述图片就是对w,b进行修改,修改方式就是原数值减去学习率()乘以对应偏导的值。之后的操作就是将(l)层当作新的(l+1)层,进行新一轮的反向传播,如此循环。
以上学习笔记来自视频:
【从“卷积”、到“图像卷积操作”、再到“卷积神经网络”,“卷积”意义的3次改变】https://www.bilibili.com/video/BV1VV411478E?vd_source=68f026aa93dbaf683828dfeccbf855b8
的总结。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)