7、SySeVR复现——Deep learning model
SySeVR复现
·
该部分代码并没有太大问题,只是tensorflow版本的改动,有些语法需要修改。
我使用的tensorflow版本是:1.15.0
目录
1、实验代码
代码对应bgru.py :
import keras.metrics
from keras.preprocessing import sequence
from keras.optimizers import SGD, RMSprop, Adagrad, Adam, Adadelta
from keras.models import Sequential, load_model
from keras.layers.core import Masking, Dense, Dropout, Activation
from keras.layers.recurrent import LSTM, GRU
from preprocess_dl_Input_version5 import *
from keras.layers.wrappers import Bidirectional
from collections import Counter
import numpy as np
import pickle
import random
import time
import math
import os
RANDOMSEED = 2018 # 设置种子值,使得随机数据可预测,即只要seed的值一样,生成的随机数都一样。
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID" # 按照PCI_BUS_ID顺序从0开始排列GPU设备
os.environ["CUDA_VISIBLE_DEVICES"] = "0" # 设置当前使用的GPU设备仅为0号设备 设备名称为'/gpu:0'
def build_model(maxlen, vector_dim, layers, dropout):
print('Build model...')
model = Sequential() # 类似神经网络的一个框架,主要功能就是添加layer
model.add(Masking(mask_value=0.0, input_shape=(maxlen, vector_dim))) # Mask机制就是我们在使用不等长特征的时候先将其补齐,在训练模型的时候再将这些参与补齐的数去掉,从而实现不等长特征的训练问题
for i in range(1, layers):
model.add(Bidirectional(
GRU(units=256, activation='tanh', recurrent_activation='hard_sigmoid', return_sequences=True)))
model.add(Dropout(dropout))
model.add(Bidirectional(GRU(units=256, activation='tanh', recurrent_activation='hard_sigmoid')))
model.add(Dropout(dropout))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adamax', metrics=[keras.metrics.TruePositives(), keras.metrics.TrueNegatives(), keras.metrics.FalsePositives(), keras.metrics.FalseNegatives(), 'accuracy', 'sparse_categorical_accuracy'])
model.summary()
return model
def main(traindataSet_path, testdataSet_path, weightpath, resultpath, batch_size, maxlen, vector_dim, layers, dropout):
print("Loading data...")
model = build_model(maxlen, vector_dim, layers, dropout)
print("Train...")
dataset = []
labels = []
testcases = []
for filename in os.listdir(traindataSet_path):
# if (filename.endswith(".pkl") is True):
# continue
print(filename)
f = open(os.path.join(traindataSet_path, filename), "rb")
dataset_file, labels_file, funcs_file, filenames_file, testcases_file = pickle.load(f)
f.close()
dataset += dataset_file
labels += labels_file
print(len(dataset), len(labels))
bin_labels = []
for label in labels:
bin_labels.append(multi_labels_to_two(label))
labels = bin_labels
np.random.seed(RANDOMSEED) # 设置随机数,针对使用np.random()生成随机数的时候相同
np.random.shuffle(dataset) # 将数据打乱
np.random.seed(RANDOMSEED)
np.random.shuffle(labels) # 将标签打乱顺序,数据与标签仍然对应。
train_generator = generator_of_data(dataset, labels, batch_size, maxlen, vector_dim)
all_train_samples = len(dataset)
steps_epoch = int(all_train_samples / batch_size)
print("start")
t1 = time.time()
model.fit_generator(train_generator, steps_per_epoch=steps_epoch, epochs=1)
t2 = time.time()
train_time = t2 - t1
model.save_weights(weightpath)
#model.load_weights(weightpath)
print("Test...")
dataset = []
labels = []
testcases = []
filenames = []
funcs = []
for filename in os.listdir(testdataSet_path):
if (filename.endswith(".pkl") is False):
continue
print(filename)
f = open(os.path.join(testdataSet_path, filename), "rb")
datasetfile, labelsfile, funcsfiles, filenamesfile, testcasesfile = pickle.load(f)
f.close()
dataset += datasetfile
labels += labelsfile
testcases += testcasesfile
funcs += funcsfiles
filenames += filenamesfile
# print(len(dataset), len(labels), len(testcases))
bin_labels = []
for label in labels:
bin_labels.append(multi_labels_to_two(label))
labels = bin_labels
# print(testcases)
test_generator = generator_of_data(dataset, labels, batch_size, maxlen, vector_dim)
all_test_samples = len(dataset)
steps_epoch = int(math.ceil(all_test_samples / batch_size))
t1 = time.time()
result = model.evaluate_generator(test_generator, steps=steps_epoch) # 测试数据
t2 = time.time()
test_time = t2 - t1
# print(result)
# print(result[:4])
TP = result[1]
TN = result[2]
FP = result[3]
FN = result[4]
FPR = float(FP) / (FP + TN + 1e-7)
FNR = float(FN) / (TP + FN + 1e-7)
accuracy = result[5]
precision = float(TP) / (TP + FP + 1e-7)
recall = float(TP) / (TP + FN + 1e-7)
f_score = (2 * precision * recall) / (precision + recall + 1e-7)
fwrite = open(resultpath, 'a') # a表示在已存在的数据后面写入,不会覆盖源文件。
fwrite.write('cdg_ddg: ' + ' ' + str(all_test_samples) + '\n')
fwrite.write("TP:" + str(TP) + ' FP:' + str(FP) + ' FN:' + str(FN) + ' TN:' + str(TN) + '\n')
fwrite.write('FPR: ' + str(FPR) + '\n')
fwrite.write('FNR: ' + str(FNR) + '\n')
fwrite.write('Accuracy: ' + str(accuracy) + '\n')
fwrite.write('precision: ' + str(precision) + '\n')
fwrite.write('recall: ' + str(recall) + '\n')
fwrite.write('fbeta_score: ' + str(f_score) + '\n')
fwrite.write('train_time:' + str(train_time) + ' ' + 'test_time:' + str(test_time) + '\n')
fwrite.write('--------------------\n')
fwrite.close()
def testrealdata(realtestpath, weightpath, batch_size, maxlen, vector_dim, layers, dropout):
model = build_model(maxlen, vector_dim, layers, dropout)
model.load_weights(weightpath)
print("Loading data...")
for filename in os.listdir(realtestpath):
print(filename)
f = open(realtestpath + filename, "rb")
realdata = pickle.load(f, encoding="latin1")
f.close()
labels = model.predict(x=realdata[0], batch_size=1)
for i in range(len(labels)):
if labels[i][0] >= 0.5:
print(realdata[1][i])
if __name__ == "__main__":
batchSize = 2 # 每一批数据的数量
vectorDim = 40 #
maxLen = 500
layers = 2 # 神经网络层数
dropout = 0.2
traindataSetPath = "./terminal/train/" # 训练数据路径,用于学习
testdataSetPath = "./terminal/test/" # 测试数据路径,用于测试
#realtestdataSetPath = "./teminal/realdata/" # 真实数据路径,用于预测
weightPath = './model/BGRU.h5' # 保存训练好的模型的权重
resultPath = "./result/test.txt" # 保存测试数据的实验结果
main(traindataSetPath, testdataSetPath, weightPath, resultPath, batchSize, maxLen, vectorDim, layers, dropout)
#testrealdata(realtestdataSetPath, weightPath, batchSize, maxLen, vectorDim, layers, dropout)2、实验结果
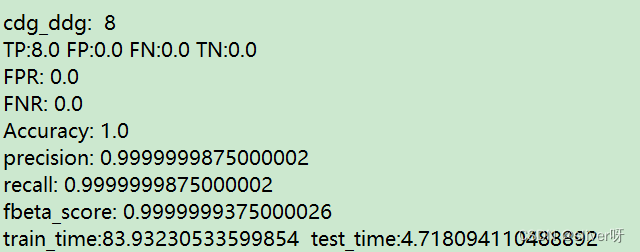
注:整个SySeVR代码的流程大概是这样,没有用完整的数据跑整个代码,所以不清楚最终结果如何。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)