Mask R-CNN介绍与代码分析
代码分析--数据预处理
项目源代码/Mask_RCNN
inspect_data.ipynb展示了准备训练数据的预处理步骤。
导包
导入的coco包需要从coco/PythonAPI下载操作数据代码,并在本地使用make指令编译,将生成的pycocotools拷贝至工程的主目录下,即和该inspect_data.ipynb文件同一目录。
import os
import sys
import itertools
import math
import logging
import json
import re
import random
from collections import OrderedDict
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import matplotlib.patches as patches
import matplotlib.lines as lines
from matplotlib.patches import Polygon
import utils
import visualize
from visualize import display_images
import model as modellib
from model import log
%matplotlib inline
ROOT_DIR = os.getcwd()加载数据集
COCO数据集的训练集内有82081张图片,共81类。
# MS COCO Dataset
import coco
config = coco.CocoConfig()
COCO_DIR = "/home/ouc/fjq/Mask_RCNN/coco" # COCO数据集位置
if config.NAME == 'shapes':
dataset = shapes.ShapesDataset()
dataset.load_shapes(500, config.IMAGE_SHAPE[0], config.IMAGE_SHAPE[1])
elif config.NAME == "coco":
dataset = coco.CocoDataset()
dataset.load_coco(COCO_DIR, "train")
# Must call before using the dataset
dataset.prepare()
print("Image Count: {}".format(len(dataset.image_ids)))
print("Class Count: {}".format(dataset.num_classes))
for i, info in enumerate(dataset.class_info):
print("{:3}. {:50}".format(i, info['name']))loading annotations into memory...
Done (t=10.62s)
creating index...
index created!
Image Count: 82081
Class Count: 81
0. BG
1. person
2. bicycle
3. car
4. motorcycle
5. airplane
6. bus
7. train
8. truck
9. boat
...
70. oven
71. toaster
72. sink
73. refrigerator
74. book
75. clock
76. vase
77. scissors
78. teddy bear
79. hair drier
80. toothbrushDisplay Samples
# Load and display random samples
image_ids = np.random.choice(dataset.image_ids, 4)
for image_id in image_ids:
image = dataset.load_image(image_id)
mask, class_ids = dataset.load_mask(image_id)
visualize.display_top_masks(image, mask, class_ids, dataset.class_names)
Bounding Boxes
这里我们不使用数据集本身提供的bbox坐标数据,取而代之的是通过mask计算出bbox,这样可以在不同的数据集下对bbox使用相同的处理方法。因为我们是从mask上计算bbox,相比与从图片计算bbox转换来说,更便于放缩,旋转,裁剪图像。
# Load random image and mask.
image_id = random.choice(dataset.image_ids)
image = dataset.load_image(image_id)
mask, class_ids = dataset.load_mask(image_id)
# Compute Bounding box
bbox = utils.extract_bboxes(mask)
# Display image and additional stats
print("image_id ", image_id, dataset.image_reference(image_id))
log("image", image)
log("mask", mask)
log("class_ids", class_ids)
log("bbox", bbox)
# Display image and instances
visualize.display_instances(image, bbox, mask, class_ids, dataset.class_names)image_id 73536 http://cocodataset.org/#explore?id=378229
image shape: (428, 640, 3) min: 0.00000 max: 255.00000
mask shape: (428, 640, 24) min: 0.00000 max: 1.00000
class_ids shape: (24,) min: -1.00000 max: 57.00000
bbox shape: (24, 4) min: 0.00000 max: 640.00000
Resize Images
因为训练时是批量处理的,每次batch要处理多张图片,模型需要一个固定的输入大小。故将训练集的图片放缩到一个固定的大小(1024×1024),放缩的过程要保持不变的宽高比,如果照片本身不是正方形,那边就在边缘填充0。
需要注意的是:原图片做了放缩,对应的mask也需要放缩,因为我们的bbox是依据mask计算出来的,这样省了修改程序了。
# Load random image and mask.
image_id = np.random.choice(dataset.image_ids, 1)[0]
image = dataset.load_image(image_id)
mask, class_ids = dataset.load_mask(image_id)
original_shape = image.shape
# Resize
image, window, scale, padding = utils.resize_image(
image,
min_dim=config.IMAGE_MIN_DIM,
max_dim=config.IMAGE_MAX_DIM,
padding=config.IMAGE_PADDING)
mask = utils.resize_mask(mask, scale, padding)
# Compute Bounding box
bbox = utils.extract_bboxes(mask)
# Display image and additional stats
print("image_id: ", image_id, dataset.image_reference(image_id))
print("Original shape: ", original_shape)
log("image", image)
log("mask", mask)
log("class_ids", class_ids)
log("bbox", bbox)
# Display image and instances
visualize.display_instances(image, bbox, mask, class_ids, dataset.class_names)image_id: 75153 http://cocodataset.org/#explore?id=250084
Original shape: (360, 640, 3)
image shape: (1024, 1024, 3) min: 0.00000 max: 254.00000
mask shape: (1024, 1024, 3) min: 0.00000 max: 1.00000
class_ids shape: (3,) min: 42.00000 max: 69.00000
bbox shape: (3, 4) min: 257.00000 max: 1024.00000原图片从(428, 640, 3)放大到(1024, 1024, 3),图片的上下两端都填充了0(黑色的部分):
Mini Masks
训练高分辨率的图片时,表示每个目标的二值mask也会非常大。例如,训练一张1024×1024的图片,其目标物体对应的mask需要1MB的内存(用boolean变量表示单点),如果1张图片有100个目标物体就需要100MB。讲道理,如果是五颜六色就算了,但实际上表示mask的图像矩阵上大部分都是0,很浪费空间。
为了节省空间同时提升训练速度,我们优化mask的表示方式,不直接存储那么多0,而是通过存储有值坐标的相对位置来压缩表示数据的内存,原理和压缩算法差类似。
- 我们存储在对象边界框内(bbox内)的mask像素,而不是存储整张图片的mask像素,大多数物体相对比于整张图片是较小的,节省存储空间是通过少存储目标周围的0实现的。
- 将mask调整到小尺寸
56×56,对于大尺寸的物体会丢失一些精度,但是大多数对象的注解并不是很准确,所以大多数情况下这些损失是可以忽略的。(可以在config类中设置mini mask的size。)
说白了就是在处理数据的时候,我们先利用标注的mask信息计算出对应的bbox框,而后利用计算的bbox框反过来改变mask的表示方法,目的就是操作规范化,同时降低存储空间和计算复杂度。
image_id = np.random.choice(dataset.image_ids, 1)[0]
image, image_meta, class_ids, bbox, mask = modellib.load_image_gt(
dataset, config, image_id, use_mini_mask=False)
log("image", image)
log("image_meta", image_meta)
log("class_ids", class_ids)
log("bbox", bbox)
log("mask", mask)
display_images([image]+[mask[:,:,i] for i in range(min(mask.shape[-1], 7))])image shape: (1024, 1024, 3) min: 0.00000 max: 255.00000
image_meta shape: (89,) min: 0.00000 max: 17734.00000
class_ids shape: (5,) min: 1.00000 max: 36.00000
bbox shape: (5, 4) min: 70.00000 max: 845.00000
mask shape: (1024, 1024, 5) min: 0.00000 max: 1.00000随机选取一张图片,可以看到图片目标相对与图片本身较小:

visualize.display_instances(image, bbox, mask, class_ids, dataset.class_names)
使用load_image_gt方法,传入use_mini_mask=True实现mini mask操作:
# Add augmentation and mask resizing.
image, image_meta, class_ids, bbox, mask = modellib.load_image_gt(
dataset, config, image_id, augment=True, use_mini_mask=True)
log("mask", mask)
display_images([image]+[mask[:,:,i] for i in range(min(mask.shape[-1], 7))])mask shape: (56, 56, 5) min: 0.00000 max: 1.00000
这里为了展现效果,将mini_mask表示方法通过expand_mask方法扩大到大图像下的mask,再绘制试试:
mask = utils.expand_mask(bbox, mask, image.shape)
visualize.display_instances(image, bbox, mask, class_ids, dataset.class_names)
可以看到边界是锯齿状,这也是压缩的副作用,总体来说效果还可以。
Anchors
Anchors是Faster R-CNN提出的方法。
模型在运行过程中有多层feature map,同时也会有非常多的Anchors,处理好Anchors的顺序非常重要。例如使用anchors的顺序要匹配卷积处理的顺序等规则。
对于FPN网络,anchor的顺序要与卷积层的输出相匹配:
- 先按金字塔等级排序,第一层的所有anchors,第二层所有anchors,etc..通过按层次可以很容易分开所有的anchors
- 对于每个层,通过feature map处理序列来排列anchors,通常,一个卷积层处理一个feature map 是从左上角开始,向右一行一行来整
- 对于feature map的每个cell,可为不同比例的Anchors采用随意顺序,这里我们将采用不同比例的顺序当参数传递给相应的函数
Anchor步长:在FPN架构下,前几层的feature map是高分辨率的。例如,如果输入是1024×1024,那么第一层的feature map大小为256×256,这会产生约200K的anchors(2562563),这些anchor都是32×32,相对于图片像素的步长为4(1024/256=4),这里面有很多重叠,如果我们能够为feature map的每个点生成独有的anchor,就会显著的降低负载,如果设置anchor的步长为2,那么anchor的数量就会下降4倍。
这里我们使用的strides为2,这和论文不一样,在Config类中,我们配置了3中比例([0.5, 1, 2])的anchors,以第一层feature map举例,其大小为256×256,故有256*256*3/2*2=49152。
# Generate Anchors
anchors = utils.generate_pyramid_anchors(config.RPN_ANCHOR_SCALES,
config.RPN_ANCHOR_RATIOS,
config.BACKBONE_SHAPES,
config.BACKBONE_STRIDES,
config.RPN_ANCHOR_STRIDE)
# Print summary of anchors
num_levels = len(config.BACKBONE_SHAPES)
anchors_per_cell = len(config.RPN_ANCHOR_RATIOS)
print("Count: ", anchors.shape[0])
print("Scales: ", config.RPN_ANCHOR_SCALES)
print("ratios: ", config.RPN_ANCHOR_RATIOS)
print("Anchors per Cell: ", anchors_per_cell)
print("Levels: ", num_levels)
anchors_per_level = []
for l in range(num_levels):
num_cells = config.BACKBONE_SHAPES[l][0] * config.BACKBONE_SHAPES[l][1]
anchors_per_level.append(anchors_per_cell * num_cells // config.RPN_ANCHOR_STRIDE**2)
print("Anchors in Level {}: {}".format(l, anchors_per_level[l]))Count: 261888
Scales: (32, 64, 128, 256, 512)
ratios: [0.5, 1, 2]
Anchors per Cell: 3
Levels: 5
Anchors in Level 0: 196608
Anchors in Level 1: 49152
Anchors in Level 2: 12288
Anchors in Level 3: 3072
Anchors in Level 4: 768看看位置图片中心点cell的不同层anchor表示:
## Visualize anchors of one cell at the center of the feature map of a specific level
# Load and draw random image
image_id = np.random.choice(dataset.image_ids, 1)[0]
image, image_meta, _, _, _ = modellib.load_image_gt(dataset, config, image_id)
fig, ax = plt.subplots(1, figsize=(10, 10))
ax.imshow(image)
levels = len(config.BACKBONE_SHAPES)
for level in range(levels):
colors = visualize.random_colors(levels)
# Compute the index of the anchors at the center of the image
level_start = sum(anchors_per_level[:level]) # sum of anchors of previous levels
level_anchors = anchors[level_start:level_start+anchors_per_level[level]]
print("Level {}. Anchors: {:6} Feature map Shape: {}".format(level, level_anchors.shape[0],
config.BACKBONE_SHAPES[level]))
center_cell = config.BACKBONE_SHAPES[level] // 2
center_cell_index = (center_cell[0] * config.BACKBONE_SHAPES[level][1] + center_cell[1])
level_center = center_cell_index * anchors_per_cell
center_anchor = anchors_per_cell * (
(center_cell[0] * config.BACKBONE_SHAPES[level][1] / config.RPN_ANCHOR_STRIDE**2) \
+ center_cell[1] / config.RPN_ANCHOR_STRIDE)
level_center = int(center_anchor)
# Draw anchors. Brightness show the order in the array, dark to bright.
for i, rect in enumerate(level_anchors[level_center:level_center+anchors_per_cell]):
y1, x1, y2, x2 = rect
p = patches.Rectangle((x1, y1), x2-x1, y2-y1, linewidth=2, facecolor='none',
edgecolor=(i+1)*np.array(colors[level]) / anchors_per_cell)
ax.add_patch(p)
Level 0. Anchors: 196608 Feature map Shape: [256 256]
Level 1. Anchors: 49152 Feature map Shape: [128 128]
Level 2. Anchors: 12288 Feature map Shape: [64 64]
Level 3. Anchors: 3072 Feature map Shape: [32 32]
Level 4. Anchors: 768 Feature map Shape: [16 16]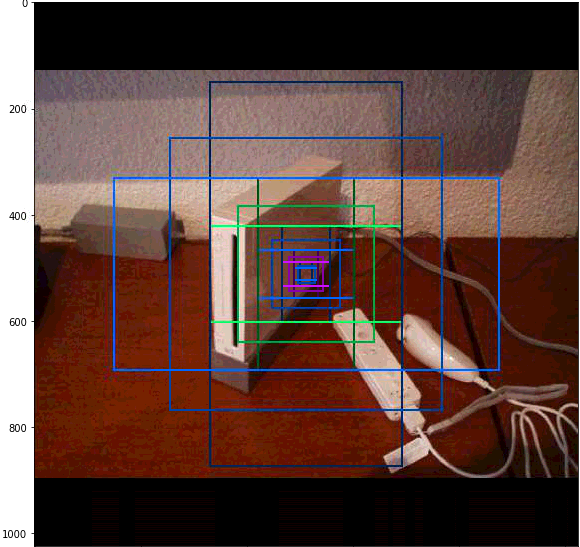

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)