论文阅读:FFVT for FGVC
Feature Fusion Vision Transformer for Fine-Grained Visual Categorization文章目录Feature Fusion Vision Transformer for Fine-Grained Visual Categorization摘要1 引言2 相关研究3 方法3.1 Transformer3.2 FFVT架构特征融合模块相互注意力
Feature Fusion Vision Transformer for Fine-Grained Visual Categorization
文章目录
摘要
- 深层的分类token更关注全局信息,缺乏局部和低级特征。文本提出了一种基于Transformer框架的特征融合视觉转换器(FFVT),聚合来自每个Transformer layer的重要token以弥补局部信息,低级和中级信息
- 设计了一种称为相互注意权重选择 (MAWS) 的token选择模块,指导网络选择判别性token。
- 在三个基准测试中验证了 FFVT 的有效性,取得了最先进的性能。
1 引言
TransFG中,虽然将最后transformer layer输入改成最重要的token,但是最终的类token可能更多地关注全局信息而较少关注局部和低级特征,而局部信息在 FGVC 中起着重要作用。 此外,之前的工作侧重于大规模 FGVC 基准,没有研究探索在小规模环境中的能力。
本文提出的方法合主要工作:
- 一种特征融合视觉transformer(FFVT),聚合了来自低级、中级和高级token的局部信息进行分类。
- 一种重要token选择方法,称为相互注意权重选择 (MAWS),选择每一层上的代表性token,这些token被添加为最后一个transformer layer的输入。
- 探索在一个大规模和两个小规模 FGVC 数据集上的性能
本文主要贡献:
- 首次探索transformer在小规模和大规模细粒度视觉分类设置上的性能的研究。
- FFV,可以自动检测区分区域并利用图像中不同级别的全局和局部信息。
- 重要token选择方法,相互注意权重选择 (MAWS)。
- 验证了方法在三个数据集上的性能
2 相关研究
FGVC和transformer
作者认为 TransFG 无法在一些具有挑战性的数据集(即小规模和超细粒度数据集)上捕获足够的判别信息,本文将 ViT 扩展到大规模 FGVC 和小规模超细粒度视觉分类设置。
3 方法
3.1 Transformer
将patch映射到D维嵌入空间上。加上一个可训练的位置嵌入:
z 0 = [ x c l a s s ; x p 1 E , x p 2 E , . . . , x p N E ] + E p o s z l ′ = M S A ( L N ( z l − 1 ) ) + z l − 1 , l ∈ 1 , 2 , . . . , L z l = M L P ( L N ( z l ′ ) ) + z l ′ , l ∈ 1 , 2 , . . . , L z_0=[x_{class};x^1_pE,x^2_pE,...,x^N_pE]+E_{pos}\\ z'_l=MSA(LN(z_{l-1}))+z_{l-1}, l\in 1,2,...,L\\ z_l=MLP(LN(z'_{l}))+z'_l, l\in 1,2,...,L z0=[xclass;xp1E,xp2E,...,xpNE]+Eposzl′=MSA(LN(zl−1))+zl−1,l∈1,2,...,Lzl=MLP(LN(zl′))+zl′,l∈1,2,...,L
- N N N是token的个数
- E ∈ R ( P 2 ∗ C ) ∗ D E\in R^{(P^2*C)*D} E∈R(P2∗C)∗D。token大小是 P ∗ P ∗ C P*P*C P∗P∗C,每个token映射到 D D D维度。
- E p o s ∈ R N ∗ D E_{pos}\in R^{N*D} Epos∈RN∗D
- M S A MSA MSA:multi-head self-attention
- M L P MLP MLP:Linear-GELU-Dropout-Linear-Dropout
3.2 FFVT架构
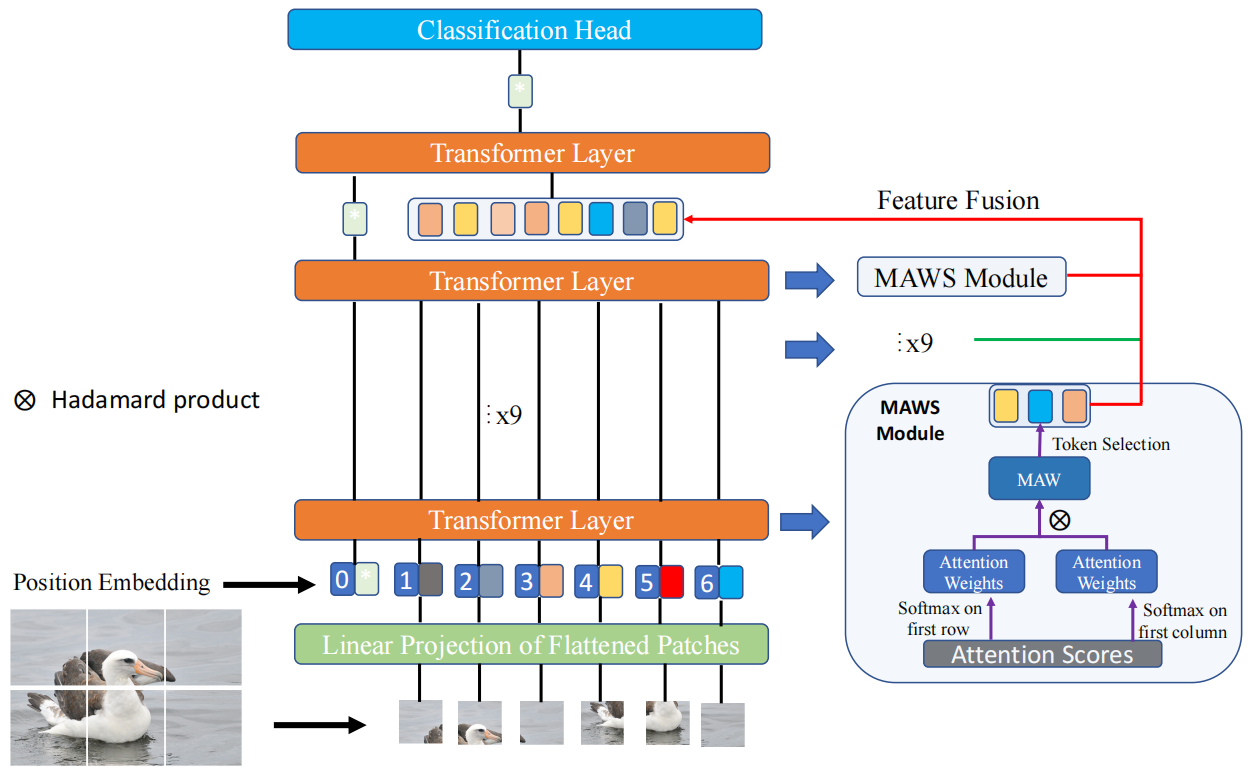
特征融合模块
来弥补缺失的局部信息。给定 MAWS 模块选择的每一层的重要token,将最后一个Transformer layer的输入(class token除外)替换为选择的token。这样使class token聚合了低级、中级、高级特征,丰富局部信息和特征表示能力。
z l l o c a l = [ z l 1 , z l 2 , . . . , z l K ] z f f = [ z L − 1 0 ; z 1 l o c a l ; z 2 l o c a l ; . . . ; z L − 1 l o c a l ] z^{local}_l=[z^1_l,z^2_l,...,z^K_l]\\ z_{ff}=[z^0_{L-1};z^{local}_1;z^{local}_2;...;z^{local}_{L-1}] zllocal=[zl1,zl2,...,zlK]zff=[zL−10;z1local;z2local;...;zL−1local]
相互注意力权重选择模块MAWS
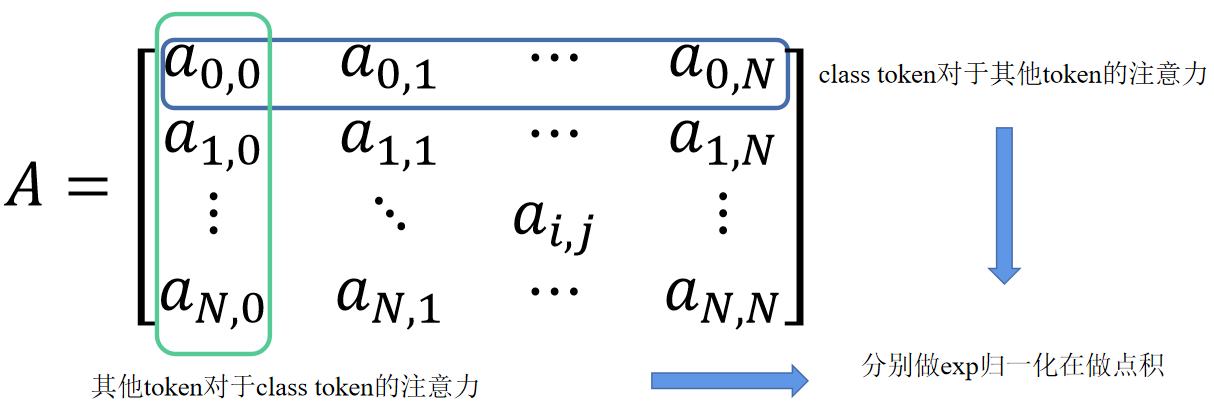
注意力分数矩阵:
A = [ a 0 ; a 1 ; a 2 ; . . . , ; a N ] ∈ R ( N + 1 ) × ( N + 1 ) a i = [ a i , 0 , a i , 1 , a i , 2 , . . . , a i , j , . . . , a i , N ] A=[a^0;a_1;a_2;...,;a_N]\in R^{(N+1)\times(N+1)}\\ a_i=[a_{i,0},a_{i,1},a_{i,2},...,a_{i,j},...,a_{i,N}] A=[a0;a1;a2;...,;aN]∈R(N+1)×(N+1)ai=[ai,0,ai,1,ai,2,...,ai,j,...,ai,N]
- a i , j a_{i,j} ai,j就是两个token的注意力分数,即 i i i的 q q q和 j j j的 k k k点积
策略:
- 单一注意力权重选择(SAWS):选择具有与分类token较高注意力分数的token。可以通过对 a 0 a_0 a0 进行排序并选择前 K K K 个实现。可能会引入嘈杂的信息,因为选定的token可以从嘈杂的patch中聚合很多信息。
- 相互注意力权重选择模块(MAWS):它要求选择的token和class token相似,既要在class token上又要在被选择的token上。
具体来说,将注意力得分矩阵中的第一列表示为 b 0 b_0 b0( b 0 b_0 b0 是其他的token对于class token的注意力分数, a 0 a_0 a0是class token对于其他token的注意力分数)分类token和token i 之间的相互注意权重 (MAW) m a i ma_i mai:
m a i = a 0 , i ′ ∗ b i , 0 ′ a 0 , i ′ = e a 0 , i ∑ i = 0 N e a 0 , j b i , 0 ′ = e b i , 0 ∑ j = 0 N e b j , 0 ma_i=a'_{0,i}*b'_{i,0}\\ a'_{0,i}=\frac{e^{a_{0,i}}}{\sum^N_{i=0}e^{a_{0,j}}}\\ b'_{i,0}=\frac{e^{b_{i,0}}}{\sum^N_{j=0}e^{b_{j,0}}}\\ mai=a0,i′∗bi,0′a0,i′=∑i=0Nea0,jea0,ibi,0′=∑j=0Nebj,0ebi,0
对于multi-head self attention,先平均所有head的注意力分数。得到相互关注权重后,根据相互关注值收集重要token的指标。方法没有引入额外的学习参数。
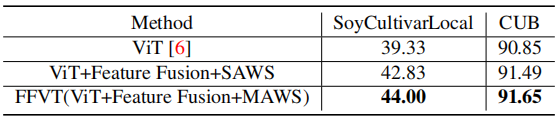
4 实验
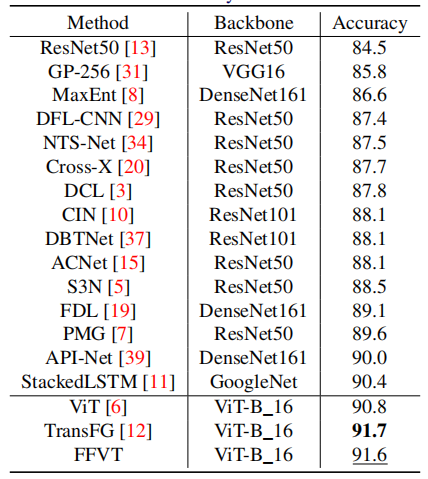
比TransFG差,因为它的重叠策略将patch数量从784增加到1296。
5 总结
- 特征融合方法
- 相互注意力选择模块

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)