编译原理 —— FOLLOW集
FOLLOW集FOLLOW(A):紧跟在非终结符A后边的终结符α的集合如果A是某个句型的的最右符号,则将结束符 $$$ 添加到 FOLLOW(A)中计算非终结符A的 FOLLOW集合(1)将$$$放入 FOLLOW(S)中,其中S是开始符号,$$$是输入右端的结束标记(2)如果存在一个产生式 A→αBβA→αBβA→αBβ ,那么FIRST(B)中除 εεε 之外的所有符号都在FOL...
·
FOLLOW集
- FOLLOW(A):紧跟在非终结符A后边的终结符α的集合
- 如果A是某个句型的的最右符号,则将结束符 $ $ $ 添加到 FOLLOW(A)中
计算非终结符A的 FOLLOW集合
(1)将 $ $ $放入 FOLLOW(S)中,其中S是开始符号, $ $ $是输入右端的结束标记
(2)如果存在一个产生式 A → α B β A→αBβ A→αBβ ,那么FIRST(β)中除 ε ε ε 之外的所有符号都在FOLLOW(B)中
(因为B可以由A推导出来,且位于最右边,所以A的FOLLOW集也是B的FOLLOW集)
(3)如果存在一个产生式 A → α B A→αB A→αB,或存在产生式 A → α B β A→αBβ A→αBβ且FIRST(β)包含 ε ε ε ,那么FOLLOW(A)中的所有符号都在FOLLOW(B)中
(4)重复上述过程,直到没有新的终结符可以加入
举例: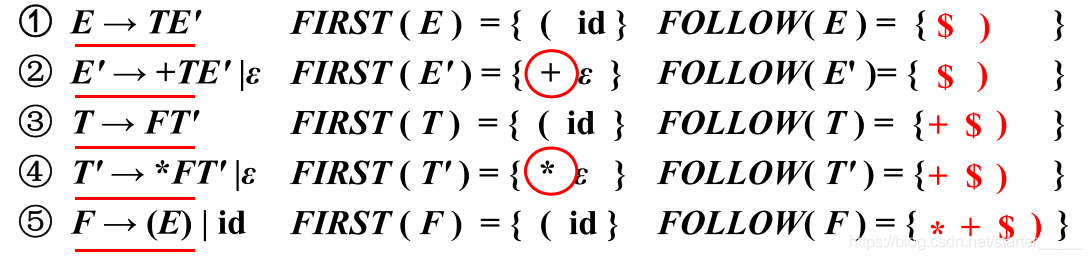
- E E E 本身就是一个句型,它是该句型的最右符号,故将结束符 $ $ $添加到FOLLOW ( A ) (A) (A)中
- 由式子①
- E ′ E' E′ 紧跟在 T T T 后面,故 FOLLOW ( T ) (T) (T) 中包含 FIRST ( E ′ ) (E') (E′)中的终结符 +
- FIRST ( E ′ ) (E') (E′)中包含 ε ε ε, T T T可能是产生式①右部的最后一个符号,故 T T T 依赖于 E E E,FOLLOW ( E ) (E) (E) ∈ FOLLOW ( T ) (T) (T)
- E ′ E' E′ 可能是产生式①右部的最后一个符号,故 E ′ E' E′ 依赖于 E E E,FOLLOW ( E ) (E) (E) ∈ FOLLOW ( E ′ ) (E') (E′)
- 式子②中, T T T 和 E ′ E' E′ 所处位置与式子①相同,分析结果也将相同
- 由式子③
- T ′ T' T′ 紧跟在 F F F 后面,故 FOLLOW ( F ) (F) (F) 中包含 FIRST ( T ′ ) (T') (T′)中的终结符 *
- FIRST ( T ′ ) (T') (T′)中包含 ε ε ε, F F F 可能是产生式③右部的最后一个符号,故 F F F 依赖于 T T T,FOLLOW ( T ) (T) (T) ∈ FOLLOW ( F ) (F) (F)
- T ′ T' T′ 可能是产生式③右部的最后一个符号,故 T ′ T' T′ 依赖于 T T T,FOLLOW ( T ) (T) (T) ∈ FOLLOW ( T ′ ) (T') (T′)
- 式子④中, F F F 和 T ′ T' T′ 所处位置与式子③相同,分析结果也将相同
- 式子⑤中, E E E 的后面跟着终结符 ) ) ),故将 ) ) )添加到FOLLOW ( E ) (E) (E)中
- 验证是否满足所有的依赖关系
参考地址:
https://www.icourse163.org/learn/HIT-1002123007?tid=1003246005#/learn/announce

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 2
2 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)