看见统计——第一章 基础概率论
看见统计——第一章 基础概率论
看见统计——第一章 基础概率论
参考
- https://github.com/seeingtheory/Seeing-Theory
入门概念
术语
概率实验(experiment)(如抛硬币或掷骰子)有几个组成部分。样本空间(sample space)是实验中所有可能结果的集合。我们通常用希腊大写字母“omega” Ω Ω Ω 表示样本空间。所以在掷硬币的实验中,样本空间是
Ω = { H , T } \Omega =\{H,T\} Ω={H,T}
因为只有两种可能的结果:正面(H)或反面(T)。
对于掷色子的实验,其样本空间则为 Ω = { 1 , 2 , 3 , 4 , 5 , 6 } \Omega =\{1,2,3,4,5,6\} Ω={1,2,3,4,5,6}。
样本空间Ω中的结果集合称为事件(event),我们通常使用大写罗马字母来表示这些集合。例如,我们可能会对掷骰子出现偶数的事件感兴趣。如果我们将此事件称为 E E E,则
E = { 2 , 4 , 6 } E=\{ 2,4,6\} E={2,4,6}
Ω Ω Ω 的任何子集都是有效事件。
给掷骰子和抛硬币分配概率
在随机实验中,每个事件都有一个概率。如果 A A A 是某个感兴趣的事件,那么 P ( A ) P(A) P(A) 是 A A A 发生的概率。实验中的概率不是任意的,它们必须满足一组规则或公理。首先要求所有概率都是非负的。换句话说,在一个样本空间 Ω Ω Ω 的实验中,对于任何事件, A ⊆ Ω A⊆Ω A⊆Ω,一定有:
P ( A ) ≥ 0 (1) P(A)\ge 0\tag{1} P(A)≥0(1)
下一个公理是 Ω Ω Ω 中所有结果的概率之和必须为1。形式化表达如下:
∑ ω ∈ Ω P ( ω ) = 1 (2) \sum_{\omega\in\Omega}P(\omega)=1\tag{2} ω∈Ω∑P(ω)=1(2)
一旦我们知道了实验结果的概率,我们就可以计算出任何事件的概率。这是因为一个事件的概率是它所包含的结果的概率之和。换句话说,对于事件 A ⊆ Ω A⊆Ω A⊆Ω, A A A 的概率为
P ( A ) = ∑ ω ∈ A P ( ω ) (3) P(A) = \sum_{\omega\in A}P(\omega)\tag{3} P(A)=ω∈A∑P(ω)(3)
为了说明这个等式,让我们找出掷骰子出现偶数的概率,我们将用 E E E 表示事件。由于 E = { 2 , 4 , 6 } E=\{2,4,6\} E={2,4,6} ,我们只需将这三个结果的概率相加即可获得:
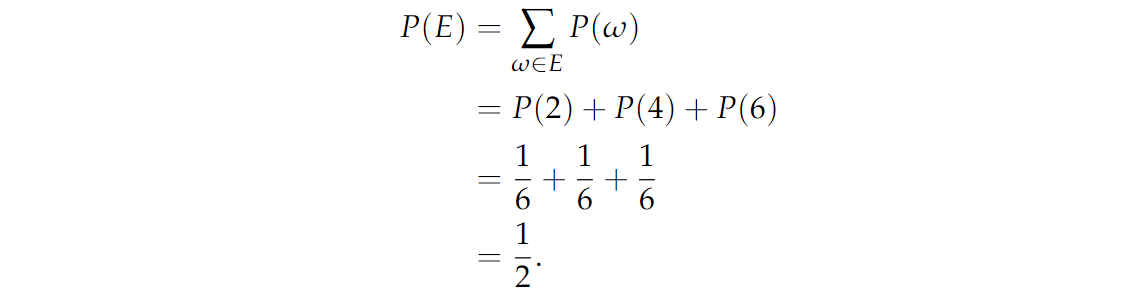
我们得到至少一个 H H H 的概率是多少?解决这个问题的一个方法是把所有至少有一个 H H H 的结果的概率加起来,我们会得到:

另一种方法是找出我们没有投出至少一个 H H H 的概率,然后从1中减去这个概率:
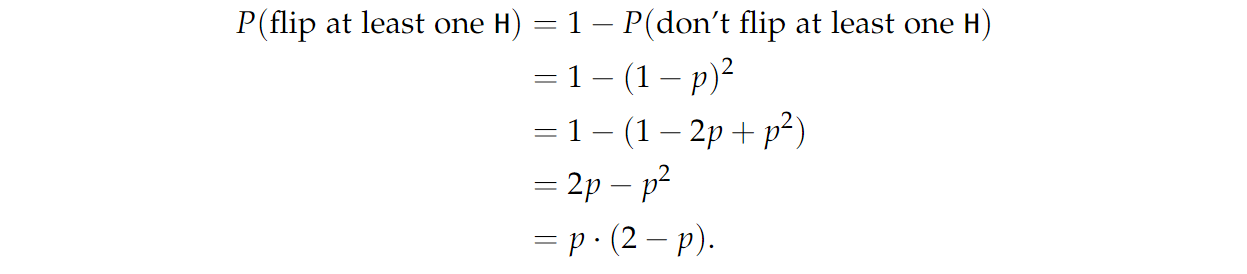
通常情况下,计算一个事件的补的概率并从1中减去它,以求出原始事件的概率会花费更少的时间。
独立性
如果 A A A 和 B B B 这两个事件既不影响对方,也不给对方提供任何信息,我们就说 A A A 和 B B B 是独立的。记住,这并不等于说 A A A 和 B B B 是不相交的。如果 A A A 和 B B B 不相交,那么给出 A A A 发生的信息,我们就可以肯定地知道 B B B 没有发生。因此,如果 A A A 和 B B B 是不相交的,它们永远不可能是独立的。独立事件的数学表述如下所示:
P ( A ∩ B ) = P ( A ) ∩ P ( B ) P(A\cap B)=P(A)\cap P(B) P(A∩B)=P(A)∩P(B)
∩ \cap ∩ 符号表示 A A A 和 B B B 发生,即事件的交集。
🌠 例子:抛硬币抛两次,样本空间为:
Ω = { H H , H T , T H , T T } \Omega = \{HH,HT,TH,TT\} Ω={HH,HT,TH,TT}
定义事件如下:
A ≐ { f i r s t f l i p h e a d s } = { H H , H T } B ≐ { s e c o n d f l i p h e a d s } = { H H , H T } } \begin{aligned} & A\doteq\{first\ flip\ heads\}=\{HH,HT\}\\ & B\doteq\{second\ flip \ heads\}=\{HH,HT\}\} \end{aligned} A≐{first flip heads}={HH,HT}B≐{second flip heads}={HH,HT}}
符号 ≐ \doteq ≐ 来表示我们在定义某物。在上面的表达式中,我们定义任意符号 A A A 和 B B B 来表示事件。
有 P ( A ∩ B ) = P ( { H T } ) = 1 4 , P ( A ) = P ( B ) = 1 4 + 1 4 = 1 2 P(A\cap B)=P(\{HT\})=\frac{1}{4},P(A)=P(B)=\frac{1}{4}+\frac{1}{4}=\frac{1}{2} P(A∩B)=P({HT})=41,P(A)=P(B)=41+41=21.
所以 P ( A ∩ B ) = P ( A ) P ( B ) P(A\cap B)=P(A)P(B) P(A∩B)=P(A)P(B),则有 A A A 和 B B B 两个事件是独立的。
图解
生活中充满了随机性。概率论是一门用数学语言来刻画这些随机事件的学科。一个随机事件的概率是一个介于0与1之间的实数,这个实数的大小反映了这个事件发生的可能性。因此,概率为0意味着这个事件不可能发生(不可能事件),概率为1意味着这个事件必然发生(必然事件)。
以一个投掷一枚公平的硬币(出现正面和反面的概率相等,均为1/2)的经典的概率实验为例。在现实中,如果我们重复抛一枚硬币,出现正面的频率可能不会恰好是50%。但是当抛硬币的次数增加时,出现正面的概率会越来越接近50%。
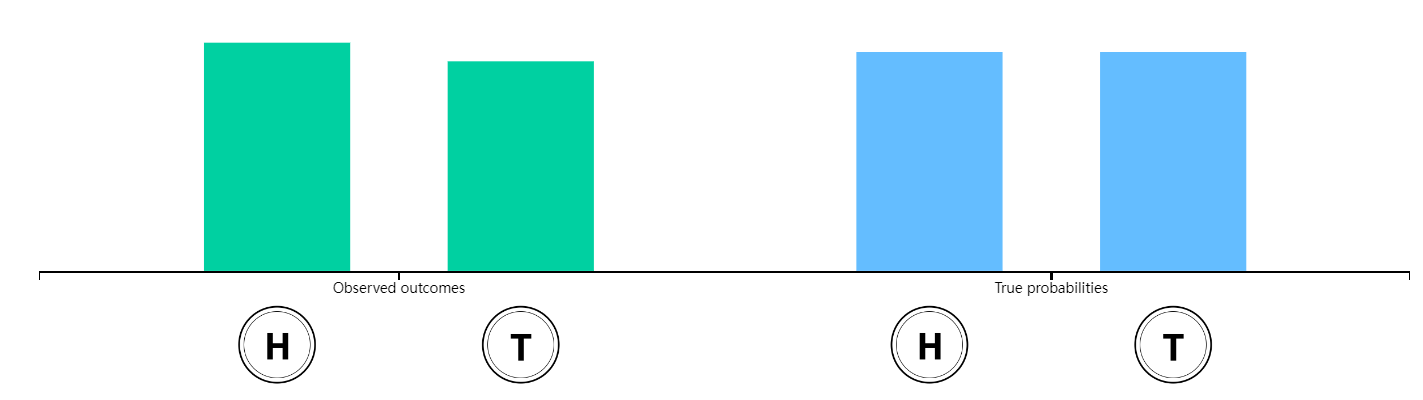
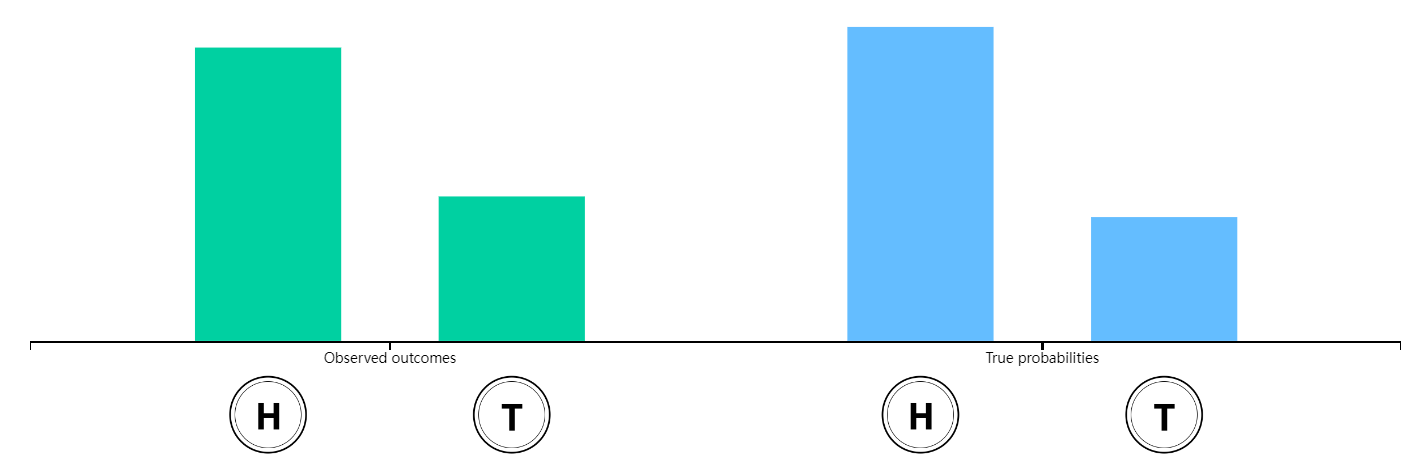
如果硬币两面的重量不一样, 出现正面的概率就和出现反面的概率不一样了。上下拖动屏幕右侧蓝色柱状图来改变硬币正面和反面的的重量分布。如果我们用一个实数来代表抛硬币的结果:比如说1表示正面,0表示反面,那么我们称这个数为 随机变量(random variable)。
期望Expectation
一个随机变量的期望刻画的是这个随机变量的概率分布的“中心”。简而言之,当有无穷多来自同一个概率分布的独立样本时,它们的平均值就是期望。数学上对期望的定义是以概率(或密度)为权重的加权平均值。
🔥 定义: X X X 的期望值,用 E ( X ) E(X) E(X)表示,定义如下:
E ( X ) = ∑ x ∈ X ( Ω ) x P ( X = x ) E(X) = \sum_{x \in X(\Omega)}xP(X=x) E(X)=x∈X(Ω)∑xP(X=x)
抛硬币的期望值
现在,让 X X X 表示有偏置 p p p 的硬币抛出的值。也就是说,对于概率 p p p ,我们抛出 H H H ,在这种情况下, X = 1 X=1 X=1 。类似地,对于概率 1 − p 1−p 1−p ,我们抛出 T T T ,在这种情况下, X = 0 X=0 X=0。然后,随机数 X X X 的期望值为:
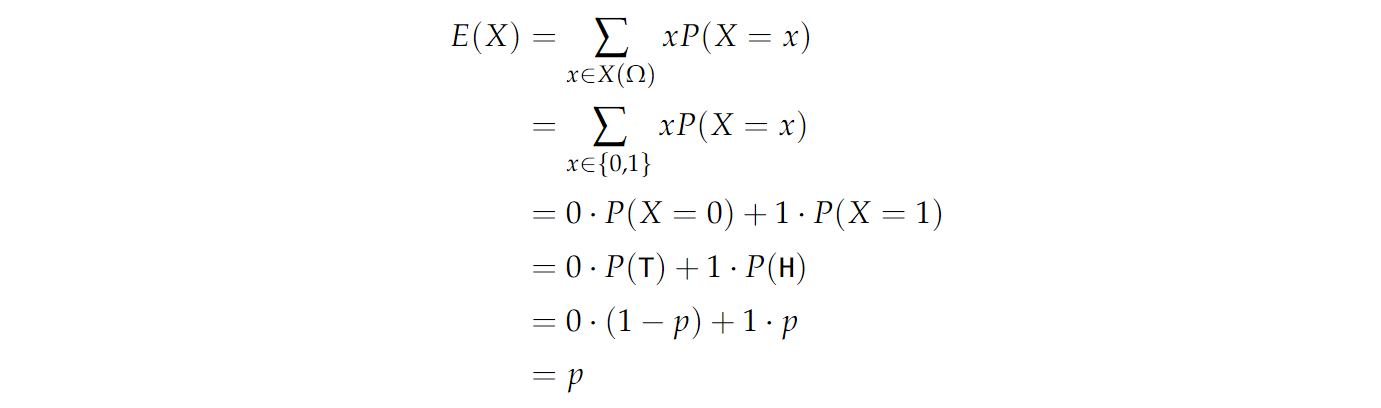
所以这个实验的期望值是 p p p ,如果我们掷一枚公平的硬币,那么 p = 1 / 2 p=1/2 p=1/2,那么 X X X 的平均值就是 1 / 2 1/2 1/2 。
期望的性质
-
如果 X X X 和 Y Y Y 是两个随机变量,那么:
E ( X + Y ) = E ( X ) + E ( Y ) E(X+Y)=E(X)+E(Y) E(X+Y)=E(X)+E(Y) -
如果 X X X 是随机变量,而 c c c 是常量,那么:
E ( c X ) = c E ( X ) E(cX)=cE(X) E(cX)=cE(X) -
如果 X X X 和 Y Y Y 是独立的随机变量,那么:
E ( X Y ) = E ( X ) E ( Y ) E(XY)=E(X)E(Y) E(XY)=E(X)E(Y)
图示
现在以另一个经典的概率实验为例:扔一枚公平的骰子,每一面出现的概率相等,均为1/6。当试验的次数越来越多时,扔出的结果的平均值慢慢趋向于它的期望3.5。
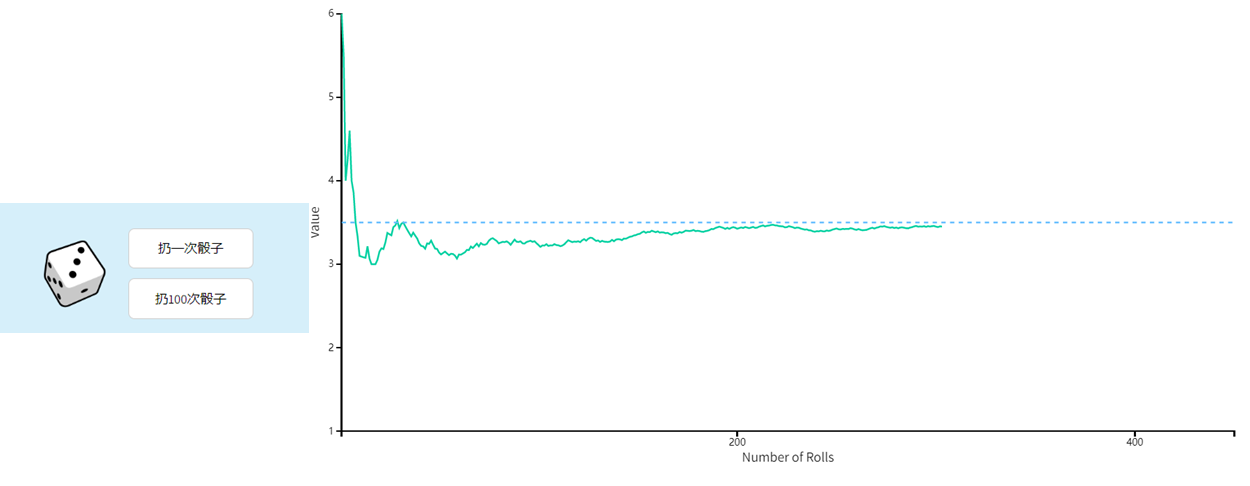
改变骰子每一面的重量分布(把骰子变的不公平),期望受到影响。
方差Variance
随机变量 X X X 的方差是一个非负数,它概括了 X X X 与其平均值或期望值相差多少的平均值。第一个自然的想法是
X − E ( X ) X-E(X) X−E(X)
即 X X X 与其平均值之间的差值。这本身就是一个随机变量,因为即使 E ( X ) E(X) E(X) 只是一个数字, X X X仍然是随机的。因此,我们需要取一个期望值,将此表达式转换为 X X X 与其期望值相差的平均值。这将我们引向
E ( X − E ( X ) E(X-E(X) E(X−E(X)
这几乎就是对方差的定义。我们要求方差始终为非负,因此期望值中的表达式应始终为 ≥ 0 ≥0 ≥0。所以不是取差值的期望值,而是取差值的平方的期望值。
🔥 定义: X X X 的方差用 V a r ( X ) Var(X) Var(X)表示,定义如下:
Var ( X ) = E [ ( X − E [ X ] ) 2 ] \text{Var}(X) = \text{E}[(X - \text{E}[X])^2] Var(X)=E[(X−E[X])2]
如果说随机变量的期望刻画了它的概率分布的“中心”,那么方差则刻画了概率分布的分散度。方差的定义是一个随机变量与它的期望之间的差的平方的加权平均值。这里的权重仍然是概率(或者密度)。
🍎 *The square root of the variance is called the standard deviation.*方差的平方根称为标准差。
方差的性质
如果 X X X 是具有平均值 E ( X ) E(X) E(X) 的随机变量并且 c c c 是实数
-
V a r ( X ) ≥ 0 Var(X)\ge 0 Var(X)≥0
-
V a r ( c X ) = c 2 V a r ( X ) Var(cX)=c^2Var(X) Var(cX)=c2Var(X)
-
V a r ( X ) = E ( X 2 ) − E ( X ) Var(X)=E(X^2)-E(X) Var(X)=E(X2)−E(X)
-
如果 X X X 和 Y Y Y 是独立的随机变量,那么
V a r ( X + Y ) = V a r ( X ) + V a r ( Y ) Var(X+Y)=Var(X)+Var(Y) Var(X+Y)=Var(X)+Var(Y)
图示
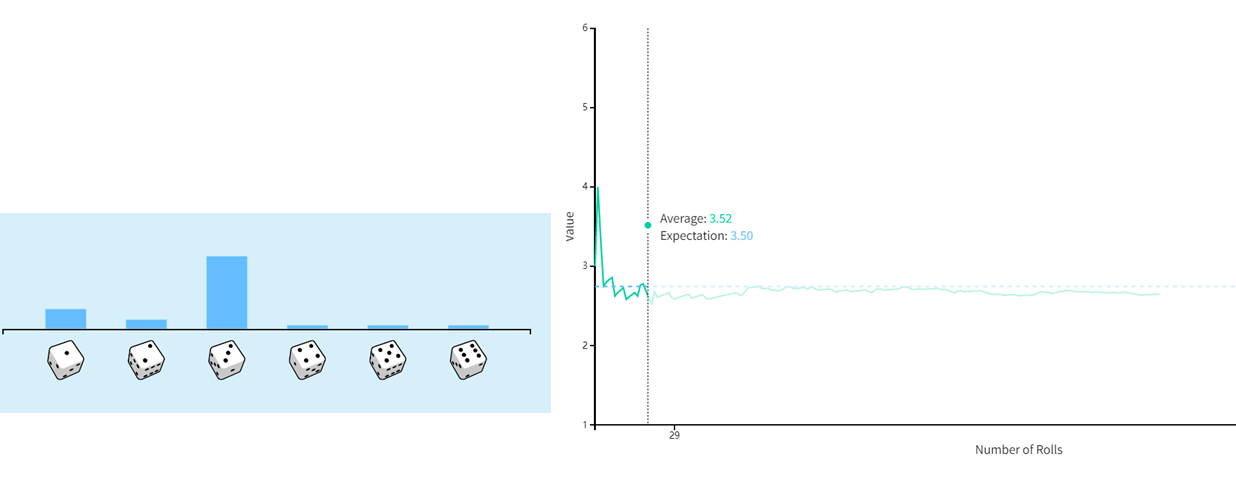
随机从下面十张牌中抽牌。当抽取的次数越来越多时,可以观察到样本平方差的平均值(绿色)逐渐趋向于它的方差(蓝色)。
马尔可夫不等式Markov’s Inequality
在这里,我们介绍一个将在下一节中对我们有用的不等式。
马尔可夫不等式是关于非负随机变量 X X X 超过某个数 a a a 的概率的一个界限。
📏 定理:Markov’s inequality ,设 X X X 为非负随机变量, a a a 为正数。则有:
P ( X ≥ a ) ≤ E ( X ) a P(X\ge a)\le \frac{E(X)}{a} P(X≥a)≤aE(X)
证明如下:
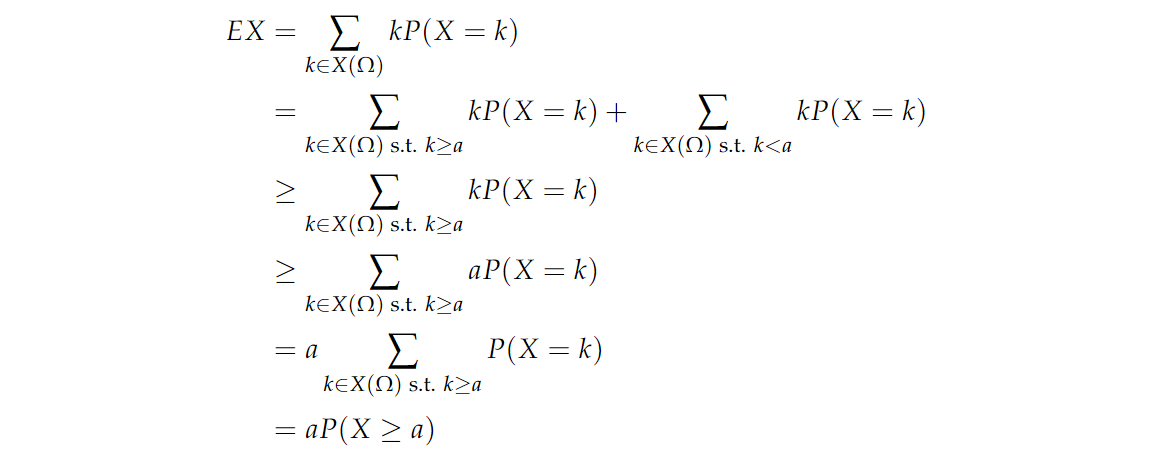
"s.t.” 代表 “such that”。
马尔可夫不等式的一个实际应用是,超过5倍于人均收入的人数不会超过总人数的1/5。
📐 推论(切比雪夫不等式 Chebyschev’s inequality)。 设 X X X 是随机变量,则有:
P ( ∣ X − E ( X ) > ϵ ) ≤ V a r ( X ) ϵ 2 P(|X-E(X)>\epsilon)\le \frac{Var(X)}{\epsilon ^2} P(∣X−E(X)>ϵ)≤ϵ2Var(X)
证明如下:
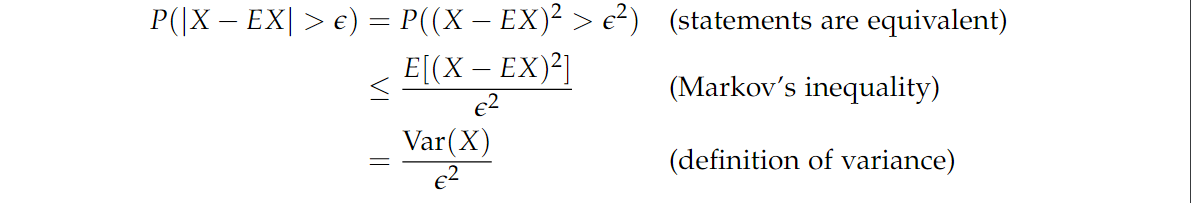
估测Estimation
我们做统计的主要原因之一是,在给定某个总体的子集数据的情况下,对该总体做出推断。例如,假设有两名候选人竞选公职。我们可能有兴趣找出支持某一特定政治候选人的人口的真实比例。我们可以从全国范围内随机挑选几千人,记录他们的偏好,而不是问每个人他们喜欢的候选人。然后,我们可以使用这个样本比例来估计支持候选人的人口的真实比例。由于每个人只能选择两个候选人中的一个,我们可以将这个人的偏好建模为一个bias p = 支持候选人 1 的真实比例 p=支持候选人1的真实比例 p=支持候选人1的真实比例 的掷硬币问题。
估计硬币的偏差Bias
现在假设我们再次掷硬币,这次有偏差(bias) p p p。换句话说,我们的硬币可以被认为是一个随机数量 X X X, 定义如下:
X = { 1 概率为 p 0 概率为 1 − p X=\begin{cases} 1&概率为p\\ 0&概率为1-p \end{cases} X={10概率为p概率为1−p
其中1为正面(H),0为负面(T)。
那我们如何估测偏差 p p p,一种方法是将硬币抛 n n n 次,计算我们抛出的正面向上数,然后将这个数字除以 n n n 。让 X i X_i Xi 代表第 i i i 次抛掷,估测值为 p ^ \hat p p^ ,则有:
p ^ = 1 n ∑ i = 1 n X i \hat p = \frac{1}{n}\sum_{i=1 }^nX_i p^=n1i=1∑nXi
随着样本数量 n n n 的增加,我们预计 p ^ \hat p p^ 会越来越接近 p p p 的真实值。
🔥 定义:如果对任意 ϵ ≥ 0 \epsilon \ge 0 ϵ≥0,
lim n → ∞ P ( ∣ p ^ − p ∣ > ϵ ) = 0 \lim_{n\to ∞}{P(|\hat p - p|> \epsilon)}=0 n→∞limP(∣p^−p∣>ϵ)=0
我们称估计量 p ^ \hat p p^ 是 p p p 的一致估计量。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 2
2 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)