EasyOCR-1.7.1Win10内网离线安装【Python3.8】
此文旨在指导如何在内网机上离线部署EasyOCR
本文转自博主的个人博客:https://blog.zhumengmeng.work,欢迎大家前往查看。
原文链接:点我查看
一、安装准备
因公司工作需求,特需在公司内网离线安装EasyOCR。首先我们需要对安装EasyOCR所需要的pip依赖包进行下载,具体如下表所示。
| Name | Version |
|---|---|
| opencv-python-headless | 4.8.1.78 |
| torchvision | 0.16.1 |
| torch | 2.1.1 |
| fsspec | 2023.10.0 |
| sympy | 1.12 |
| typing-extensions | 4.8.0 |
| filelock | 3.13.1 |
| mpmath | 1.3.0 |
| ninja | 1.11.1.1 |
| pyclipper | 1.3.0 |
| shapely | 2.0.2 |
| PyYAML | 6.0 |
| python-bidi | 0.4.2 |
| scikit-image | 0.21.0 |
| Pillow | 10.1.0 |
| numpy | 1.21.2 |
| scipy | 1.8.0 |
| six | 1.16.0 |
| lazy-loader | 0.3 |
| packaging | 23.2 |
| PyWavelets | 1.4.1 |
| tifffile | 2023.7.10 |
| imageio | 2.33.0 |
| networkx | 3.1 |
| requests | 2.26.0 |
| Jinja2 | 3.0.2 |
| idna | 3.2 |
| charset-normalizer | 2.0.6 |
| certifi | 2021.5.30 |
| urllib3 | 1.26.6 |
| MarkupSafe | 2.0.1 |
博主下载完了总计是31个.whl安装包:happy:。
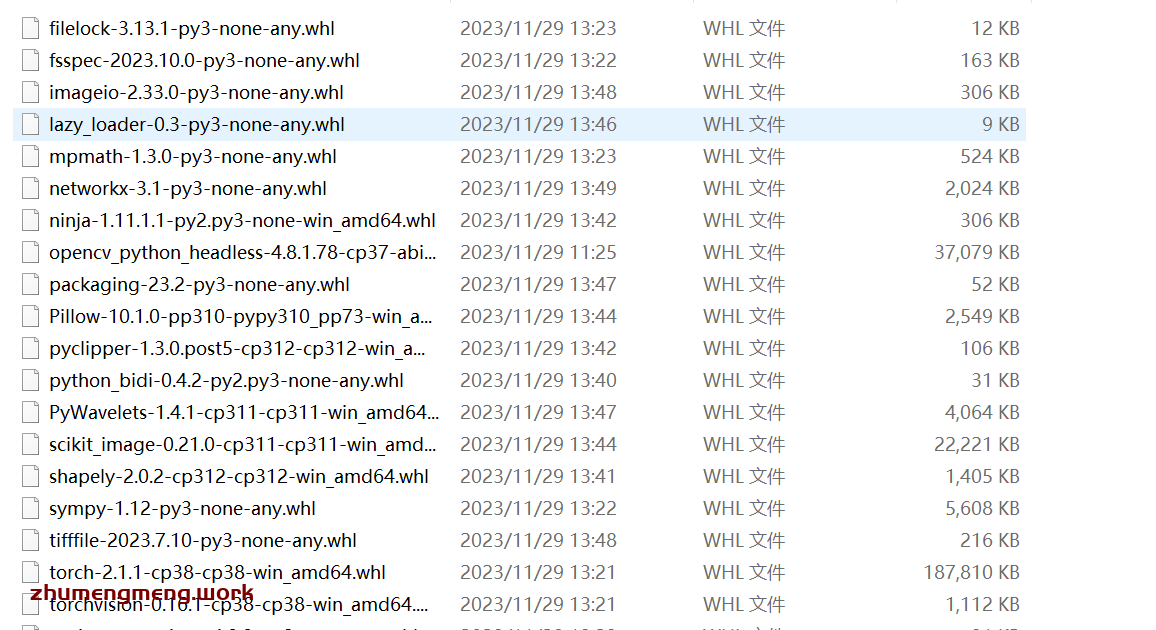
)
接下来便需要将这些安装包依次进行安装,按照下图从左到右的依赖循序进行安装。
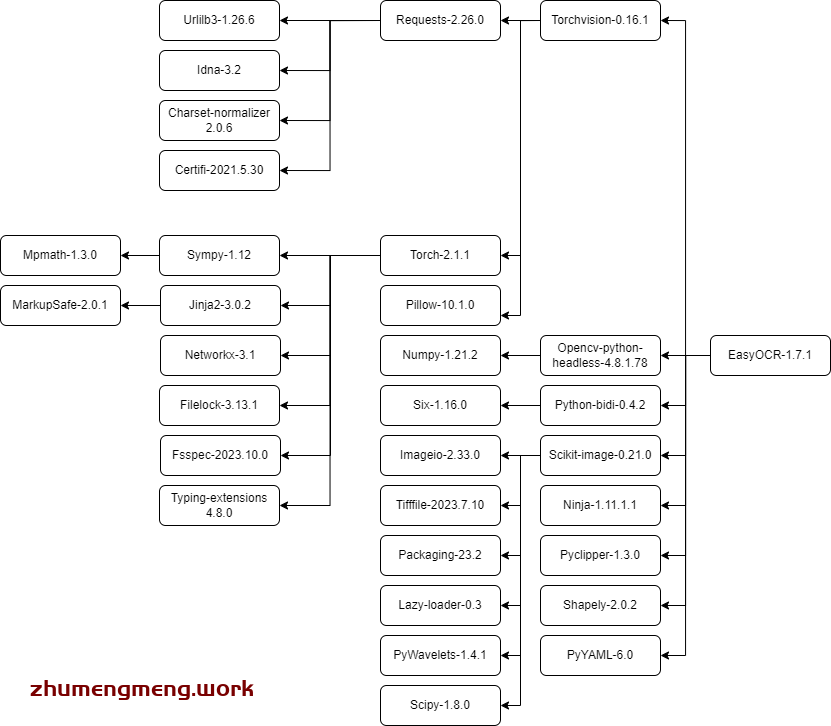
打个比方,我要安装Request,便需要先安装Urlilb3,idna,Charset-normalizer,certifi,然后才能安装Requests。
单个安装包的安装命令如下(需打开cmd,cd到安装包所在目录),以安装Pillow为例:
pip install ./Pillow-10.1.0-pp310-pypy310_pp73-win_amd64.whl
二、安装EasyOCR本体
下载EasyOCR本体压缩包,点我下载。解压到电脑中的固定位置。
打开cmd,cd到EasyOCR文件夹中,并输入以下代码进行安装。
python setup.py install;
等待安装即可,出现:Finished processing dependencies for easyocr==1.7.1代表安装完成
三、下载基础文字结构模型与常用语言模型
官方提供了下载中心,点我进入。
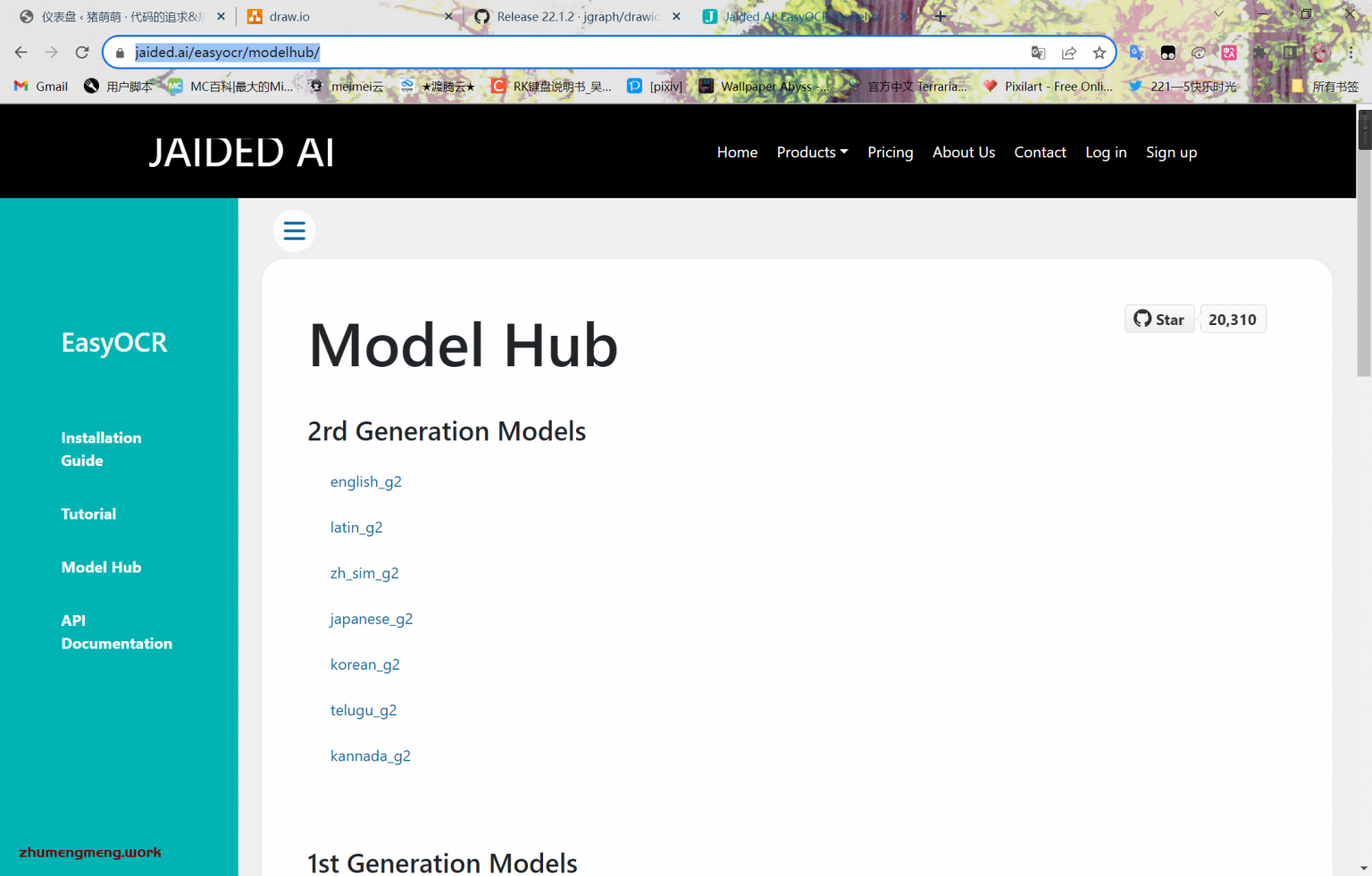
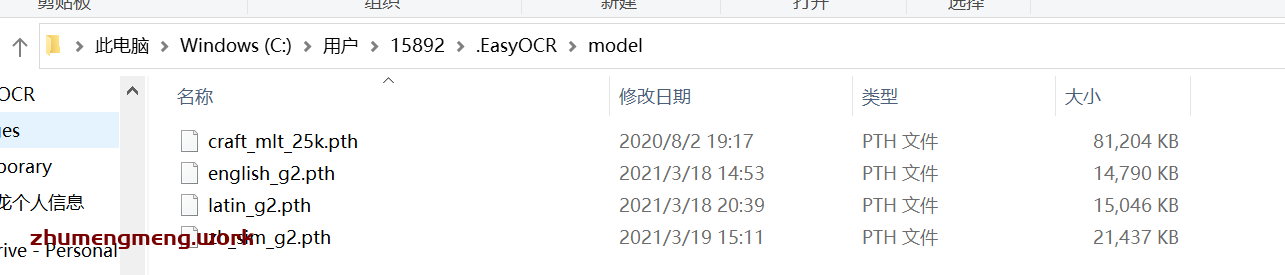
点击下载常用的english_g2、latin_g2、zh_sim_g2,这三个分别是英文-拉丁文-简体中文。
下面的Craft是所需要的基础文字模型,必须下载才能正常进行使用。

下载完后是4个压缩包,如下图所示。

打开C:\Users\<你的用户名>(个人用户文件夹),查看其目录下是否有.EasyOCR文件夹,有的话如下图所示。
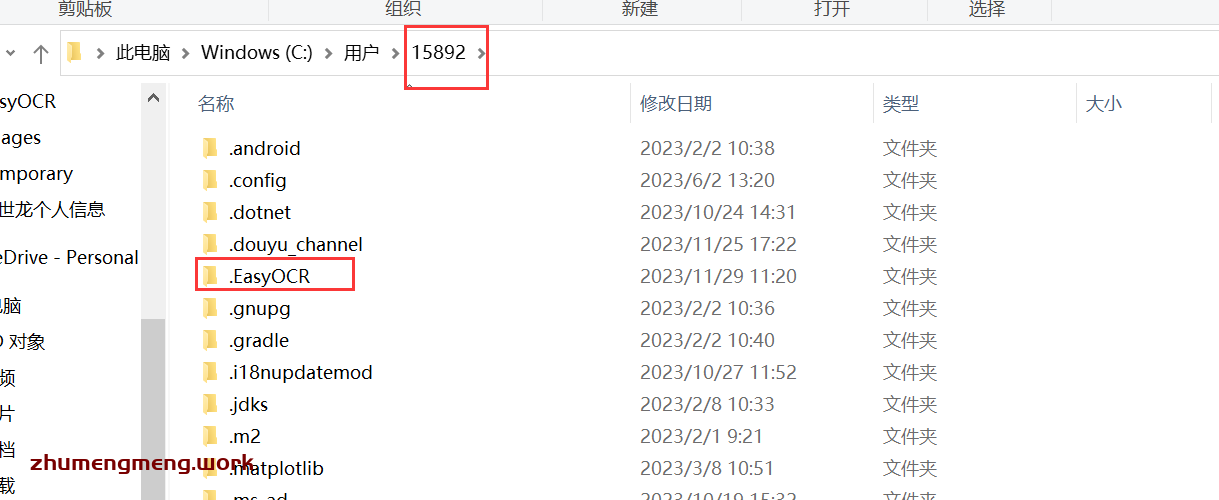
如果没有则创建一个.EasyOCR文件夹,并在其里面创建一个名为model的文件夹。
将刚刚下载的四个模型解压到model文件夹中,即可正常使用EasyOCR。
四、EasyOCR的基础使用
打开Pycharm新建python项目,并复制粘贴以下代码:
#-*- coding: utf-8 -*-
import easyocr
def get_text(path):
text_list = []
# 创建reader对象
# gpu=False,代表着不利用显卡进行图片识别,采用cpu进行图片识别,尽管可能会慢一些。
# ['ch_sim', 'en']代表着试用简体中文以及英文模型进行识别。
reader = easyocr.Reader(['ch_sim', 'en'],gpu=False)
# 读取图像
result = reader.readtext(path)
# 提取文字
for t in result:
print(t[1])
text_list.append(t[1])
return text_list
if __name__ == '__main__':
path1 = 'EasyOCR.png'
text1 = get_text(path1)
print(text1)
# save_text(text1)
并在项目文件夹中放入一张你想要识别的图片EasyOCR.png
下面是我的所需识别图片:

输出结果:


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 22
22 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)