IMDL-BenCo: A Comprehensive Benchmark and Codebase for Image Manipulation Detection &Localization
在图像处理检测与定位(IMDL)领域尚未建立一个全面的基准。缺乏这样一个基准导致模型评价不充分和具有误导性,严重破坏了这一领域的发展。然而,开源基线模型的缺乏和不一致的训练和评估协议使得在IMDL模型之间进行严格的实验和公平的比较具有挑战性。为了应对这些挑战,我们引入了IMDL- benco,这是第一个全面的IMDL基准测试和模块化代码库。IMDL- benco: i)将IMDL框架分解为标准化、
paper: https://arxiv.org/pdf/2406.10580
code: https://github.com/scu-zjz/IMDLBenCo
Abstract
在图像处理检测与定位(IMDL)领域尚未建立一个全面的基准。缺乏这样一个基准导致模型评价不充分和具有误导性,严重破坏了这一领域的发展。然而,开源基线模型的缺乏和不一致的训练和评估协议使得在IMDL模型之间进行严格的实验和公平的比较具有挑战性。为了应对这些挑战,我们引入了IMDL- benco,这是第一个全面的IMDL基准测试和模块化代码库。IMDL- benco: i)将IMDL框架分解为标准化、可重用的组件,并修改模型构建管道,提高编码效率和自定义灵活性;ii)全面实施或合并最先进模型的训练代码,以建立全面的IMDL基准;iii)基于已建立的基准和代码库进行深入分析,对IMDL模型架构、数据集特征和评估标准提供新的见解。具体而言,IMDL- benco包括常用的处理算法、8个最先进的IMDL模型(其中1个模型是从头开始复制的)、2套标准训练和评估协议、15个gpu加速评估指标和3种鲁棒性评估。这个基准和代码库在校准IMDL领域的当前进展和激励未来的突破方面代表了一个重大的飞跃。代码可从https://github.com/scu-zjz/IMDLBenCo获得。
1 Introduction
授权的图像处理或生成模型将图像处理检测和定位(IMDL)任务推向了信息取证和安全的前沿[23,35]。虽然在文献中,该任务偶尔被称为“伪造检测”[15,13]或“篡改检测”[31,30],但现在的共识是,术语IMDL[13]是该研究领域最合适的描述。IMDL中的“操纵”范围局限于部分图像的改变,从而产生与原始内容的语义差异[37]。它不适用于纯生成的图像(例如,由纯文本生成的图像),也不适用于引入噪声或其他非语义变化而不改变图像潜在含义的图像处理技术的应用[5]。术语“检测和定位”表示IMDL模型的双重责任:进行图像级和像素级评估。这包括图像级别的二值分类,识别输入图像是被操纵的还是真实的,以及像素级别的分割任务,通过掩码描绘精确的被操纵区域。简而言之,IMDL模型应该识别语义上重要的图像更改,并提供双重结果:类标签和操作掩码。
尽管深度神经网络在IMDL领域取得了快速成功[10,43,11],但现有模型存在不一致的训练和评估协议,如附录B.1中的表所示。这些不一致导致不兼容和不公平的比较,产生不充分和误导性的实验结果。因此,建立一个统一、全面的基准是IMDL领域最关心的问题。然而,建立这个基准远远不只是简单的协议统一或简单的模型重新训练。首先,大多数SoTA工作的训练代码是不公开的,一些SoTA工作的源代码是完全未发布的[26]。其次,IMDL模型通常包含多种底层特征[41,4,13]和复杂的损失函数,需要高度自定义的模型架构和解耦的管道设计来实现高效的复制。现有的框架,如OpenMMLab和Detectron2,严重依赖于注册机制和紧密耦合的管道。在现有框架下重现IMDL模型时,这种冲突会导致严重的效率问题,并导致具有极高编码负载和低可伸缩性的单一模型体系结构。因此,尚未建立一个全面的IMDL基准。
为了解决这个问题,我们引入了IMDL- benco,这是第一个全面的IMDL基准测试和模块化代码库。IMDL-BenCo: i)具有四个组件的模块化代码库: data loader , model zoo, training script, and evaluator;model zoo包含可自定义的模型体系结构,包括SoTA模型和骨干模型。损失设计也被隔离在model zoo内,而其他组件通过接口标准化,具有高度可重用性;这种方法减轻了模型自定义和编码效率之间的冲突;ii)全面实现或整合8个SoTA IMDL模型的训练代码,并建立了包含2套标准训练和评估协议、15个gpu加速评估指标和3种鲁棒性评估的综合基准。iii)基于所建立的基准和代码库进行深入分析,对IMDL模型架构、数据集特征和评估标准提供新的见解。该基准和代码库代表了校准IMDL领域当前进展的重大飞跃,并可以激发未来的突破。
2 Related Works
IMDL Model Arthitectures. IMDL的关键是识别由操作创建的伪影。伪影被认为是在低级特征空间上显示的。因此,几乎所有现有的IMDL模型都采用了“骨干网络+底层特征提取器”的模式。例如,SPAN[18]和ManTra-Net[41]使用VGG[33]作为其模型的主干,并结合SRM[47]和BayarConv[1]滤波器获得图像的底层特征。MVSS-Net[4]结合了提取边缘信息的Sobel[34]操作和ResNet50[16]主干上的BayarConv操作来提取图像噪声。每个模型的详细信息见表1。各种低级特征提取器导致各种损失函数和极其自定义的模型架构。因此,在现有框架中再现IMDL模型是低效的。各种损失函数和训练体系结构之间的高度耦合也使得扩展不同的模型训练框架变得极其困难。训练框架之间的差异进一步增加了模型复制的难度。这种紧密耦合也严重影响了算法的创新和快速迭代。

Inconsisitent Training and Evaluation Protocols. 除了模型再现的困难之外,到目前为止,存在着多种截然不同的训练和评估IMDL模型的协议。MVSS Net、CAT-Net和TruFor在ImageNet[6]数据集上进行预训练。SPAN[18]、PSCC-Net[24]、CAT-Net[21]和TruFor[21]使用合成数据集进行训练。此外,TruFor使用了来自流行照片分享网站Flickr和DPReview的大量原始图像来训练其noiseprint++ Extractor。MVSS-Net[4]和IML-ViT[26]在CASIAv2[8]数据集上进行训练。另一方面,NCL[45]没有使用预训练,而是在NIST16[12]数据集上进行训练。详细的模型训练和评估方案见附录B.1。考虑到IMDL基准数据集都是小尺寸的(几百到几千张图像)[45],训练数据集之间的巨大差异使得使用大型训练集或预训练的模型在其他评估集上的表现不可避免地会异常出色,这对模型性能评估的公平性提出了很大的挑战。此外,如表1所示,大多数模型并没有完全开放它们的代码。他们的结果很难校准,而且可能对新的IMDL研究人员产生很大的误导。
Exisiting IMDL Surveys and Benchmark. 尽管IMDL研究[27,44]已经注意到IMDL研究中的协议不一致和模型再现困难,但很少有人致力于解决这一问题。现有的研究往往依赖于独立设计的模型,具有独特的训练策略和数据集,导致报告结果存在偏差。此外,据我们所知,目前还没有一个全面的基准来确保对IMDL模型进行公平和一致的评估。缺乏统一的基准导致了误导性和不公平的模型评估,并破坏了IMDL领域的总体进展。
3 Our Codebase
本节介绍用PyTorch4实现的模块化、研究型和用户友好型代码库。如图1所示,它包括四个关键组件:data loader, model zoo, training script, and evaluator。我们的代码库在为IMDL任务提供标准化工作流和为用户提供广泛的自定义选择以满足他们的特定需求之间取得了平衡。
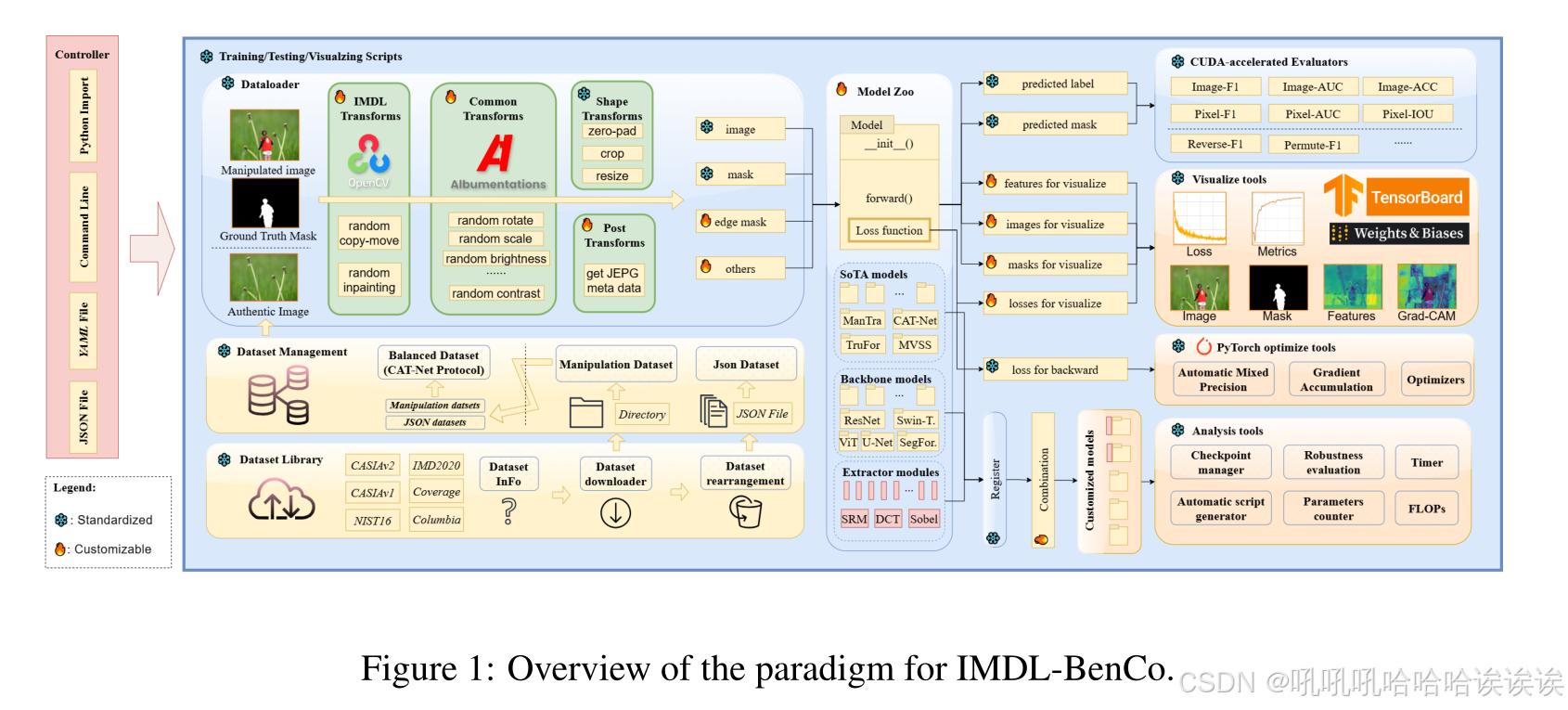
3.1 Data Loader
Data Loader主要处理数据集的排列、增强和转换过程。
Dataset Management. 我们为每个数据集提供了转换脚本,将它们重新排列成一组JSON文件。后续的训练和评估可以基于这些JSON文件进行。
Augmentations and Transformations. 由于需要专业注释和大量的手工工作,IMDL数据集通常非常小,难以满足越来越大的模型的需求。因此,数据增强是必不可少的。此外,确保输入模态和图像形状满足现有模型的要求至关重要。我们的数据加载器设计了以下转换序列:1)IMDL-specific transforms 特定于IMDL的转换:受MVSS Net[4]的启发,我们实现了简单的重绘和简单的复制-移动转换,这可以有效地提高性能,而无需额外的数据集。2) Common transforms 普通转换:这包括典型的视觉转换,如翻转、旋转和随机亮度调整,使用Albumentations[3]库实现。3) Post transforms 后变换:一些模型需要RGB模态以外的附加信息。例如,CAT-Net[21]需要JPEG格式特有的特定元数据,这些元数据可以通过回调函数从增强图像的RGB域进一步获得。4)Shape transforms 形状变换:这包括零填充[26],裁剪和调整大小,以确保均匀的输入形状。此外,评估器可以自动适应不同的形状策略来完成度量计算。
3.2 Model Zoo
Model Zoo目前由8个SoTA模型、4个使用开箱即用的视觉主干构建的主干模型和5个用于IMDL任务的特征提取器模块组成。重要的是要强调,我们的目标是使用相同的训练脚本(标准化)训练所有模型,同时也适应所有SoTA IMDL模型(自定义)。如图1所示,我们将损失函数计算集成到模型的前向函数中。通过统一的接口,我们传入所需的信息,如图像和掩码,输出预测结果,反向传播的损失,以及任何损失,中间特征和需要可视化的图像。因此,对于新的IMDL方法,用户只需要将具有损失设计的模型脚本添加到model zoo中,它将与IMDL- benco中的所有其他组件无缝集成。通过使用该框架有效地再现当前的SoTA模型,我们证明了我们已经成功地平衡了标准化和自定义之间的冲突。
1) SoTA模型。如表1所示,我们公平地复制了8个主流的IMDL SoTA模型,并坚持了原工作的设置。只要有可能,我们就使用公开可用的代码,只做必要的接口修改。对于缺乏公开可用代码的模型,我们基于各自论文中描述的设置来实现它们。每个模型的实现细节列在附录B.2中。2)主干模型:主流IMDL算法作为分类和分割任务,大量使用现有的视觉主干,这些主干的性能也会影响实现算法的性能。因此,我们将广泛使用的ResNet[16]、U-Net[29]、ViT[9]、swing - transformer[25]、SegFormer[42]等视觉主干改编为IMDL-BenCo作为主干。3)特征提取器模块:目前,在IMDL任务中广泛使用了几种标准的特征提取器。我们已经实现了5个主流的特征提取器作为nn.module,其中包括离散余弦变换(DCT)、快速傅立叶变换(FFT)[2]、Sobel操作[34]、BayarConv[1]和SRM滤波器[47]-允许与我们的骨干模型与注册机制无缝集成,用于管理大规模实验或直接导入,以便在后续研究中方便使用。
3.3 Training Scripts
训练脚本是使用IMDL-BenCo的入口点,集成其他组件来执行特定的功能。它可以有效地自动化任务,如模型训练、指标评估、可视化、GradCAM分析[32],以及基于配置文件(如JSON、命令行或YAML)的复杂性计算。为了避免在其他框架中看到的训练管道的高耦合(例如,Open MM Lab经常需要修改Python包函数来定制特性),我们提供了一个代码生成器,允许用户创建高度自定义的训练脚本,同时仍然利用IMDL-BenCo的高效组件来提高开发效率。
3.4 Evaluators
评估指标对于评估IMDL模型的性能至关重要。因此,现有的方法面临两个关键问题:1)指标通常不明确,使用诸如optimal-F1、permuet -F1和macro-F1等术语匿名地用作F1分数;2)大多数开源代码在CPU上计算指标,导致处理速度较慢。
为了解决这些问题,我们在PyTorch中实现了gpu加速的评估器作为标准指标。每个评估器处理一个特定的度量,包括图像级(检测)F1分数、曲线下面积(AUC)、精度和像素级(定位)F1分数、AUC、精度和IOU(交集/联合)。所有算法都能方便地自动适应数据加载器中的形状变换。我们还显式地实现了衍生算法,如reverse - f1和permuteF1,以评估其高估的公平性,如第5.3节所示,强调在未来的工作中需要谨慎和明确的度量声明,以确保公平公正的比较。
使用来自CASIAv2数据集的12,554张图像和四个NVIDIA 4090 gpu,我们使用神经网络测试了我们的评估器的时间效率。作为模型的同一性,可以忽略计算时间。结果如表2所示,表明我们的算法显著减少了度量评估时间,为大规模IMDL任务提供了更快、更可靠的工具。

4 Our Benchmark
本节主要详细介绍基准测试的过程和结果。
4.1 Benchmark Settings
数据集。我们的基准包括8个IMDL领域经常使用的公开数据集:CASIA[8]、Fantastic Reality[20]、IMD2020[28]、NIST16[12]、Columbia[17]、COVERAGE[40]、tampered COCO[21]、tampered RAISE[21]。
评价指标。考虑到被操纵区域和真实区域之间的大小不平衡,像素级的F1分数被广泛用于评估模型的性能。我们还测量了两种不同协议下模型的像素级F1分数。此外,对于包含检测头(DH)的模型,我们报告了图像级F1分数。我们还报告了高斯模糊、高斯噪声和JPEG压缩下模型的像素级F1分数稳健性测试结果。
硬件配置。为了模拟不同的硬件配置,实验在三个不同的服务器上进行,分别使用两个AMD EPYC 7542 cpu, 128G RAM,并包含4×NVIDIA A40 gpu, 6×NVIDIA 3090 gpu和4×NVIDIA 4090 gpu。
模型和超参数。我们的基准选择IMDL领域中的8个SoTA方法作为初始批实现的方法。这些模型有:Mantra-Net[41]、MVSS-Net[4]、CAT-Net[21]、ObjectFormer[39]、PSCC-Net[24]、NCL-IML[45]、Trufor[13]和IML-ViT[26]。相应测试和超参数的详细信息可在附录B.2中找到。
4.2 Benchmark Protocols
现有公共数据集在规模和质量上的不平衡导致了IMDL方法的训练和评估方案的不一致性。这使得很难在现有方法之间实现公平和方便的比较。为此,我们选择了两种合理且应用广泛的协议:Protocol-MVSS,由MVSS-Net[4]提出,模型只在CASIAv2数据集上进行训练,然后直接在其他数据集上进行测试,不需要进行微调。CASIAv2数据集的大小适中,但质量较高,因此该协议是衡量模型泛化能力的一个很好的指标。Protocol-CAT,由CAT-Net提出[21],其中模型在由CASIAv2、Fantastic Reality、IMD2020、tampered COCO和tampered RAISE组成的混合数据集上进行训练。对于每个epoch,随机抽取固定数量的图像进行训练,然后直接在其他数据集上测试模型,而不进行微调。该混合数据集包含各种类型的篡改和大量被操纵的图像,使模型能够有效地展示其学习能力。
具体来说,在Protocol-MVSS中,我们在训练没有检测头的方法时不使用真实图像。而在Protocol-CAT中,我们不做这种区分。此外,我们使用每篇论文中指定的推荐图像缩放尺寸。我们还为所有方法应用一致的数据增强技术,例如翻转、模糊、压缩以及使用OpenCV实现的简单复制移动和重绘操作。
4.3 Our Benchmark Results
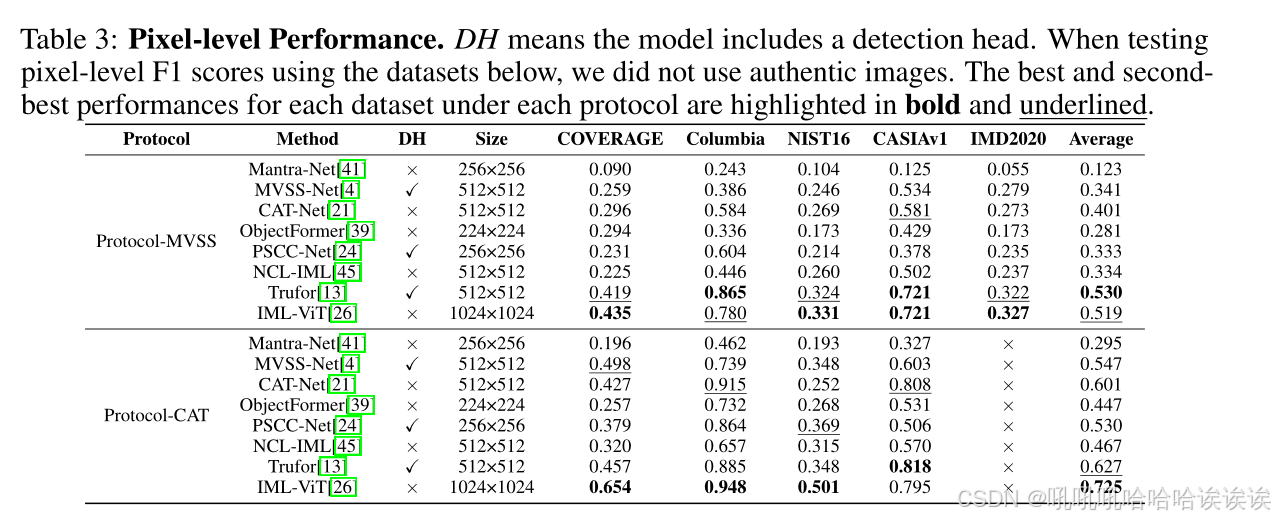
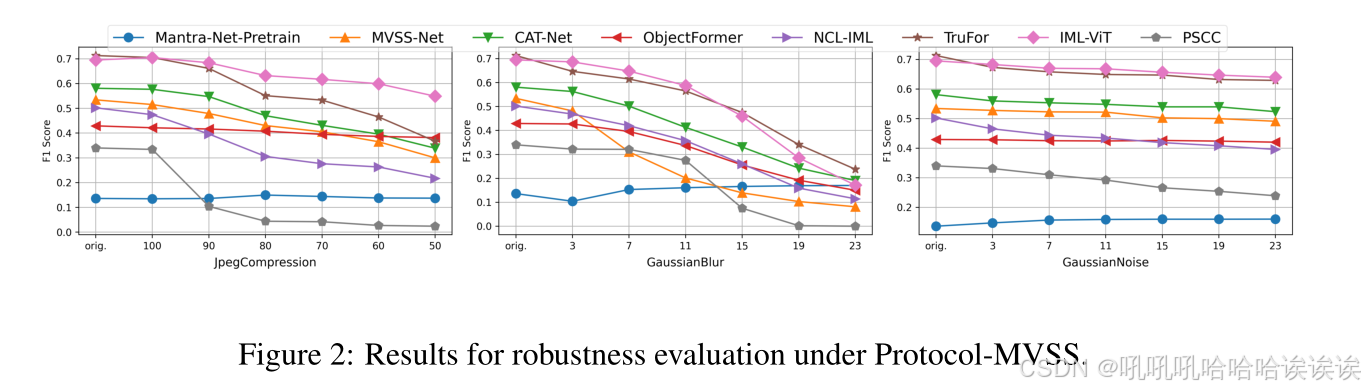
对于Protocol-MVSS,我们报告了COVERAGE、Columbia、NIST16、CASIAv1和IMD2020数据集上的F1分数。对于Protocol-CA T,我们排除了IMD2020,因为它包含在训练过程中。我们使用0.5的固定阈值。像素级F1分数和图像级F1分数分别如表3和表4所示。我们复制的模型的性能与原论文报道的结果之间存在一些差异。此外,在相同的协议下,一些模型的性能有限。我们还在图2中描述了Protocol-MVSS下的鲁棒性测试。与原始论文相比,我们观察到一些模型的显著鲁棒性变化,证明了统一框架的必要性和准确度。

5 Experiments and Analysis
我们的代码库和基准统一了IMDL模型的测试和训练协议。尽管这种统一,与其他检测或分割任务相比,IMDL任务还保留了许多独特和关键的特征,特别是对“骨干网络+底层特征提取器”范式,随机分割的基准数据集,以及各种评估指标的依赖。因此,我们进一步研究和深入分析了4个广泛关注但较少探索的问题,包括:1)底层特征提取器在IMDL中是必须的吗?2)哪种主干架构最适合IMDL任务?3)随机分割的训练和测试数据集是否会影响模型性能?4)哪些指标最能代表模型的实际行为?
通过广泛的实验,我们是第一个用证据事实回答上述问题的人,并为IMDL领域的模型设计、数据集清理和度量提供了新的关键见解。
5.1 Low-level Feature Extractors and Backbones
如表1所示,流行的IMDL方法严重依赖特征提取器来检测操作痕迹。然而,很少有文章具体分析不同提取器的优点。在本节中,我们将model zoo(见3.2节)中实现的骨干模型与不同的特征提取器模块结合起来,探索每个特征提取器的性能及其与骨干的兼容性。每个组合模型的复杂度如表5所示。

所有组合模型在CASIAv2数据集上进行200次epoch的训练,图像大小为512×512。详细的实验设置见附录B.5.1。然后在四个不同的数据集(casiav1、Columbia、NIST16和coverage)上对它们进行评估,以评估它们的泛化能力。表6报告了四个数据集中每种设置的平均F1分数。
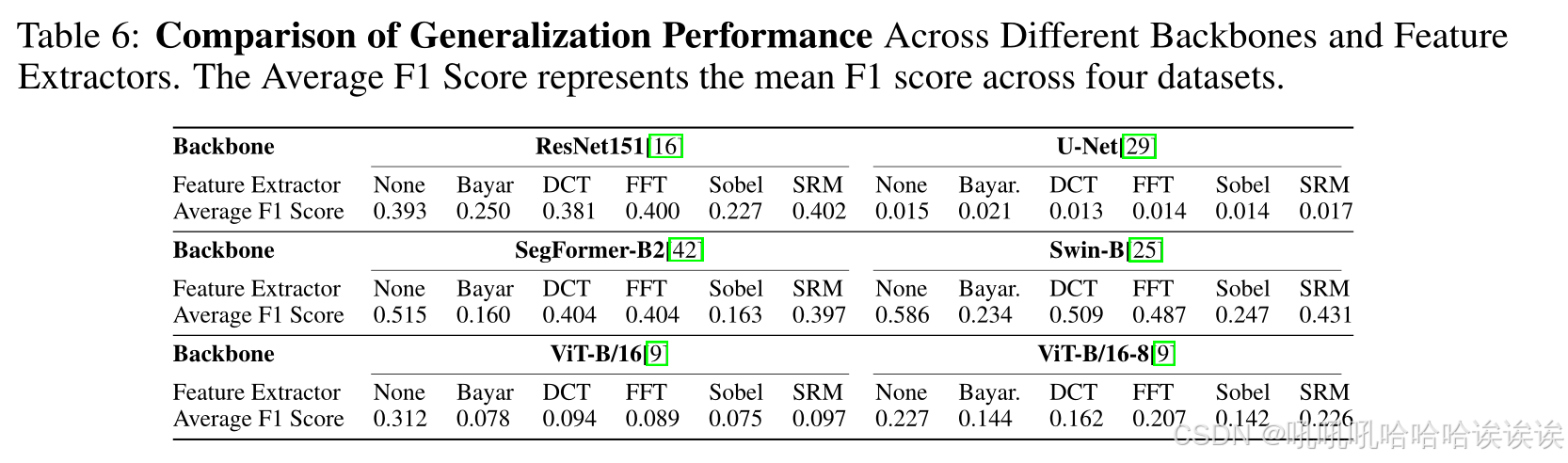
实验表明,特定的特征提取器,如BayarConv和Sobel,会对模型性能产生负面影响。相比之下,当配备DCT、FFT和SRM特征提取器时,ResNet模型表现出更好的性能。当配备特征提取器时,ViT模型倾向于欠拟合,并且可能需要更多的epoch来收敛。一种更好的特征融合方法可以消除当前ViT模型存在的问题。对于Swin Transformer,添加特征提取器可能导致过拟合,而Segformer的性能通常会下降。详细讨论和实验结果见附录B.5.2。
特征提取器的必要性。总之,BayarConv和Sobel不适合IMDL任务。适当的低级特征提取器,如DCT、FFT和SRM,可以提高ResNet model的性能。然而,所有的特征提取器都可能阻碍ViT及其变体的收敛,导致Swin Transformer过拟合,并导致SegFormer的整体性能下降。因此,低级特征提取器在IMDL中不是必需的。
Backbone Fitness。如表6所示,Swin Transformer和Segformer在IMDL任务上表现出强大的性能,优于ResNet和ViT。U-Net架构并不适合这项任务。
5.2 Dataset Bias and Cleansing Methods
Dataset Bias 数据集偏差。通过我们的基准测试,我们发现将我们协议下的模型性能与他们论文中微调后的模型性能进行比较,在每个模型上,在NIST16数据集上都观察到明显的性能下降。关于NIST16数据集的详细信息和性能下降情况,请参见附录B.5.3和表12。然而,在其他基准数据集上并没有出现如此巨大的下降。
经过深入分析,我们发现NIST16数据集包含“极其相似”的操作模式。然后,将这些极其相似的图像随机分成训练集和测试集,模型可以通过记忆这些极其相似的训练样本来有效地定位操作区域。我们将这种关键的数据集偏差称为“标签泄漏”。图3展示了NIST16数据集中标签泄漏的一个实例。

Dataset Cleansing 数据清洗。鉴于广泛使用NIST16进行评估,我们提出了一种使用SSIM(结构相似性)索引的数据集清理方法,以确保清理后的NIST16- c数据集避免过度相似的图像。这种清理方法对于解决数据集偏差和校准标签泄漏带来的性能提升至关重要。详细的清洗过程见附录B.5.3。
我们对NIST16-C进行了广泛的基准测试,测试结果见表7。这表明我们已经消除了NIST16数据集中的冗余数据,解决了标签泄漏问题。因此,模型现在可以专注于学习操作的潜在特征。

5.3 Evaluation Metrics Selection
Controversial F1 Scores 有争议的F1分数。F1度量在不同的计算方程下有多种变化,如 inverted F1和Permuted F1[19]。inverted F1是通过计算反转预测结果与原始掩码之间的F1得到的值。Permuted F1是F1和inverted F1之间的最大值。公式为Permuted-F1(G, P) = max(F1(G, P), Inverted-F1(G, P)),其中G为GT,P为预测掩码。我们在B.5.4中总结了各种现有的F1指标及其计算。这些不统一的度量会影响对模型真实性能的判断。
如图4所示,当掩码的白色面积较大,且模型预测结果与掩码存在较大偏差时,inverted F1得分远高于F1得分。这个度量会影响评估的公平性。

此外,在通过sklearn库计算F1分数时使用“宏观 macro”、“微观 micro”和“加权 weighted”等参数是不合适的,因为它人为地夸大了我们的F1指标,这是不合理的。综上所述,我们认为使用带有“二进制”参数的F1分数进行计算更加科学和严谨。我们希望未来的研究能统一采用这一标准。此外,我们在附录B.5.5中讨论了当前AUC被高估的问题。

6 Conclusions
总之,IMDL-BenCo标志着图像处理检测与定位领域的重大进步。通过提供全面的基准测试和模块化的代码库,IMDL- benco提高了编码效率和自定义灵活性,从而促进了IMDL模型的严格实验和公平比较。此外,IMDL-BenCo通过为模型开发和评估提供统一和可扩展的框架,激发了未来的突破。我们预计IMDL- benco将成为研究人员和从业人员的重要资源,推动IMDL技术在包括信息取证和安全在内的各个领域的能力和应用。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)