ResNet50的训练以及使用和模型的优化
通常,我们会有一个根文件夹,里面包含两个子文件夹:train 和 val(分别用于训练和验证)。每个子文件夹下应该包含代表类别的进一步子文件夹,每个类别文件夹里包含相应的图像文件。使用 PyTorch 的数据加载器和数据变换工具来准备你的数据。这包括规范化图像尺寸和颜色值,使其适合 ResNet50 模型。加载预训练的 ResNet50 模型,并修改它的最后一层,以适应你的类别数量。编写代码来训练
·
1.ResNet50模型代码(resnet50_origin.py)
import torch
import torch.nn as nn
from torchvision.models.utils import load_state_dict_from_url
# 定义残差块(Bottleneck),这是ResNet的核心组件之一
class Bottleneck(nn.Module):
expansion = 4 # 扩展因子,用于调整输出通道数
def __init__(self, in_planes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
# 第一个1x1卷积,用于减少维度
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
# 第二个3x3卷积,是残差块的主体,可能带有步长
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
# 第三个1x1卷积,用于扩展维度,准备与输入相加
self.conv3 = nn.Conv2d(planes, planes * self.expansion, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
# 如果需要调整输入维度以匹配输出维度,使用downsample
self.downsample = downsample
def forward(self, x):
identity = x # 保存输入,用于之后的残差连接
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity # 残差连接
out = self.relu(out)
return out
# 定义整个ResNet模型架构
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000):
super(ResNet, self).__init__()
self.in_planes = 64
# 初始卷积层
self.conv1 = nn.Conv2d(3, 64, kernel_size=7,
stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# 构建4个层级的残差块
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
# 全局平均池化和全连接层,用于分类
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
# 辅助函数,用于构建每一层的残差块
def _make_layer(self, block, planes, num_blocks, stride=1):
downsample = None
if stride != 1 or self.in_planes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_planes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.in_planes, planes, stride, downsample))
self.in_planes = planes * block.expansion
for _ in range(1, num_blocks):
layers.append(block(self.in_planes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
"""_summary_
Returns:
_type_: _description_
"""
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
# 函数用于获取预训练的ResNet50模型
def resnet50(pretrained=False, **kwargs):
model = ResNet(Bottleneck, [3, 4, 6, 3], **kwargs)
if pretrained:
state_dict = load_state_dict_from_url('https://download.pytorch.org/models/resnet50-19c8e357.pth')
model.load_state_dict(state_dict)
return model
2.训练代码(jupyter格式,方便逐次运行)(resnet50_train.ipynb)
注意:以下代码都放在resnet50_train.ipyn文件中。
确保你的图像数据被组织成适当的文件夹结构。通常,我们会有一个根文件夹,里面包含两个子文件夹:train 和 val(分别用于训练和验证)。每个子文件夹下应该包含代表类别的进一步子文件夹,每个类别文件夹里包含相应的图像文件。如下图所示:
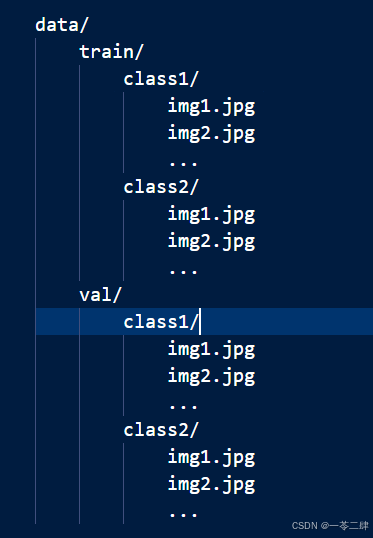
使用 PyTorch 的数据加载器和数据变换工具来准备你的数据。这包括规范化图像尺寸和颜色值,使其适合 ResNet50 模型。
from torchvision import transforms, datasets
import torch
import os
# 设置数据转换
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
# 数据目录
data_dir = r'F:\AI\resnet50\data'
# 加载数据集
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x])
for x in ['train', 'val']}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4,
shuffle=True, num_workers=4)
for x in ['train', 'val']}
加载预训练的 ResNet50 模型,并修改它的最后一层,以适应你的类别数量。
from torchvision import models
model = models.resnet50(pretrained=True)
num_ftrs = model.fc.in_features
model.fc = torch.nn.Linear(num_ftrs, len(image_datasets['train'].classes))
设置优化器和损失函数,准备模型训练。
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
编写代码来训练模型,记录训练和验证过程中的损失和准确率。
def train_model(model, criterion, optimizer, num_epochs=25):
for epoch in range(num_epochs):
print(f'Epoch {epoch}/{num_epochs - 1}')
print('-' * 10)
for phase in ['train', 'val']:
if phase == 'train':
model.train()
else:
model.eval()
running_loss = 0.0
running_corrects = 0
for inputs, labels in dataloaders[phase]:
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
if phase == 'train':
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(image_datasets[phase])
epoch_acc = running_corrects.double() / len(image_datasets[phase])
print(f'{phase} Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f}')
return model
# 调用训练函数
model = train_model(model, criterion, optimizer, num_epochs=25)
3.模型优化
ResNet50SE.py
import torch
import torch.nn as nn
import torch.nn.functional as F
# Squeeze-and-Excitation (SE) 层定义
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
# 适应性平均池化层用于进行通道压缩
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# 两层全连接网络,第一层降维,第二层升维,用于学习通道间的非线性关系
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False), # 降维
nn.ReLU(inplace=True), # 非线性激活
nn.Linear(channel // reduction, channel, bias=False), # 升维
nn.Sigmoid() # 输出通道权重
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c) # Squeeze操作,将空间维度压缩为1x1
y = self.fc(y).view(b, c, 1, 1) # Excitation操作,学习每个通道的重要性
return x * y.expand_as(x) # 通过乘法重新调整原始特征图的通道权重
# 带有SE模块和分组卷积的Bottleneck残差块定义
class SEBottleneck(nn.Module):
expansion = 4 # 输出通道数是输入通道数的四倍
def __init__(self, in_planes, planes, groups, stride=1, downsample=None):
super(SEBottleneck, self).__init__()
# 第一个1x1卷积用于降低维度
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
# 分组卷积层,减少参数数量并提高效率
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, groups=groups, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
# 第三个1x1卷积用于扩展维度,恢复通道数
self.conv3 = nn.Conv2d(planes, planes * self.expansion, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.se = SELayer(planes * self.expansion) # 在最后一个卷积后添加SE模块
self.downsample = downsample # 如果stride不为1或者维度改变则需要调整维度的下采样层
def forward(self, x):
identity = x # 保存输入,用于最后的残差连接
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out = self.se(out) # 应用SE模块增强特征表达
if self.downsample is not None:
identity = self.downsample(x)
out += identity # 残差连接
out = self.relu(out)
return out
# ResNet50SE模型,使用SEBottleneck构建
class ResNet50SE(nn.Module):
def __init__(self, block, layers, num_classes=1000, groups=32):
super(ResNet50SE, self).__init__()
self.in_planes = 64
# 初始层
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# 构建四个残差层,不同层使用不同的配置
self.layer1 = self._make_layer(block, 64, layers[0], groups)
self.layer2 = self._make_layer(block, 128, layers[1], groups, stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], groups, stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], groups, stride=2)
# 结尾的全局平均池化和全连接层
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
def _make_layer(self, block, planes, num_blocks, groups, stride=1):
downsample = None
if stride != 1 or self.in_planes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_planes, planes * block.expansion, kernel_size=1, stride=stride, groups=groups, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.in_planes, planes, groups, stride, downsample))
self.in_planes = planes * block.expansion
for _ in range(1, num_blocks):
layers.append(block(self.in_planes, planes, groups))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
# 例如,创建模型实例并指定是否预训练
model = ResNet50SE(SEBottleneck, [3, 4, 6, 3], num_classes=1000, groups=32)
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)