开源符号音乐生成(Symbolic Music Generation)模型调研
MusicTransformer对于语言的理解最好,但是是针对于钢琴旋律生成。MuseCoco和MuseGAN相似,都能基于文字生成多轨乐谱。MusicVAE主要特点是能够对旋律进行变奏,为两个旋律生成桥段。
·
音乐生成模型概述
当前主流方法可分为两种,基于符号、基于音频,本博客聚焦于调研基于符号的开源模型,即根据提示生成数字乐谱(midi、abc等)的模型。
运用:音乐创作、生成游戏音轨等
Magenta
- 发布者:Google Brain
- 发布时间:2016年
- 基本信息:大型的音乐人工智能项目
-
MusicTransformer
- GitHub - gwinndr/MusicTransformer-Pytorch: MusicTransformer written for MaestroV2 using the Pytorch framework for music generation
- 效果:https://magenta.tensorflow.org/piano-transformer,可以说是非常好,生成的结果音乐性很强,有基本的音乐结构,对于提示的理解也很好。例如,示例中“给德彪西的月光开头生成续曲”,“给划船歌的格式生成伴奏”效果都不错。
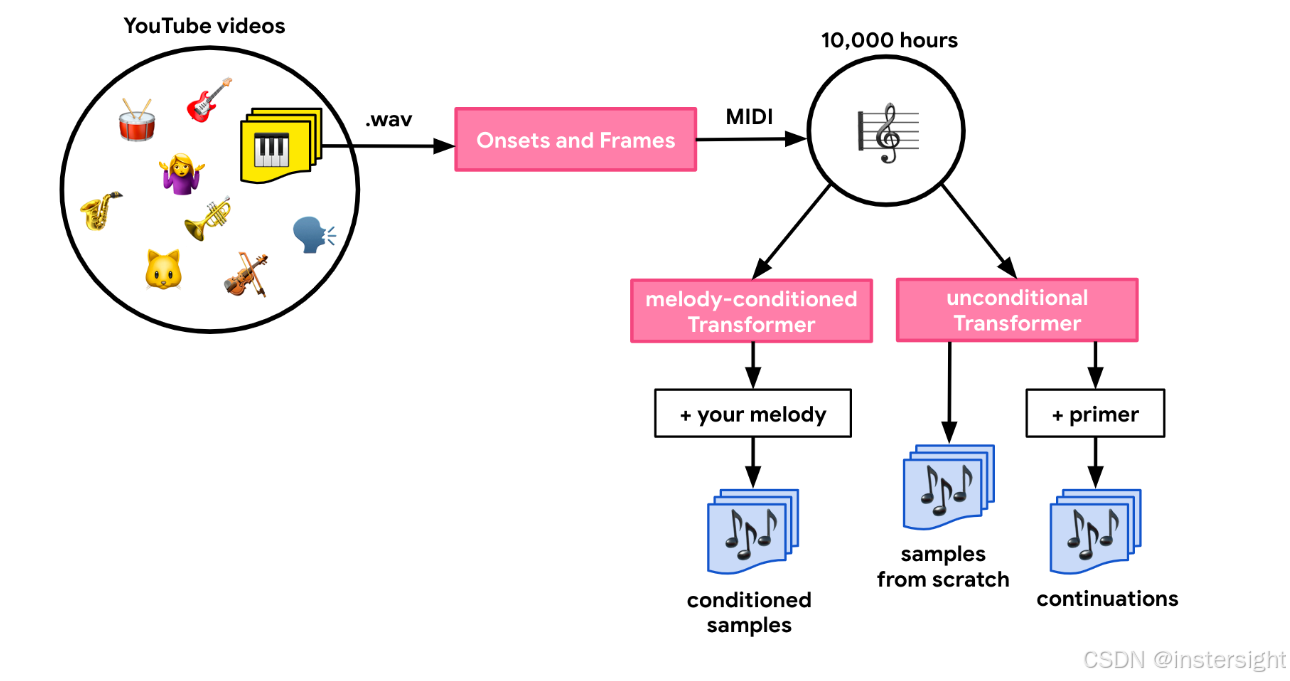
- dataset:对于我们的数据集,我们从公开的 YouTube 视频开始,这些视频具有允许使用的许可证。然后,我们使用基于 AudioSet 的模型来识别只包含钢琴音乐的片段。这产生了数十万段视频。为了训练 Transformer 模型,我们需要将这些内容转化为符号化的、类似 MIDI 的形式。因此,我们提取了音频并使用我们的 Onsets and Frames 自动音乐转录模型对其进行了处理。这最终生成了超过 10,000 小时的符号化钢琴音乐,我们随后使用这些数据来训练模型。
-
MusicVAE
- 基本信息:不能接受自然语言提示,主要功能是音乐的生成、变换、插值(接受两段旋律,能够生成过渡片段)
- magenta/magenta/models/music_vae at main · magenta/magenta · GitHub
- dataset:貌似没有公开

Muzic
- 发布者: Muzic was started by some researchers from Microsoft Research Asia and also contributed by outside collaborators.
- 发起时间:2019年
- 基本功能:有关AI music的一个research,涵盖音乐人工智能的各个领域
-
MuseCoco
- muzic/musecoco at main · microsoft/muzic · GitHub
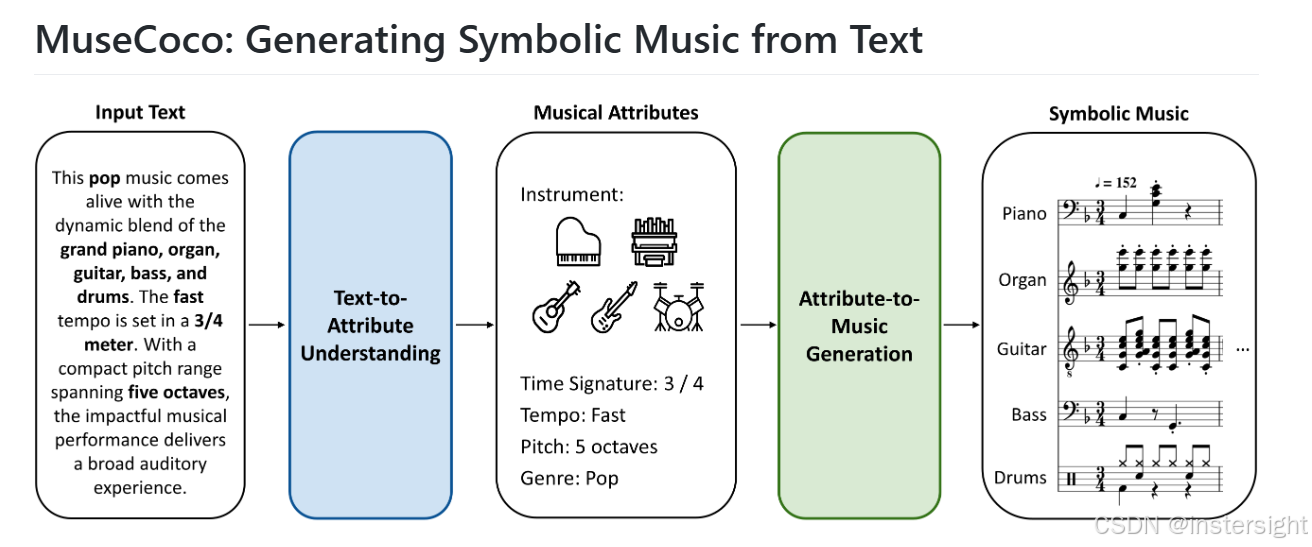
- 进行两个建模,第一个是从文字里提取音乐属性,比如说使用到的乐器、拍号、速度、八度跨度、流派,再输入生成模块生成多轨音乐。
DeepJazz
- 发布者:Ji-Sung Kim
- 发布时间:2016年(论文发布时)
- 基本功能:
- 使用递归神经网络(RNN)和长短时记忆网络(LSTM)生成爵士乐风格的音乐。
- 不再支持使用
MuseGAN
- 发布者:北京大学、清华大学等多家机构合作
- GitHub - salu133445/musegan: An AI for Music Generation
- 发布时间:2017年(论文首次发布)
- 基本功能:
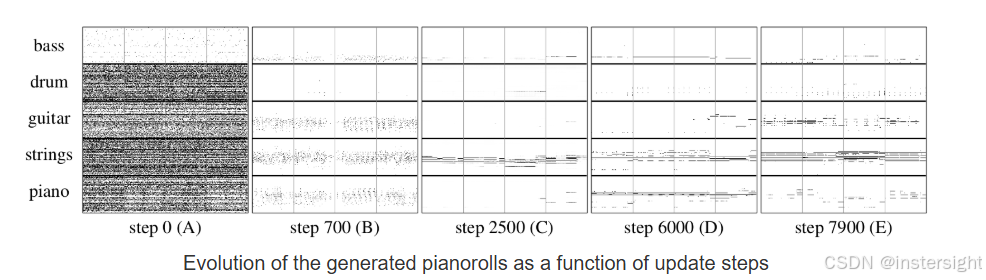
- 使用生成对抗网络(GAN)进行多乐器音乐生成。
- 支持生成多轨道、不同乐器的音乐片段,并且可以协调旋律、和声、节奏等音乐元素。
总结
MusicTransformer对于语言的理解最好,但是是针对于钢琴旋律生成。
MuseCoco和MuseGAN相似,都能基于文字生成多轨乐谱。
MusicVAE主要特点是能够对旋律进行变奏,为两个旋律生成桥段。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 27
27 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)